AWS Database Blog
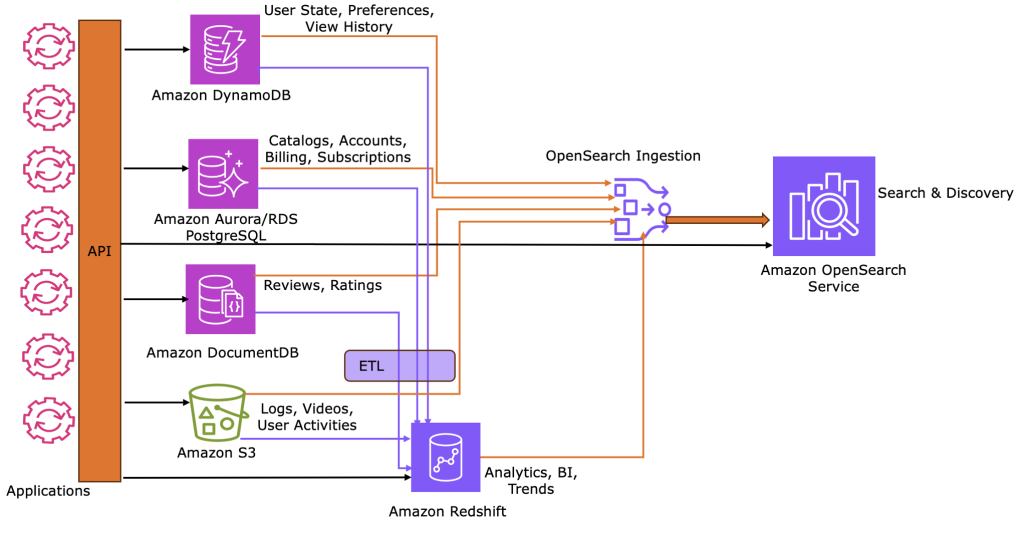
How to build unified JSON search solutions in AWS
Using a movie streaming reference architecture, this post shows how to implement and sync operational, analytical, and search JSON workloads across AWS services. This pattern provides a scalable blueprint for any use case requiring multi-modal JSON data capabilities.

Monitor custom database metrics in Amazon RDS for SQL Server using Amazon CloudWatch
In this post, we demonstrate how to create custom Amazon RDS for SQL Server CloudWatch metrics. You accomplish this by using SQL Server Agent jobs and CloudWatch Logs integration. We walk through an example of monitoring table size within a SQL Server database however, this approach works for various other metrics. You can adapt this approach to track row counts, database size, job counts, user sessions, or other metrics.

PostgreSQL logical replication: How to replicate only the data that you need
In this post, we show how logical replication with fine-grained filtering works in PostgreSQL, when to use it, and how to implement it using a realistic healthcare compliance scenario. Whether you’re running Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL, or a self-managed PostgreSQL database on an Amazon EC2 instance, the approach is the same.

Navigating backup and recovery options for Oracle Database@AWS
Oracle Database@AWS (ODB@AWS) delivers Oracle Exadata infrastructure, managed by Oracle Cloud Infrastructure (OCI), directly within Amazon Web Services (AWS) data centers. In this post, we walk you through the backup and recovery options available for ODB@AWS services: Oracle Exadata Database Service on Dedicated Infrastructure (ExaDB-D) and Oracle Autonomous AI Database on Dedicated Exadata Infrastructure (ADB-D).

Optimize full-text search in Amazon RDS for MySQL and Amazon Aurora MySQL
In this post, we show you how to optimize full-text search (FTS) performance in Amazon RDS for MySQL and Amazon Aurora MySQL-Compatible Edition through proper maintenance and monitoring. We discuss why FTS indexes require regular maintenance, common issues that can arise, and best practices for keeping your FTS-enabled databases running smoothly.

Working with identity columns and sequences in Aurora DSQL
Amazon Aurora DSQL now supports PostgreSQL-compatible identity columns and sequence objects, so developers can generate unique integer identifiers with configurable performance characteristics optimized for distributed workloads. In distributed database environments, generating unique, sequential identifiers is a fundamental challenge: coordinating across multiple nodes creates performance bottlenecks, especially under high concurrency workloads. In this post, we show you how to create and manage identity columns for auto-incrementing IDs, selecting between identity columns and standalone sequence objects, and improving cache settings while choosing between UUIDs and integer sequences for your workload requirements.

Stream live data from Amazon Keyspaces to S3 vector for real time AI applications
In this post, you learn how to build a real-time AI movie recommendation system by streaming live data changes from Amazon Keyspaces to Amazon S3 vector storage. The post shows how to use Keyspaces change data capture streams to capture database modifications, convert them into vector embeddings using Amazon Bedrock, and store them in S3 Vector indexes for similarity searches that give AI applications access to fresh data within milliseconds.

Turbocharge your applications with Amazon DocumentDB 8.0
Amazon DocumentDB 8.0 brings in support for MongoDB 8.0 API driver compatibility while maintaining support for applications built using MongoDB API versions 6.0 and 7.0. This post explores the new features in Amazon DocumentDB 8.0 and demonstrates how they improve performance and cost efficiency.

Conversational Oracle EBS operations with CloudWatch MCP and Kiro CLI
In this post, you learn how to implement conversational operations for Oracle E-Business Suite (Oracle EBS) on AWS by connecting Kiro CLI with your monitoring infrastructure through the MCP. We walk through the technical architecture that enables natural language queries to retrieve CloudWatch metrics, analyze logs, and execute operational commands.

Migrating to Amazon ElastiCache for Valkey: Best practices and a customer success story
In this post, we provide a guide to migrating from Redis OSS to ElastiCache for Valkey, incorporating different migration strategies and AWS best practices. Additionally, we highlight a customer’s successful migration to Valkey, which maintained their robust performance standards while achieving a 20% reduction in ElastiCache cluster costs.