.NET on AWS Blog
AWS Transform SQL Server to PostgreSQL Schema Validation in .NET Application Modernization
Sayan Ghosh, Yuhao Zhang, Uday Kiran Erukulla, Srinivasa Varadan Saragur Madabhushi, Koushik Rajagopal, Khurram Khawaja, Vikas Babu Gali and Luke Huan contributed to this article.
Migrating databases from Microsoft SQL Server to Amazon Aurora PostgreSQL – Compatible Edition is a common modernization strategy for organizations seeking to reduce licensing costs, improve scalability, and leverage open-source database technologies. When migrating SQL Server databases to Aurora PostgreSQL, schema transformation is only the beginning of the journey. The real challenge lies in validating that every table, constraint, stored procedure, and trigger migrated correctly and that they behave identically in the target PostgreSQL environment. A single missed decimal precision change, or an incorrectly transformed stored procedure, can lead to data corruption, application failures, or incorrect business logic in production.
Traditional migration testing that relies on manual spot-checks, smoke tests, or basic row-count comparisons, cannot catch subtle semantic differences. You need a systematic approach that validates not just whether objects exist, but whether they’re functionally equivalent.
In this post, we show how AWS Transform uses a three-tier validation model, combining structural analysis, semantic verification, and behavioral testing to provide comprehensive schema validation for SQL Server to PostgreSQL migrations. We also describe how an AI agent powered by Amazon Bedrock analyzes validation results, clusters issues by root cause, and assigns severity grades to help you prioritize remediation efforts.
Solution Overview
The schema validation solution in AWS Transform provides automated, end-to-end validation of migrated database schemas by deploying both source and target to live database engines and running checks against them directly. The validation is independent of how the target schema was produced, whether rule-based tooling, an agentic solution, or a hand-written generative AI (GenAI) conversion pipeline. Figure 1 illustrates how source and target schemas flow through the validation workflow.
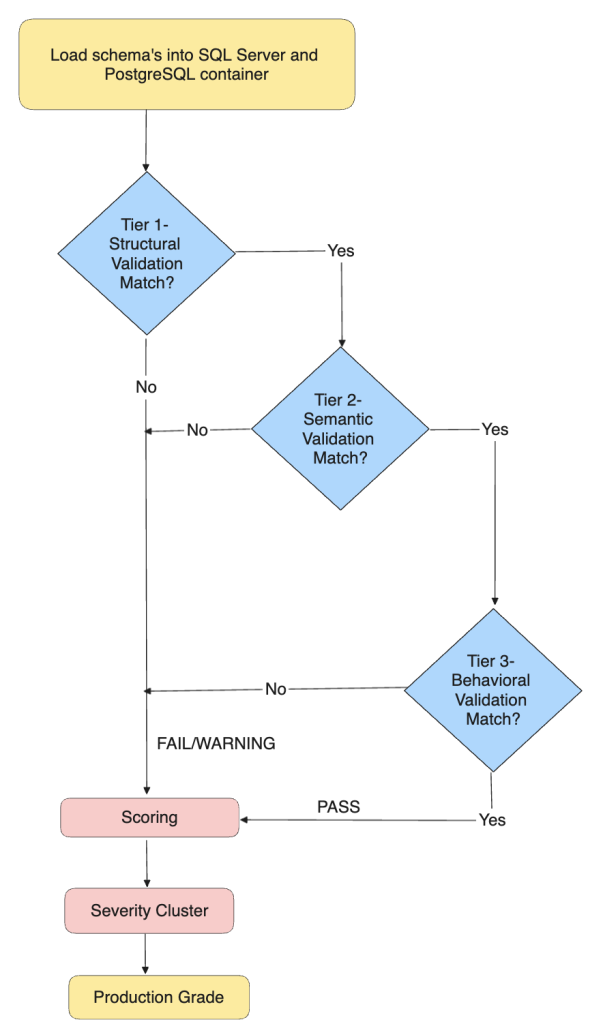
Figure 1. The end-to-end schema validation workflow
As shown in Figure 1, the validation proceeds as follows:
- The source SQL Server schema and the target PostgreSQL schema are each loaded into their dedicated Amazon Elastic Container Service (Amazon ECS) container.
- Both schemas enter Tier 1 (structural), where validation workflow programmatically checks each object for existence on the target side.
- Objects that pass structural checks advance to Tier 2 for semantic equivalence comparison.
- Stored procedures that pass semantic checks advance to Tier 3 (behavioral) for runtime testing.
- Each tier produces per-object verdicts (PASS, FAIL, or WARNING) that accumulate into the scoring layer.
- The expert assessment agent then reviews all verdicts and queries both live databases to verify flagged issues. It then clusters findings by root cause, assigns severity grades, and produces the final production-readiness report.
Walkthrough
Under the hood, this workflow runs as five discrete steps:
- Launches source SQL Server and PostgreSQL validation container on Amazon ECS.
- Loads the source and target schemas into their corresponding validation databases.
- Runs rule-based checks by querying both databases.
- Runs AI expert analysis using an Amazon Strands agent.
- Generates the final validation report.
The validation follows two core principles:
- Live databases, not regex parsing. Validators query each live database directly, reporting what the engine understood rather than what the raw SQL file appears to say.
- Deterministic first, LLM second: Rule-based checks run before the large language model (LLM) layer, and the LLM receives filtered inputs, so that it augments rather than replaces the deterministic signal.
With those principles in mind, the rule-based checks and AI analysis work as follows:
1. Structural Validation (Tier-1)
Objective: Verify that every database object in the source schema exists in the target schema.
This tier queries both the source and target databases directly, running rule-based existence checks in parallel across all schema objects. The following table shows a few examples:
| Object type | What is checked |
| Tables | Confirm each table exists on target with matching columns and nullability rules |
| Constraints | Validate primary keys, foreign keys (including cascade rules), unique constraints, and check constraints |
One non-obvious challenge in structural matching is name normalization. SQL Server is case-insensitive by default, while PostgreSQL folds unquoted identifiers to lowercase and treats them as case-sensitive. PostgreSQL also truncates identifiers at 63 bytes. As a result, two distinctly named SQL Server procedures can collapse to the same PostgreSQL name, and a perfectly migrated table can fail a naive byte-for-byte comparison. To handle this, structural matching normalizes names in stages (case-folding, truncation, quote-stripping) and applies record normalization at each step.
2. Semantic Validation (Tier-2)
Objective: Verify that migrated objects are semantically equivalent, not just structurally present.
While Tier 1 confirms objects exist, Tier 2 checks whether their definitions are semantically equivalent. The checks are rule-based, encoding type-mapping and precision rules across the SQL Server and PostgreSQL type systems. Some examples:
| Check | Example |
| Type mapping | nvarchar(100) to character varying(100) is valid; integer is not |
| Numeric precision | decimal(18,2) must remain numeric(18,2), not numeric(10,0) |
Semantic checks never fabricate equivalence: if normalization fails (e.g., incompatible defaults), the tool raises warnings instead of applying silent corrections. This prevents production issues while avoiding unnecessary alerts.
3. Behavioral Validation (Tier-3)
Objective: Confirm runtime behavior matches expectations.
After Tier 2 validates definitions, Tier 3 tests actual runtime behavior. Two routines can pass structural and semantic checks yet still produce different results caused by stubs, branching bugs, or dialect-specific features that do not survive translation. To find these issues, behavioral validation escalates through three steps:
Step 1: Stub detection
The validator inspects whether the PostgreSQL routine body contains only placeholder logic (for example, BEGIN RETURN 0; END) rather than a meaningful implementation. Because stub generation is one of the most common failure modes in automated conversions, catching it first prevents unnecessary work in later steps.
The following example shows a PostgreSQL stub converted from a SQL Server procedure by an AI agent during transformation:
SQL Server procedure:
--SQL Server procedure
CREATE PROCEDURE BabelFish.bf_collationproperty
@collation_name SYSNAME = 'Traditional_Spanish_CS_AS_KS_WS',
@prop_name VARCHAR(255) = 'CodePage'
AS
BEGIN
SELECT COLLATIONPROPERTY('Traditional_Spanish_CS_AS_KS_WS', 'CodePage') AS 'CodePage'
, COLLATIONPROPERTY('Traditional_Spanish_CS_AS_KS_WS', 'LCID') AS 'LCID'
, COLLATIONPROPERTY('Traditional_Spanish_CS_AS_KS_WS', 'ComparisonStyle') AS 'ComparisonStyle'
, COLLATIONPROPERTY('Traditional_Spanish_CS_AS_KS_WS', 'Version') AS 'Version';
END;
PostgreSQL stub procedure:
--PostgreSQL stub procedure
CREATE OR REPLACE PROCEDURE babelfish.bf_collationproperty(IN collation_name varchar(128) DEFAULT 'Traditional_Spanish_CS_AS_KS_WS', IN prop_name varchar(255) DEFAULT 'CodePage')
LANGUAGE plpgsql
AS $body$
BEGIN
RAISE NOTICE 'Stub: babelfish.bf_collationproperty - needs manual T-SQL to PL/pgSQL conversion';
END;
$body$;
Step 2: Structural validation
The validator examines routine signatures, input/output parameters, and return types on both sides, identifying any structural mismatches that would cause call-site failures in the migrated application.
Step 3: Mutation testing / LLM assessment
The validator generates test inputs, executes them against both databases, and compares the results. A single row-level disagreement serves as a concrete counterexample, showing the routines are not equivalent. If mutation testing is inconclusive, an LLM assessment via Amazon Bedrock evaluates functional equivalence to reach a final verdict.
4. Scoring
Each check produces PASS/FAIL or WARNING per object. The report then presents two deterministic headline scores, identical across runs for the same input:
- Storage Score — Measures schema consistency across data-holding objects (tables, indexes).
- Code Score — Measures functional coverage across executable objects (views, stored procedures, functions, triggers).
These two numbers give you a quick read on migration coverage, but they do not drive the final grade. That is the job of the AI judge (LLM-as-a-Judge); an Amazon Strands agent that acts as an expert reviewer. The rule-based checks answer “What is different?”. The judge answers, “Does it matter, and how should you fix it?”
The AI judge has read-only access to both live databases and can issue its own verification queries to confirm or refute each flagged issue. The agent then groups findings into root-cause clusters. For example, 29 missing triggers from a single missing schema count as one cluster, not 29, and assigns each cluster a severity grade:
| Severity | Criteria |
CRITICAL |
User data loss or corruption |
HIGH |
Silent future failures, or application call will fail |
MEDIUM |
Application may not function as intended |
LOW |
Cosmetic or non-blocking |
The root-cause clustering approach reduces noise by addressing the underlying issue rather than listing every affected object individually. Fixing the common ancestor resolves all downstream symptoms at once.
Production Readiness Rules
Critical: findings block production deployment, regardless of other scores.High: clusters trigger conditional readiness (requires further validation).Medium/Low: issues do not override critical or high-severity blockers.
Conclusion
Migrating from SQL Server to PostgreSQL is a high-impact change, and passing tests is a claim, not proof. The three-tier validation workflow in AWS Transform turns that claim into an auditable artifact: Tier 1 confirms that every object made it across, Tier 2 confirms that each one is semantically equivalent, and Tier 3 empirically verifies that routines produce the same results. An Amazon Strands agent then clusters findings by root cause and issues a severity-driven grade, so a high headline score cannot mask a single critical data-loss issue.
To get started, try validating your first schema migration with AWS Transform. For more information, see the following resources: