AWS HPC Blog
Announcing expanded support for Custom Slurm Settings in AWS Parallel Computing Service
 Today we’re excited to announce expanded support for custom Slurm settings in AWS Parallel Computing Service (PCS). With this launch, PCS now enables you to configure over 65 Slurm parameters. And for the first time, you can also apply custom settings to queue resources, giving you partition-specific control over scheduling behavior.
Today we’re excited to announce expanded support for custom Slurm settings in AWS Parallel Computing Service (PCS). With this launch, PCS now enables you to configure over 65 Slurm parameters. And for the first time, you can also apply custom settings to queue resources, giving you partition-specific control over scheduling behavior.
This release responds directly to customer feedback. Many organizations running HPC workloads on PCS told us they needed more flexibility to enforce access policies, implement fair-share scheduling, or just optimize job lifecycles. Others were blocked from critical use cases because they couldn’t set the parameters they rely on in their on-premises Slurm clusters.
In this post, we’ll show you how new capabilities remove those limitations, making it possible to align your cloud-based environment with the operational and research requirements you already know from traditional HPC.
Why Custom Slurm Settings matter
At its core, Slurm is about policy. Schedulers decide which jobs run, where they run, and how resources are shared among competing users and projects. Fine-tuning Slurm settings can mean the difference between a cluster that feels sluggish and unfair, and one that consistently delivers results while keeping everyone happy.
With this release, PCS exposes many more knobs and dials. At the cluster level, you can now set parameters that tune fair-share and quality-of-service, enable license management, customize the job lifecycle, and manage preemption. At the queue level, you can implement resource limits, access controls, and further configure fair-share and priority behavior. At the compute node group level, you can tag nodes with features, reserve resources, and adjust utilization parameters.
These controls unlock important HPC scenarios. For example, a university research center can track compute usage per department for monthly chargeback, while still enforcing fair-share policies across the entire cluster. An industrial R&D lab can assign higher QoS to safety-critical simulations, ensuring they preempt background batch work. Machine learning teams can dedicate GPU partitions to certified users, preventing general workloads from misusing scarce accelerators.
How it works
You can apply Custom Slurm Settings through the AWS Console, CLI, or SDKs during resource creation or later via update operations.
In the console, you’ll find a new Additional scheduler settings section on the create or edit page for clusters, queues, and compute node groups. Adding a parameter is as simple as choosing Add new setting, selecting the parameter from the drop-down (which includes descriptions and the associated Slurm config file), and entering its value. To remove a parameter, choose Remove and update the resource. Figure 1 shows the current console view for setting these configurations.
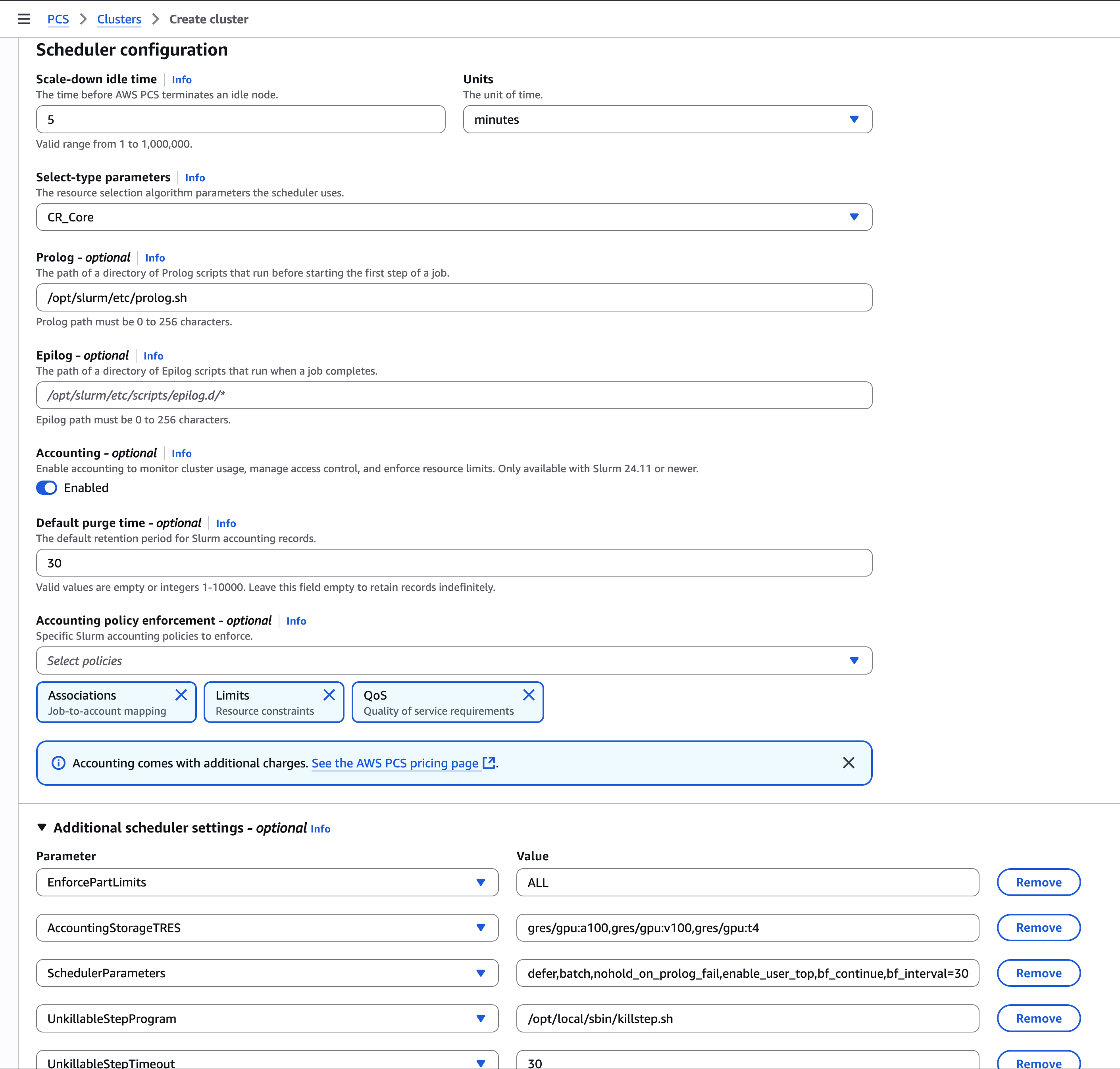
Figure 1 – You can edit Slurm custom settings through the console, CLI, or SDK. Here we show the AWS PCS console with various settings being changed. Whichever method you choose, settings are validated for correctness before being accepted.
For those of you who prefer programmatic control, PCS now supports a SlurmCustomSettings field in create and update calls. This makes it easy to version, automate, and audit configuration changes as part of your DevOps pipeline.
Examples in action
Let’s look at a couple of concrete cases.
Suppose you want every job in a given cluster to run a prolog script that sets up the environment. You can now update the cluster like this:
aws pcs update-cluster --cluster-identifier my-cluster \
--slurm-configuration \
'SlurmCustomSettings=[{parameterName=Prolog,parameterValue="/path/to/prolog.sh"}]'
This ensures that before any job starts, your script executes, handling tasks such as loading environment modules, staging data, or checking license availability.
Now imagine you want a specific queue to be the default for users who don’t specify a partition. That’s straightforward too:
aws pcs update-queue \
--cluster-identifier my-cluster \
--queue-identifier my-queue \
--slurm-configuration 'SlurmCustomSettings=[{parameterName=Default,parameterValue=YES}]'
This helps direct jobs automatically to the right partition, reducing user error and ensuring workloads land on the appropriate resources.
Finally, if you maintain a compute node group with GPUs and NVMe storage, you can tag those features explicitly:
aws pcs update-compute-node-group \
--cluster-identifier my-cluster \
--compute-node-group-identifier my-cng-1 \
--slurm-configuration \
'SlurmCustomSettings=[{parameterName=Features,parameterValue="gpu,nvme"}]'
Users can then request these resources in job submissions with --constraint=gpu&nvme, just as they would on any other Slurm cluster.
Built-in validation
Configuring Slurm is powerful, but anyone who has wrestled with slurm.conf knows how easy it is to introduce mistakes. PCS adds a layer of protection with synchronous validation of custom settings. Each parameter is checked for correct data types, allowed values, and context. For example, time values must match Slurm’s expected format, and parameters that only make sense with accounting enabled are validated against the current cluster state.
If you submit an invalid configuration, PCS responds with a clear ValidationException that lists the problematic fields and provides actionable error messages. This helps administrators avoid downtime and misconfiguration while still retaining the flexibility they need.
While PCS helps prevent errors through validation, it’s still possible to submit an invalid configuration. If an update operation fails, the resource may enter an UPDATE_FAILED state. When this happens, review your configuration settings and ensure all related resources are in an ACTIVE state before submitting a corrected update request.
What you can configure
The list of supported parameters is extensive. Cluster-level options include accounting controls like AccountingStorageEnforce and AccountingStorageTRES, health monitoring (HealthCheckProgram, HealthCheckInterval), job lifecycle hooks (TaskProlog, TaskEpilog), and priority weights for fair-share and QoS scheduling.
Queue-level options give fine-grained partition control. You can set DefaultTime and MaxTime for different workloads, define AllowAccounts and AllowQoS access restrictions, configure PreemptMode and PriorityTier, or enforce differentiated billing with TRESBillingWeights.
At the compute node group level, you can assign Features tags, reserve memory with MemSpecLimit, or pin specialized CPUs with CpuSpecList.
Together, these controls let you re-create the nuanced policies that many HPC organizations depend on, but now with the elasticity and manageability of PCS.
Real-world use cases
Consider a national weather agency running daily forecasts. By assigning high QoS to the forecasting partition and enabling preemption, urgent simulation jobs always displace less critical workloads, guaranteeing timely results.
A pharmaceutical company running molecular dynamics simulations may use queue-level fair-share policies to ensure that no single research team monopolizes the cluster, while still allowing priority projects to move ahead.
An academic HPC center could use this as a source of data to support their own chargeback mechanism so their research group can reconcile their consumption using actual compute time.
These are just a few ways the expanded parameter set can map cloud HPC environments to the realities of institutional policy and workload diversity.
Getting started
To explore the new functionality, log in to the AWS PCS console and open the Additional scheduler settings section when creating or editing clusters, queues, or node groups. For a programmatic approach, add SlurmCustomSettings to your CLI or SDK calls.
Documentation for each parameter is available in the official Slurm manual.
The expanded support for custom Slurm settings in PCS represents a major step forward for cloud-based HPC. Customers can now bring the same sophistication and nuance from their on-premises clusters into AWS, while gaining the elasticity and operational advantages of a managed service. By exposing dozens of additional parameters and extending them to queues, PCS gives HPC administrators the fine-grained control they need to enforce policies, allocate resources intelligently, and deliver results faster.
If you’re completely new to AWS Parallel Computing Service, you can get started really quickly – and with virtually no learning curve – by using the console quick launch, or using one of the one-click launch recipes for PCS from the HPC Recipes Library on GitHub.