AWS Compute Blog
Using shared memory for low-latency, intra-node communication in AWS Batch
This post is courtesy of Dario La Porta, Senior Consultant, HPC.
AWS Batch enables developers, scientists, and engineers to run hundreds of thousands of HPC jobs in AWS. By managing the provisioning of computing resources, this allows you to focus on your core business. Shared memory support is a new feature that can help improve overall performance.
This post explains the shared memory paradigm and how it can help you improve the performance of your single and multi-node applications. Performance gains can also help you to reduce the total runtime of your jobs and therefore reduce the overall cost.
The second part of the post shows you how to use shared memory in AWS Batch both in the AWS Management Console and the AWS CLI. Finally, I show the performance gains that are made possible with shared memory usage by walking through a benchmarking analysis with OSU Micro-Benchmarks and GROMACS.
Shared memory paradigm
Advanced, compute-intensive workloads require high-performance hardware to use scalability to deliver results. The Amazon EC2 C5n instance type provides cost-efficient, high-performance hardware with a configurable number of cores.
HPC workloads use algorithms that require parallelization and a low latency communication between the different processes. The two main technologies used for the parallel communications are message-passing with distributed memory and shared memory.
Message Passing Interface (MPI) is a message-passing standard used for the communication in a parallel distributed environment. Elastic Fabric Adapter (EFA) enables your MPI applications to use low-latency, inter-node communication.
The shared memory paradigm allows multiple processors in the same system to communicate using a memory (RAM) portion that is shared between the processes. This method takes advantage of the high-speed memory bus.

MPI with intra-node shared memory communication
The two main MPI implementations, OpenMPI and Intel MPI, enable an intra-node shared memory communication in a distributed compute environment. When configured, you take advantage of the EFA libfabic implementation having consistent and reduced latency. This results in higher throughput than the TCP transport for the intra-node communication. From libfabric 1.9 onwards, the shared memory support has been directly added to the EFA provider. You no longer need to perform any modification to the OFI MTL.
MPI jobs in AWS Batch
AWS Batch enables the execution of MPI jobs using a multi-node configuration. First, a job definition is created that enables the execution of the job in multiple nodes. To learn how to create this definition, see Creating a Multi-node Parallel Job Definition.
To take advantage of the EFA capabilities, select a supported instance type and read Leveraging Elastic Fabric Adapter to run HPC and ML Workloads on AWS Batch. This post shows how to create the necessary resources in AWS Batch and run your first job with EFA.
Shared memory in AWS Batch
The new AWS Batch console interface enables you to configure the shared memory of the container inside the Job Definition. To see this, expand the Additional configuration in the Container properties section:
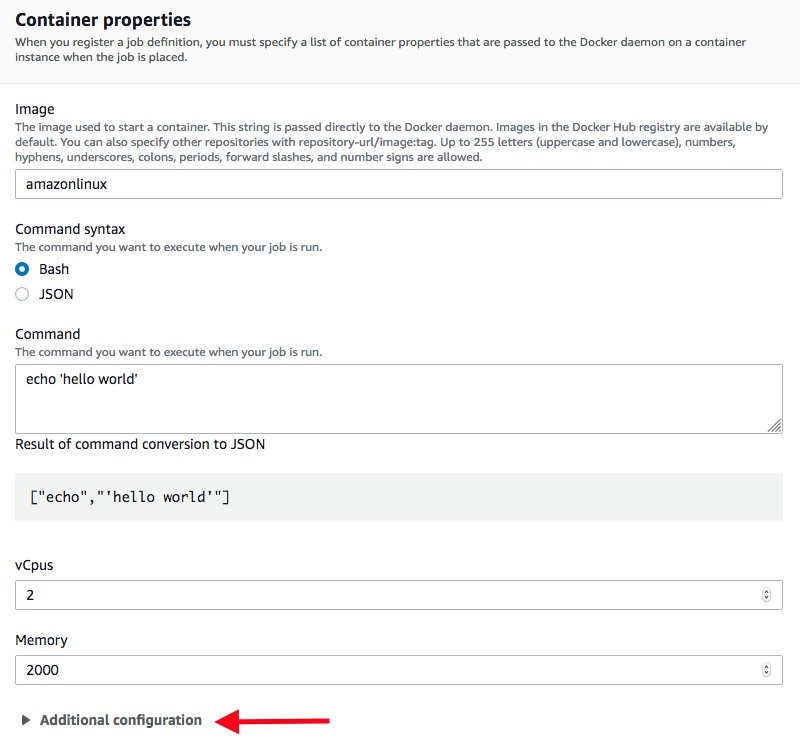
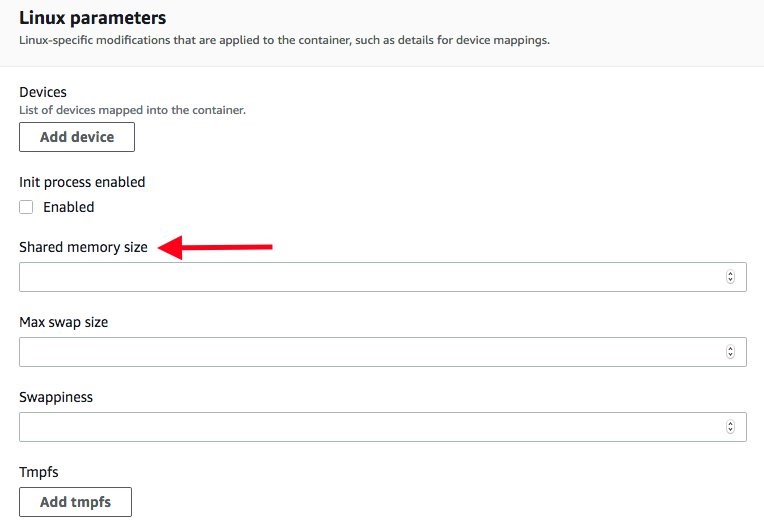
The Linux parameters section contains the Shared memory size parameter in MB.
You can set the same configuration in the AWS CLI by passing JSON parameters to the RegisterJobDefinition API:
"linuxParameters": {
"sharedMemorySize": integer
}When you run the job, it creates a shared memory area on each node that uses two or more processes. The shared memory area cannot be changed during the execution of the job. The size of the shared memory area is determined by the number of cores available in the node and the application requirements. For most jobs, a suggested initial value is 4096 MB.
Modern Linux kernels support a POSIX shared memory API. You can inspect the size of the container shared memory using the df -h /dev/shm command. The output can help you determine the shared memory space needed for your job.
Benchmarks
The following section compares the different performance using shared memory with Intel MPI 2019 update 7 and EFA.
The instance type used for the benchmark is the c5n.18xlarge and, for the multi-node use case, a cluster placement group. This compares the performance increase from shared memory versus using pure EFA communication. The first benchmark focuses on the latency of the communication in a single node use case.
OSU Micro-Benchmarks is a suite of benchmarks for measuring and evaluating the performance of MPI operations. The specific test case used is the osu_latency, measuring the minimum, maximum and average latency of a ping-pong communication between a sender and a receiver. Specifically, this is where the message sender waits for the reply from the receiver. The benchmark uses a variety of data sizes to report the average one-way latency.

The chart shows the latency in μs on the horizontal axis and packet size in bits on the vertical axis. The result shows a decrease in the communication latency using shared memory for the intra-node communication compared with using only EFA. The following chart shows the latency improvement:

The next benchmark demonstrates how shared memory can also increase the performance in a multi-node configuration. The test application is GROMACS, a versatile package to perform molecular dynamics. The overall performance of the application is susceptible to communication latency variance.

The code for the test has been downloaded from the Unified European Applications Benchmark Suite. The specific use case is named lignocellulose-rf and it uses the Reaction field for electrostatics. The details and the download link can be found in the UEABS repository.
The benchmark uses one thread per core and the following mdrun parameters:
-maxh 0.50 -resethway -noconfout -nsteps 10000 -dlb yes -nstlist 100 -pin on
The compilation options and the parameters configuration are explained in the README file. The test is run on a c5n.18xlarge instance, instead of a GPU instance, to focus on measuring the performance improvement caused specifically by increasing the number of total cores of the simulation. The chart explains the performance gain (measure in ns/day) that are achieved by increasing the number of cores. This is possible by using the shared memory for the intra-node communication during the simulation instead of using only EFA networking.
The following chart illustrates a significant percentage performance improvement by using the shared memory:

Conclusion
In this post, I show how the new shared memory support in AWS Batch is able to improve performance while decreasing the latency of the intra-node communication. This performance gain can also lower the cost of running jobs overall.
I show how to enable the usage of the shared memory in AWS Batch from the AWS Management Console or the AWS CLI. I also highlight the performance gain from using shared memory with the high-speed memory bus of the c5n.18xlarge instance, using benchmarking analysis with OSU Micro-Benchmarks and GROMACS.
AWS Batch multi-node parallel jobs are now even more performant with EFA and shared memory configurations, enabling you to focus more on your applications and less on tuning. In addition, the Elastic Fabric Adapter (EFA) has a more consistent latency and higher throughput than the TCP transport for the inter-node communication.
To learn more about using this feature, visit the Getting Started guide.