Containers
Implementing granular failover in multi-Region Amazon EKS
Enterprises across industries operate tens of millions of Amazon Elastic Kubernetes Service (Amazon EKS) clusters annually, supporting use cases from web/mobile applications to data processing, machine learning (ML), generative AI, gaming, and Internet of Things (IoT). As organizations increasingly adopt multi-tenant platform models where multiple application teams share an EKS cluster, they need more granular control over application availability in their multi-Region architectures—particularly for serving global users and meeting strict regulatory requirements.
Although multi-tenant models optimize resource usage and reduce operational overhead, they present challenges when applications need individualized Recovery Point Objective (RPO) and Recovery Time Objective (RTO) targets across multiple AWS Regions. Traditional approaches force uniform failover policies across all applications where a single application’s failure creates an unnecessary compromise between operational efficiency and application-specific resilience.
In this post, we demonstrate how to configure Amazon Route 53 to enable unique failover behavior for each application within your multi-tenant Amazon EKS environment across AWS Regions, which allows you to maintain the cost benefits of shared infrastructure while meeting diverse availability requirements.
Typical architecture
Before diving into the solution, we demonstrate how a typical multi-Region multi-tenant Amazon EKS architecture is structured, and the key components that enable Regional traffic routing. Figure 1 consists of the following key components:
- Route 53
- Routes traffic to the Application Load Balancer (ALB) in the respective Region
- Makes sure of high availability and resiliency during failure events
- AWS Load Balancer Controller
- Exposes applications running on the EKS cluster through ALB
- Uses IP target type to register application Pods to the ALB
The Route 53 configuration details are as follows:
- Regional Routing
- Each AWS Region uses a Route 53 alias record to route traffic to its Region-specific ALB.
- Example:
app1.example.compoints to ALB in Region 1 - Example:
app2.example.compoints to ALB in Region 2
- Example:
- Each AWS Region uses a Route 53 alias record to route traffic to its Region-specific ALB.
- Health monitoring
- “Evaluate target health” feature in alias records:
- Continuously monitor ALB health
- Automatically remove unhealthy ALBs from DNS responses
- “Evaluate target health” feature in alias records:
- Request routing
- Provide routing policies for active-active architecture
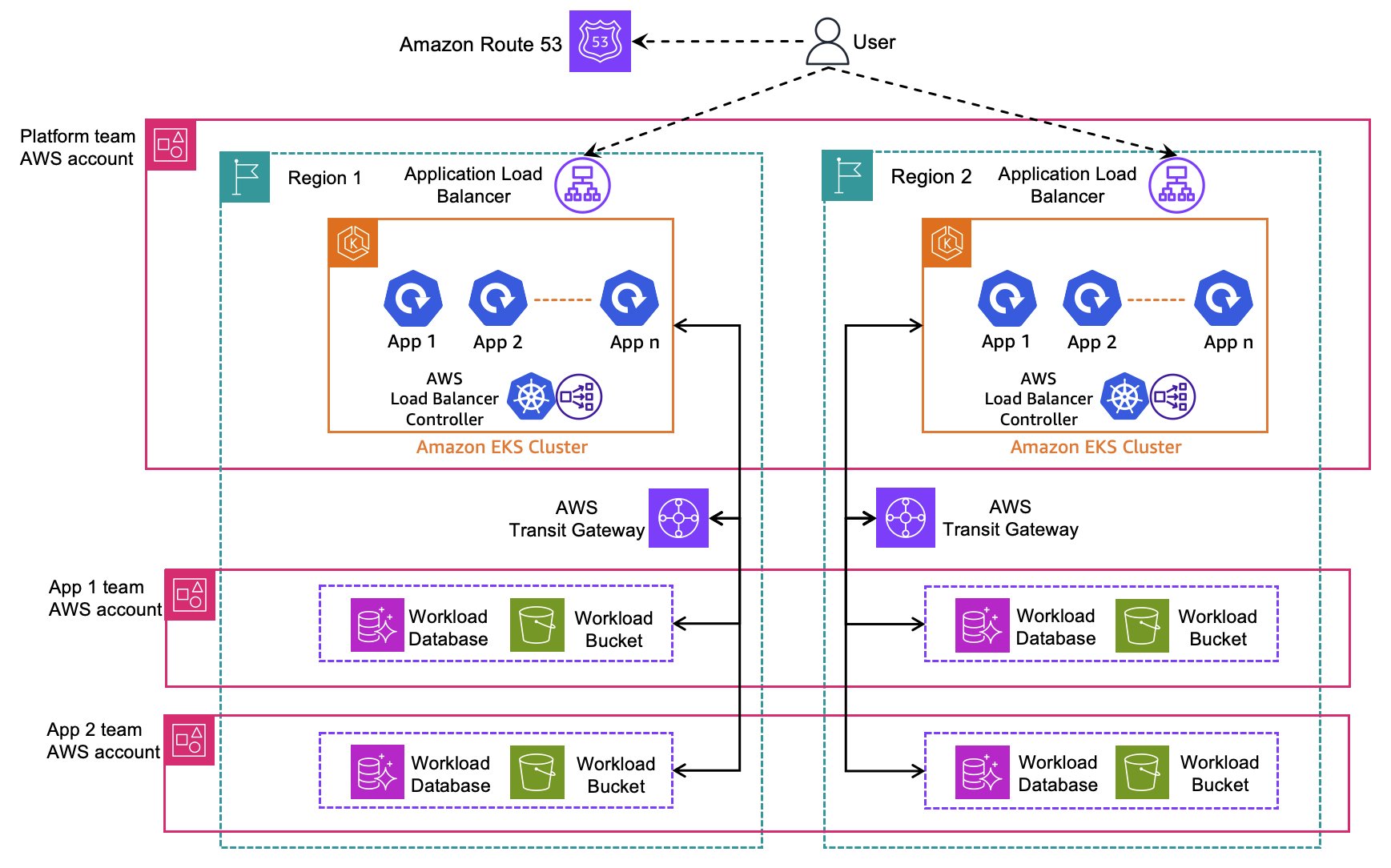
Figure 1: Multi-Region, multi-tenant Amazon EKS platform architecture
The all-or-nothing health check problem
The Route 53 Evaluate target health attribute in alias records continuously monitors the health of the specified ALB target. An ALB is considered healthy only if each of its configured target groups contains at least one healthy target. If any target group becomes unhealthy, then Route 53 marks the entire ALB as unhealthy and removes it from DNS responses, redirecting users to the remaining healthy Region(s).
This reflects the cascading failure effect in multi-tenant environments:
- When one application fails, Route 53 marks the entire ALB as unhealthy
- All traffic redirects to other AWS Region(s), even for healthy applications
- Healthy applications unnecessarily experience increased latency
Consider this example:
app1.example.comfails in Region 1app2.example.comremains healthy in Region 1- Route 53 redirects all traffic to Region 2
- Users of healthy
app2experience unnecessary latency - Healthy applications are impacted by unrelated service failures
This behavior forces users to choose between two sub-optimal options:
- Accept complete Regional failure when any single microservice fails
- Deploy separate ALBs for each microservice, thus increasing both operational complexity and costs
In the following sections, we present a solution that addresses these architectural challenges and provides a more resilient multi-Region deployment model.
Solution overview
To address the challenge, we propose a solution that provides granular failover control at the application level. Figure 2 shows the solution architecture. The solution consists of two key configurations:
- Application-specific health checks
- Configure dedicated Route 53 health checks for each application in each AWS Region
- Associate each health check with the respective Route 53 alias record
- Set Evaluate Target Health to No in alias records
- Granular failover control
- Route 53 monitors application health independently
- During failures, affected application’s traffic is redirected
- Healthy applications continue serving traffic from their original AWS Region
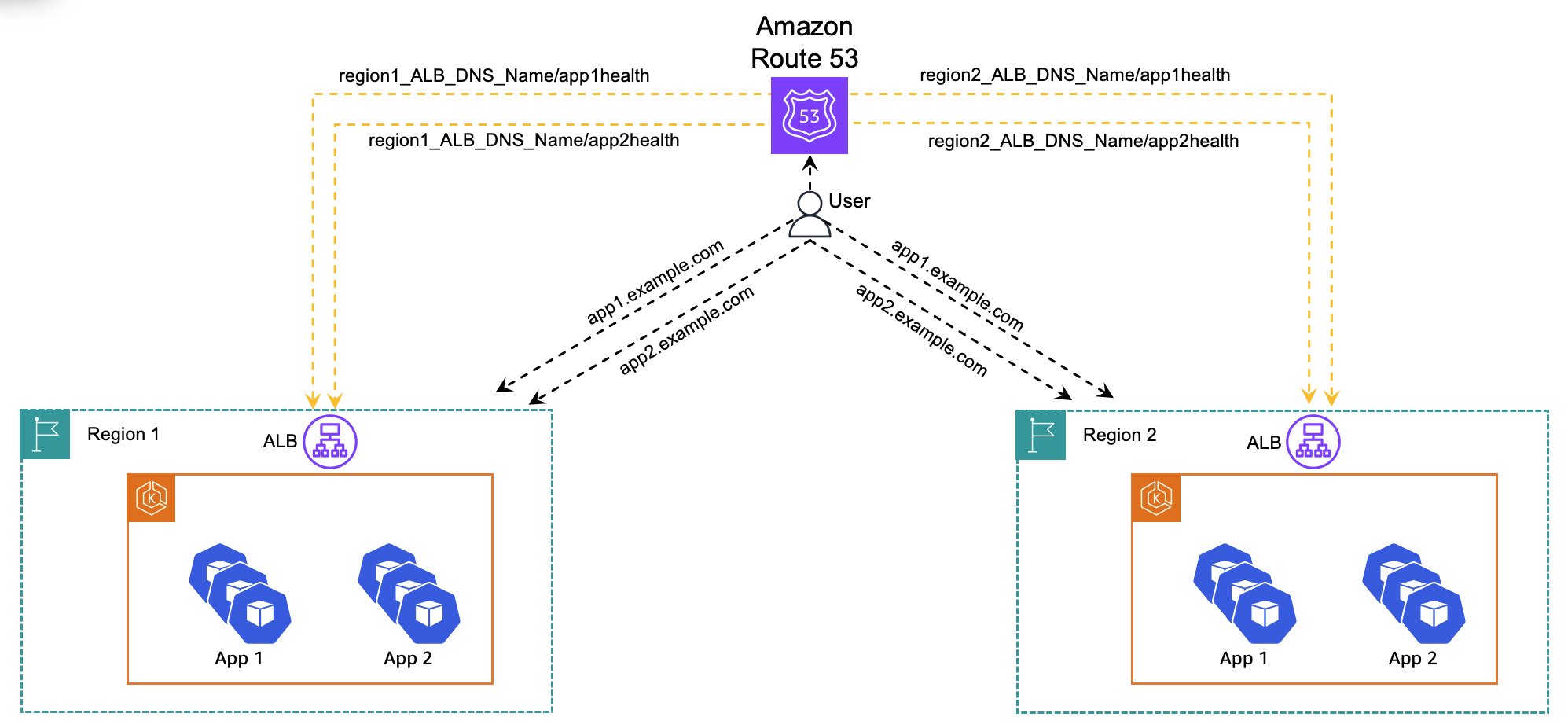
Figure 2: Solution architecture
This architecture provides the following key benefits:
- Enhanced control and monitoring:
- Provides granular monitoring at the application level (target group)
- Eliminates the limitation of monitoring only at the ALB level
- Intelligent failover management:
- Selective failover for individual applications
- Protects healthy applications when a single service fails
- Maintains optimal routing for unaffected services
- Organizations can do the following:
- Maintain multi-tenant cost benefits
- Achieve application-specific resilience
- Meet diverse availability requirements
- Avoid unnecessary cross-Region routing
Prerequisites
The following prerequisites are necessary to complete the solution:
- An AWS account
- An existing public hosted zone in Route 53, or you can register a new domain with Route 53 or use it for an existing domain
- AWS Command Line Interface (AWS CLI)
- eksctl
- kubectl
- kubectx (optional)
- AWS CloudShell (optional)
Walkthrough
The following steps walk you through this solution.
Configure environment variables
Replace the values in the following example with your own values and create the variables.
Create EKS clusters in Region 1 and Region 2
- Create an EKS cluster in Region 1.
- Wait for the cluster state to become
Active. This takes approximately 12 minutes.
- Create an EKS cluster in Region 2.
- Wait for the cluster state to become
Active. This takes approximately 12 minutes.
- eksctl updates your kubeconfig file as it completes the creation of each cluster. Use
kubectlto list the nodes in each cluster. Usekubectxor manually switch between the clusters.
Create IngressClass configuration
- Run the following command to create the IngressClassParams and IngressClass on the cluster in Region 1.
- Verify that the resources are created.
- Repeat Steps 1 and 2 for the cluster in Region 2.
Deploy app1 and app2 on the EKS clusters
- We use a manifest to deploy the applications on the cluster in Region 1. The manifest creates the following:
- a deployment, with a single replica, for each application
- a service for each deployment
- an ingress that forwards http requests to the services
- Verify that the resources are created. You should see two deployments, two services, and an ingress in the output. Confirm that the pod status is
running.
- Repeat Steps 1 and 2 for the cluster in Region 2.
The applications that we deployed are simple web servers that display an HTML page that includes the application name, pod name, AWS Region, and AWS Availability Zone (AZ). We show this as a sample in Figure 3 and Figure 4. We test the access when we define the Route 53 records in the next few steps.

Figure 3: App1 web page

Figure 4: App2 web page
Configure Route 53 health checks for app1 and app2
- Define environment variables for the ALBs created previously.
- Configure the health checks for app1 in Region 1 and Region 2.
- Configure the health checks for app2 in Region 1 and Region 2.
Configure Route 53 alias records for app1 and app2
- Define environment variables for the health checks created earlier.
- Define environment variables for the ALBs’
CanonicalHostedZoneId. We need to use it when creating the alias records in the next steps.
- Create the alias records for app1. In this example we use latency based routing policy in each record.
- Verify that the alias records for app1 are successfully created in the Route 53 hosted zone.
- Create the alias records for app2. In this example we use a latency based routing policy in each record.
- Verify that the alias records for app2 are successfully created in the Route 53 hosted zone.
It may take a while for the DNS to propagate. Therefore, you may not have immediate access to the application domain names (app1.example.com and app2.example.com).
Test application failure
With the configuration now in place, we can examine how the system responds to an individual application failure. Figure 5 illustrates the sequence of events during such a scenario. Under normal conditions, users located in Region 1 are always directed to applications in Region 1 because we created Route 53 alias records that use latency-based routing policy. Let’s assume app1 fails. In that case, users in Region 1 accessing app1 are redirected to Region 2, while users in Region 1 sending requests to app2 continue to be served by app2 in Region 1.
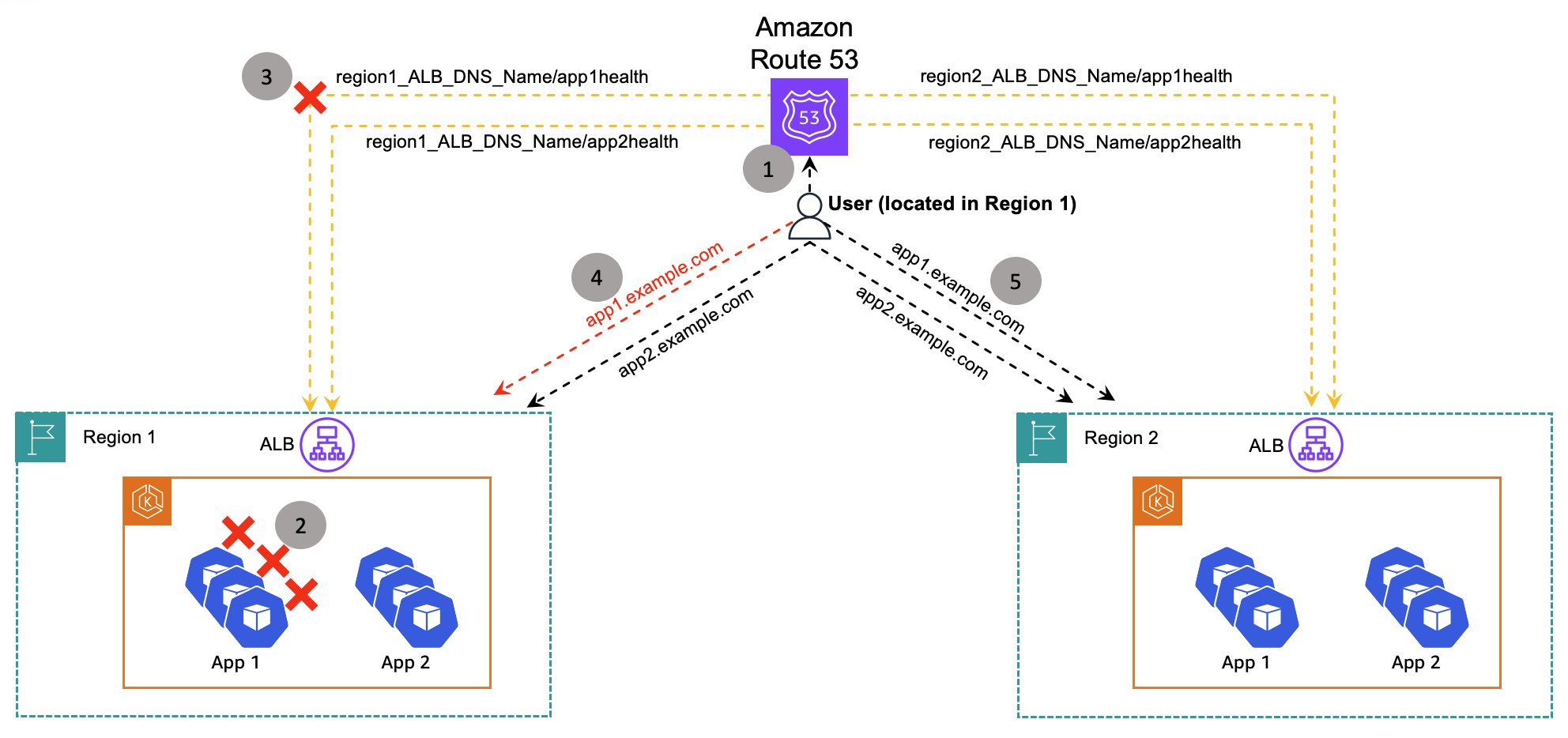
Figure 5: Application failure scenario
The following sequence of events is shown in Figure 5.
- Both health checks are healthy
- App1 workloads fail in Region 1
- Route 53 health check (for app1 in Region 1) becomes unhealthy
- Route 53 withdraws the Region 1 ALB from the DNS responses
- All users are redirected to app1 in Region 2
Validate the behavior shown in Figure 5 by scaling down the deployment for app1 to zero replicas, which simulates an application failure. Use the following command:
We used the default timers in the Route 53 health checks in this scenario. Therefore, it takes several minutes for Route 53 to start redirecting user requests for app1 to Region 2. You can configure more aggressive timers for your use case to provide much quicker failover.
The key differentiator of this approach becomes immediately apparent: the Route 53 application-specific health checks detect only app1’s failure and redirect app1 traffic exclusively to Region 2. Meanwhile, app2 continues serving users from Region 1, maintaining optimal latency for healthy applications.
This selective failover behavior contrasts sharply with traditional ALB-level monitoring, where a single application failure forces all applications to fail over to another Region, unnecessarily impacting performance for healthy services. Our solution makes sure that failure isolation occurs at the application level, not the infrastructure level, providing true granular control in multi-tenant environments.
Things to know
- Each application consumes one rule for the application endpoint and one rule for the healthcheck endpoint on the ALB. Consider the maximum number of rules allowed per ALB when planning.
- When creating an alias record using Route 53 console, Evaluate target health is automatically set to Yes. When using AWS CLI or other tools, you must explicitly set it.
- You must configure Route 53 health checks for each application. Be mindful of the Route 53 health check pricing.
- Route 53 health checkers that are based on HTTPS do not validate SSL/TLS certificates. Therefore, checks do not fail due to invalid or expired certificates.
- Route 53 health checkers can’t monitor endpoints with IP addresses in local, private, non-routable, or multicast ranges. If your application runs in a private subnet, you can implement custom Route 53 health checks using CloudWatch alarms. A custom health check implementation using a Lambda function is demonstrated in this AWS post: Performing Route 53 health checks on private resources in a VPC with AWS Lambda and Amazon CloudWatch.
- The ALB HTTP keepalive duration is crucial for clients to quickly detect failures in multi-tenant environments. For more information, go to Application Load Balancer enables configuring HTTP client keepalive duration.
- This post is not applicable to path based application segregation on the same domain name (for example when app1 is
example.com/app1and app2 isexample.com/app2). - Refer to Configuring DNS Failover to understand how health checks, alias records, and failover work in various scenarios.
- Amazon Application Recovery Controller (ARC) is another AWS service to achieve Regional resiliency. However, ARC is out of scope for this post. For more details, consult the ARC Developer Guide.
Cleaning up
You continue to incur costs until deleting the infrastructure that you created for this post. Use the following commands to delete those resources.
- Delete the EKS clusters using the following commands. eksctl automatically deletes all ELB resources (target groups, ALB, etc.), which are provisioned by ALB Controller as a result of the Kubernetes ingress requests.
- Delete the Route 53 alias records.
- Delete the Route 53 health checks.
- Clean up any other resources that you created as part of the prerequisites if they are no longer needed.
Conclusion
In this post, we demonstrated how to overcome a critical limitation in multi-Region, multi-tenant Amazon EKS architectures: the all-or-nothing failover behavior that impacts healthy applications when a single service fails. Implementing application-specific Amazon Route 53 health checks granted surgical precision in your failover strategy, redirecting only affected applications while maintaining optimal performance for healthy services.
This solution allows you to maintain the cost benefits of shared infrastructure while meeting diverse availability requirements. This eliminated unnecessary cross-Region latency for healthy applications during partial failures.
Ready to enhance your multi-Region resilience further? Consider these next steps:
- Extend health checks beyond basic HTTP responses to monitor business-critical dependencies.
- Integrate with Amazon Application Recovery Controller (ARC) for automated disaster recovery orchestration.
Start by identifying applications in your current setup that benefit most from independent failover behavior—particularly those with different SLA requirements or varying Regional user bases.
For more information, see the following references:
- Amazon EKS Best Practices Guide
- Best Practices for Amazon Route 53
- Designing for high availability and resiliency in Amazon EKS applications
About the authors
 Dumlu Timuralp is a Senior Solutions Architect with AWS based in the United Kingdom. In this role he provides architecture guidance on cloud migration, application modernization and cloud native patterns. He loves working with users and meet their business needs with technology.
Dumlu Timuralp is a Senior Solutions Architect with AWS based in the United Kingdom. In this role he provides architecture guidance on cloud migration, application modernization and cloud native patterns. He loves working with users and meet their business needs with technology.
 Pratik Mankad is a Network Solutions Architect at AWS. He is passionate about network technologies and loves to innovate to help solve user problems. He enjoys architecting solutions and providing technical guidance to help users and partners achieve their technical and business objectives.
Pratik Mankad is a Network Solutions Architect at AWS. He is passionate about network technologies and loves to innovate to help solve user problems. He enjoys architecting solutions and providing technical guidance to help users and partners achieve their technical and business objectives.