AWS Database Blog
How Wiz achieved near-zero downtime for Amazon Aurora PostgreSQL major version upgrades at scale using Aurora Blue/Green Deployments
This is a guest post by Sagi Tsofan, Senior Software Engineer at Wiz, in partnership with AWS.
Wiz, a leading cloud security company, identifies and removes risks across major cloud platforms. Our agent-less scanner processes tens of billions of daily cloud resource metadata entries. This demands high-performance, low-latency processing, making our Amazon Aurora PostgreSQL-Compatible Edition database, serving hundreds of microservices at scale, a critical component of our architecture.
Our motivation to upgrade from PostgreSQL 14 to 16 was driven by its significant performance gains, including enhanced parallel query, faster aggregations, and up to 300% improved COPY performance. Version 16 also offered enhanced security, smarter query planning, and reduced CPU and I/O usage, making it a highly desirable upgrade for our infrastructure.
In this post, we share how we upgraded our Aurora PostgreSQL database from version 14 to 16 with near-zero downtime using Amazon Aurora Blue/Green Deployments.
Challenges with minimizing downtime for Aurora PostgreSQL database major version upgrades
At Wiz, we manage hundreds of production Aurora PostgreSQL clusters and faced a significant challenge as major version upgrades which use pg_upgrade internally, typically caused around 1 hour of downtime in our environment, likely due to the large size and heavy workloads of our clusters. This level of disruption was unacceptable for customers relying on continuous service. We needed a better solution. Our approach, described in the next section, reduced downtime from approximately 1 hour to 30 seconds.
Solution overview
To overcome these downtime challenges, we implemented our own DB Upgrade Pilot – an automated, eight-step flow based on Aurora Blue/Green Deployments with custom enhancements. Aurora Blue/Green Deployments already provide a way to copy a production database to a synchronized staging environment where changes (like version upgrades) can be made without affecting production, with eventual promotion typically under one minute. Our solution builds upon this foundation by adding fully automated validation steps, enhanced synchronization monitoring, and a complete end-to-end orchestration that requires just a single command to execute the entire upgrade process across our diverse Aurora PostgreSQL fleet. Designed for minimal downtime, maximum operational safety, and low resource overhead, this solution seamlessly creates a mirrored production environment, provides stable synchronization, and performs sub-minute switchover, all with a single command. The following diagram illustrates the automated flow.
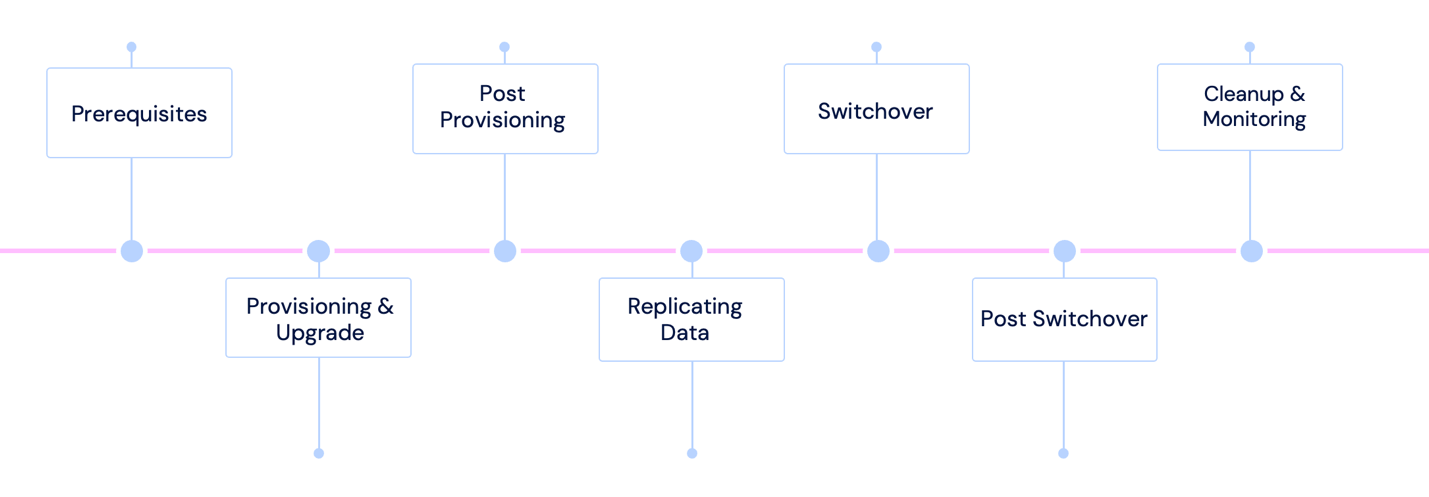
Overall Automated Flow
In this section, we outline the high-level steps of DB Upgrade Pilot, and in the next section, we will dive deeper into each of them.
- Prerequisites – Takes cluster snapshot and configures necessary database parameters like logical replication, DDL logging, and temporarily deactivates specific extensions.
- Provisioning & Upgrade – Creates Aurora Blue/Green Deployments and provisions a synchronized replica (green) of the production database (blue), targeting PostgreSQL 16.
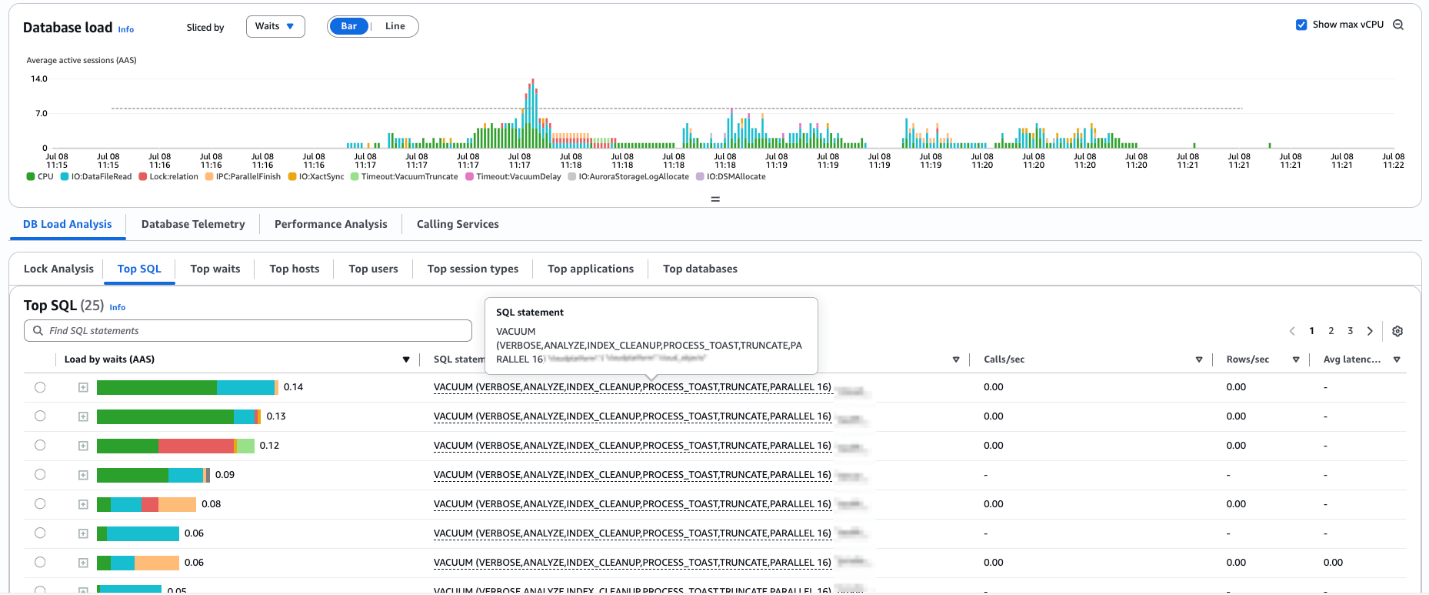
- Post-Provisioning – Executes VACUUM ANALYZE on green cluster tables to optimize performance and refresh database statistics after the upgrade.
- Replicating Data – Tracks replication lag through CloudWatch metrics and performs data verification health checks between environments.
- Switchover – Validates zero replication lag and stops long-running transactions on the blue cluster and performs the actual switchover from Blue to Green using Aurora Blue/Green Deployments.
- Post-Switchover – Re-enables and upgrades extensions, then resumes data pipeline ingestion after confirming compatibility
- Cleanup & Monitoring – Decommissions old infrastructure by removing deletion protection and cleaning up the Aurora Blue/Green Deployment. Maintains real-time visibility tracking replication lag and system metrics throughout the process.
Prerequisites
In this first step of the automation flow, DB Upgrade Pilot prepares the required components and configurations:
- Create a cluster snapshot before proceeding to enable rollback capability if issues occur during the process
- Enable
rds.logical_replicationwithin the database parameters, required for the logical replication used by Aurora Blue/Green Deployments - Set
log_statementparameter toddlto record all schema-changing operations in the database logs. This helps identify DDL operations that might cause replication failures during execution.
Important: Be aware that this setting may log sensitive information, including passwords in plain text, in your log files. - Deactivate extensions that can interfere or break logical replication, such as
pg_cronandpg_partman - Due to the parameter group change, validate the writer instance is in sync mode and configurations are synchronized, restarting if needed
- Temporarily pause data ingestion pipelines to minimize writes and Write-Ahead Log (WAL) generation
The following diagram shows DB Upgrade Pilot in Amazon Elastic Kubernetes Service (Amazon EKS) connecting to Amazon Aurora PostgreSQL 14 to apply the necessary prerequisites.
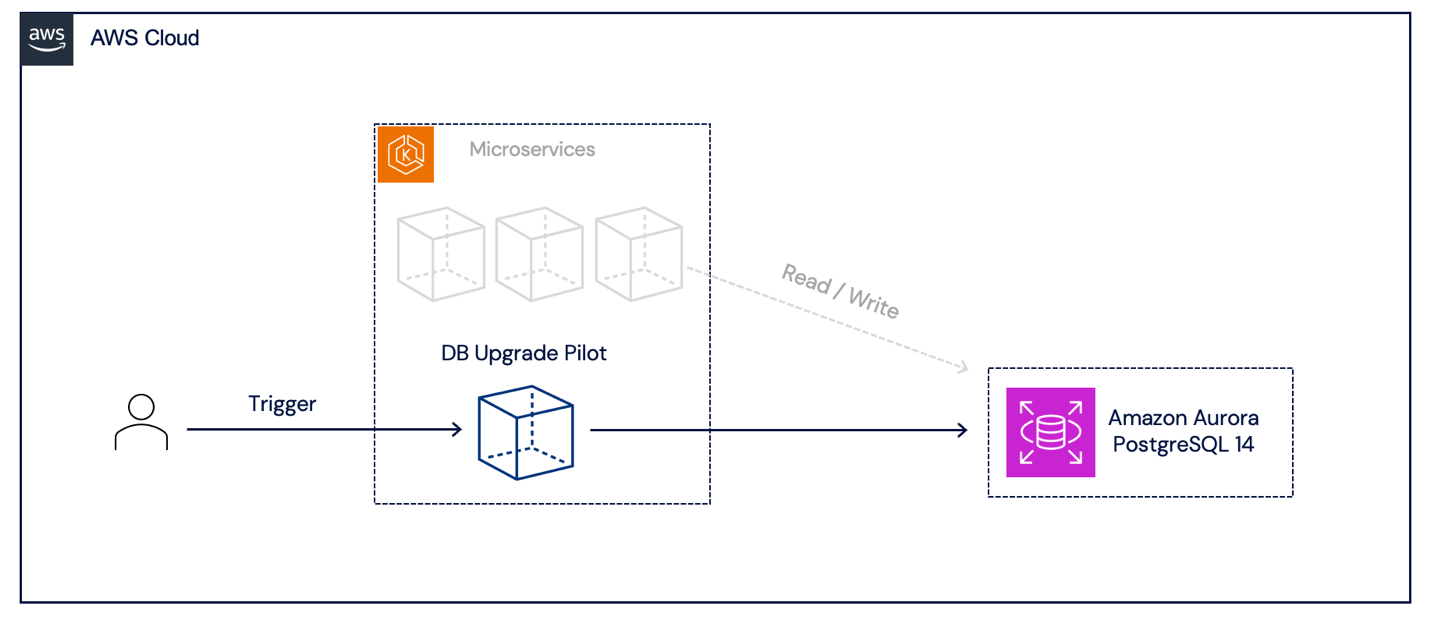
Provisioning and Upgrade
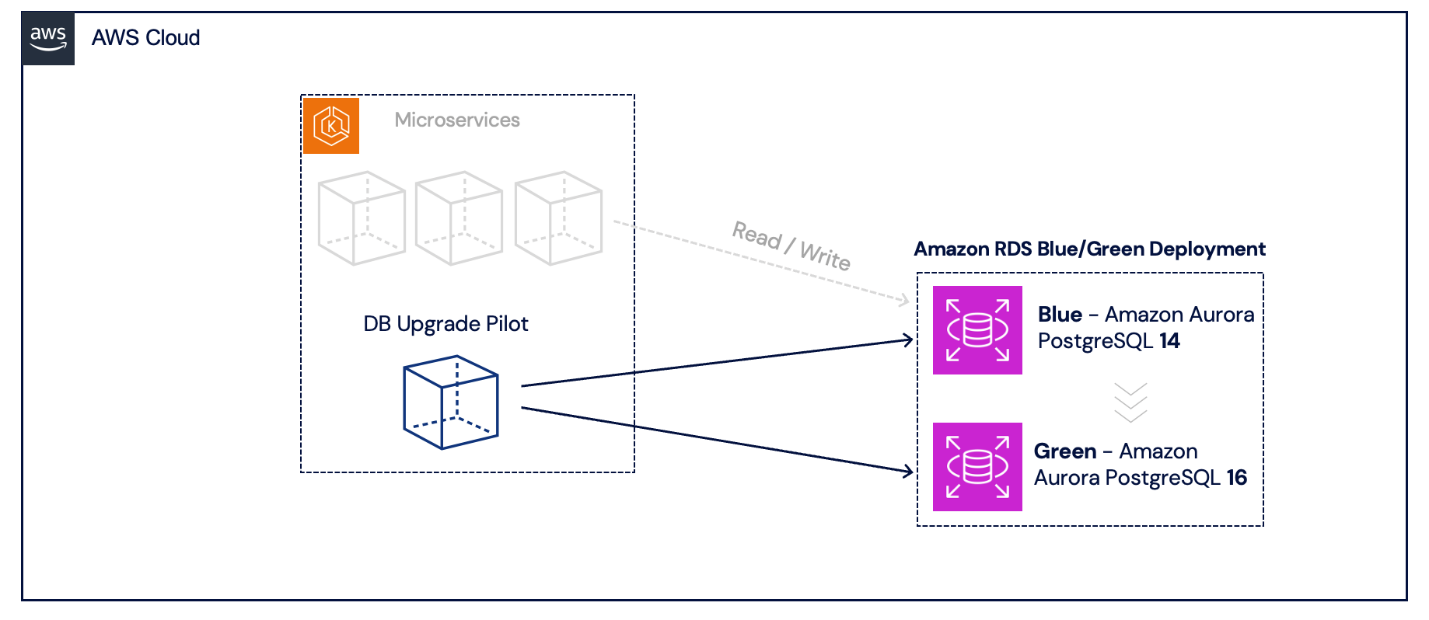
Next, we create a new Aurora Blue/Green Deployment, targeting to PostgreSQL version 16. The Aurora Blue/Green Deployment provisions a synchronized replica (green) of the production (blue) database. You can make updates to the replica/green database without impacting the original/blue database. It’s important to proceed with caution during this process, improper changes to the green environment can break replication, potentially requiring a full reprovision. Once you’re done with your changes and replication has fully caught up, you can switch over to the green environment with minimum downtime.
During this provisioning phase, the blue cluster maintains full service to our customers. The following diagram illustrates DB Upgrade Pilot triggering the Aurora Blue/Green Deployment and the WALs being replicated.
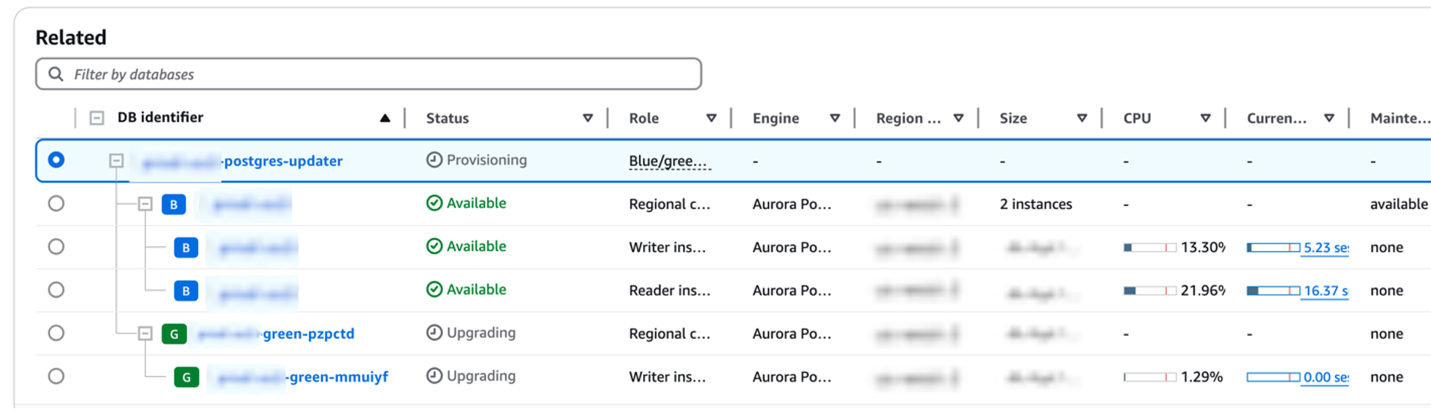
The following screenshot of the Aurora console shows the Aurora Blue/Green Deployment with the green cluster being upgraded to PostgreSQL version 16.
Post-Provisioning
Following the upgrade, DB Upgrade Pilot connects to the green cluster and runs a VACUUM ANALYZE on the tables to optimize performance and refresh database statistics. Because pg_upgrade does not transfer table statistics during the upgrade process, recalculating them is strongly recommended to ensure optimal performance from the outset. It is recommended to perform this step before making the green database available for application traffic.
The following screenshot shows Amazon CloudWatch Database Insights details of the green cluster tables being vacuumed after provisioning.
Replicating Data
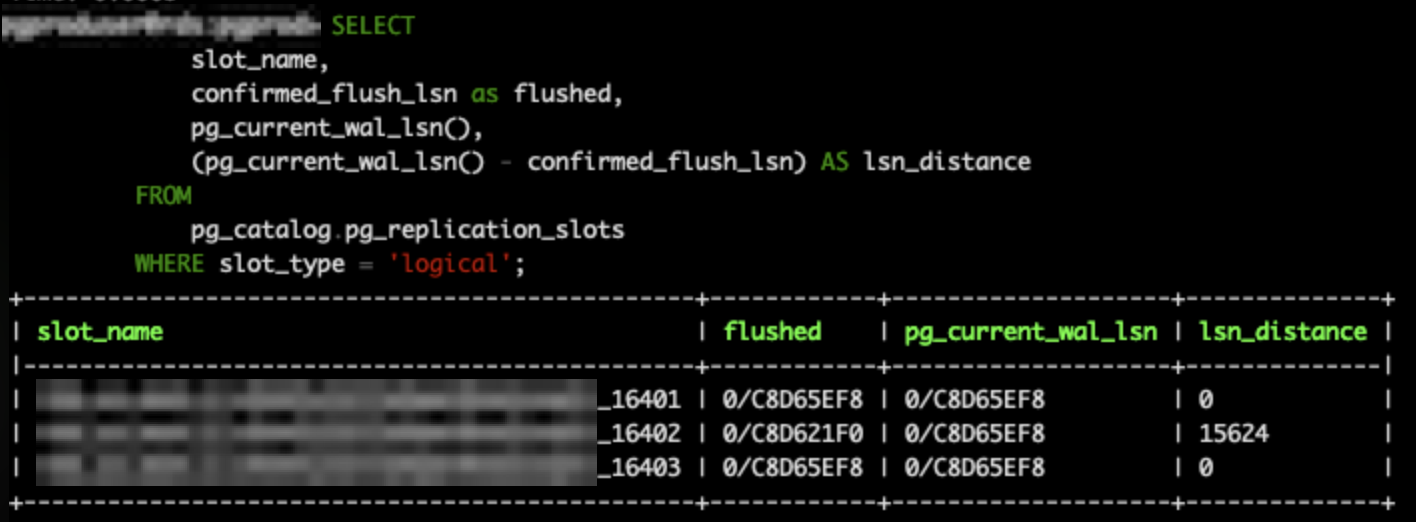
DB Upgrade Pilot monitors the replication lag before the final cutover via the Amazon CloudWatch OldestReplicationSlotLag metric. The following SQL query identifies logical replication slots and calculates the lsn_distance, indicating WAL data not yet flushed or confirmed by the subscriber (replication lag):
The following screenshot shows sample output for the SQL query, the lsn_distance of 15624 for the second slot indicates there’s a lag in replication for that particular slot, while the other two slots (with distance 0) are fully caught up.
Prior to the switchover, DB Upgrade Pilot automatically runs essential sanity checks to confirm the green environment’s readiness. This involves comprehensive data verification (row counts, key business data) and rigorous database statistics validation for optimal query performance and planning.
Switchover
This critical phase begins by confirming that the green environment is fully synchronized with the blue environment (zero replication lag); if the synchronization is incomplete, the operation fails and automatically retries. The DB Upgrade Pilot then identifies and stops long-running transactions on the blue environment to prevent switchover delays, as the process must wait for all active queries to complete. After the switchover is complete, the automation automatically resubmits any interrupted transactions to the green environment to ensure data continuity.
The following screenshot shows the Amazon CloudWatch OldestReplicationSlotLag metric, tracking WAL data on the source from the most lagging replica. The switchover triggers when replica lag reaches zero, which was built as part of our automation.
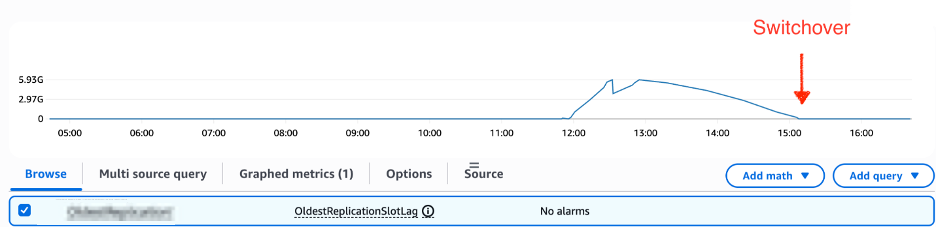
The switchover is initiated with a 5-minute timeout, if it exceeds this window, the process is automatically reverts, leaving the blue environment in its original state. After the switchover is successful, production traffic is immediately redirected from the blue cluster to the new green cluster, with minimal downtime of 30 seconds. Aurora Blue/Green Deployments preserves the database endpoint when redirecting traffic from Blue to Green, ensuring no application changes are needed for endpoint management.
Post-Switchover
After confirming that traffic is successfully routing to the new PostgreSQL 16 cluster, we proceed to upgrade and re-enable the pg_cron and pg_partman extensions. We then test these extensions to verify their compatibility with PostgreSQL 16.
Monitoring
We created a Grafana dashboard to display real-time metrics of the system, as shown in the following screenshot. It is part of DB Upgrade Pilot which includes a dedicated dashboard built for this specific upgrade flow. The dashboard tracks critical metrics including replication lag between clusters and data pipeline ingestion rates, while measuring the duration of each migration step. This monitoring allows our team to quickly identify any issues during the upgrade process and provides detailed visibility into the migration progress.
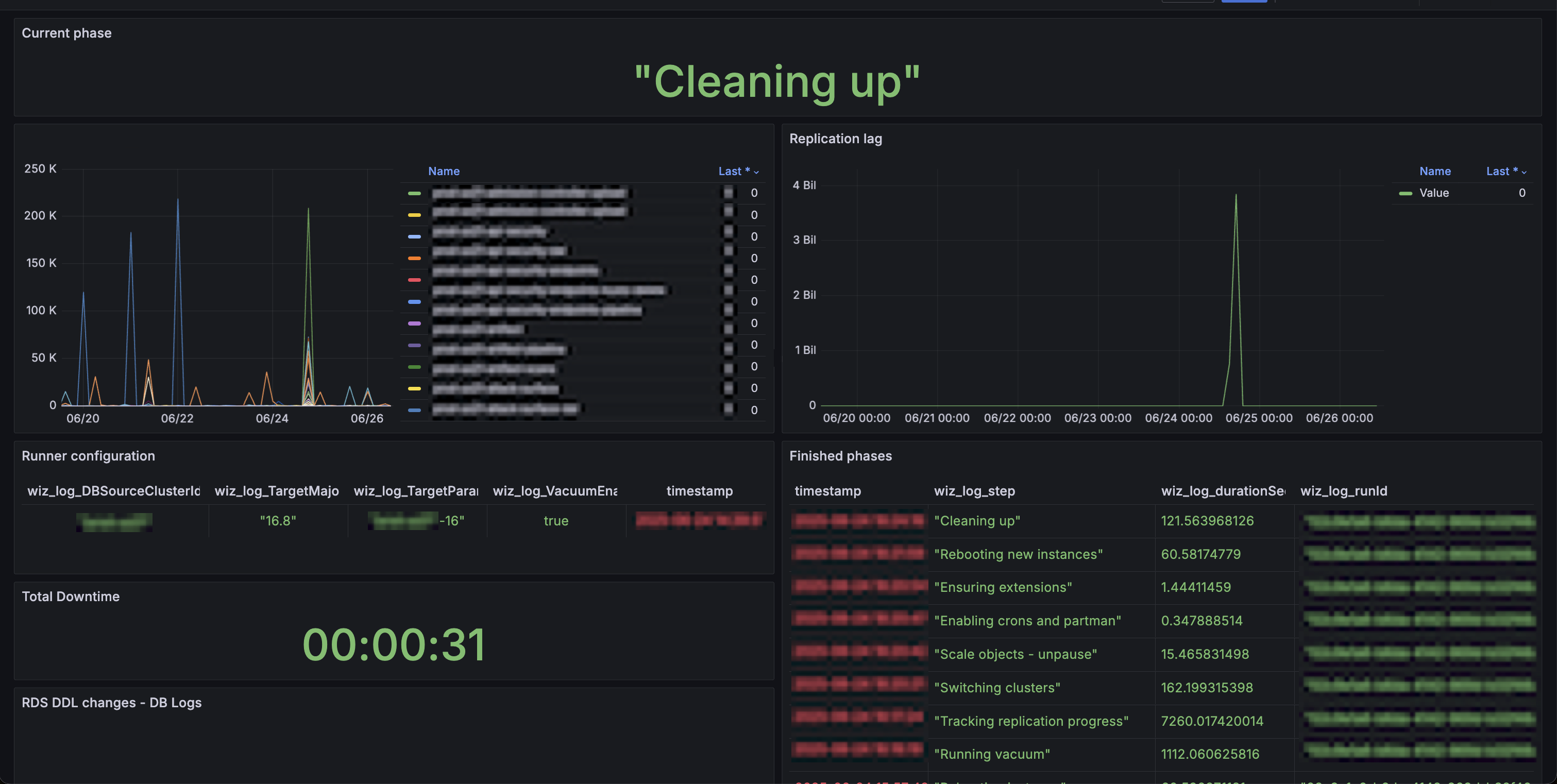
Here’s a breakdown of each section in the screenshot:
- Current phase (upper center) – Shows the DB Upgrade Pilot current step
- Backlogs (upper left) – Monitors our ingestion pipeline, which we pause during the upgrade to minimize generation of writes and Write-Ahead Logging (WAL) generation
- Replications (upper right) – Shows replication lag. We expect a sharp decrease after the upgrade. If not, it signals a problem, and we may need to revert and retry
- Runner Configuration (lower left) – Displays the parameters used to trigger the upgrade, such as target version, source cluster, whether to run a vacuum, and other custom settings
- Finished Steps (lower right) – Lists completed upgrade steps and their durations to help track progress and spot bottlenecks
- Total Downtime (lower left) – Measures the cluster’s unavailability during the switchover, critical for assessing customer impact
- DDL Changes – Captures any schema changes during the upgrade that could break replication and require rollback
Cleanup
In the final step of the workflow, we decommission the old infrastructure. This involves removing its deletion protection and deleting the Aurora Blue/Green Deployment with the former blue cluster, resulting in a clean and cost-effective transition.
Production traffic is now fully running on the upgraded PostgreSQL 16 instance while the old PostgreSQL 14 clusters are gracefully retired, leaving behind a streamlined, high-performance database infrastructure. This marks a significant milestone in our database management capabilities, setting a new standard for Aurora PostgreSQL database major version upgrades.
Safety measures
The integrity and stability of our production environment was paramount throughout this automated upgrade journey. DB Upgrade Pilot is built with multiple layers of comprehensive safety measures to mitigate risks, including:
- Automatic rollback capability – Our system automatically reverts to a stable state if issues (such as replication lag not catching up, DDL changes that break the replication, or Blue/Green failures) are detected prior to switchover. Automatic rollback is supported only until the switchover step, not after traffic shifts
- Robust steps validation – Each upgrade step includes built-in validations, making sure prerequisites are met and the environment is healthy before proceeding
- Idempotency – DB Upgrade Pilot can be safely rerun if a step fails or is interrupted, preventing unintended side effects and enhancing reliability
Challenges and lessons learned
Although our solution delivers impressive results, no complex process is without its hurdles. During development, we encountered several challenges that yielded invaluable lessons:
- Testing – Thorough, iterative validation across all scenarios and workloads (lab, staging, dogfooding, production simulations) proved absolutely essential. With hundreds of production database clusters of varying sizes (4xl, 8xl, 24xl) and unique workloads, comprehensive testing helped us harden our tooling and uncover critical edge cases. One such finding led to the creation of our “idle transaction purger”: during Blue/Green Deployments in PostgreSQL, replication slot creation can fail if idle transactions block consistent snapshots. Our purger continuously detects and terminates these idle transactions, ensuring reliable slot creation
- Replication lag monitoring – We learned not to switch over with high replication lag, because this increases downtime. We implemented safeguards to achieve minimal lag before switchover; high lag causes both environments to become unresponsive while replication catches up. To learn more, refer to Aurora Blue/Green Switchover best practices
- Schema change impact – Certain operations, like materialized view refreshes, can break logical replication, which requires you to rerun the entire process from the start. This led us to log the DDL statements for vital visibility, enabling troubleshooting of replication failures. Close monitoring of the Grafana dashboard status is paramount
Results and future steps
Our automated approach reduced average downtime from approximately 1 hour to 30 seconds per cluster with minimal overhead, providing near-zero business disruption during Aurora PostgreSQL database major version upgrades. Our future plans include expanding the system capabilities to support future major versions upgrades, integrating support for FULL VACUUM operations (which causes down time) and other critical maintenance jobs with minimal customer impact.
Conclusion
In this post, we shared how Wiz achieved near-zero downtime for Aurora PostgreSQL database major version upgrades using DB Upgrade Pilot that leverages Aurora Blue/Green Deployments. This process greatly reduced their downtime and resulted in minimal customer impact.
Try out Aurora Blue/Green Deployments for your Aurora PostgreSQL major version upgrades, and share your thoughts in the comments.