AWS Database Blog
Identifying and resolving performance issues caused by TOAST OID contention in Amazon Aurora PostgreSQL Compatible Edition and Amazon RDS for PostgreSQL
In PostgreSQL, data storage is optimized through a variety of mechanisms, one of which is The Oversized-Attribute Storage Technique (TOAST). This mechanism helps efficiently store large data types by moving them out-of-line into a separate table. While TOAST is an integral part of the database’s architecture, it can sometimes lead to unexpected performance issues, particularly when the underlying object identifiers (OIDs) approach their maximum limit. When the OID space runs out, PostgreSQL struggles to assign new OIDs for new rows, significantly slowing down operations such as INSERT (or UPDATE).
In this post, we explore the challenges of OID exhaustion in PostgreSQL, focusing on its impact on TOAST tables and how it leads to performance issues. We will cover how to identify the problem by reviewing wait events, session activity, and table usage. Additionally, we discuss practical solutions, from cleaning up data to more advanced strategies such as partitioning.
What is an OID?
An OID is a system-wide unique identifier used by PostgreSQL to reference database objects such as tables, indexes, functions, and more. These identifiers play a vital role in PostgreSQL’s internal operations, allowing the database to efficiently locate and manage objects.
Understanding TOAST in PostgreSQL
TOAST is PostgreSQL’s method for efficiently handling large data types—such as TEXT, BYTEA, and JSON—that can’t fit into a standard database page (typically 8 KB in size). Instead of storing large values directly in the main table, PostgreSQL stores them in a separate table specifically designated for TOASTed data.
TOAST performs compression and stores large field values out of line. Field values exceeding 2KB (adjustable via toast_tuple_target) are compressed using a configurable algorithm (such as pglz) to reduce their size. The default_toast_compression parameter allows you to configure the compression algorithm. If compression alone is insufficient, values are split into 2KB chunks stored in a separate TOAST table, created automatically for tables with TOAST-able columns. In the main table, these large fields are replaced with small TOAST pointers referencing the chunks.
By default, TOAST uses the EXTENDED storage strategy, which enables both compression and out-of-line storage. The typstorage column of pg_type determines the storage method for each column. Other strategies, such as MAIN , PLAIN, EXTERNAL can be chosen to modify TOAST behavior for specific columns. For example, PLAIN disables TOAST entirely for a column, while EXTERNAL stores data out-of-line without compression. This process is transparent to users and is enabled by default. TOAST tables are automatically created for tables containing columns with data types such as TEXT, BYTEA, or JSONB.
For tables with a data set that’s eligible for TOASTing, OIDs are assigned to uniquely identify each chunk of oversized data stored in the associated TOAST table. Each chunk is associated with a chunk_id, which helps PostgreSQL organize and locate the chunks efficiently within the TOAST table.
Performance Challenges with OID assignment
TOAST uses OIDs to track large out-of-line data stored in a separate table. However, the OID system in PostgreSQL has a fundamental limitation—it can only handle up to 4 billion OIDs (2^32). As the TOAST table grows and more data is stored, the available OIDs begin to deplete. After this occurs, PostgreSQL faces significant challenges:
- Reusing freed OIDs: PostgreSQL attempts to reuse OIDs from previously deleted or updated data. While this can work in theory, it’s not always efficient.
- OID search loops: If the freed OIDs don’t provide enough gaps or if there are too many OIDs in use, PostgreSQL can get stuck in a search loop, trying to find an available OID. This exhaustive search can slow insert operations on tables with TOAST columns down to a crawl, as PostgreSQL spends an increasing amount of time locating a free OID.
This search for free OIDs leads to significant performance bottlenecks, particularly during inserts that require the data to be TOASTed. The more data you have in the TOAST table, the greater the likelihood that OID exhaustion will occur, causing delays in insert operations. In large-scale production systems, where tables grow substantially in size or store large objects, the OID exhaustion problem becomes more pronounced, especially if the TOAST mechanism isn’t optimized for those use cases. It’s important to take proactive steps to avoid performance bottlenecks caused by this issue.
Symptoms of OID exhaustion
When PostgreSQL experiences performance degradation because of OID exhaustion in TOAST tables, the symptoms typically surface through seemingly simple operations, such as inserting new rows. What would normally be a quick operation now takes significantly longer. Here’s what you might observe when OID exhaustion starts affecting your database:
- A simple
INSERTnow takes much more time to complete. - The time taken for each
INSERTcan vary, sometimes running fast, other times taking much longer. - The delay occurs only when the
INSERTinvolves TOASTed data. Normal inserts without TOAST proceed as expected. - While the following log entries may appear during this issue, performance degradation can occur even in their absence. If other symptoms align with the problem description, proceed to the identifying the problem regardless of these log entries’ presence.
LOG: still searching for an unused OID in relation "pg_toast_20815"
DETAIL: OID candidates have been checked 1000000 times, but no unused OID has been found yet.
Identifying OID exhaustion
When you notice slow inserts and irregular latency patterns, you’ll want to determine the root cause. While TOAST table OID exhaustion can be tricky to diagnose, you can use monitoring tools to verify if this is indeed the issue you’re facing.
Step 1: Investigating active sessions
Start by checking the pg_stat_activity view, which shows the current activity of all PostgreSQL sessions. If you’re experiencing slow inserts, run the following query to identify any active sessions that are waiting on events such as LWLock:buffer_io or LWLock:OidGenLock:
Sample output:
If you see that many sessions are waiting on LWLock:OidGenLock, this is a strong indication that PostgreSQL is struggling to generate new OIDs.
Step 2: Checking Database Insights
The wait events LWLock:buffer_io and LWLock:OidGenLock appear in Performance Insights during operations that require assigning new OIDs. High Average Active Sessions (AAS) for these events typically point to contention during OID assignment and the associated resource management, particularly in environments with high data churn, extensive large object usage, or frequent object creation.
A couple of examples from Database Insights:
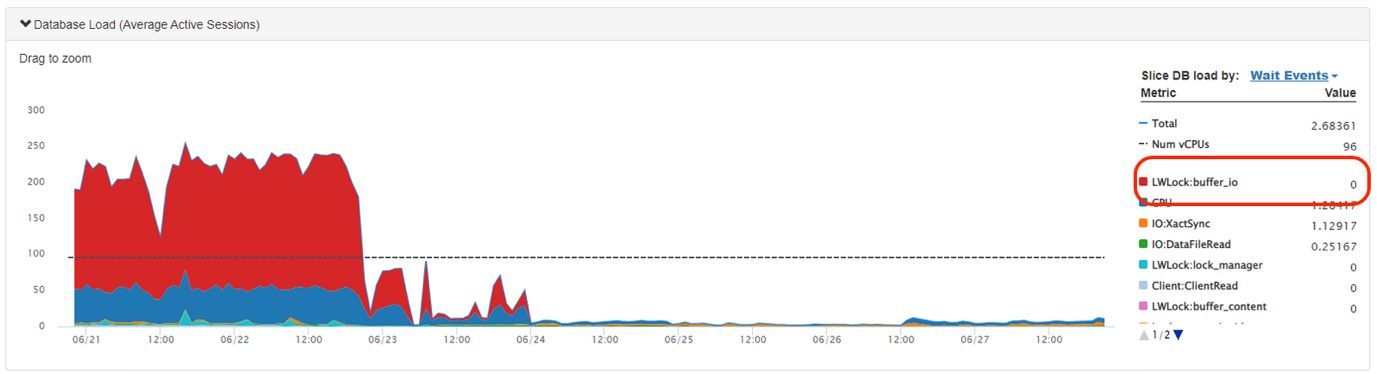
The following figure shows LWLock:buffer_iowhich indicates waiting for I/O operations on shared buffers. High occurrences may suggest disk bottlenecks or excessive I/O, possibly related to large TOAST indexes and OID uniqueness checks.
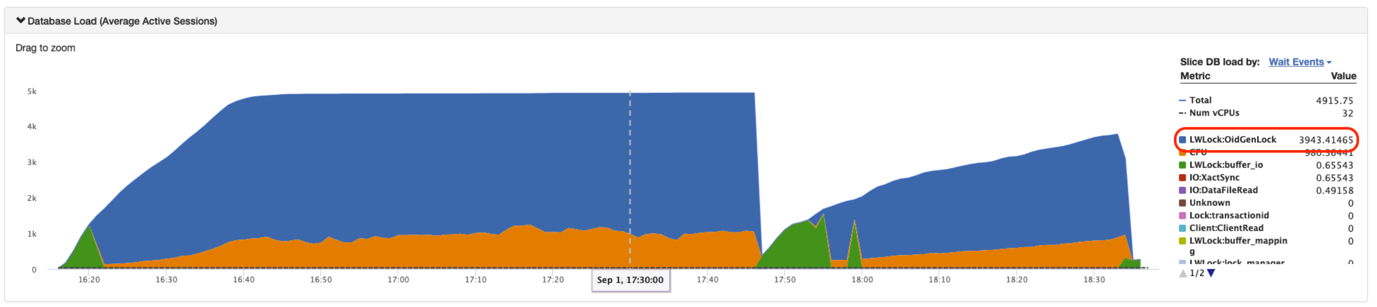
The following figure shows OidGenLock which hows waiting for new OID allocation. High contention here can result from concurrent TOAST operations, frequent object creation, or heavy system catalog activity
Step 3: Checking TOAST table size and OID usage
After confirming that OID exhaustion is the likely culprit, examine the TOAST table directly. Use the following query to check if the table in question uses TOAST and to get an overview of the table size:
Sample output:
Check the size of the table, it should be noticeably very large.\dt+ test_tableSample output:
In this case, the table is 12 TB, which suggests that the TOAST table might be storing a significant amount of data.Next, check the current OID usage within the TOAST table. If the OID count is close to the maximum limit (4 billion), this is a clear sign of potential OID exhaustion. Note that depending on the number of records in the TOAST table, this query could take some time, so it’s important to set expectations accordingly.
Sample output:
In this example, the OID count is 4,293,066,164, which is very close to the OID limit of 4 billion.
Finally, check the maximum OID used in the TOAST table by running the following query:
Sample output:
If the maximum chunk ID is near the 4 billion mark, this is a strong indication that the OID space is either exhausted or very close to it.
Note that while seeing the MAX(chunk_id) near 4 billion is an indication of a problem, it doesn’t necessarily mean the issue is imminent. OIDs can be freed when toast records are deleted, so it’s more accurate to check the total count of distinct chunk IDs to confirm if the system is nearing the limit.
Solutions to OID exhaustion in TOAST tables
When facing OID exhaustion in TOAST tables, there are several ways to mitigate the issue, ranging from immediate fixes to long-term strategies. While short-term solutions can provide temporary relief, long-term approaches, such as partitioning, provide the most scalable options. In the following sections, we explore both immediate and long-term solutions for handling OID exhaustion in PostgreSQL.
Immediate solutions
This section outlines the solutions that can be implemented immediately to address the identified issues, providing actionable steps for rapid deployment and ensuring minimal disruption to the operations.
1. Cleaning up existing data
One immediate way to address OID exhaustion is to clean up existing data in the TOAST table. By deleting obsolete or unnecessary rows, you can free up OIDs for future use. This can help reduce the pressure on the OID system and improve insert performance temporarily.
Considerations:
- This approach works well initially, but as the table grows, the cleanup opportunities might dwindle. If the data volume keeps increasing, cleaning up data might become less effective.
- If the table is large and frequent vacuuming is necessary, cleanup might also introduce challenges using
VACUUM, because the database needs to reclaim space effectively after each delete operation.
Downside:
- Over time, the space for cleanup might diminish, leading to a situation where there’s no significant improvement from continued data deletion.
- The regular
VACUUMprocess might become more challenging, especially if the cleanup volume is large.
2. Archiving data to a new table
Another short-term solution is to archive data to a new table, essentially moving outdated or less frequently accessed data out of the live table. This can help reduce the number of records in the TOAST table, allowing PostgreSQL to manage OIDs more efficiently.
Approach:
- Create a new table, move the data to the new table, and then purge the live table.
- This reduces the size of the original table and might alleviate the OID exhaustion issue for a time.
Downside:
- Archiving and purging can still create challenges with routine use of
VACUUMon the live table, because it might not fully resolve the underlying issue of OID exhaustion if the table grows significantly over time. - Like data cleanup, archiving can provide temporary relief but is not a long-term solution.
3. Writing to a new table
A more proactive solution is to write data to a new table. Here’s how to approach it:
- Rename the existing table to
mytable_old(for example, rename tasks totasks_old). - Create a new empty table,
mytable, with the same structure. - Direct all new writes to the
mytabletable. - Create a view that combines the old and new tables using
UNION ALL. This makes both tables appear as one logical table to the application, which can continue to use the same query structure.
This approach allows you to continue inserting data while bypassing the OID exhaustion issue in the old table.
Downside:
- If there are any
UPDATEoperations on the old table, they could bring back the OID exhaustion issue. A workaround is to implement logic in the application layer that directs usingUPDATEon the new table. - For example, when an update is required, the application can:
- Fetch the record from the old table.
- Create a new record with the updated values.
- Insert the updated record into the new table.
While this approach works, it could increase response time and introduce latency because of the extra logic required.
- Additionally, over time, all records in the old table might eventually be updated, which could cause OID exhaustion to resurface, even in the new table.
Recommendation:
- This approach is viable in the short term but isn’t scalable over time. The OID exhaustion problem might recur as the new table grows and more updates occur.
Long-term and scalable solutions: Table partitioning
The best long-term solution to OID exhaustion is table partitioning. Partitioning divides a large table into smaller, more manageable pieces, known as partitions. Each partition can have its own TOAST table and OID space, effectively spreading the OID usage across multiple partitions and preventing any single partition from reaching the OID limit.
Benefits:
- Reduces the risk of OID exhaustion in any single partition.
- Improves performance by reducing the amount of data PostgreSQL needs to scan during queries and inserts.
Considerations:
- Partitioning requires careful design to ensure data is distributed evenly across partitions. For instance, choosing the right column for partitioning (for example, date or region) can make a significant difference in performance.
- Careful consideration of query patterns and indexing strategies is crucial, as improper partitioning implementation can severely impact database performance.
Monitoring OIDs and TOAST table usage
To prevent OID exhaustion and maintain optimal performance, it’s important to monitor OID usage in TOAST tables. This section outlines some queries for tracking OID consumption and identifying potential issues.
UPDATE behavior and OID management
In PostgreSQL, UPDATE operations don’t preserve the original OID of a row. Instead, a new OID is generated for the updated row, which can result in faster OID consumption, particularly when updates occur frequently on TOASTed columns.
For instance, consider the following:
Before the update:
After performing an UPDATE operation:
After the update:
Notice that new OIDs are assigned for the updated rows, which contributes to further OID consumption and exacerbates OID exhaustion in the TOAST table.
Useful queries for monitoring OID usage
Here are some useful queries to monitor and manage OID usage in TOAST tables:
Query 1: Get tables with non-empty TOAST relations and maximum OID usage
This query identifies tables with active TOAST relations and reports the maximum OID used in each table and is helpful in pinpointing TOASTed relations that are nearing the OID limit.
Sample output:
Query 2: Count the number of OIDs used per TOAST relation
To track the OID usage within specific TOAST relations, run the following query to count the number of distinct chunk IDs. This helps to understand how many OIDs are being used by each TOAST relation, providing insight into potential OID exhaustion.
Sample output:
Conclusion
OID exhaustion in TOAST tables is a subtle but critical performance issue that can have significant consequences for PostgreSQL databases, especially as data volumes grow. By understanding the root cause of this problem and using monitoring tools such as Database Insights, you can identify OID consumption patterns and take corrective action. Immediate solutions such as cleaning up or archiving data, along with more scalable strategies such as partitioning or migrating to a new table, can help restore performance.
However, addressing OID exhaustion is not a one-time fix. Continuous monitoring of OID usage and TOAST table size is essential to prevent the issue from resurfacing. By adopting best practices and staying proactive in managing large data types, you can ensure that your PostgreSQL database remains efficient, scalable, and capable of handling growing workloads without hitting the OID limit.