AWS HPC Blog
Financial services industry HPC migrations using AWS ParallelCluster with Slurm
If you’re reading this post, you’ll know that HPC is a way of solving hard problems by slicing the problem space up amongst a lot of computers. You might have also heard the term ‘grid computing’ in the context of financial services. This refers to centralized systems which are typically used to provide ‘utility computing’ to support HPC workloads.
In financial services these types of jobs use complex algorithms to calculate as many risk or trading scenarios in parallel as possible, bound only by the amount of compute available. Financial services firms are always keen to reduce their operational costs and look to the cloud as a way to provide the elasticity and cost benefits to do this, but also: the ability to respond rapidly to changing economic conditions and market volatility.
Customers from all the major Financial Services Industry (FSI) verticals (including banking, capital markets, and insurance) are moving their on-premises grid workloads partially, or entirely, to the cloud. These workloads typically include high volumes of short-running tasks.
In this post, we’ll walk through how these firms can migrate or burst their grid workloads onto AWS using AWS ParallelCluster and the Slurm scheduler – and we’ll give you an introduction to those two packages, if you’ve not met them before.
Loosely-coupled Grid scenarios
Grid workloads often require hundreds of thousands, or millions, of parallel processes to complete a calculation or simulation. Generally, these jobs run on a single node, consuming one process or multiple processes with shared memory parallelization (SMP) for parallelization within the node. The parallel processes, or the iterations in the simulation, are post-processed to create one solution or discovery from the simulation.
During the simulation, the operations can take place in any order, and the loss of any one node or job in a loosely coupled workload usually doesn’t delay the entire calculation. The lost work can be picked up later or omitted altogether. The nodes involved in the calculation can vary in specification and power. This gives us some hints about the types of compute that we need to run these loosely-connected simulations.
Architectural considerations
Networking
Grid processes run in parallel and don’t communicate with each other (at all) to exchange information. This means the performance of jobs isn’t impacted by latency between the nodes. This is great because it means that instead of optimizing for latency, we can instead optimize for instance availability: we can spread the job out over several Availability Zones (AZs), each of which have their own capacity pools. This is especially useful when using the Amazon Elastic Compute Cloud (Amazon EC2) Spot purchasing model because the availability of Spot instances in any given AZ can be limited.
By providing AWS ParallelCluster with options about where to place the compute, we can achieve an architecture that can scale up to tens or hundreds of thousands of cores.
Storage
Loosely coupled jobs also have a great characteristic when working with shared storage. Typically, they need to read data in, compute on it, and then write it out all without interfering with any other job. This is the perfect use case for object storage. In this post, we’ll focus on Amazon Simple Storage Service (Amazon S3) as the storage layer because it provides internet-scale storage, it’s low cost, and it scales up to hundreds of thousands of tasks working simultaneously.
Compute
Choosing instance types means looking at the job’s requirement for memory:vCPU ratio, availability, and architecture support for the workload. (ie x86 or aarch64). In this post, we’ll stick with x86, to provide the greatest instance availability and compatibility.
ParallelCluster can request instances based on what’s available and will quickly “fail-over” if the instances can’t be launched. For the purposes of testing we chose instances from both x86 manufacturers’ families because they share the same instruction set and by choosing both we have a larger pool to draw from.
In this post, we’ll use vCPUs instead of cores because most x86 instances onAWS have hyperthreading enabled. Hyperthreading allows two virtual cores to share the same arithmetic/logic unit (ALU). This increases overall throughput by doubling the core count but deceases the individual core’s solve-time. This is sometimes a controversial topic in HPC, but for grid workloads in FSI, we’ve seen that hyperthreading is a net benefit, so we’re leaving it enabled.
Scheduling
Running a few tasks on a single instance is easy to manage by hand, but once you scale up the number of tasks, you’ll need a scheduler to manage their lifecycle. Slurm is an open-source job scheduler that’s optimized for scheduling both tightly-coupled and loosely-coupled tasks across multiple instances. It handles queuing, execution, retries, and accounting. ParallelCluster sets up Slurm using the Slurm cloud bursting plugin and manages the scaling of Amazon EC2 instances.
We recommend enabling Slurm’s memory based scheduling feature. This provides an easy way to request specific memory amounts and compute directly in the job submission, i.e. 1 vCPU and 4 GB of memory could be set in the Slurm sbatch file. It also helps Slurm maximize the CPU utilization of all the cores across the fleet.
AWS ParallelCluster
AWS ParallelCluster is an open-source cluster management tool that makes it straightforward for you to deploy, manage, and scale Slurm-based clusters on AWS. ParallelCluster allows you to leverage the elasticity of AWS by providing an easy way to expand and contract compute queues that you define. You can use multiple instance types, in multiple Availability Zones, and create job submission queues with a lot of creative freedom.
You can also quickly spin up clusters for experimenting and prototyping. Since ParallelCluster uses a simple YAML file to define all the resources you need, the process of standing up additional clusters – for production, dev, or testing – is an automated (and secure) process.
Let’s look at a reference architecture and a tutorial that you can use to deploy this in your own AWS account.
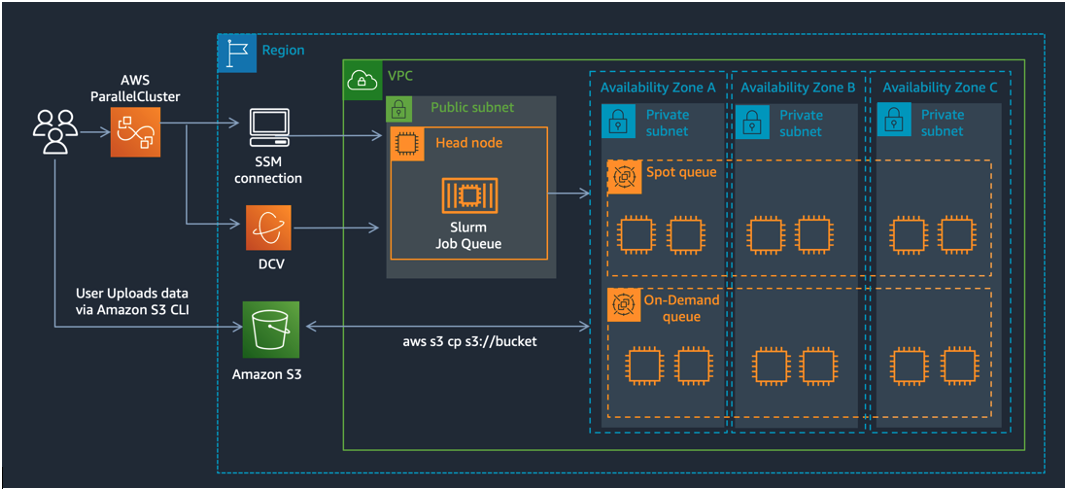
Figure 1 –The reference architecture for FSI grid-style computing on AWS using AWS ParallelCluster. The queues span over all the Availability Zones in the region and read and write data from an Amazon S3 bucket in that region.
Implementation details
In the following steps, we’ll show you how to setup a cluster with a headnode and two compute queues. The queues span over all the Availability Zones in the region and read and write data from an Amazon S3 bucket in that region. The Slurm scheduler process (slurmctld) runs on the HeadNode and users can login there to submit jobs via AWS Systems Manager (SSM), using SSH, or with a remote desktop connection using DCV as shown in the reference architecture in Figure 1.
You can follow along with these steps in the FSI Tutorial hands-on lab.
First, install AWS ParallelCluster CLI or UI. We’ll assume you’re using the CLI for now. In ParallelCluster, you initiate the creation of a cluster through the CLI by specifying the location of your configuration file, like this:
pcluster create-cluster -c cluster.yaml -n cluster-nameYour config file might look something like the this:
HeadNode:
InstanceType: c5a.xlarge
Networking:
SubnetId: subnet-846f1aff
LocalStorage:
RootVolume:
VolumeType: gp3
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
- Policy: arn:aws:iam::aws:policy/AmazonS3FullAccess
Dcv:
Enabled: true
CustomActions:
OnNodeConfigured:
Sequence:
- Script: >-
https://raw.githubusercontent.com/aws-samples/aws-parallelcluster-post-install-scripts/main/docker/postinstall.sh
- Script: >-
https://raw.githubusercontent.com/aws-samples/aws-parallelcluster-post-install-scripts/main/pyxis/postinstall.sh
Args:
- /fsx
Imds:
Secured: true
Scheduling:
Scheduler: slurm
SlurmQueues:
- Name: c6i
AllocationStrategy: capacity-optimized
ComputeResources:
- Name: spot
Instances:
- InstanceType: c6i.32xlarge
- InstanceType: c6a.32xlarge
- InstanceType: m6i.32xlarge
- InstanceType: m6a.32xlarge
- InstanceType: r6i.32xlarge
- InstanceType: r6a.32xlarge
MinCount: 0
MaxCount: 100
CustomActions:
OnNodeConfigured:
Sequence:
- Script: >-
https://raw.githubusercontent.com/aws-samples/aws-parallelcluster-post-install-scripts/main/pyxis/postinstall.sh
Args:
- /fsx
ComputeSettings:
LocalStorage:
RootVolume:
VolumeType: gp3
Networking:
SubnetIds:
- subnet-8b15a7c6
- subnet-04f44e9dc1c8ee425
- subnet-91ab80f8
PlacementGroup:
Enabled: false
CapacityType: SPOT
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
- Policy: arn:aws:iam::aws:policy/AmazonS3FullAccess
Region: us-east-2
Imds:
ImdsSupport: v2.0
Image:
Os: alinux2
SharedStorage:
- Name: Ebs0
StorageType: Ebs
MountDir: /shared
EbsSettings:
VolumeType: gp3
DeletionPolicy: Retain
Size: '100'
Tags:
- Key: parallelcluster-ui
Value: 'true'
This config has a few key sections:
HeadNode – this is the Amazon EC2 instance that runs the Slurm scheduler processes (slurmctld, for example). Because this instance is responsible for scaling up the cluster, scheduling jobs, and serving the config files, we recommend going with an instance like the c6i.2xlarge that has sufficient resources (8 vCPUs and 16 GB memory) to run Slurm comfortably.
SlurmQueues – these will depend on your resource requirements. For example, if you have jobs that requires 1 vCPUs and 2 GB memory, set up a queue with c6i instances. These instances all meet the memory to core ratio and specifying multiples different sizes of them will ensure you’re most likely to get your desired capacity. If you require more memory, the m6i and r6i instances offer 8 GB per vCPU and 16 GB per vCPU, respectively. We recommend you offer your users a choice by putting each instance family in their own SlurmQueue. In addition to diversifying the instance types by providing multiple from each family, we also recommend you provide multiple Availability Zones, because this expands the number of pools you’re drawing from and is especially important for using Amazon EC2 Spot.
Storage – for grid workloads there’s rarely a need for a parallel filesystem – more important is a filesystem that can serve traffic in multiple Availability Zones and scale up to the thousands of jobs that can execute concurrently. We recommend using Amazon S3 or if there’s a need for a POSIX compliant filesystem, then Amazon FSx for OpenZFS. The creation of the filesystem is out of scope for this blog, but you can learn more by reading about Filesystem Support in AWS ParallelCluster.
When ParallelCluster builds your cluster, it’ll attach any existing filesystems you specified in the config file. Those filesystems are typically used for applications, libraries, and users’ data. It’s important to have a separation between the filesystem and cluster configuration because it allows for easy upgrades later when ParallelCluster release a new version which you want to take advantage of. In the config file we showed, it calls for ParallelCluster itself to create an EBS-based shared file system, mounted as /shared. This will be NFS-exported to the compute nodes in the cluster when they’re created.
Once your cluster is up and running, you have several ways to interact with it:
- You can login to the head node: you can use normal SSH, or connect through SSM using the attached
SSMInstanceCoreSSM allows access to instances that are not routable through SSH, like those in a private subnet. - You can submit jobs using the default Slurm commands like
sbatch,srun, and then monitor withsqueueandsinfo. See Slurm sbatch documentation for more details on options for submitting jobs, and the syntax for the run scripts. - When Slurm detects new jobs in the queue, it uses the Cloud Scheduling plugin, which calls a
ResumeProgramscript that ParallelCluster manages. This script, in turn, calls the Amazon EC2 Fleet API to allocate instances to the queue. The jobs run soon after the instances bootstrap (typically 2-3 minutes). - Once all jobs are complete, the instances are left running for a short ScaleDownIdleTime, in case more jobs arrive. This defaults to 10 minutes, but you can configure it yourself by specifying a
ScaleDownIdleTimeparameter in the ParallelCluster config file. After this time expires, ParallelCluster will terminate the instances, and wait again for new jobs to arrive in the queues. - If the cluster is deleted, all instances including the head node will be terminated.
There’s an AWS Workshop available online to show you how to calculate the price of a financial auto-callable option based on this ParallelCluster architecture. The workshop provides step-by-step guidance to create and configure ParallelCluster and to deploy the containerized workload.
Best Practices when using ParallelCluster with Slurm
Smaller and heterogeneous job duration
If your job durations are small, for example in seconds and somewhat heterogeneous, we suggest following the recommendations from SchedMD (the makers of Slurm) to tune the cluster for the best job throughput – measured in tasks per second. It’s possible for Slurm to scale to 500 jobs/sec – under the right conditions and with the right architecture.
Large Scale Clusters
If your cluster exceeds 1024 instances, we recommend that following the Slurm Large Cluster Administration guide.
You’ll also want to consider your HeadNode architecture. Using a c6i.2xlarge won’t be sufficient for the network bandwidth demanded by slurmctld when it’s communicating with all the child nodes. We recommend using a network optimized instance with at least 50 Gbps of dedicated bandwidth, like the c6in.8xlarge. Remember, the HeadNode instance communicates with the compute instances and serves the Slurm config file, and application binaries via NFS.
You’ll also need to review your AWS account limits, (which, we remind you, are set on a per-region basis):
- Amazon EC2 Limits – make sure you increase the Amazon EC2 limits for the compute nodes you plan to use. You can review these, and request limit increases via the AWS Service Quotas console.
- EBS limits – each compute node mounts a 35 GB root volume (or larger) of gp3 EBS storage. If you plan to launch more instances than your quota (which defaults to 50 TiB), you should increase this limit, too.
- Route53 limit – each compute node is added to a Route53 Private Hosted Zone. This has a default limit of 10,000 records. If you plan to exceed this limit, make sure to request a limit increase.
Acadian did this – so you can you
Acadian chose to use Slurm in AWS ParallelCluster to execute thousands of these heterogeneous jobs. This cloud-native grid solution enables them to benefit from faster and seamless compute capacity provisioning and on-demand auto scaling features, resulting in optimal results.
According to Jian Pan, Head of Quantitative Systems at Acadian, “we are able to reap immediate benefit such as maintaining consistent 4hr model runtime in AWS, comparing to 20~40hr runtime on-premise when resource is under stress”.
Conclusion
Slurm can handle a cluster that grows and shrinks – driven by demand. It’s able to this dynamically by scaling compute resources from Amazon EC2. Compute fleets can be spun up to complete the workload in the queue. When the jobs are complete, ParallelCluster scales those same fleets back down to the minimum level you set (usually zero).
If you want to try this yourself, you can follow the steps in the FSI Tutorial hands-on lab, and when you’ve done that, you can try a real application to calculate the price of a financial auto-callable option. Let us know how to get on – you can reach out to us at ask-hpc@amazon.com.