AWS Compute Blog
Operating serverless at scale: Improving consistency – Part 2
This post is written by Jerome Van Der Linden, Solutions Architect.
Part one of this series describes how to maintain visibility on your AWS resources to operate them properly. This second part focuses on provisioning these resources.
It is relatively easy to create serverless resources. For example, you can set up and deploy a new AWS Lambda function in a few clicks. By using infrastructure as code, such as the AWS Serverless Application Model (AWS SAM), you can deploy hundreds of functions in a matter of minutes.
Before reaching these numbers, companies often want to standardize developments. Standardization is an effective way of reducing development time and costs, by using common tools, best practices, and patterns. It helps in meeting compliance objectives and lowering some risks, mainly around security and operations, by adopting enterprise standards. It can also reduce the scope of required skills, both in terms of development and operations. However, excessive standardization can reduce agility and innovation and sometimes even productivity.
You may want to provide application samples or archetypes, so that each team does not reinvent the wheel for every new project. These archetypes get a standard structure so that any developer joining the team is quickly up-to-speed. The archetypes also bundle everything that is required by your company:
- Security library and setup to apply a common security layer to all your applications.
- Observability framework and configuration, to collect and centralize logs, metrics and traces.
- Analytics, to measure usage of the application.
- Other capabilities or standard services you might have in your company.
This post describes different ways to create and share project archetypes.
Sharing AWS SAM templates
AWS SAM makes it easier to create and deploy serverless applications. It uses infrastructure as code (AWS SAM templates) and a command line tool (AWS SAM CLI). You can also create customizable templates that anyone can use to initialize a project. Using the sam init command and the --location option, you can bootstrap a serverless project based on the template available at this location.
For example, here is a CRUDL (Create/Read/Update/Delete/List) microservice archetype. It contains an Amazon DynamoDB table, an API Gateway, and five AWS Lambda functions written in Java (one for each operation):

You must first create a template. Not only an AWS SAM template describing your resources, but also the source code, dependencies and some config files. Using cookiecutter, you can parameterize this template. You add variables surrounded by {{ and }} in files and folders (for example, {{cookiecutter.my_variable}}). You also define a cookiecutter.json file that describes all the variables and their possible values.
In this CRUD microservice, I add variables in the AWS SAM template file, the Java code, and in other project resources:

You then need to share this template either in a Git/Mercurial repository or an HTTP/HTTPS endpoint. Here the template is available on GitHub.
After sharing, anyone within your company can use it and bootstrap a new project with the AWS SAM CLI and the init command:
$ sam init --location git+ssh://git@github.com/aws-samples/java-crud-microservice-template.git
project_name [Name of the project]: product-crud-microservice
object_model [Model to create / read / update / delete]: product
runtime [java11]:
The command prompts you to enter the variables and generates the following project structure and files.

Variable placeholders have been replaced with their values. The project can now be modified for your business requirements and deployed in the AWS Cloud.
There are alternatives to AWS SAM like AWS CloudFormation modules or AWS CDK constructs. These define high-level building blocks that can be shared across the company. Enterprises with multiple development teams and platform engineering teams can also use AWS Proton. This is a managed solution to create templates (see an example for serverless) and share them across the company.
Creating a base container image for Lambda functions
Defining complete application archetypes may be too much work for your company. Or you want to let teams design their architecture and choose their programming languages and frameworks. But you need them to apply a few patterns (centralized logging, standard security) plus some custom libraries. In that case, use Lambda layers if you deploy your functions as zip files or provide a base image if you deploy them as container images.
When building a Lambda function as a container image, you must choose a base image. It contains the runtime interface client to manage the interaction between Lambda and your function code. AWS provides a set of open-source base images that you can use to create your container image.
Using Docker, you can also build your own base image on top of these, including any library, piece of code, configuration, and data that you want to apply to all Lambda functions. Developers can then use this base image containing standard components and benefit from them. This also reduces the risk of misconfiguration or forgetting to add something important.
First, create the base image. Using Docker and a Dockerfile, specify the files that you want to add to the image. The following example uses the Python base image and installs some libraries (security, logging) thanks to pip and the requirements.txt file. It also adds Python code and some config files:
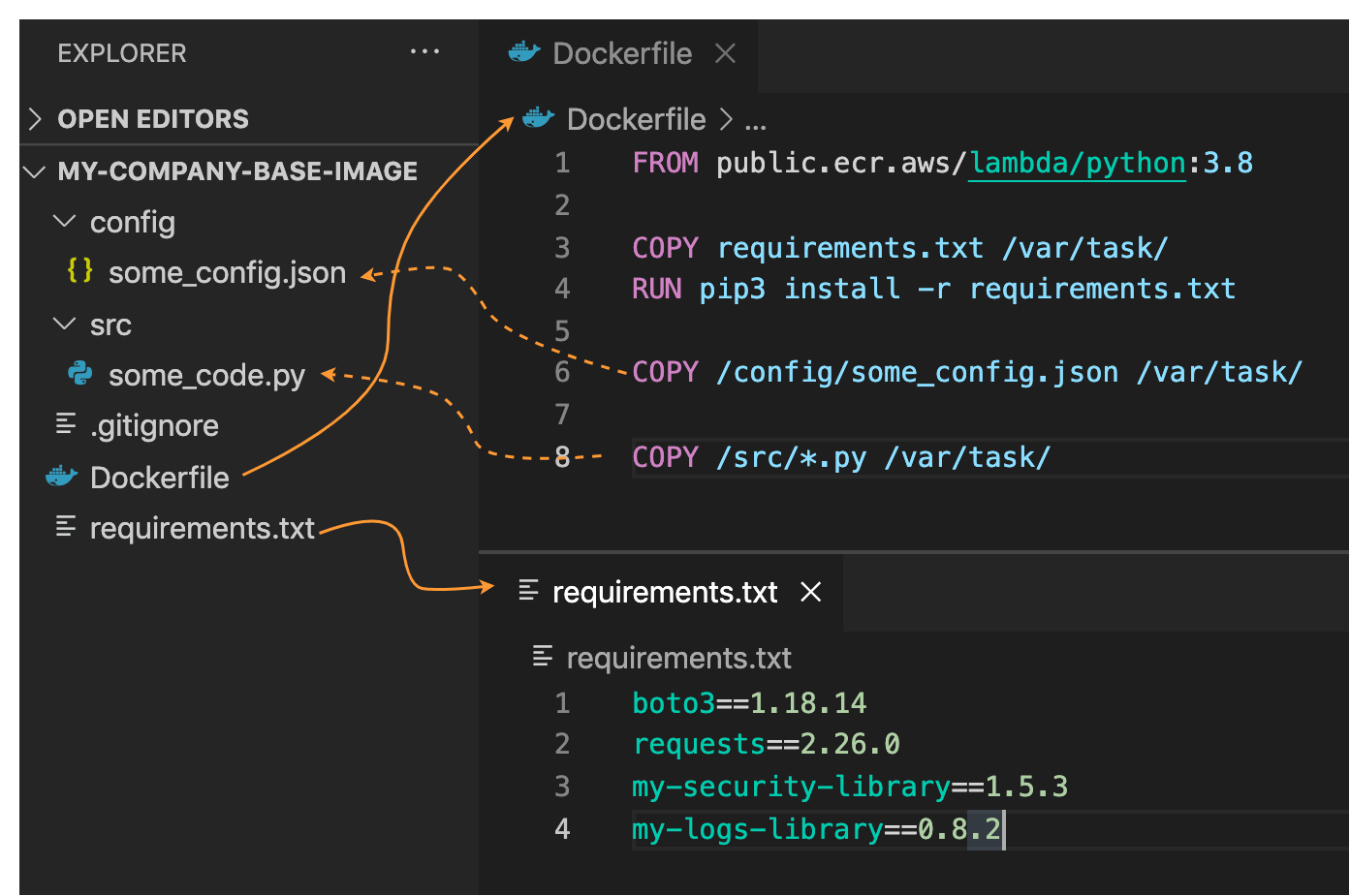
It uses the /var/task folder, which is the working directory for Lambda functions, and where code should reside. Next you must create the image and push it to Amazon Elastic Container Registry (ECR):
# login to ECR with Docker
$ aws ecr get-login-password --region <region> | docker login --username AWS --password-stdin <account-number>.dkr.ecr.<region>.amazonaws.com
# if not already done, create a repository to store the image
$ aws ecr create-repository --repository-name <my-company-image-name> --image-tag-mutability IMMUTABLE --image-scanning-configuration scanOnPush=true
# build the image
$ docker build -t <my-company-image-name>:<version> .
# get the image hash (alphanumeric string, 12 chars, eg. "ece3a6b5894c")
$ docker images | grep my-company-image-name | awk '{print $3}'
# tag the image
$ docker tag <image-hash> <account-number>.dkr.ecr.<region>.amazonaws.com/<my-company-image-name>:<version>
# push the image to the registry
$ docker push <account-number>.dkr.ecr.<region>.amazonaws.com/<my-company-image-name>:<version>The base image is now available to use for everyone with access to the ECR repository. To use this image, developers must use it in the FROM instruction in their Lambda Dockerfile. For example:
FROM <account-number>.dkr.ecr.<region>.amazonaws.com/<my-company-image-name>:<version>
COPY app.py ${LAMBDA_TASK_ROOT}
COPY requirements.txt .
RUN pip3 install -r requirements.txt -t "${LAMBDA_TASK_ROOT}"
CMD ["app.lambda_handler"]Now all Lambda functions using this base image include your standard components and comply with your requirements. See this blog post for more details on building Lambda container-based functions with AWS SAM.
Conclusion
In this post, I show a number of solutions to create and share archetypes or layers across the company. With these archetypes, development teams can quickly bootstrap projects with company standards and best practices. It provides consistency across applications and helps meet compliance rules. From a developer standpoint, it’s a good accelerator and it also allows them to have some topics handled by the archetype.
In governance, companies generally want to enforce these rules. Part 3 will describe how to be more restrictive using different guardrails mechanisms.
Read more information about AWS Proton, which is now generally available.
For more serverless learning resources, visit Serverless Land.