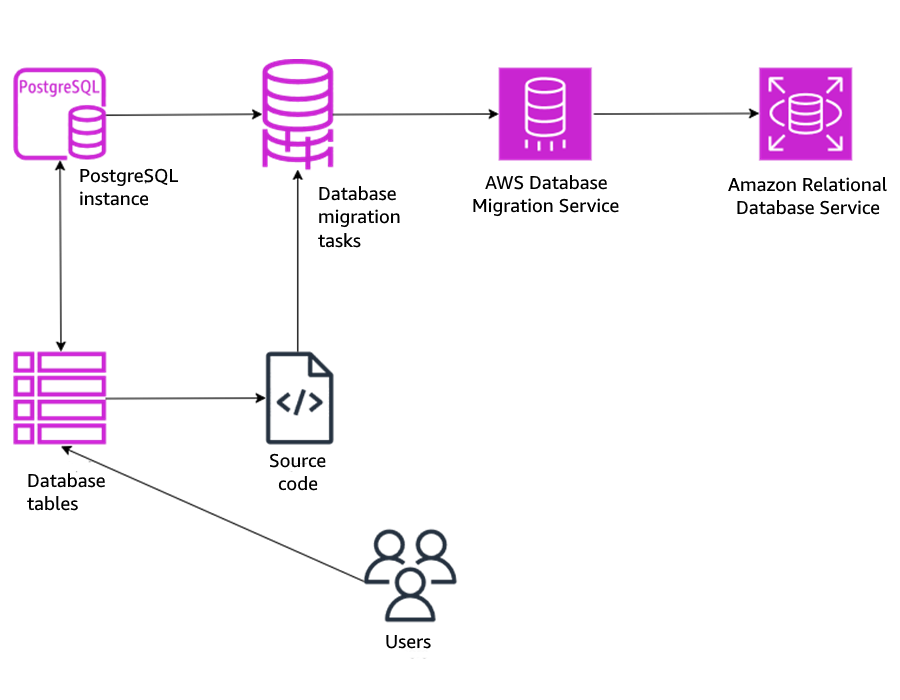
Group database tables under AWS Database Migration Service tasks for PostgreSQL source engine
AWS Database Migration Service (AWS DMS) is a cloud-based tool engineered to ease the transfer and duplication of data repositories, including databases and data warehouses. It provides a solution for moving data between similar and dissimilar database systems, enabling shifts across various data platforms.
The data transfer process generally includes two key stages:
The transfer of current information (full load) – In this stage, AWS DMS conducts a full data transfer, moving all existing information from the origin data store to the destination data store.
Continuous synchronization (change data capture) – Following the initial complete load, AWS DMS enables ongoing synchronization of data changes through a method known as change data capture (CDC). These changes are continually replicated and implemented in the destination data store in real time or near real-time, ensuring the destination data store remains in sync with the origin.
AWS DMS accommodates a broad range of source and target data repositories, such as relational databases, data warehouses, and NoSQL databases. For a successful transfer, it’s essential to tackle the database and application prerequisites, with initial groundwork and planning playing a crucial role in achieving this goal.
Though AWS DMS offers robust tools for database migration, every transfer project is unique and presents specific challenges. Proper preparation and design are vital for a successful migration process, especially when it comes to optimizing performance and addressing potential delay issues.
In this blog post, we offer guidance about recognizing potential root causes of complete load and CDC delays early in the process and provide suggestions for optimally clustering tables to achieve the best performance for an AWS DMS task. By adhering to the strategy outlined in this post, you can more effectively plan your database migration, estimate task dimensions, and design an efficient transfer process that minimizes potential issues and maximizes performance.
Know your data
Embarking on a data transfer project necessitates an initial comprehension of the information you’re relocating. The complete load transfer phase includes moving a full replica of the source information to the destination database. This procedure ensures that the destination database is filled with an exact copy of the data from the source database.
CDC is a method that records incremental modifications to data and data structures (schemas) from the origin database in real time or near real-time. CDC facilitates the distribution of these changes to other databases or applications, ensuring they stay in sync with the origin database.
You can evaluate the complete load and CDC requirements for database relocation by examining the database dimensions, operational load, and hardware specifications to provide suggestions about the number of tasks and table groupings needed for each task.
Multiple factors can directly and indirectly affect the pace of data transfer when utilizing AWS DMS. The following are some of the typical factors for both complete load and CDC:
Database object dimensions – Isolating enormous tables (exceeding 2 TB) in a dedicated transfer task can aid in enhancing migration efficiency. By segregating the handling of extensive data sets within a specific task or operation, the transfer process can potentially become more streamlined and effective.
Segmented and nonsegmented objects – You can transfer large, segmented tables by loading multiple tables concurrently. AWS DMS also permits loading a single large table using multiple parallel threads. This is particularly beneficial for tables with billions of records having multiple segments and sub-segments.
Objects lacking a primary key and unique index – AWS DMS requires a primary key or unique key for source tables with large objects to transfer.
Large objects (LOBs) – LOB columns require special handling because AWS DMS can’t determine LOB size per row per column to allocate appropriate memory on the replication instance side. AWS DMS offers full, limited, and inline LOB modes to migrate LOB data. Keeping LOBs in a separate task can help efficiently manage transfer activity.
Change volume – If your workload involves a high volume of CDC changes, updating the same set of records repeatedly or inserting or updating and deleting the same records, you can improve the target apply throughput using batch apply.
Solution overview
The goal of this post is to analyze the source database’s data dictionary and combine that information with hardware details to create recommendations for efficient data migration tasks. This analysis helps determine the optimal number of AWS DMS tasks and grouping of tables within those tasks, reducing potential latency issues during the migration process.
The workflow involves the following steps:
Create a control table on the source PostgreSQL database.
Populate the control table by analyzing table size, partitions, indexes, constraints, data types, and LOB data using data dictionary tables and views.
Capture the daily growth of tables by monitoring the volume of incoming changes.
Categorize the tables by step number.
Group the database tables.
The following diagram illustrates the solution architecture.
Prerequisites
To follow along with this post, you should have familiarity with the following:
AWS DMS
PostgreSQL Relational Database Service
PSQL and PLPGSQL procedures
1. Create a control table on the source PostgreSQL database
In this first step, create a control table named table_mapping, which provides a one-window view to understand which data we’re migrating. This table is created by referring to system catalogs and statistics views information about the size of the table, partition, partition size (count, average, minimum, and maximum), LOB column, number of indexes, primary key or unique key constraints, foreign key constraints, and data definition language (DDL)/data manipulation language (DML) operation count of truncate, insert, update, and delete operations on the table.
The control table provides baseline data to use in the next step to group table.
To create a control table on the source PostgreSQL database:
Connect to your source PostgreSQL database.
Run the following SQL block to create the control table:
Now that you have created the control table, you can populate the control table with system catalogs and statistics views in PostgreSQL databases that provide information about the size, type, partitioning, constraints, and LOB data related to database objects. Specifically, the following data dictionary objects are mentioned:
PG_TABLES – Provides access to useful information about each table in the PostgreSQL database.
PG_PARTITIONED_TABLE – The catalog table stores information about how tables are partitioned.
PG_INHERITS – The catalog table records information about table and index inheritance hierarchies. One entry exists for each direct parent-child table or index relationship in the database.
PG_CLASS – The catalog table describes tables and other objects that have columns or are otherwise similar to a table. These similarities include indexes, sequences, views, materialized views, composite types, and TOAST tables.
PG_NAMESPACE – The catalog table stores namespaces. A namespace is the structure underlying SQL schemas. Each namespace can have a separate collection of relations and types without name conflicts.
INFORMATION_SCHEMA.COLUMNS – Provides metadata about columns in tables and views within a database. This is a standard way to access information about table structures across different database systems.
You can query these catalog and views objects to retrieve metadata about the database objects, allowing you to identify and analyze the structure, size, constraints, and modifications made to various objects in the database.
Now read from the system catalogs and statistics views into the control table:
Insert into the control table the database table details such as name, size, and partition for the desired schema (here, 'admin' is used):
INSERT INTO admin.table_mapping(OWNER, OBJECT_NAME, OBJECT_TYPE, SIZE_IN_MB, PART_NUM, PARTITIONED)
SELECT
schemaname,
tablename,
'TABLE',
pg_total_relation_size(schemaname || '.' || tablename) / 1024.0 / 1024.0,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN (
SELECT count(*) FROM pg_inherits
WHERE inhparent = (schemaname || '.' || tablename)::regclass
) ELSE 1 END,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN 'YES' ELSE 'NO' END
FROM pg_tables
WHERE schemaname = 'admin';
Clean up the child table data from the mapping table in the 'admin' schema:
DELETE FROM admin.table_mapping WHERE object_name IN (SELECT
child.relname AS child_table
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p' and nmsp_child.nspname ='admin');
Populate partition table size for parent tables:
WITH partition_sizes AS (
SELECT
parent_schema,
parent_table,
SUM(partition_size)/(1024*1024) as size_mb -- Convert bytes to MB
FROM (
SELECT
nmsp_parent.nspname AS parent_schema,
parent.relname AS parent_table,
pg_total_relation_size(child.oid) AS partition_size
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p'
) subquery
GROUP BY parent_schema, parent_table
)
UPDATE admin.table_mapping tm
SET SIZE_IN_MB = ps.size_mb
FROM partition_sizes ps
WHERE tm.OWNER = ps.parent_schema
AND tm.OBJECT_NAME = ps.parent_table;
Update the PK_PRESENT field of the control table for database tables that have primary keys defined:
UPDATE admin.table_mapping
SET PK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'PRIMARY KEY'
) THEN 'YES' ELSE 'NO' END;
Update the UK_PRESENT field of the control table for database tables that have unique keys defined:
UPDATE admin.table_mapping
SET UK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'UNIQUE'
) THEN 'YES' ELSE 'NO' END;
Update the LOB_COLUMN field of the control table for database tables that have at least one LOB column:
UPDATE admin.table_mapping
SET LOB_COLUMN = (
SELECT COUNT(*)
FROM information_schema.columns
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND data_type IN ('bytea', 'text', 'json', 'jsonb')
);
3. Capture the volume of DML changes over time
The pg_stat_user_tables system view in the PostgreSQL database contains information about modifications made to all tables in the database since the last time statistics were gathered on those tables. PostgreSQL uses pg_stat_user_tables to gather table DML and statistics information, which are based on the PostgreSQL statistics collector. The last autovacuum timestamp is used get timing information. Regular ANALYZE operations are performed on the tables to update pg_stat_user_tables with information about DML changes and time of last analyze.
By reviewing the data daily, you can gain insights into the daily modifications made to tables. This information can be valuable for identifying tables that have undergone a significant number of changes, which may impact their performance or require maintenance tasks such as statistics gathering or reorganization.
To capture the volume of DML changes over time:
Create a staging table called MST_DBA_TAB_MOD to get the details from pg_stat_user_tables:
Populate the MST_DBA_TAB_MOD table with the daily average DML count for the tables by gathering the information from the PostgreSQL pg_stat_user_tables system view. Counts are noted from the last-analyzed date and then averaged, so having recent table stats information makes the counts more accurate.
INSERT INTO admin.mst_dba_tab_mod (
TABLE_OWNER,
TABLE_NAME,
INSERTS,
UPDATES,
DELETES,
TOTAL_DML,
TIMESTAMP
)
SELECT
schemaname AS TABLE_OWNER,
relname AS TABLE_NAME,
n_tup_ins AS INSERTS,
n_tup_upd AS UPDATES,
n_tup_del AS DELETES,
ROUND((n_tup_ins + n_tup_upd + n_tup_del)::numeric /
GREATEST(EXTRACT(EPOCH FROM (now() - last_autovacuum))::numeric / 86400, 1)) AS TOTAL_DML,
now() AS TIMESTAMP
FROM pg_stat_user_tables
WHERE schemaname = 'admin';
Next, populate the DML information in the control table_mapping_mapping table by running the following update statement that collects this information from MST_DBA_TAB_MOD, which you populated in the previous step:
UPDATE admin.table_mapping a
SET TOTAL_DML = b.TOTAL_DML
FROM admin.mst_dba_tab_mod b
WHERE a.OWNER = b.TABLE_OWNER
AND a.OBJECT_NAME = b.TABLE_NAME
AND b.TABLE_OWNER = 'admin';
4. Categorize the tables by step number
Tables are then categorized in a database based on various factors related to their data characteristics, as shown in the following code. These factors include whether the table is partitioned or nonpartitioned, whether it contains LOBs, the table size, and the number of DML operations performed on the table. Nonpartitioned tables that don’t have LOB fields are categorized as step 1, nonpartitioned tables with LOB fields are categorized as step 2, partitioned tables without LOB fields are categorized as step 3, and so on. For example, all tables reporting SIZE_IN_MB as 0 are categorized as out of scope for the migration. You can add additional tables to this step if your use case needs them.
Categorization of tables based on these attributes is done for optimization purposes.
UPDATE admin.table_mapping SET STEP = 1 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'NO' AND STEP IS NULL;
UPDATE admin.table_mapping SET STEP = 2 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'NO' AND STEP IS NULL;
UPDATE admin.table_mapping SET STEP = 3 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'YES' AND STEP IS NULL;
UPDATE admin.table_mapping SET STEP = 4 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'YES' AND STEP IS NULL;
UPDATE admin.table_mapping SET STEP = 5 WHERE TOTAL_DML > 9999999;
UPDATE admin.table_mapping SET STEP = 0 WHERE SIZE_IN_MB = 0 AND STEP IS NULL;
5. Group the database tables
The process of recommending groups begins by creating and populating the TABLE_MAPPING_GROUPS table based on the information stored in the TABLE_MAPPING control table. The process is initiated by a procedure that takes three parameters:
Mapping table (TABLE_MAPPING)
Source migration schema (ADMIN)
Size of database objects per task (600 GB)
The size of database objects per task (600 GB) is chosen to evenly distribute the tables across tasks, considering factors such as CPU, network, and I/O capabilities of the source and target replication instances.
Use a shell script to call the admin.both stored procedure to group the tables and then list the grouped tables by using step and groupnum by using section in procedure both one for partition and one for nonpartition table:
CREATE OR REPLACE PROCEDURE admin.both (
IN p_n NUMERIC,
IN p_schema_name VARCHAR,
IN p_table_name VARCHAR
)
AS
$BODY$
DECLARE
vTab CHARACTER VARYING(30);
vDumpSize DOUBLE PRECISION := 0;
vSumBytes DOUBLE PRECISION := 0;
vGroupNum DOUBLE PRECISION := 0;
vPrevStep DOUBLE PRECISION := 1;
reggrouptabs RECORD;
BEGIN
vDumpSize := 1024 * p_n;
-- Dynamic SQL to truncate the table
EXECUTE format('TRUNCATE %I.%I_groups', p_schema_name, p_table_name);
-- Dynamic SQL to insert data
EXECUTE format('
INSERT INTO %I.%I_groups
SELECT owner, object_name, object_type, size_in_mb, step, ignore, partitioned
FROM %I.%I',
p_schema_name, p_table_name, p_schema_name, p_table_name);
FOR reggrouptabs IN
EXECUTE format('
SELECT *
FROM %I.%I_groups
ORDER BY step, size_in_mb',
p_schema_name, p_table_name)
LOOP
IF (reggrouptabs.step != vPrevStep) THEN
vGroupNum := 0;
vSumBytes := 0;
END IF;
vSumBytes := vSumBytes + reggrouptabs.size_in_mb;
IF (vSumBytes >= vDumpSize) THEN
vGroupNum := vGroupNum + 1;
vSumBytes := 0;
END IF;
-- Dynamic SQL for UPDATE
EXECUTE format('
UPDATE %I.%I_groups
SET groupnum = $1
WHERE owner = $2 AND object_name = $3',
p_schema_name, p_table_name)
USING vGroupNum, reggrouptabs.owner, reggrouptabs.object_name;
vPrevStep := reggrouptabs.step;
END LOOP;
COMMIT;
END;
$BODY$
LANGUAGE plpgsql;
You can collect the final plpgsql procedure output by executing the following select statement to iteratively go over table_mapping_groups and list the table names by the respective group names, which can be used to create the respective AWS DMS tasks:
SELECT partitioned,step, groupnum, count(1) table_in_group,sum(size_in_mb) Total_group_size
FROM admin.table_mapping_groups
group by partitioned,step, groupnum
ORDER BY 1,2,3;
Demonstration
To demonstrate this post’s solution, we use a PostgreSQL source instance measuring 6.2 TB for data transfer and group tables within 600 GB size per DMS task. The configuration employs a db.m5.4xlarge instance, featuring 8 cores, 16 vCPU, and 64 GiB of memory. Following an assessment of CPU usage, network throughput, and operational load, creating tasks in 600 GB sets was determined to be optimal for this workload. However, because each source has unique characteristics, you must thoroughly analyze your specific source database dimensions, workload, CPU, memory, and network utilization to determine the appropriate cluster size.
The process implements a method of organizing step information from a loop table in descending sequence, followed by clustering the arranged data according to a defined size parameter.
We have consolidated the following procedures into a shell script to eliminate the need for manual execution of individual steps:
Create a control table on the source PostgreSQL database.
Populate the control table by analyzing table size, partitions, indexes, constraints, data types, and LOB data using data dictionary tables and views.
Capture the daily growth of tables by monitoring the volume of incoming changes.
Categorize the tables by step number.
The following code is the corresponding shell script:
#!/bin/bash
# Collect database connection details
echo "Please enter database connection details:"
read -p "Database name [postgres]: " DB_NAME
DB_NAME=${DB_NAME:-postgres}
read -p "Database user [postgres]: " DB_USER
DB_USER=${DB_USER:-postgres}
read -p "Database host [localhost]: " DB_HOST
DB_HOST=${DB_HOST:-localhost}
read -p "Database port [5432]: " DB_PORT
DB_PORT=${DB_PORT:-5432}
read -s -p "Database password: " password
DB_PASSWORD=$password
# Export variables for psql to use
export PGPASSWORD="$DB_PASSWORD"
# Function to execute psql query and return result
execute_query() {
psql -U "$DB_USER" \
-h "$DB_HOST" \
-p "$DB_PORT" \
-d "$DB_NAME" \
-t -A \
-c "$1"
}
# Test connection
echo -e "\nTesting database connection..."
if ! execute_query "SELECT 1;" > /dev/null 2>&1; then
echo "Error: Could not connect to the database. Please check your credentials."
exit 1
fi
echo "Connection successful!"
# Example 1: Simple SELECT query
#echo -e "\nExample 1: List of users"
#users=$(execute_query "SELECT usename FROM pg_catalog.pg_user;")
#echo "$users"
echo -e "\nCreating the control table"
table_ddl=$(execute_query "CREATE TABLE TABLE_MAPPING (
OWNER VARCHAR(30),
OBJECT_NAME VARCHAR(30),
OBJECT_TYPE VARCHAR(30),
SIZE_IN_MB NUMERIC(12,4),
STEP INTEGER,
IGNORE CHAR(3),
PARTITIONED CHAR(3),
PART_NUM INTEGER,
SPECIAL_HANDLING CHAR(3),
PK_PRESENT CHAR(3),
UK_PRESENT CHAR(3),
LOB_COLUMN INTEGER,
GROUPNUM INTEGER,
TOTAL_DML INTEGER
);")
echo "$table_ddl"
echo -e "\nCleaning up the old control table"
clean_ddl=$(execute_query "TRUNCATE TABLE admin.table_mapping;")
echo "$clean_ddl"
echo -e "\nInsert into the control table the database table details "
table_insert=$(execute_query "INSERT INTO admin.table_mapping(OWNER, OBJECT_NAME, OBJECT_TYPE, SIZE_IN_MB, PART_NUM, PARTITIONED)
SELECT
schemaname,
tablename,
'TABLE',
pg_total_relation_size(schemaname || '.' || tablename) / 1024.0 / 1024.0,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN (
SELECT count(*) FROM pg_inherits
WHERE inhparent = (schemaname || '.' || tablename)::regclass
) ELSE 1 END,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN 'YES' ELSE 'NO' END
FROM pg_tables
WHERE schemaname = 'admin';")
echo "$table_insert"
echo -e "\nCleaning up child table data"
clean_dml=$(execute_query "DELETE FROM admin.table_mapping WHERE object_name IN (SELECT
child.relname AS child_table
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p' and nmsp_child.nspname ='admin') ;
;")
echo "$clean_dml"
echo -e "\nPopulate partition table size"
pop_part=$(execute_query "WITH partition_sizes AS (
SELECT
parent_schema,
parent_table,
SUM(partition_size)/(1024*1024) as size_mb -- Convert bytes to MB
FROM (
SELECT
nmsp_parent.nspname AS parent_schema,
parent.relname AS parent_table,
pg_total_relation_size(child.oid) AS partition_size
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p'
) subquery
GROUP BY parent_schema, parent_table
)
UPDATE admin.table_mapping tm
SET SIZE_IN_MB = ps.size_mb
FROM partition_sizes ps
WHERE tm.OWNER = ps.parent_schema
AND tm.OBJECT_NAME = ps.parent_table;")
echo "$pop_part"
echo -e "\nUpdate the PK_PRESENT field of the control table"
pk_present=$(execute_query "UPDATE admin.table_mapping
SET PK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'PRIMARY KEY'
) THEN 'YES' ELSE 'NO' END;")
echo "$pk_present"
echo -e "\nUpdate the UK_PRESENT field of the control table "
uk_present=$(execute_query "UPDATE admin.table_mapping
SET UK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'UNIQUE'
) THEN 'YES' ELSE 'NO' END;")
echo "$uk_present"
echo -e "\nUpdate the LOB_COLUMN field of the control table "
lob_column=$(execute_query "UPDATE admin.table_mapping
SET LOB_COLUMN = (
SELECT COUNT(*)
FROM information_schema.columns
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND data_type IN ('bytea', 'text', 'json', 'jsonb')
);")
echo "$lob_column"
echo -e "\nCreate a staging table called MST_DBA_TAB_MOD to get the details from pg_stat_user_tables"
table_ddl=$(execute_query "CREATE TABLE admin.mst_dba_tab_mod (
DATA_DATE DATE,
TABLE_OWNER VARCHAR(128),
TABLE_NAME VARCHAR(128),
PARTITION_NAME VARCHAR(128),
SUBPARTITION_NAME VARCHAR(128),
INSERTS BIGINT,
UPDATES BIGINT,
DELETES BIGINT,
TIMESTAMP TIMESTAMP,
TRUNCATED VARCHAR(3),
TOTAL_DML BIGINT,
DROP_SEGMENTS BIGINT
);")
echo "$table_ddl"
echo -e "\nPopulate the MST_DBA_TAB_MOD table with the daily average DML count for the tables "
table_dml=$(execute_query "INSERT INTO admin.mst_dba_tab_mod (
TABLE_OWNER,
TABLE_NAME,
INSERTS,
UPDATES,
DELETES,
TOTAL_DML,
TIMESTAMP
)
SELECT
schemaname AS TABLE_OWNER,
relname AS TABLE_NAME,
n_tup_ins AS INSERTS,
n_tup_upd AS UPDATES,
n_tup_del AS DELETES,
ROUND((n_tup_ins + n_tup_upd + n_tup_del)::numeric /
GREATEST(EXTRACT(EPOCH FROM (now() - last_autovacuum))::numeric / 86400, 1)) AS TOTAL_DML,
now() AS TIMESTAMP
FROM pg_stat_user_tables
WHERE schemaname = 'admin';")
echo "$table_dml"
echo -e "\nPopulate the DML information in the control table_mapping_mapping table "
load_dml=$(execute_query "UPDATE admin.table_mapping a
SET TOTAL_DML = b.TOTAL_DML
FROM admin.mst_dba_tab_mod b
WHERE a.OWNER = b.TABLE_OWNER
AND a.OBJECT_NAME = b.TABLE_NAME
AND b.TABLE_OWNER = 'admin';
")
echo "$load_dml"
echo -e "\nCategorize the tables by step number"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 1 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'NO' AND STEP IS NULL;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 2 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'NO' AND STEP IS NULL;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 3 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'YES' AND STEP IS NULL;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 4 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'YES' AND STEP IS NULL;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 5 WHERE TOTAL_DML > 9999999;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 0 WHERE SIZE_IN_MB = 0 AND STEP IS NULL;")
echo "$update_dml"
# Clear password from environment
unset PGPASSWORD
echo -e "\nScript execution completed"
The following are the results of running the script, showcasing the different steps of its execution for easy reference:
[ec2-user@ip-10-0-0-40 ~]$ ./pg_table_grouping.sh
Please enter database connection details:
Database name [postgres]:
Database user [postgres]:
Database host [localhost]: pg-dms-target.caub0zqkqtdt.us-east-1.rds.amazonaws.com
Database port [5432]:
Database password:
Testing database connection...
Connection successful!
Creating the control table
ERROR: relation "table_mapping" already exists
Cleaning up the old control table
TRUNCATE TABLE
Insert into the control table the database table details
INSERT 0 287
Cleaning up child table data
DELETE 192
Populate partition table size
UPDATE 19
Update the PK_PRESENT field of the control table
UPDATE 95
Update the UK_PRESENT field of the control table
UPDATE 95
Update the LOB_COLUMN field of the control table
UPDATE 95
Create a staging table called MST_DBA_TAB_MOD to get the details from pg_stat_user_tables
ERROR: relation "mst_dba_tab_mod" already exists
Populate the MST_DBA_TAB_MOD table with the daily average DML count for the tables
INSERT 0 287
Populate the DML information in the control table_mapping_mapping table
UPDATE 95
Categorize the tables by step number
UPDATE 56
UPDATE 20
UPDATE 6
UPDATE 13
UPDATE 0
UPDATE 0
Script execution completed
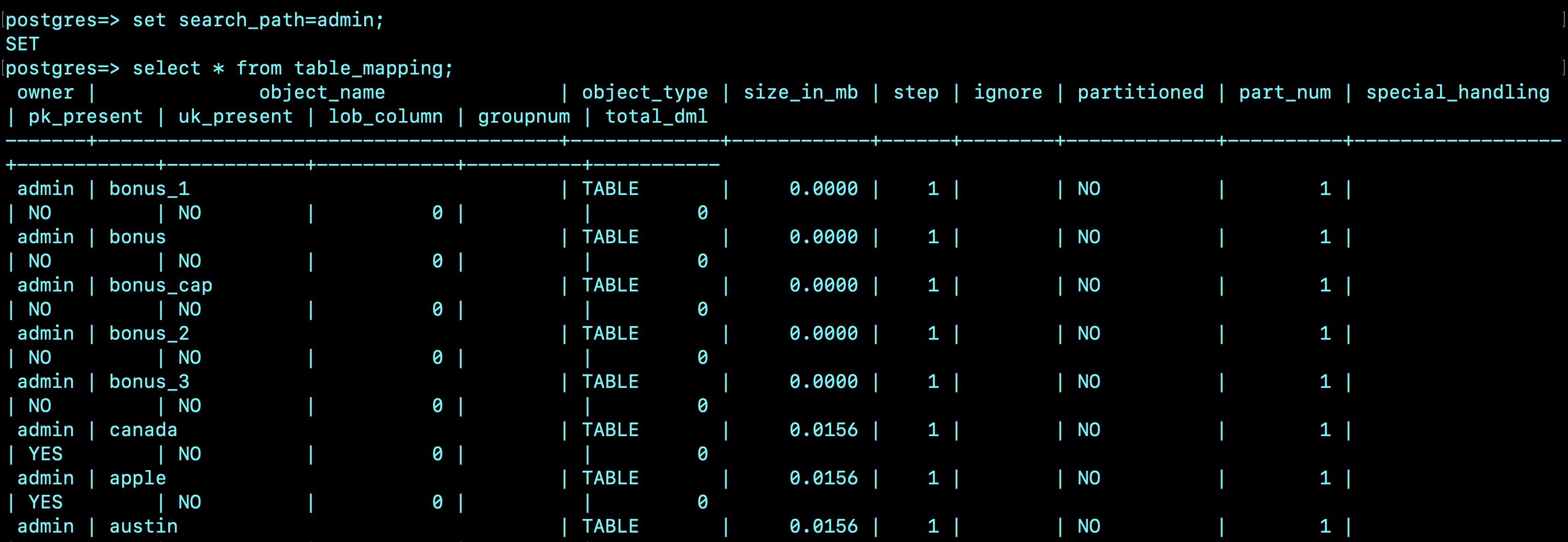
The following code is a snippet of the control table, table_mapping, which is populated from the data dictionary after running the shell script shown earlier in this section:
The following is a screenshot of the table_mapping output:
After the table grouping script has run, the final output consists of six initial step numbers, 0–5:
0 for ignore or skip for special handling tables
1 for nonpartitioned tables without LOB fields
2 for nonpartitioned tables with LOB fields
3 for partitioned tables without LOB fields
4 for partitioned tables with LOB fields
5 for high DML tables
Next, run the table grouping shell script to create the final grouping of the tables. Tables that are part of a group will be included under a single AWS DMS task. See previous sections of this blog post for more details about this code.
The following shell script creates the final grouping of the tables:
#!/bin/bash
# Collect database connection details
echo "Please enter database connection details:"
read -p "Database name [postgres]: " DB_NAME
DB_NAME=${DB_NAME:-postgres}
read -p "Database user [postgres]: " DB_USER
DB_USER=${DB_USER:-postgres}
read -p "Database host [localhost]: " DB_HOST
DB_HOST=${DB_HOST:-localhost}
read -p "Database port [5432]: " DB_PORT
DB_PORT=${DB_PORT:-5432}
read -s -p "Database password: " password
DB_PASSWORD=$password
# Export variables for psql to use
export PGPASSWORD="$DB_PASSWORD"
# Function to execute psql query and return result
execute_query() {
psql -U "$DB_USER" \
-h "$DB_HOST" \
-p "$DB_PORT" \
-d "$DB_NAME" \
-t -A \
-c "$1"
}
# Test connection
echo -e "\nTesting database connection..."
if ! execute_query "SELECT 1;" > /dev/null 2>&1; then
echo "Error: Could not connect to the database. Please check your credentials."
exit 1
fi
echo "Connection successful!"
# Step 1: Create the plpgsql procedure
echo -e "\nCreating plpgsql procedure..."
create_procedure_query=$(cat << EOF
CREATE OR REPLACE PROCEDURE admin.both (
IN p_n NUMERIC,
IN p_schema_name VARCHAR,
IN p_table_name VARCHAR
)
AS
\$BODY\$
DECLARE
vTab CHARACTER VARYING(30);
vDumpSize DOUBLE PRECISION := 0;
vSumBytes DOUBLE PRECISION := 0;
vGroupNum DOUBLE PRECISION := 0;
vPrevStep DOUBLE PRECISION := 1;
reggrouptabs RECORD;
BEGIN
vDumpSize := 1024 * p_n;
-- Dynamic SQL to truncate the table
EXECUTE format('TRUNCATE %I.%I_groups', p_schema_name, p_table_name);
-- Dynamic SQL to insert data
EXECUTE format('
INSERT INTO %I.%I_groups
SELECT owner, object_name, object_type, size_in_mb, step, ignore, partitioned
FROM %I.%I',
p_schema_name, p_table_name, p_schema_name, p_table_name);
FOR reggrouptabs IN
EXECUTE format('
SELECT *
FROM %I.%I_groups
ORDER BY step, size_in_mb',
p_schema_name, p_table_name)
LOOP
IF (reggrouptabs.step != vPrevStep) THEN
vGroupNum := 0;
vSumBytes := 0;
END IF;
vSumBytes := vSumBytes + reggrouptabs.size_in_mb;
IF (vSumBytes >= vDumpSize) THEN
vGroupNum := vGroupNum + 1;
vSumBytes := 0;
END IF;
-- Dynamic SQL for UPDATE
EXECUTE format('
UPDATE %I.%I_groups
SET groupnum = \$1
WHERE owner = \$2 AND object_name = \$3',
p_schema_name, p_table_name)
USING vGroupNum, reggrouptabs.owner, reggrouptabs.object_name;
vPrevStep := reggrouptabs.step;
END LOOP;
COMMIT;
END;
\$BODY\$
LANGUAGE plpgsql;
EOF
)
execute_query "$create_procedure_query"
echo "Procedure created successfully!"
# Step 2: Execute the plpgsql procedure
echo -e "\nExecuting the procedure..."
read -p "Enter p_n value: " p_n
read -p "Enter p_schema_name: " p_schema_name
read -p "Enter p_table_name: " p_table_name
execute_procedure_query="CALL admin.both($p_n, '$p_schema_name', '$p_table_name');"
execute_query "$execute_procedure_query"
echo "Procedure executed successfully!"
# Step 3: Execute the SELECT query and display results
echo -e "\nExecuting SELECT query..."
select_query="
SELECT partitioned, step, groupnum as substep,
count(1) as table_in_group,
round(sum(size_in_mb)/1024, 2) as Total_size_GB
FROM admin.table_mapping_groups
GROUP BY partitioned, step, groupnum
ORDER BY 1,2,3;
"
echo "
*********************************************************
Tables are grouped based on ${p_n}GB size
*********************************************************
1(10,11,...) --> Non Partition Table.
2(20,21....) --> Non Partition Table(LOB)
3(30,31...) --> Partition Table.
4(40,41...) --> Partition Table(LOB).
5(50,51...) --> High DML Table.
0(0,99) --> Ignore or Skip/Special Handling table.
**********************************************************
"
# First display the traditional output
result=$(execute_query "$select_query")
echo -e "\nQuery Results:"
echo -e "partitioned\tstep\tsubstep\ttable_in_group\tTotal_size_GB"
echo "$result" | sed 's/|/\t/g'
# Now generate the formatted output
echo -e "\nDetailed Group Summary:"
formatted_query="
WITH grouped_data AS (
SELECT
concat(step, groupnum) as group_number,
count(1) as table_count,
round(sum(size_in_mb)/1024, 2) as size_gb,
CASE
WHEN step = 0 THEN ' comprising of ignored objects'
WHEN step = 1 THEN ' with no partitions'
WHEN step = 2 THEN ' with no partitions but containing lob fields'
WHEN step = 3 THEN ' with partitions'
WHEN step = 4 THEN ' with partitions and containing lob fields'
WHEN step = 5 THEN ' with high DML change'
ELSE ''
END as description
FROM admin.table_mapping_groups
GROUP BY step, groupnum
ORDER BY concat(step, groupnum)
)
SELECT format('Group number %s will have %s table%s with size of %s GB%s.',
group_number,
table_count,
CASE WHEN table_count = 1 THEN '' ELSE 's' END,
to_char(size_gb, 'FM999,999'),
description)
FROM grouped_data
WHERE group_number != '099';
"
execute_query "$formatted_query" | while read -r line; do
echo "$line"
done
# Clear password from environment
unset PGPASSWORD
echo -e "\nScript execution completed"
The PLPGSQL procedure generates a final recommendation for migrating data tables. It involves running a PLPGSQL block with the following steps:
Check and drop an existing table named table_mapping_groups to create a new table.
Create a new table_mapping_groups table from TABLE_MAPPING.
Group partitioned tables with LOB and non-LOB columns based on a group size of 600 GB, resulting in groups such as 10, 11, 12, and 13.
Group nonpartitioned tables with LOB and non-LOB columns using a similar procedure.
The process accommodates tables requiring special handling by separating them into distinct groups or excluding them from the migration based on specific requirements. The migration process described here is unique and might vary based on your case requirements. In the following code example, tables are grouped based on ${groupsize} of 600 GB:
[ec2-user@ip-10-0-0-40 ~]$ ./pg_both.sh
Please enter database connection details:
Database name [postgres]:
Database user [postgres]:
Database host [localhost]: pg-dms-target.caub0zqkqtdt.us-east-1.rds.amazonaws.com
Database port [5432]:
Database password:
Testing database connection...
Connection successful!
Creating plpgsql procedure...
CREATE PROCEDURE
Procedure created successfully!
Executing the procedure...
Enter p_n value: 600
Enter p_schema_name: admin
Enter p_table_name: table_mapping
CALL
Procedure executed successfully!
Executing SELECT query...
*********************************************************
Tables are grouped based on 600GB size
*********************************************************
1(10,11,...) --> Nonpartitioned table
2(20,21....) --> Nonpartitioned table(LOB)
3(30,31...) --> Partitioned table
4(40,41...) --> Partitioned table(LOB)
5(50,51...) --> High DML table
0(0,99) --> Ignore or skip/special handling table
**********************************************************
Query Results:
partitioned step substep table_in_group Total_size_GB
NO 0 0 2 0.00
NO 1 0 52 332.71
NO 1 1 2 837.89
NO 2 0 13 413.36
NO 2 1 2 467.77
NO 2 2 1 408.13
NO 2 3 1 648.07
NO 2 4 1 1440.51
NO 2 5 1 1620.33
NO 5 0 1 7.57
YES 3 0 6 0.62
YES 4 0 12 147.91
YES 5 0 1 28.99
Detailed Group Summary:
Group number 00 will have 2 tables with size of 0 GB comprising ignored objects.
Group number 10 will have 52 tables with size of 333 GB with no partitions.
Group number 11 will have 2 tables with size of 838 GB with no partitions.
Group number 20 will have 13 tables with size of 413 GB with no partitions but containing lob fields.
Group number 21 will have 2 tables with size of 468 GB with no partitions but containing lob fields.
Group number 22 will have 1 table with size of 408 GB with no partitions but containing lob fields.
Group number 23 will have 1 table with size of 648 GB with no partitions but containing lob fields.
Group number 24 will have 1 table with size of 1,441 GB with no partitions but containing lob fields.
Group number 25 will have 1 table with size of 1,620 GB with no partitions but containing lob fields.
Group number 30 will have 6 tables with size of 1 GB with partitions.
Group number 40 will have 12 tables with size of 148 GB with partitions and containing lob fields.
Group number 50 will have 2 tables with size of 37 GB with high DML change.
Now that the PLPGSQL procedure has grouped the tables under the different steps and groups, you need to generate a list of the tables under every group, which can then be used to create AWS DMS tasks. Final group numbers are generated by concatenating two columns, step and substep. For example, step 1 and substep 0 combined to become group number 10 with 52 tables and a size of 340 GB.
Similarly, the following groups are also created:
Group number 00 will have 2 tables with size of 0 GB comprising of ignored objects.
Group number 10 will have 52 tables with size of 333 GB with no partitions.
Group number 11 will have 2 tables with size of 838 GB with no partitions.
Group number 20 will have 13 tables with size of 413 GB with no partitions but containing lob fields.
Group number 21 will have 2 tables with size of 468 GB with no partitions but containing lob fields.
Group number 22 will have 1 table with size of 408 GB with no partitions but containing lob fields.
Group number 23 will have 1 table with size of 648 GB with no partitions but containing lob fields.
Group number 24 will have 1 table with size of 1,441 GB with no partitions but containing lob fields.
Group number 25 will have 1 table with size of 1,620 GB with no partitions but containing lob fields.
Group number 30 will have 6 tables with size of 1 GB with partitions.
Group number 40 will have 12 tables with size of 148 GB with partitions and containing lob fields.
In the preceding output, tables are grouped as close to the desired group size of 600 GB as possible. For example, group 10 contain 52 tables with a total size of 333 GB. Two huge tables with a size of 838 GB have been kept in a separate AWS DMS task as group 11 so as not to split a single table. Depending on the number of tables and table sizes, some groups will be either smaller or larger than the desired group size of 600 GB. Therefore, a database will have 11 tasks by grouping them based on partition, nonpartition LOB, and DML volume.
Next, use the following script to extract the tables under different groups into respective files:
#!/bin/bash
# Collect database connection details
echo "Please enter database connection details:"
read -p "Database name [postgres]: " DB_NAME
DB_NAME=${DB_NAME:-postgres}
read -p "Database user [postgres]: " DB_USER
DB_USER=${DB_USER:-postgres}
read -p "Database host [localhost]: " DB_HOST
DB_HOST=${DB_HOST:-localhost}
read -p "Database port [5432]: " DB_PORT
DB_PORT=${DB_PORT:-5432}
read -p "Schema name for table_mapping_groups: " usr
usr=${usr:-admin}
read -s -p "Database password: " password
DB_PASSWORD=$password
# Export variables for psql to use
export PGPASSWORD="$DB_PASSWORD"
# Function to execute psql query and return result
execute_query() {
psql -U "$DB_USER" \
-h "$DB_HOST" \
-p "$DB_PORT" \
-d "$DB_NAME" \
-t -A \
-c "$1"
}
# Test connection
echo -e "\nTesting database connection..."
if ! execute_query "SELECT 1;" > /dev/null 2>&1; then
echo "Error: Could not connect to the database. Please check your credentials."
exit 1
fi
echo "Connection successful!"
# Generate parfile equivalent
echo "Generating step/group combinations..."
execute_query "SELECT DISTINCT concat(step, groupnum)
FROM ${usr}.table_mapping_groups
WHERE owner = '${usr}'
AND step IS NOT NULL" > parfile.lst
# Remove any existing files
rm -rf ADMIN_TAB*
# Process each combination
while IFS= read -r combination
do
echo "Generating table list for step and group ${combination}"
execute_query "
SELECT object_name
FROM ${usr}.table_mapping_groups
WHERE concat(step, groupnum) = '${combination}'
" > "${usr}_TAB_${combination}.lst"
done < parfile.lst
# Clear password from environment
unset PGPASSWORD
echo -e "\nScript execution completed"
After the script runs, the following files are generated with table names:
As part of this demonstration, you created a few tables in the source PostgreSQL database and 1 procedure. You can clean up these tables and drop the procedure by using the following drop statements after the task grouping has been noted:
DROP TABLE TABLE_MAPPING;
DROP PROCEDURE admin.both;
DROP TABLE MST_DBA_TAB_MOD;
DROP TABLE TABLE_MAPPING_GROUPS;
Conclusion
In this post, we explored methods for leveraging system catalogs and statistics views to examine database dimensions, operational load, and hardware configurations. These methods can help you determine the ideal number of tasks and table clusters for effective database transfer using AWS DMS. By integrating database object information with source database hardware specifications, you can make well-informed choices during the transfer design phase. We suggest also reviewing the Best practices for AWS Database Migration Service User Guide to optimize your transfer tasks.
We welcome your insights and questions in the comments section.