AWS Web3 Blog
Access Bitcoin and Ethereum open datasets for cross-chain analytics
In this post, we share an open-source solution for running cross-chain analytics on public blockchain data along with public datasets for Bitcoin and Ethereum available through AWS Open Data. These datasets are still experimental and are not recommended for production workloads. You can find the open-source project on GitHub here and the public blockchain datasets here.
Today, AWS launches accessible Bitcoin and Ethereum blockchain datasets for public use. With the increase of Web3 activity around the world, more and more data is hosted on public blockchains. Although these blockchains are public, accessing and analyzing data across multiple chains continues to be a challenge for Web3 builders. TBs of data sit on these blockchains as users transact tokens, share information, and deploy smart contracts. However, querying these distributed ledgers directly is time consuming, inefficient, and unsuited for analytics.
Blocks on each chain contain information about transactions across the network. This includes public keys and addresses where tokens were exchanged, transaction volume and times, and metadata that highlights mining difficulty, network hash rates, available supply. Additionally, these blockchains are often used to host metadata that doesn’t impact or affect the transfer of tokens on that particular network. A growing number of distributed applications embed metadata in other blockchains to validate ownership of assets beyond cryptocurrency. The growing NFT market also has a wealth of metadata, ripe for exploration and analysis.
Each distributed ledger is designed in a unique way and uses different technology stacks and consensus algorithms. The public blockchain datasets allow you to have immediate access to this data without operating dedicated full nodes for the different blockchains and without building complicated ingestion pipelines. In addition, these datasets normalize data into tabular data structures and you can instantly access years worth of data across chains in a format that can be easily analyzed and queried by data scientists and other analytics professionals.
Solution overview
For these datasets we deployed an architecture to extract, transform, and load blockchain data into a column-oriented storage format that allows for easy access and expedited analysis.
You can load these files partitioned by date into your AWS environment and use AWS services like Amazon Athena or Amazon Redshift on top of this data to query it efficiently with SQL.
The following architecture diagram shows which AWS services are used to extract the data from the public blockchains and how it is delivered to Amazon Simple Storage Service (Amazon S3). You can also see which AWS services can be utilized to access this data from the public Amazon S3 bucket.
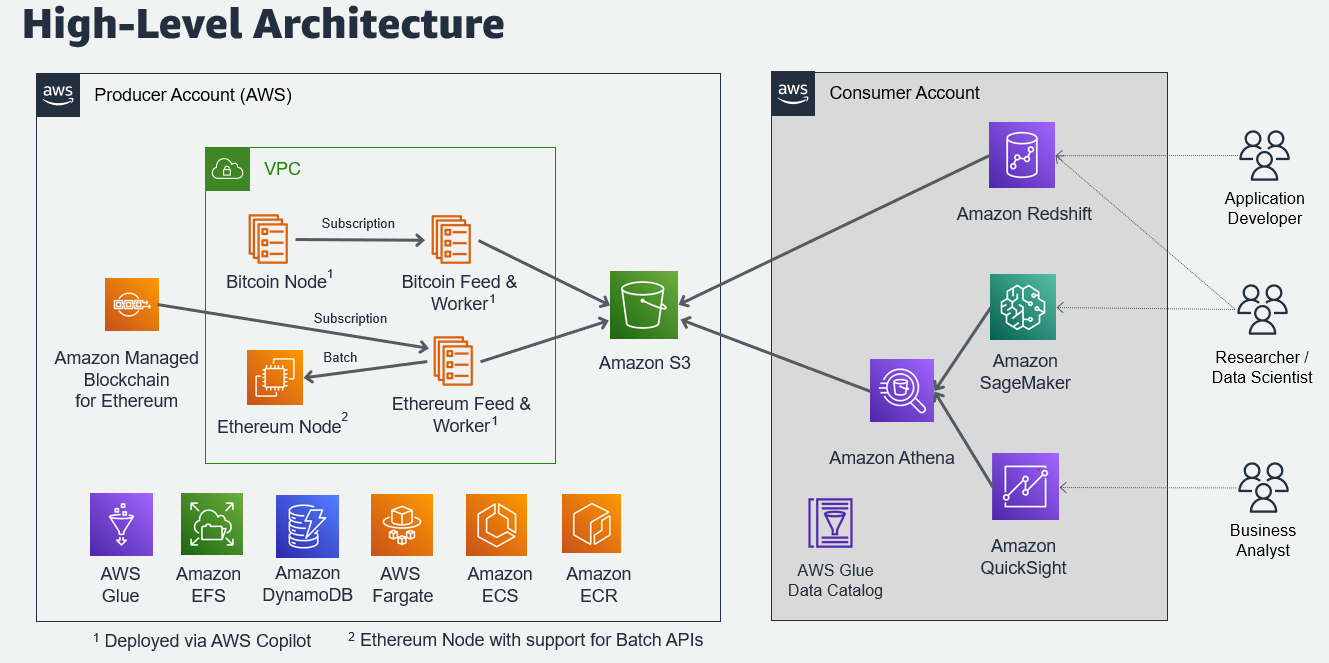
After taking an initial download of the full blockchain from the first block in 2009 for Bitcoin and in 2015 for Ethereum, an on-chain listener continuously delivers new data to the public Amazon S3 bucket that provides the open datasets. The blockchain data is then transformed into multiple tables as compressed Parquet files partitioned by date to allow efficient access for most common analytics queries.
The following folder structure is currently provided for Bitcoin and Ethereum blockchain data in the public Amazon S3 bucket.
Bitcoin: s3://aws-public-blockchain/v1.0/btc/
- blocks/date={YYYY-MM-DD}/{id}.snappy.parquet
- transactions/date={YYYY-MM-DD}/{id}.snappy.parquet
Ethereum: s3://aws-public-blockchain/v1.0/eth/
- blocks/date={YYYY-MM-DD}/{id}.snappy.parquet
- transactions /date={YYYY-MM-DD}/{id}.snappy.parquet
- logs/date={YYYY-MM-DD}/{id}.snappy.parquet
- token_transfers/date={YYYY-MM-DD}/{id}.snappy.parquet
- traces/date={YYYY-MM-DD}/{id}.snappy.parquet
- contracts/date={YYYY-MM-DD}/{id}.snappy.parquet
The schema of the Parquet files is documented for each table and field here. Currently, we provide the historical block and transaction data for both chains and some additional tables for Ethereum that are most commonly used for queries.
How to use this data?
On AWS, you can take advantage of multiple tools to access and analyze these datasets. Parquet files in Amazon S3 can be directly queried in Amazon Athena or Amazon Redshift. In addition, we provide Jupyter notebooks here for Amazon SageMaker Studio that demonstrate how to perform cross-chain analytics and how to combine blockchain data with market trends for fundamental on-chain analytics.
Before you can run these examples, you need to deploy the following AWS CloudFormation template. This template sets up AWS Glue Data Catalog, Amazon Athena Workgroup with a S3 bucket for the query results, and AWS Lambda functions to keep partitions up-to-date:
![]()
Example 1) Tell me the “birth block” for my child
Bitcoin has been around since January 2009 and Ethereum since July 2015. On average, a new Bitcoin block is created every ten minutes. New Ethereum blocks are created every 12-14 seconds. Every block has a time stamp, and we can identify the closest block for any given time in the last 13 years. In our example, we pick a birth time of 2016-01-14 18:23 UTC.
The following screenshot shows the SQL query in Amazon Athena and output of block 393,323 for Bitcoin and block 848,182 for Ethereum.

Example 2) Show me the largest stablecoin transactions
Transactions for Ethereum-based stablecoins are captured in the table “token_transfer” in the Ethereum dataset and each stablecoin has a unique token address.
The following screenshot shows how to query the largest transactions for a specific stablecoin in the query editor of Amazon Redshift.

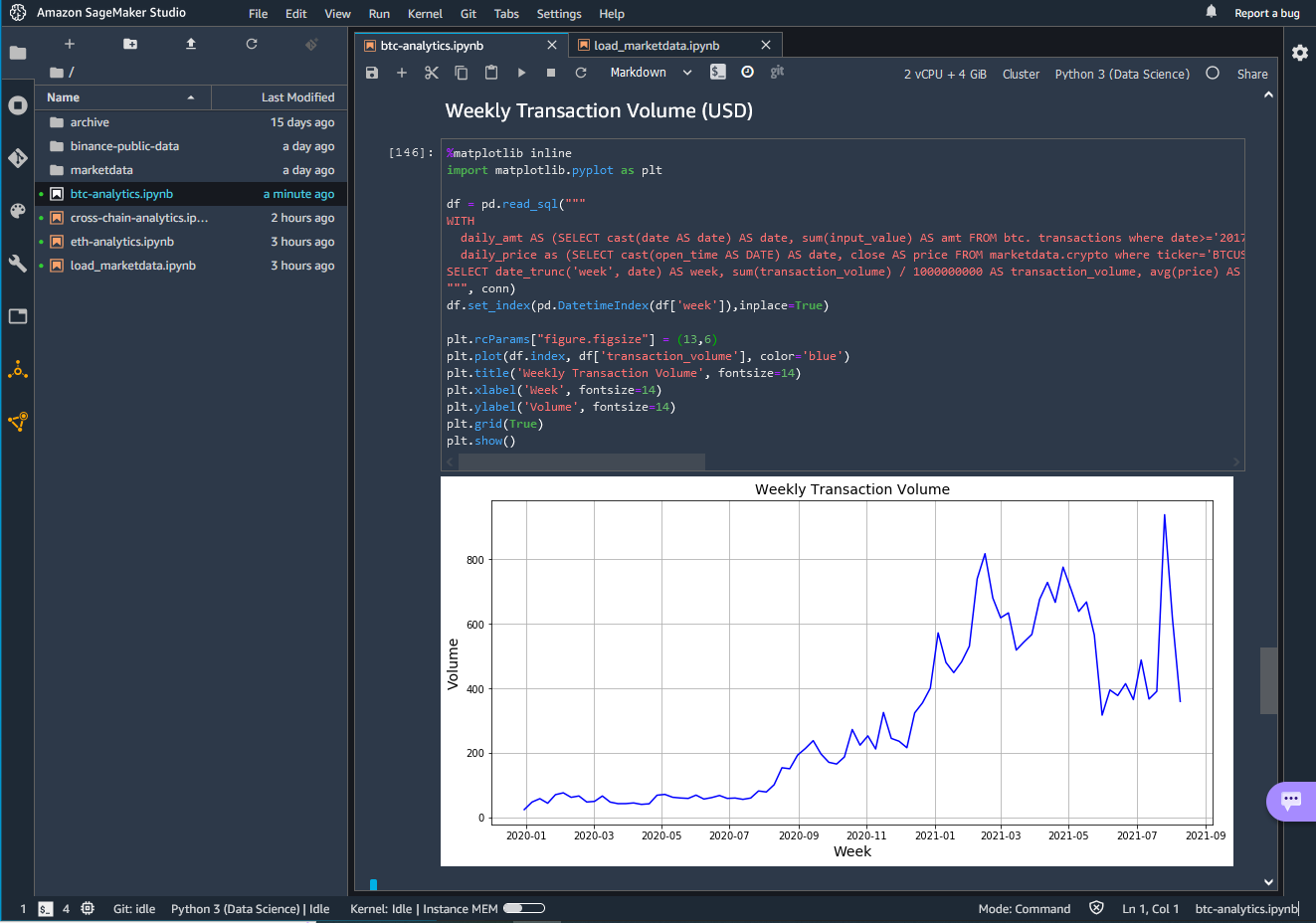
Example 3) Show me the weekly BTC transaction volume in USD
To calculate the transaction volume in USD, we also need historical price data for public blockchains. In our GitHub project, we provide a sample Jupyter notebook that pulls prices from a public crypto exchange. Once the market data is loaded, we can combine this data with the public blockchain data and visualize it in a chart. This analysis can help to better understand network adoption changes over time.
The following screenshot shows the example Jupyter notebook for this query in Amazon SageMaker Studio and the output as a chart.
Clean up
Don’t forget to remove the resources created if you don’t plan to use them anymore.
Empty the S3 bucket created by the stack and delete the CloudFormation stack.
Conclusion
These publicly available blockchain datasets can be used to jumpstart your projects, making it easier to get started working with Blockchain data. You can deploy the underlying network of nodes using services like Amazon Managed Blockchain to submit transactions and access real-time data directly from the node, but if you’re not deploying your own nodes or blockchain protocols, you can use these datasets to create an analytics layer that sits on top of these blockchains to extracts insights from the underlying data. You can use transaction volume, time, mining difficulty, and hash rates to identify trends and observations across multiple chains. You can also take advantage of the unique metadata within each blockchain, running analyses on unstructured fields.
If you are looking for a real-time ingestion pipeline from these networks, you can deploy the open-source solution in your own AWS account. This allows you also to create your own data repositories with finer controls for your data access requirements as your application scales and more users use your platform. For customers interested in production grade reliability, real-time access to Blockchain data or other advanced Blockchain data query needs, please contact us at aws-public-blockchain@amazon.com to connect and discuss your use case.
As other blockchains become more widely used, the open-source architecture can be adapted to other blockchains in the ecosystem. Any protocols developed using ERC-20 or ERC-721 can be easily supported because they use the same Ethereum protocol that has already been established in the open datasets. The same extensibility exists for tokens that are forks or variants of Bitcoin.
As we plan to extend this solution, let us know how we can help you with your use cases and improve our open source solution and open datasets.
Learn more about Amazon Managed Blockchain and how you can share and access petabytes of open data through AWS Open Data.
About the authors
 Oliver Steffmann is a Principal Solutions Architect at AWS based in New York and is passionate about public blockchain use cases. He has over 20 years of experience working with financial institutions and helps his customers get their cloud transformation off the ground. Outside of work he enjoys spending time with his family and training for the next Ironman.
Oliver Steffmann is a Principal Solutions Architect at AWS based in New York and is passionate about public blockchain use cases. He has over 20 years of experience working with financial institutions and helps his customers get their cloud transformation off the ground. Outside of work he enjoys spending time with his family and training for the next Ironman.
 Stefan Dicker works in AWS’ Startup Business Development function focused on supporting the growing Venture Studio ecosystem. He first started working with Blockchain startups in 2015 and helped execute the world’s first blockchain-based trade-finance deal. Outside of work you can find him on the ultimate field, gardening or geeking out on the latest in technical innovations.
Stefan Dicker works in AWS’ Startup Business Development function focused on supporting the growing Venture Studio ecosystem. He first started working with Blockchain startups in 2015 and helped execute the world’s first blockchain-based trade-finance deal. Outside of work you can find him on the ultimate field, gardening or geeking out on the latest in technical innovations.
 Bhaskar Ravat is a Senior Solutions Architect at AWS based in New York and is passionate about public blockchain use case and technology landscape including Ethereum, Web3 and Defi. You can find him reading 4 books at time when not helping or building solutions for customers.
Bhaskar Ravat is a Senior Solutions Architect at AWS based in New York and is passionate about public blockchain use case and technology landscape including Ethereum, Web3 and Defi. You can find him reading 4 books at time when not helping or building solutions for customers.
 Sreeji Gopal is a Data Lake Architect in Big Data at AWS. He helps customers create a meaningful experience with data analytics focused on customers’ vision on products/services. Sreeji is a CrossFit enthusiast and likes to spend his free time with family, hiking, and traveling.
Sreeji Gopal is a Data Lake Architect in Big Data at AWS. He helps customers create a meaningful experience with data analytics focused on customers’ vision on products/services. Sreeji is a CrossFit enthusiast and likes to spend his free time with family, hiking, and traveling.