AWS Database Blog
Introducing Graph Store Protocol support for Amazon Neptune
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Neptune’s database engine is optimized for storing billions of relationships and querying with millisecond latency. The W3C’s Resource Description Framework (RDF) model and the popular Labeled Property Graph model are both supported. This post discusses W3C Recommendations RDF 1.1, the SPARQL 1.1 query language, and focuses on Neptune’s recently released support for SPARQL 1.1 Graph Store HTTP Protocol.
Graph Store Protocol overview
This post assumes the reader has a level of comfort with RDF modeling and building Java applications that interact with graph models. However, to set the stage, let’s provide some background and context.
Neptune provides various HTTP endpoints to support operations on the associated graph database cluster. The Neptune SPARQL endpoint refers to an RDF dataset. An RDF dataset is a collection of RDF named graphs. Named graphs provide a logical way of separating the data in your graph database. In any RDF dataset, you have exactly one default graph and zero or more named graphs. Each named graph in an RDF dataset is uniquely identified by an Internationalized Resource Identifier (IRI).
It’s important to understand that graph databases define datasets with either an inclusive or exclusive assumption. In a database operating with an inclusive assumption, all triples are considered part of the default graph. In a database operating with an exclusive assumption, the default graph is limited to only those triples that aren’t part of any named graph. Neptune uses the inclusive assumption, so retrieving the default graph returns all triples including those from named graphs, and SPARQL queries where no graph is specified return results from all triples in the database.
SPARQL 1.1 provides a query-based approach to fetching, inserting, updating, and deleting RDF triples. Graph Store Protocol supports these actions on entire named graphs in the dataset. This can make certain types of applications much more efficient. To illustrate, we walk through some examples using Apache Jena, a popular open-source Java framework for building RDF graph applications. Jena makes extensive use of Graph Store Protocol behind the scenes.
Before we dive in, let’s go over the basics. Graph Store Protocol is an HTTP protocol. The addition of Graph Store Protocol support introduces a new endpoint URL:
The query string is used to specify either the default graph, ?default, or a named graph, ?graph=http%3A//www.example.com/named/graph.
The Graph Store Protocol endpoint implements the four HTTP methods:
- HTTP GET – The GET method retrieves a serialization of the specified graph:
Alternatively:
- HTTP PUT – The PUT method replaces or creates the specified graph with the RDF payload provided in the request:
- HTTP POST – The POST method merges the provided RDF payload with the specified graph if it exists, or creates it if it doesn’t yet exist:
- HTTP DELETE – The DELETE method deletes the triples associated with the specified graph:
The HTTP HEAD method of the recommendation is not implemented. The intent of the HEAD method is to return whether or not the specified named graph exists in the RDF dataset—providing the success status of the GET method without actually returning the serialization of the specified named graph. You can use the following SPARQL query as an alternative to answer this question:
There are a few nuances that we discuss as we build the examples.
Use case
Graph Store Protocol operates on whole named graphs. The examples that follow describe parts of a hypothetical public transit application. In this application, we receive schedule information separately from several agencies in the transportation district. New data is published whenever changes make updates necessary. Among buses, subway, light rail, rail, and ferry services, there are thousands of trip and route variations every day, updated by their respective scheduling agencies. Once received, the data is processed and ingested into Neptune, where it supports various customer-facing applications.
Our graph data model uses named graphs to segment the RDF dataset by agency/route. This is an example of a graph-per-resource pattern. Other commonly used patterns include graph-per-source where each publishing agency is modeled using a separate named graph corresponding to the publishing agency and graph-per-version where each update is modeled using a named graph corresponding to the published version. An excerpt of the graph is shown in the diagram and the corresponding TriG serialization.
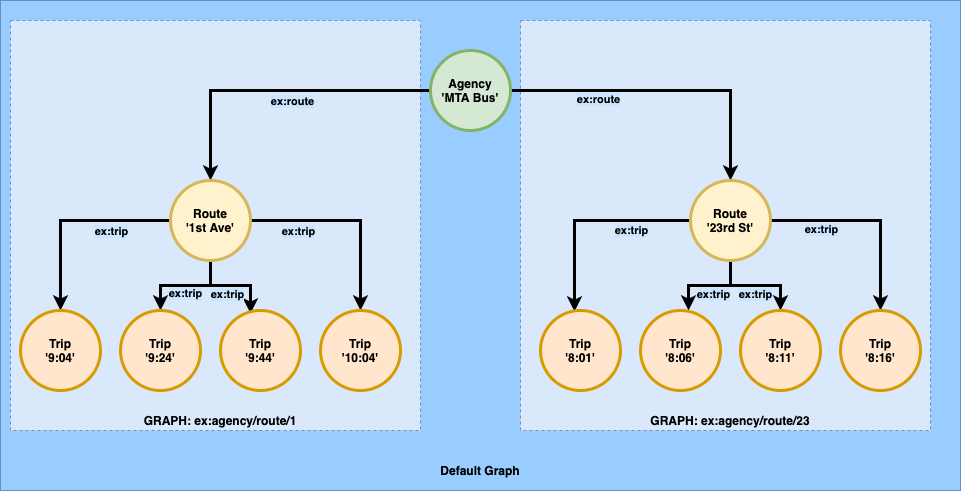
Using graph-per-* patterns provides benefits for data management of your application and can allow server-side code to be written to be data driven. Retrieving or updating a route does not require a specially built SPARQL CONSTRUCT query to retrieve the route graph – it can be returned with a single Graph Store Protocol GET operation – and it works for any named graph IRI.
This approach to modeling, together with Graph Store Protocol, streamlines the interactions, management and maintenance of the graph model.
Code examples
Apache Jena uses Graph Store Protocol behind the scenes of the RDFConnection implementation. These examples can also be configured to use IAM-based authentication. The examples that follow illustrate the methods that use Graph Store Protocol functionality. A full tutorial on Apache Jena is beyond the scope of this post.
To get started, you first create a connection as follows:
When we’re initially loading up the graph database with our transportation schedules, we add each agency or route schedule to Neptune as a named graph. Adding or appending a graph to a dataset corresponds to HTTP POST. This protocol method is implemented in Apache Jena with the connection.load(graph_iri, path_to_rdf_file) method. POST adds the specified named graph, or appends to it if it already exists. See the following code:
Our example transportation agency regularly publishes new route schedules. When these updates are published, they supply a completely new schedule for each affected route. Graph Store Protocol supports replacing a named graph using the HTTP PUT method. This protocol method is implemented in Apache Jena with the connection.put(graph_iri, path_to_rdf_file) method:
Occasionally, a route is discontinued. In this case, we need to delete the route from Neptune. Graph Store Protocol uses the HTTP DELETE method to delete a named graph. This protocol method is implemented in Apache Jena with the connection.delete(graph_iri) method:
Now that we have our transportation data in Neptune, a common operation is to retrieve a route into an RDF model for further processing. Graph Store Protocol uses the HTTP GET method to retrieve a named graph as a model. This protocol method is implemented in Apache Jena with the connection.fetch(graph_iri) method:
Summary
Graph Store Protocol support in Neptune provides efficient methods to interact with complete named graphs within an RDF dataset. This can streamline building graph applications using Neptune, and tools that support the Graph Store Protocol like Apache Jena. For more details, see the Using the SPARQL Graph-Store HTTP protocol (GSP) in Amazon Neptune.
If you have any questions, comments, or other feedback, share your thoughts on the Amazon Neptune Discussion Forums.
About the Author
 Chris Smith is a Principal Graph Architect on the AWS Data Lab Resident Architect Team focusing on Amazon Neptune. He works with customers to solve business problems using Amazon graph technologies. Semantic modeling, knowledge representation, and NLP are subjects of particular interest.
Chris Smith is a Principal Graph Architect on the AWS Data Lab Resident Architect Team focusing on Amazon Neptune. He works with customers to solve business problems using Amazon graph technologies. Semantic modeling, knowledge representation, and NLP are subjects of particular interest.