AWS Database Blog
Migrate full-text search from SQL Server to Amazon Aurora PostgreSQL-compatible edition or Amazon RDS for PostgreSQL
In today’s data-driven world, the ability to search and retrieve information from vast datasets is crucial. Although some commercial and open source databases similar to PostgreSQL excel at handling structured data, PostgreSQL also offers a powerful tooling for searching unstructured or semi-structured data. PostgreSQL provides built-in full-text search (FTS), and other extensions like pg_trgm and pg_bigm for text searching. Traditional SQL queries using LIKE and ILIKE operators and regular expressions are excellent for exact textual matching and structured data retrieval. However, they may have limitations in searching large blocks of unstructured text, such as documents, articles, or even product descriptions.
There are various factors to take into account when migrating from a commercial database like SQL Server to an open source database like PostgreSQL. Migrating full-text search from SQL Server to Amazon Aurora PostgreSQL-Compatible Edition requires modifying queries and schema structure because the implementation of full-text search is different in both databases and AWS Schema Conversion Tool (AWS SCT) doesn’t automatically convert full-text search code.
SQL Server FTS is designed to search for specific words, phrases, or even word forms (called stemming) within unstructured or semi-structured text data. It enables fast searching, ranking, and indexing of textual content, making it an invaluable asset for applications that need to handle vast amounts of text-based information.
In this post, we show you how to migrate full-text search in Microsoft SQL Server to Amazon Aurora PostgreSQL using text searching data types tsvector and tsquery. We also show you how to implement FTS using pg_trgm and pg_bigm extensions.
Prerequisites
For this post, we use the AdventureWorks2019 sample database to show how to migrate FTS from SQL Server 2019 Standard Edition to PostgreSQL. The following are the high-level steps to implement FTS on a SQL Server database:
- Enable full-text search for the database AdventureWorks2019:
- Create a full-text catalog:
A full-text catalog is a logical container for full-text indexes. It organizes the full-text index data and defines the language-specific word breakers and stemmers.
- Define a full-text index on the columns containing text data that you want to search:
- Use AWS SCT and AWS Database Migration Service (AWS DMS) to convert and migrate the AdventureWorks2019 database from SQL Server to Amazon Aurora PostgreSQL.
Refer to Migrate SQL Server to Amazon Aurora PostgreSQL using best practices and lessons learned from the field for migration best practices. For this post, we migrate the ProductDescription table from SQL Server to Amazon Aurora PostgreSQL using AWS SCT and AWS DMS.
PostgreSQL has a few options for searching through text: exact search, pattern matching, regular expressions, and full-text search. In the following section, we show you how to implement FTS in PostgreSQL on the migrated database to achieve similar results.
Full-text search in PostgreSQL
The LIKE operator, ILIKE operator and regular expression are used in a query’s WHERE clause for string pattern-based matching searches using wildcard characters. Search results can be ranked based on how close they are with the search pattern, LIKE and ILIKE do not provide the ranking facility and ignore frequently used words like “the”, “is,” and so on. PostgreSQL built-in full-text search provides search functionality through tsvector and tsquery data types along with related functions, operators, and parameters.
The tsvector data type represents a preprocessed and transformed version of text data, optimized for efficient full-text searching. It stores information about the individual words or tokens in a text document, allowing for quick and accurate text search operations. You can use the to_tsvector function to convert text data (documents) to tsvector data, which is used for searching data efficiently.
The tsquery data type is composed of one or more lexemes, which are the basic units of text used for searching. Lexemes can be simple words or tokens, and they can also be specified in various forms, such as prefix or exact forms. By combining lexemes and operators, you can create complex search conditions to find the most relevant results for your text search queries. to_tsquery is used to convert the search text to lexemes, which can be used to search against tsvector columns and values. For example, if you use to_tsquery on the text “He is running in the park,” the lexemes generated are “he,” “run,” and “park.” Words like “is,” “in,” and “the” are removed because they’re stop words. The word “running” is stemmed to “run” and words are made lowercase.
In the following sections, we’ll demonstrate several use-cases for full-text search, and provide strategies for how you can migrate them from SQL Server to Amazon Aurora PostgreSQL-compatible and Amazon RDS for PostgreSQL.
CONTAINS predicate with AND operator
Simple FTS queries in SQL Server use the CONTAINS predicate. The CONTAINS predicate in Transact-SQL provides a versatile way to perform advanced FTS in SQL Server databases. It supports various search conditions, proximity searches, wildcards, and thesaurus features, allowing you to tailor your queries to match specific requirements.
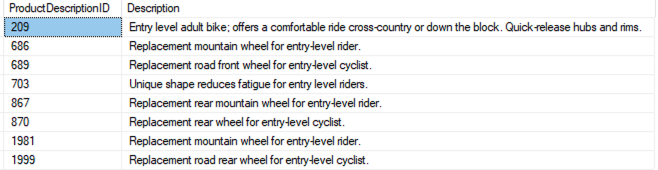
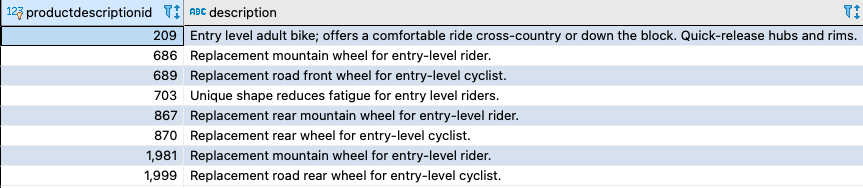
In the following sample query, the CONTAINS predicate checks for the words “entry” and “level” in the Description column:
You can rewrite the query in PostgreSQL using the to_tsvector and to_tsquery functions as follows, using the default built-in text search dictionary value pg_catalog.simple. This configuration is driven by the parameter default_text_search_config.
| SQL Server |
|
|
| PostgreSQL |
|
|
CONTAINS predicate with OR operator
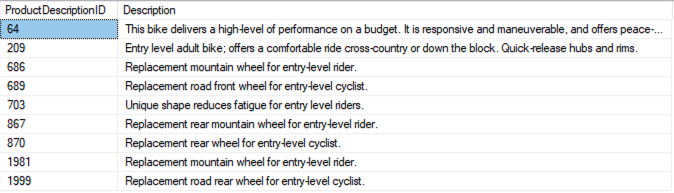
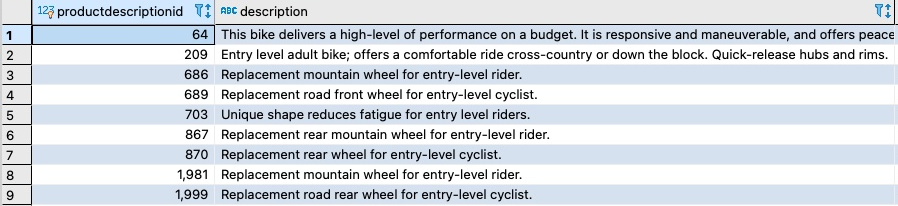
This is similar to the earlier use case using the CONTAINS predicate, except that the check is performed using the OR operator. In the following sample query, the predicate checks for “entry,” “level,” or both:
You can rewrite the query in PostgreSQL using the to_tsvector and to_tsquery functions as follows and using the default built-in text search dictionary value pg_catalog.simple.
| SQL Server |
|
|
| PostgreSQL |
|
|
FREETEXT predicate
The FREETEXT predicate in Transact-SQL (T-SQL) is used to perform full-text searches in SQL Server databases. Unlike the CONTAINS function, which requires specific terms and conditions, FREETEXT allows more flexible and natural language-based searches.
In the following sample queries, FREETEXT checks for the words “entry” or “level” and their forms (using stemming) in the Description column:
You can rewrite the query in PostgreSQL using the to_tsvector and to_tsquery functions as follows using the configuration value pg_catalog.english. This configuration uses english_stem and a simple dictionary to convert tokens to lexemes. A lexeme, therefore, represents a normalized form of a word or token that can be indexed and used for search operations.
| SQL Server |
|
|
| PostgreSQL |
|
|
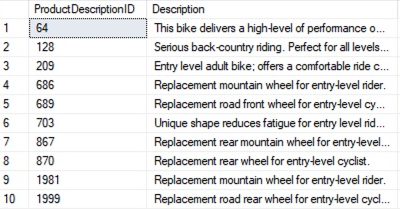
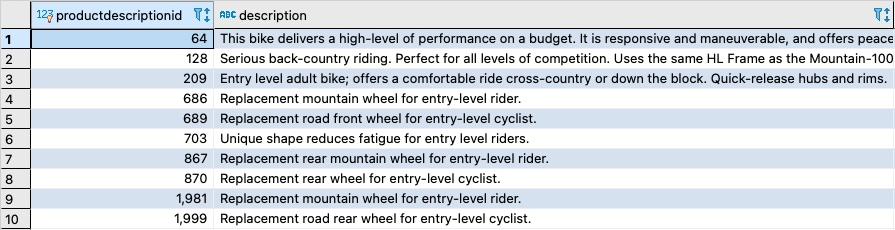
FREETEXTTABLE function with RANK
FTS in SQL Server can generate an optional score (or rank value) that shows the relevance of the data returned by a full-text query. This rank value is calculated on every row and can be used as an ordering criteria to sort the result set of a query by relevance. The rank values show only a relative order of relevance of the rows in the result set. The actual values are unimportant and typically differ each time you run the query. The rank value doesn’t hold any significance across queries.
In the following sample queries, FREETEXTTABLE checks for the words “entry” or “level” and their forms (using stemming) in the Description column and also gets the RANK information:
In PostgreSQL, the ts_rank function is used to calculate the relevance ranking of search results based on their match to a specific query. The ranking is computed using a numerical value that represents how closely a document matches the search terms in the query.
| SQL Server |
|
|
| PostgreSQL |
|
|
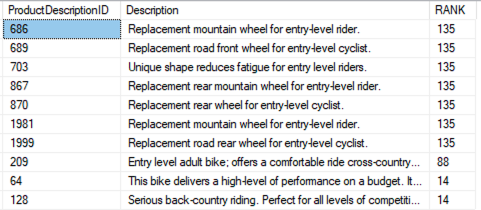
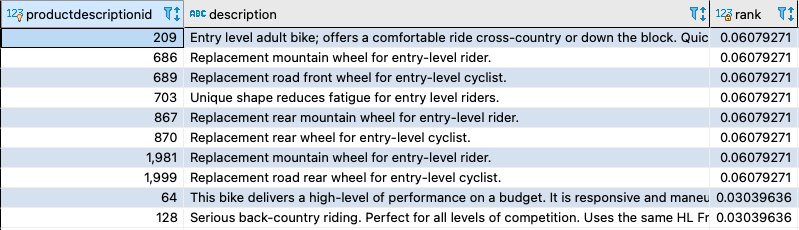
The ts_headline function is used to generate a summarized version of a document’s text that highlights the most relevant portions matching a specific search query. This function is useful for creating search result snippets or headlines that provide context to users about why a certain document applies to their search. The following screenshot shows the output of the PostgreSQL query’s headline column generated using the ts_headline function.

CONTAINSTABLE and FORMSOF functions with RANK
The FORMSOF function in SQL Server is used to perform inflectional searches. Inflectional searches involve searching for various forms of a word, such as plurals, verb tenses, or related word forms. This can help you find relevant documents even if they contain variations of the search term, thereby improving the search accuracy.
In the following sample queries, CONTAINSTABLE checks for the word “gear” and their forms (using INFLECTIONAL) in the Description column and also gets the RANK information:
In PostgreSQL queries, the phrases are first broken into words or tokens, and these words are normalized and stemmed to form base words (lexemes) using the pg_catalog.english FTS configuration. These lexemes are going to be the same for different forms (stemming) of a word. Therefore, this will automatically handle inflectional searches.
| SQL Server |
|
|
| PostgreSQL |
|
|


Improving query performance in PostgreSQL
For the sample PostgreSQL queries shown earlier, the to_tsvector function gets the tsvector values out of the Description column from the productdescription table. In the following sections, we show you various options to improve query performance.
Solution 1: Use a GIN index
The GIN (Generalized Inverted Index) index in PostgreSQL is a popular indexing method used to efficiently speed up the search for complex data types such as JSON and full-text search. The standard database index, a B-tree, is designed to work for testing equality, whereas GIN is designed for search patterns that work over nested or composite data structures to allow for more expressive search patterns. By indexing components of complex data types separately, GIN indexes enable faster queries on arrays, JSON data, and text search operations. This makes GIN indexes a valuable tool for improving the performance of queries involving complex data structures in PostgreSQL databases.
In this approach, you create an expression-based GIN index on the column of interest in the productdescription table.
- Run the following command:
If the table has millions of rows, you can increase the
maintenance_work_memconfiguration parameter at session level to speed up the index creation time.maintenance_work_memspecifies the maximum amount of memory in MB to be used by maintenance operations like the creation of INDEX—by default(PostgreSQL), it’s 64 MB. - Run the following EXPLAIN ANALYZE query:
The output shows a bitmap index scan being performed on productdescription_gin_index, which improves the query performance. The following screenshot shows the explain plan before creating the index.
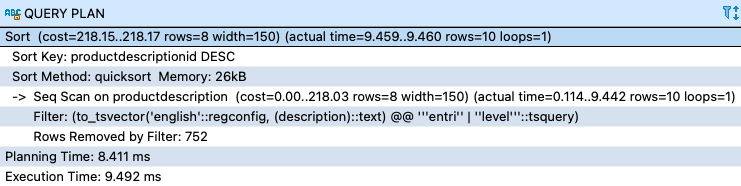
The following screenshot shows the explain plan after creating the index.
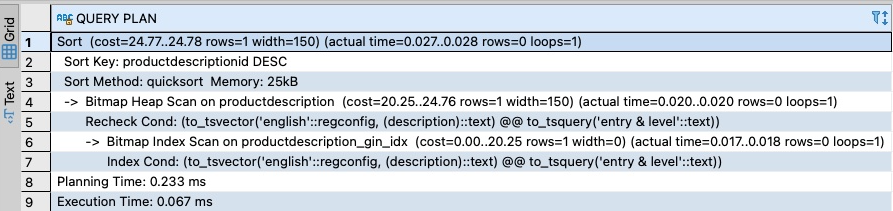
In this case, we can see a speedup in query performance when using the GIN index. While in general, using a GIN index for full-text search in PostgreSQL can help improve performance, you’ll need to be aware of other performance tradeoffs, including the time required to build an index and additional storage an index requires.
Solution 2: Use a stored generated column
In this approach, you create a computed column description_tsv that holds the tsvector value out of the description column from the table followed by a GIN index on the computed column.
- Run the following commands:
- Run the following sample EXPLAIN ANALYZE query:
The output shows that a bitmap index scan is being performed on productdescription_gin_index, which in this case demonstrated an improvement in query performance:

Full-text search in PostgreSQL using the pg_trgm extension
In PostgreSQL, the pg_trgm extension is implemented for text search functionalities utilizing trigrams. Trigrams are essentially sets of three consecutive characters extracted from a given string. By employing trigrams, users can identify resemblances or matches in text patterns within strings by comparing the number of trigrams that align between the strings, alongside the predefined similarity threshold parameter established prior to executing the search.
The pg_trgm extension provides operators that can be used to create trigram indexes on text columns in the table that need to be searched. This index allows for efficient similarity operations on the indexed columns. The extension provides the three similarity operations: similarity (%), word_similarity (<%), and strict_word_similarity (<<%). The threshold parameters for respective operations are pg_trgm.similarity_threshold, pg_trgm.word_similarity_threshold, and pg_trgm.strict_word_similarity_threshold, which can be set to a value between 0 (no similarity) and 1 (perfect match). The functions similarity(), word_similarty(), and strict_word_similarity() are used to calculate the similarity score. You can use pg_trgm as shown in following code:
- Run the following command to create the pg_trgm extension:
CREATE EXTENSION pg_trgm; - Run the following command to create the GIN index on the productdescription column:
- Run the following command to set the similarity_threshold configuration value to 0.2. similarity checks for common trigrams between two strings and returns a value between 0–1.

- Run the following command to set the word_similarity_threshold configuration value to 0.6. word_similarity checks for the common trigrams between strings at word level.

- Run the following command to set the strict_word_similarity_threshold configuration value to 0.6. strict_word_similarity is like word_similarity but it considers common trigrams only when both words are identical.

- Run the following command to drop the index and enable sequential scan:
Full-text search in PostgreSQL using the pg_bigm extension
The pg_bigm extension in PostgreSQL enhances full-text search capabilities, particularly for languages with complex character sets like Asian languages.
A bigram is a group of two consecutive characters taken from a string. The extension uses a bigram indexing approach, which involves breaking text into pairs of consecutive characters and building an index based on these bigrams. The pg_bigm extension provides the bigm_similarity() function, bigm similarity operator = %, and pg_bigm.similarity_limit threshold parameter. You can use pg_bigm as follows:
- Run the following command to create the pg_bigm extension. For instructions to create the extension in Amazon RDS for PostgreSQL, refer to Using PostgreSQL extensions with Amazon RDS for PostgreSQL.
- Run the following command to create the GIN index on the productdescription column:
- Run the following command to set the similarity_limit configuration value to 0.15. similarity checks for common bigrams between two strings and returns a value between 0–1.

- Run the following command drop the index and enable sequential scan:
Conclusion
In this post, we showed you how to migrate FTS from SQL Server to PostgreSQL and compared a few common use cases. Migrating the full-text search from SQL Server to PostgreSQL requires a manual rewrite of code. For further reading, refer to the limitations of PostgreSQL’s text search features. We also showed you how to use the pg_trgm and pg_bigm extensions in PostgreSQL to implement FTS.
Share your thoughts with us in the comments.