Containers
Using Amazon EMR on Amazon EKS for transient EMR clusters
Introduction
Many organizations as part of their cloud journey into Amazon Web Services migrate and modernize their ETL (extract-transform-load) batch processing workloads running on on-premises Hadoop clusters to AWS. They often start their journey with the lift and shift approach, by hosting their Hadoop environment on Amazon Elastic Compute Cloud (Amazon EC2) or migrate to Amazon EMR. The latter is a fully managed Hadoop solution that provides the same set of tools and features they are used to running on premises. To take advantage of cloud native storage and compute, organizations modernize their Amazon EMR clusters to move their data to Amazon Simple Storage Service (Amazon S3) and run their jobs on spark framework.
The Amazon EMR’s ability to provision Amazon EMR clusters on demand, paved the way for transient clusters that could optimize costs, operational overheads, and flexibility in selection of Hadoop services needed for each workload. Customers spin clusters up and down based on the nature of the workload, size of the workload, and the ETL schedule. A transient cluster has its own set of challenges including, higher boot-up times and steps to preserve job history and logs.
Organizations are reaping the benefits of Amazon Elastic Kubernetes Service (EKS), which is a fully managed service for Kubernetes. Spark on Kubernetes opens up a new approach for containerization and distributed computing. Amazon EMR on Amazon EKS (i.e., EMR on EKS) provides the best of both worlds and solves some of the challenges created by transient clusters running spark jobs.
Enterprise data workloads comprise thousands of spark jobs grouped into batches that run on multiple schedules and ad hoc cycles based on the business needs and environment. Each batch run can translate into a transient cluster with added configuration for boot up time, resource management (e.g., compute node types, auto scaling, and software bundle), and jobs and log history management. Data engineers, data scientists, and data analysts sought a solution that provides the ability to submit spark jobs to an Amazon EMR cluster without being dependent on operational requirements and dependencies. EMR on EKS provides this common compute platform by containerizing the spark workloads.
This blog will walk you through how to use EMR on EKS to migrate from transient clusters to a common compute platform. On this platform, you can submit jobs to virtual clusters and EMR on EKS manages the compute resources.
Amazon EMR on Amazon EC2 transient clusters
This blog demonstrates an enterprise scenario as shown in the following diagram, five types of batches running spark jobs that execute on a different frequency and different priority. The following diagram describes the current batch design with Amazon EMR transient cluster.
The following solution architecture presents an overview of the solution:
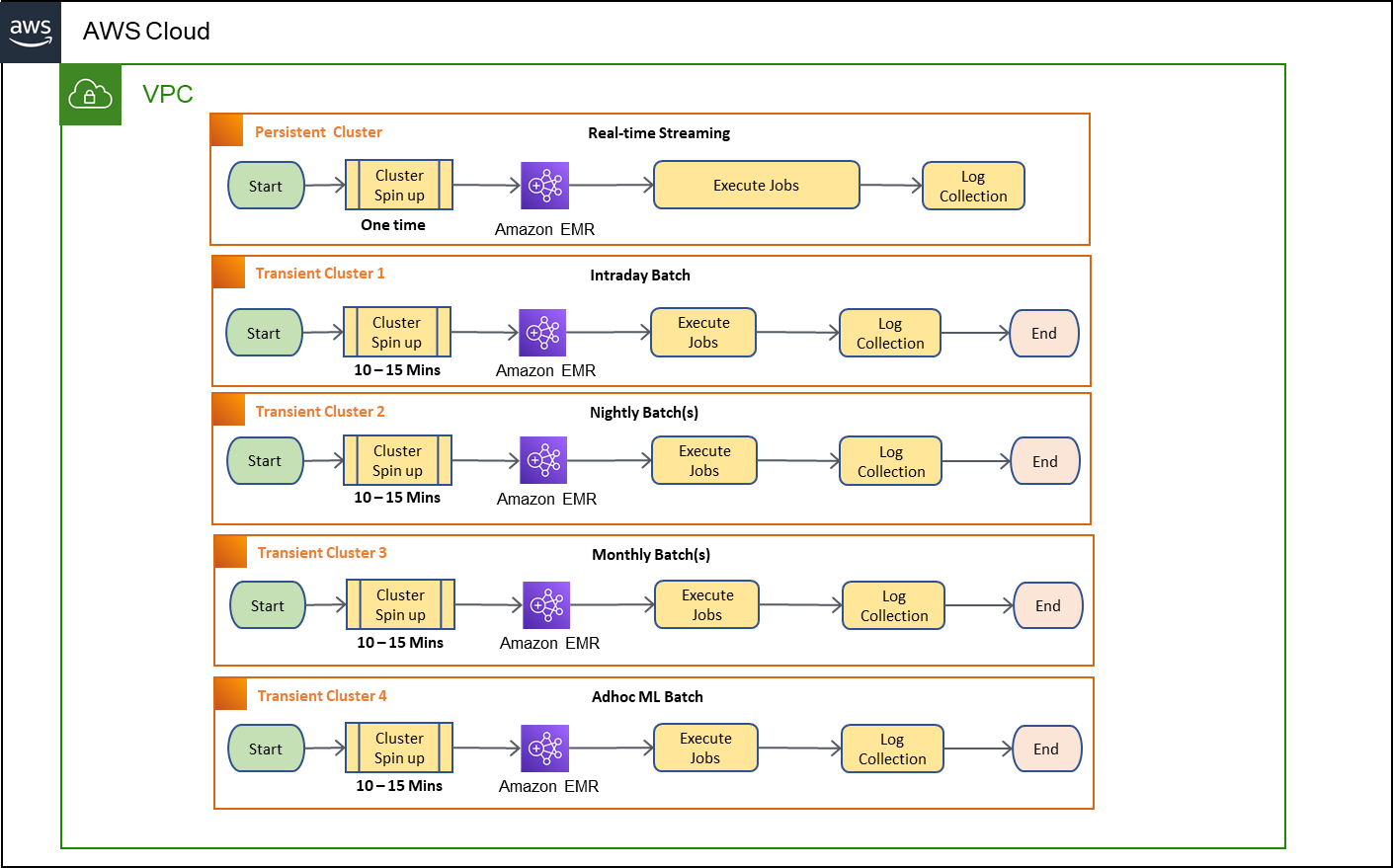
The following steps describe the solution workflow:
- Real-time streaming: Streaming jobs that need a high degree of attention and quick turnaround time.
- Intra-day batch: Jobs with multiple daily runs with a predicted completion time.
- Nightly batch: Jobs processed after business hours.
- Monthly batch: Jobs processed toward the end of each month, which requires a larger processing window.
- Ad hoc Machine Learning (ML) batch: Large ML training jobs with specific compute requirements (e.g., graphics processing unit [GPU]).
To accomplish the previous scenario, enterprise organizations spin up a transient cluster for each type of batch on the desired frequency and spins down on batch completion. The usage of transient EMR clusters will introduce few constraints and limitations that needs to be considered. Some of them are listed below:
- Multiple Amazon EMR cluster management.
- Capacity availability during aggressive scaling scenarios in single availability zone (AZ – Each Region has multiple, isolated locations known as Availability Zones) with Amazon EMR.
- 10–15 minutes average boot up time.
- Additional steps required for history and log preservation.
- Multi-master node management overhead for workloads that need high availability.
Solution Overview with Amazon EMR on Amazon EKS
Amazon EMR on EKS is a deployment option in Amazon EMR that allows you to automate the provisioning and management of open-source big data frameworks on Amazon EKS clusters. There are several advantages of running optimized spark runtime provided by Amazon EMR on Amazon EKS, which include: 3x faster performance, fully managed lifecycle, built-in monitoring and logging functionality, integrates securely with Kubernetes, and additional benefits. For more details, please review documentation.
About the solution
The following diagram illustrates the proposed batch design with EMR on EKS:
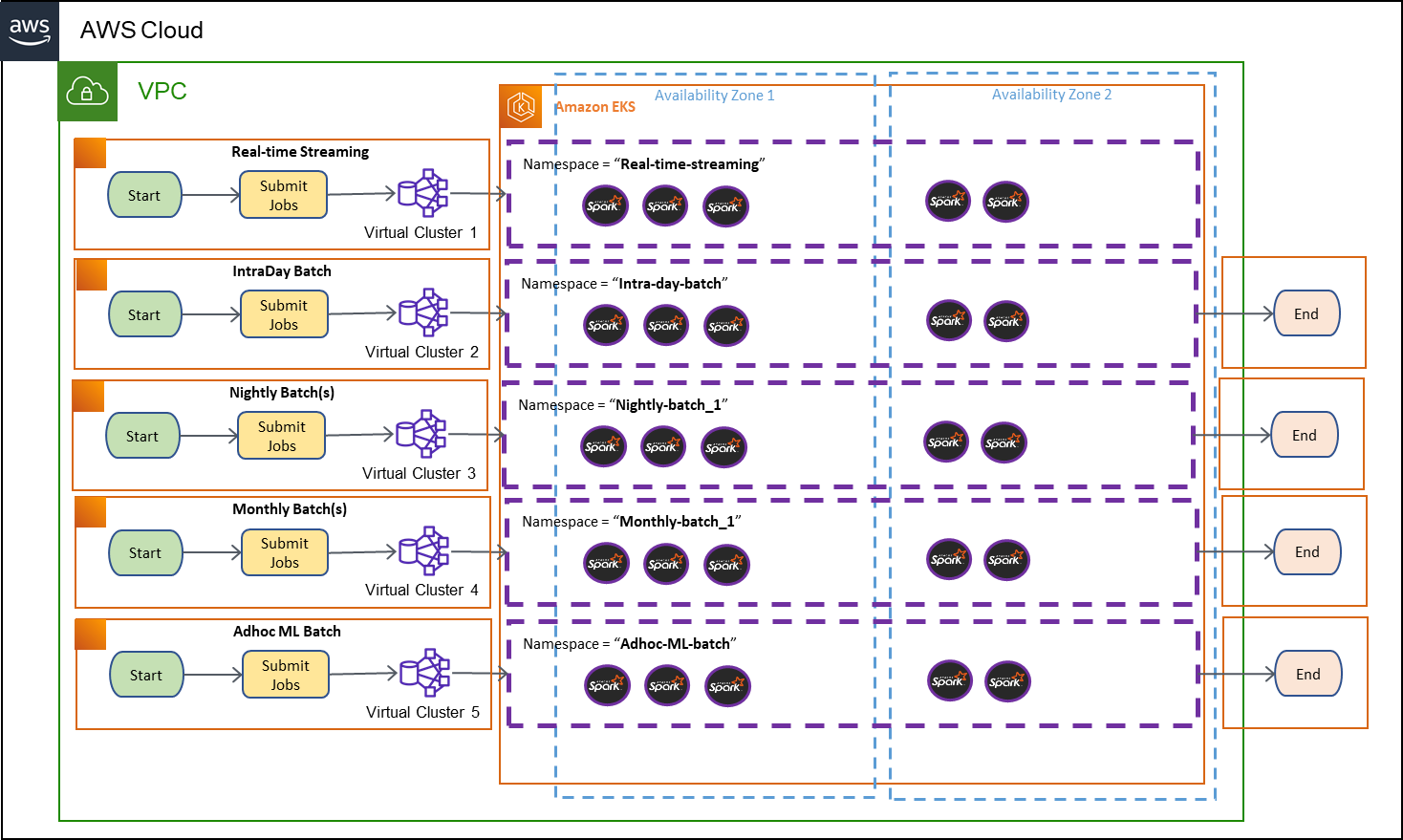
The solution presented in the preceding diagram replaces transient Amazon EMR clusters with Amazon EMR virtual clusters linked to a Single Amazon EKS cluster as a shared compute platform using EMR on EKS.
The key architectural and operational changes are described below:
- Amazon EMR virtual clusters remain active, which eliminates the need to spin up and spin down the cluster for every batch execution.
- Single Amazon EKS cluster remains active with Amazon EKS quick autoscaling capabilities.
- Job history and logs are preserved even after the completion batch execution.
- Logs can be stored on Amazon S3 natively for long term preservation.
- Yarn resource manager is replaced by Kubernetes.
- Spark jobs are containerized and executed as Kubernetes jobs.
- Flexibility to manage toolset and versions at a job level instead of cluster level.
- Job-level Identity and Access Management (IAM) permission control.
- Amazon EKS multi-AZ capability provides resiliency with wider resource capacity.
- Quick autoscaling with Karpenter.
Design differences to consider migrating to EMR on EKS
Log Management
Amazon EMR on Amazon EC2 transient clusters logs and job history are accessible via spark history and are stored by default on the master node and viewed from the console while the cluster is running. Prior to spinning off the cluster, all the logs must be copied to Amazon S3 for retention to prevent deletion once the cluster is terminated.
On EMR on EKS virtual clusters, the logs and job history are accessible via spark history server similar to Amazon EMR on Amazon EC2 transient clusters. In addition, logs are managed at a job level and can route to both Amazon CloudWatch and Amazon S3. Amazon CloudWatch logs are used for short term log retention and analysis of reactive triggers by extending Amazon CloudWatch native notification features. In contrast, Amazon S3 is used for low cost, long term, and reliable log storage solution. In addition to these built-in options, EMR on EKS provides the options to ship the logs to other locations (e.g., Amazon OpenSearch Service or third party applications like Splunk or custom locations) by using pod templates and a side car approach. With Amazon EMR 6.3.0 and later, you can turn on the Spark event log rotation feature for EMR on EKS. Instead of generating a single event log file, this feature rotates the file based on your configured time interval and removes the oldest event log files.
An example log configuration to Amazon CloudWatch and Amazon S3 at job level is shown:
Job Monitoring
Amazon EMR on Amazon EC2 provides several tools you can use to gather information about your transient clusters. You can access information about the cluster from the console, the command-line interface (CLI) or programmatically. The standard Hadoop web interfaces and log files are available on the master node. You can also use monitoring services, such as Amazon CloudWatch and Ganglia, to track the performance of your cluster while its running. The spark jobs can be monitored via the history server prior to spinning off the cluster and the logs are copied to Amazon S3 for retention.
EMR on EKS provides detailed resource monitoring to the pod level, using the native Kubernetes features. Job submissions from Amazon EMR virtual clusters are translated as job on Amazon EKS, which in turn, creates primary/driver and executor pods. These jobs and pods are monitored with Kubernetes native monitoring mechanisms (e.g., CloudWatch Container Insights and Prometheus and Grafana). For improved reactive controls, EMR on EKS uses the status-based event triggers with Amazon CloudWatch and all the access logs are monitored via Amazon CloudWatch trail logs for optimized security.
Auto Scaling
Amazon EMR on Amazon EC2 versions 5.30.0 and later (except for Amazon EMR 6.0.0), you can enable Amazon EMR-managed scaling. Managed scaling lets you automatically increase or decrease the number of instances or units in your cluster based on your workload. Amazon EMR continuously evaluates cluster metrics to make scaling decisions that optimize your clusters for cost and speed. Managed scaling is available for clusters composed of either instance groups or fleets. Older versions support automatic scaling with a customized policy for instance groups.
EMR on EKS natively supports autoscaling with Kubernetes Cluster Autoscaler or Karpenter. By using The Kubernetes Cluster Autoscaler, Amazon EKS provides horizontal auto scaling relying on EC2 Auto Scaling groups. Kubernetes Cluster-Autoscaler has some limitations (e.g., the capacity to be added or removed in the cluster) that you can’t use mixed-size clusters in an auto scaling group. Consequently, you end up with multiple different-sized autoscaling groups and relying on Cluster-Autoscaler timeouts to fallback one to the others. With Karpenter, you don’t need to create dozens of node groups to achieve the flexibility and diversity. Karpenter talks directly to the Amazon EC2 fleet application programming interface (API) and can directly choose the correct instance types, based on the pods’ specifications to achieve quick auto scaling. Karpenter provision nodes based on workload requirements, can binpack pods into a minimum number of appropriately sized nodes, and provides cost savings. In this solution, we show how to use Karpenter for your EMR on EKS clusters.
An example karpenter provisioner, which has specific requirements instance types (AZ) and capacity types is shown:
Job Dependency
In Amazon EMR on Amazon EC2 transient cluster, each cluster is built with a set of tools along with a specific version of Spark. Any additional custom packages can be added in two ways. They can be added as part of the boot strapping process by specifying an Amazon S3 location, Amazon EMR will install the packages as part of the cluster creation or the packages can be bundled as a custom Amazon Machine Images (AMI) to spin up the cluster. In other words, a cluster is dedicated for a specific set of tools and custom packages. If the team needs to tryout a different version of spark or a different set of custom packages, they need multiple cluster(s) for each variant.
In EMR on EKS clusters, the difference is its job-centric approach. With this approach you can specify the versions and tool set as part of job definition, rather than as a cluster. This gives you the freedom to use the same cluster with multiple variations of tool sets. Any custom packages can be added as custom Docker images for Amazon EMR on EKS and are fine-tuned for better performance and portability by packaging into a single image. Two jobs on the same cluster can run with a different spark versions and custom images. Custom images can be useful to integrate with existing pipelines and increase the security posture by establishing container security practices (e.g., image scanning) and helps to meet the compliance requirements.
Example custom image with boto3, pandas and numpy on emr-6.6.0 base version:
Build, tag and push this image to your repository:
Submit the job with additional spark parameter as part of job:
Multi-tenancy
Amazon EMR on Amazon EC2 provides multi-tenancy by submitting a different set of spark jobs on the same cluster. However, as explained in the Job Dependency section above, all jobs run on the same set of pre-installed tool sets and packages.
EMR on EKS virtual clusters share the same Amazon EKS computing platform with limited resources. Scenarios where jobs need to be prioritized and executed in a time-sensitive manner, can be prioritized over others with this platform. The high-priority jobs use the resources and finish the job, while low-priory jobs either get suspended or wait to start until the resources are available. In circumstances where a high-priority job is submitted during the low-priority jobs, EMR on EKS can suspend and hold low-priority jobs by evicting running pods and resuming them later based on resources availability. In this manner, low-priority jobs efficiently resume by giving way to time-sensitive jobs. EMR on EKS achieves this with the help of Pod Templates, where you specify a Pod Priority Classes for a given job.
The Pod Priority Class example shows a high-priority class defined with a value of 200. One important detail of this class is that the higher the value, the higher the priority:
An example cluster with priority class tiers:

The Pod Template is designed for ON_DEMAND capacity for high-priority jobs. Similarly, we configure low-priority jobs with SPOT to optimize the cost:
Resiliency and Capacity
Amazon EMR on Amazon EC2 supports single AZ deployments with the option of deploying a multi-master configuration within the same AZ. Transient clusters spin up based on a batch’s time and frequency. The cluster spin-up process must manage AZ failure and Amazon EC2 capacity availability depending on the size of the cluster.
EMR on EKS supports multi-AZ configurations and provides high availability and a wider pool of Amazon EC2 capacity across multiple AZs. This simplifies the job submission process for the end-users of the cluster. EMR on EKS provides the option to choose specific AZ for provisioning pods, if required. The node selector feature of pod templates helps spark driver and executor pods to choose specific nodes based on the attached labels. Node default labels include AZ, node types, and capacity types. Custom labels can also be attached.
An example job configurations for the AZ selection:
An example template configuration for node selection:
Solution benefits
- Performance: The transient Amazon EMR cluster can take up to 10–15 minutes to instantiate in preparation to submit jobs. In contrast, EMR on EKS eliminates the cluster instantiation time and submits job immediately.
- Cost optimization: Transient Amazon EMR clusters are designed based on the size and time needed to process the data. which can lead to an oversized cluster, based on Amazon EC2 node count and types. By using Amazon EMR on Amazon EKS allows you to optimize costs by:
- Daily reduction of transient cluster instantiation.
- Improved utilization of resources like central processing unit (CPU) and memory using container-based spark executors.
- Faster autoscaling capabilities by using Karpenter on Amazon EKS compare to Amazon EMR’s Amazon EC2 based autoscaling.
- Using custom images at job level, eliminates the need to create individual clusters for each set of spark versions and tools.
- Operational efficiency: EMR on EKS virtual clusters provides same capabilities of persistent EMR cluster, this eliminates the need for:
- Cluster lifecycle management overheads on a daily basis.
- Log shipping and retention overheads (i.e., logs can be natively transferred to Amazon S3 (for long term retention) and uses Amazon CloudWatch for metric analysis.
- A separate process for preserving job history due to recycling Amazon EMR transient clusters.
- Security: Amazon EMR on EKS provides fine-grain security controls using job-level IAM control versus cluster-level access on Amazon EMR.
- Reliability: Amazon EMR on EKS containerized approach helps to:
- Eliminate the need for a multi-master and multi-AZ Amazon EMR cluster with pod-level fault tolerance on Amazon EKS.
- Achieve higher resiliency, even with single-AZ deployment.
- Prioritize pods on a shared Amazon EKS cluster, by securing shared resource for time-sensitive jobs.
Solution deployment
The solution, as shown in the Amazon EMR on Amazon EC2 transient clusters section, can be implemented with help of AWS Samples – GitHub.
Prerequisites
Make sure you complete the prerequisites before proceeding with this solution:
- An AWS Account with valid AWS credentials
- AWS Command Line Interface (CLI)
- Kubernetes CLI – kubectl
- EKS CLI – eksctl
- Helm chart
- jq
Conclusion
We showed you how to use the transient Amazon EMR clusters for batch workloads and the challenges associated with this approach. This blog provided an efficient approach that uses the benefits of containerization by running spark on Kubernetes. Amazon Web services provides more managed experience with the help of Amazon EMR on Amazon EKS. By using the key features of both Amazon EMR and Amazon EKS, you experience Amazon EMR with the extended capabilities of Amazon EKS. This blog provided the benefits of this approach through the lens of AWS well-architected pillars.