AWS Database Blog
Category: RDS for SQL Server

Converting an RDS for SQL Server instance from license included to Bring Your Own Media (BYOM)
Amazon RDS for SQL Server recently launched Bring Your Own Media (BYOM), so you can use your existing SQL Server licenses with fully managed RDS instances. This is particularly valuable if you have existing Microsoft licensing agreements and want to optimize your cloud spending by using those investments on AWS. If you’re already running RDS for SQL Server with the license-included (LI) model, you can now convert those instances to BYOM in place, no database migration required. In this post, we walk you through the end-to-end conversion process: preparing your installation media, creating a BYOM engine version, and performing the in-place license model change.

Unlock license mobility with Bring Your Own Media on fully managed Amazon RDS for SQL Server
In this post, you learn how to upload your SQL Server installation media to Amazon Simple Storage Service (Amazon S3) and launch a BYOM instance.

Building agentic AI for Amazon RDS for SQL Server with Strands and AgentCore
In this post, we walk through building an agent that investigates blocking and deadlocks on Amazon RDS for SQL Server — two issues that directly impact application performance, cause transaction failures, and lead to user-facing timeouts. Using the Strands Agents framework, we convert the T-SQL queries DBAs already use for these investigations into agent tools, combine them into a single agent, and deploy it to AgentCore Runtime.

Improving storage with additional storage volumes in Amazon RDS for SQL Server
As SQL Server workloads grow on Amazon Relational Database Service (Amazon RDS) for Db2, the 64 TiB storage limit can force architectural issues that constrain business growth and create performance bottlenecks when transaction logs compete with data for I/O resources. The additional storage volumes feature in Amazon RDS for SQL Server solves these challenges. You can use Amazon RDS for SQL Server to attach additional storage volumes beyond the root volume, with each volume having different storage classes and performance characteristics. In this post, you will learn how to use the additional storage volumes feature in Amazon RDS for SQL Server to address these common challenges.

Monitor custom database metrics in Amazon RDS for SQL Server using Amazon CloudWatch
In this post, we demonstrate how to create custom Amazon RDS for SQL Server CloudWatch metrics. You accomplish this by using SQL Server Agent jobs and CloudWatch Logs integration. We walk through an example of monitoring table size within a SQL Server database however, this approach works for various other metrics. You can adapt this approach to track row counts, database size, job counts, user sessions, or other metrics.

From bottlenecks to breakthroughs: Dutchie’s database migration journey
Dutchie, a leading technology platform serving the cannabis industry, manages critical operations for thousands of dispensaries across multiple states, processing millions of transactions annually. In this post, we explore how Dutchie successfully navigated the challenges of migrating mission-critical workloads to Amazon RDS for SQL Server in preparation for 4/20 week in 2025.

Essential tools for monitoring and optimizing Amazon RDS for SQL Server
In this post, we demonstrate how you can implement a comprehensive monitoring strategy for Amazon RDS for SQL Server by combining AWS native tools with SQL Server diagnostic utilities. We explore AWS services including AWS Trusted Advisor, Amazon CloudWatch Database Insights, Enhanced Monitoring, and Amazon RDS events, alongside native SQL Server tools such as Query Store, Dynamic Management Views (DMVs), and Extended Events. By implementing these monitoring capabilities, you can identify potential bottlenecks before they impact your applications, optimize resource utilization, and maintain consistent database performance as your business scales.
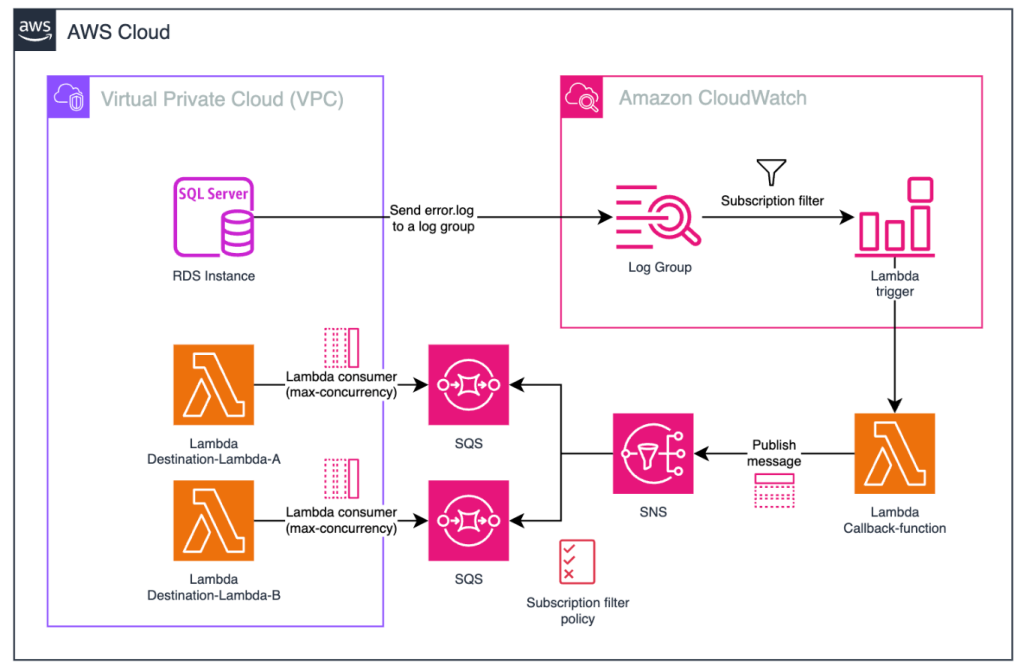
Trigger AWS Lambda functions from Amazon RDS for SQL Server database events
The ability to invoke Lambda functions in response to Amazon RDS for SQL Server database events enables powerful use cases such as triggering automated workflows, sending real-time notifications, calling external APIs, and orchestrating complex business processes. In this post, we demonstrate how to enable this integration by using Amazon CloudWatch subscription filters, Amazon SQS, and Amazon SNS to invoke Lambda functions from RDS for SQL Server stored procedures, helping you build responsive, data-driven applications.
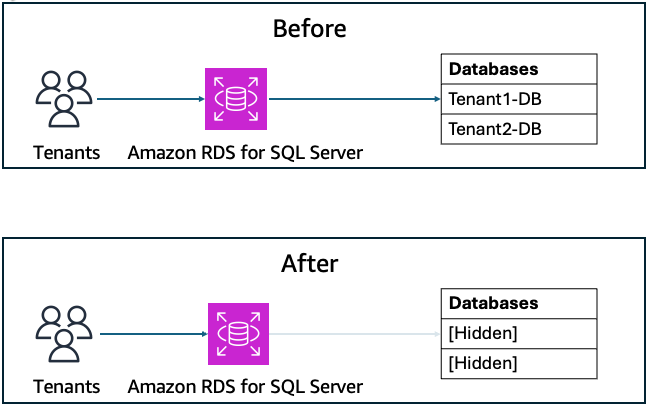
Control database name visibility in Amazon RDS for SQL Server instances
In Amazon Relational Database Service (Amazon RDS) for SQL Server, database visibility is configured using a dedicated stored procedure. In this post, we demonstrate tenant isolation at the visibility level, preventing tenants from seeing database names belonging to other customers while maintaining their access to their own resources. This solution addresses an important architectural consideration in multi-tenant SQL Server environments where database names might reveal tenant information. By using the Amazon RDS for SQL Server custom stored procedure msdb.dbo.rds_manage_view_db_permission, users can effectively control database visibility on a per-login basis while maintaining full application functionality.

Configure Optimize CPU on Amazon RDS for SQL Server
Amazon Relational Database Service (Amazon RDS) for SQL Server now offers the Optimize CPU feature, which enabled control over vCPU allocation through core count modification setting. SQL Server licensing costs can consume a significant portion of your database budget, especially when you’re paying for vCPUs that aren’t fully utilized. This post demonstrates how to implement the Optimize CPU feature to potentially reduce licensing costs while maintaining performance for both new and existing Amazon RDS instances, along with performance benchmarking results and cost implications.