AWS HPC Blog
How Adobe Search, Discovery, and Content (SDC) Empowers Large Scale Image (AI/ML) Inferencing Utilizing AWS Batch
This post was contributed by Harish Suvarna, Alec Ngo, and Suryanarayana Murthy Boddu at Adobe, and Mark Azadpour, Yoginder Sethi at AWS.
Adobe empowers everyone everywhere to imagine, create, and bring any digital experience to life. With over 29 billion assets generated using Adobe Firefly and a vast Adobe Stock ecosystem, the ability to search and discover relevant images or videos at scale is critical.
Achieving this at Adobe’s scale comes with complex technical requirements: running AI models that process hundreds of millions of assets, managing thousands of parallel inference jobs, and ensuring GPUs are fully utilized without breaking cost efficiency. Meeting these challenges requires an infrastructure that can handle massive data throughput, scale elastically, and minimize operational overhead.
In this post, we will share how the Adobe SDC team tackled these challenges and why AWS Batch—combined with GPU accelerated Amazon EC2 Instances—became a strong fit for our large-scale distributed inference workloads. More importantly, we’ll highlight the lessons we learned and the practices that helped us make inference very efficient.
The opportunity
Image assets from multiple sources power content retrieval, discovery and recommendations across various Adobe products—such as Adobe Acrobat, Adobe Express, Adobe Firefly and more—and are surfaced through semantic search. Embedding models are constantly evolving, which makes periodic re-computation of the embeddings for such huge data set(s) with hundreds of millions of assets increasingly critical for state-of-the-art search ranking and relevancy. As search features and experiences continue to evolve, with several experiments and evaluations across the development cycle, recomputing and updating embeddings becomes repetitive.
Computing image embeddings is similar to workflows for text, video, and audio and involves loading images into memory, running inference with Adobe’s proprietary machine learning models, and storing the results in internal systems that power semantic search, RAG, and other capabilities. Given the volume of the data, this process can only be implemented as a massively parallel process rather than sequential processing. AWS Batch, a fully managed service that simplifies running batch computing workloads, helped to achieve our goals.
Some of the key challenges included:
- Model and data diversity: Different models and dataset sizes require different GPU architectures to maximize performance and speed. So, our pipelines need to be flexible to use different types of EC2 instances
- High operational overhead: Building and maintaining our own container orchestration system (such as EKS) to execute these ad hoc inference jobs would involve significant engineering effort, including managing servers, auto-scaling groups, and load balancers. Instead, a simple ephemeral solution is more appropriate.
- Failure detection and recovery: Even with complete automation of cluster setup, failure detection and retry mechanisms require additional business logic.
- Data sharding complexity: Efficiently partitioning data and assigning work to each node in the data lake becomes increasingly challenging at scale.
- Long processing times: Sequential processing can take weeks to complete for large workloads, severely limiting iteration speed.
The solution
When designing solutions, we aimed to achieve:
- Immediate access to resources: Provide seamless access to GPUs across multiple instance types (e.g., g6e, g5), selected based on model requirements.
- Efficient resource utilization: Ensure resources allocated are efficiently and effectively used.
- Consistent job submission: Offer a standardized interface for job execution, regardless of parallelization level or EC2 instance type.
- Cost optimization: Leverage a “pay-as-you-go” model and dynamically scale resources up or down based on demand. Minimize per-job costs to deliver the best possible value.
- User experience: Democratize massive batch processing through a fully self-serve experience, empowering users to run jobs without deep infrastructure knowledge.
Data Preparation and Distributed Inferencing
Efficient data loading is critical to maximize GPU utilization during large-scale inference. A common bottleneck is that data is either not loaded quickly enough into GPUs, or the pipeline becomes unbalanced, leading to underutilized hardware.
For a different use case, Adobe Research customized the PyTorch Dataloader to stream samples directly from Amazon S3 into AWS Batch containers at a node level. Within each container, CPUs handle preprocessing—such as decoding and converting samples into tensors—before delivering well-formed batches to GPUs for inference. If a node has 8 GPUs, 8 dataloaders are created, each paired with its own model engine. While they all point to the same dataset, each data loader uses its assigned rank and the number of dataloaders the host is spinning up, also known as world rank, to know exactly which shard of the dataset to process, avoiding overlap and ensuring balanced throughput.
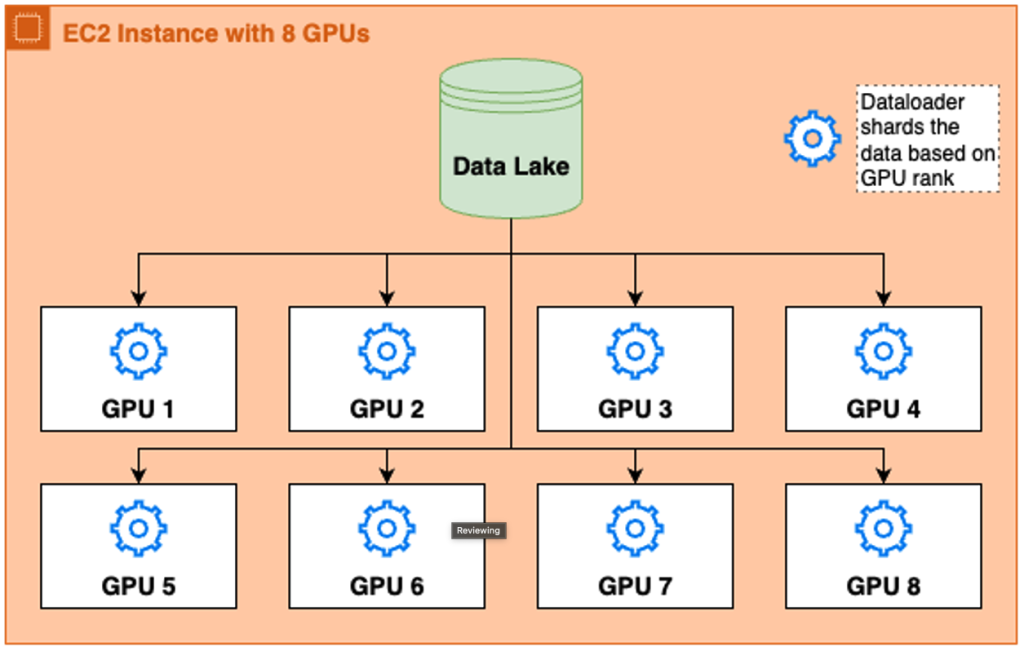
Figure 1: Dataloader System for Inferencing.
When extending the process to multiple distributed nodes, it is important for each node to be given a distinct dataset partition to process. One approach is to download the entire dataset per node and rely on dataloader rank/world size to handle partitioning. However, given the scale of the data, this would require significant extra disk usage. This is where we leveraged AWS Batch: We separated the dataset preparation and converted it into its own AWS Batch job. This preprocessing job runs multiple workers to shard the S3 bucket and compress object addresses into compact binary files.
During inference, each node only needs to download its assigned binary shard—based on its AWS_BATCH_JOB_NODE_INDEX—and to feed that to its data loaders. This reduces disk overhead, eliminates redundant data transfers, and ensures that every node processes a unique subset of the dataset. Together, these techniques keep GPUs well-fed with batches and maintain high efficiency across thousands of concurrent jobs. This stage was also achieved by AWS Batch service, and we leveraged Batch’s EC2 GPU instance type support capability.
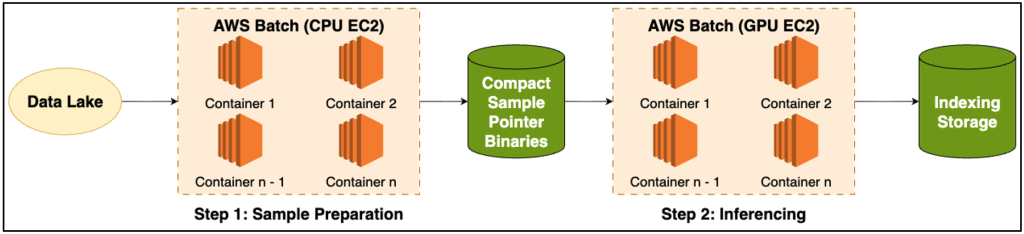
Figure 2: Inference whole system Diagram.
How AWS Batch Supports our Solution Goals and Solved Scaling Challenges
AWS Batch provides a managed architecture that removes much of the operational burden of scaling large-scale inference workloads. It enables us to run tens of thousands of concurrent jobs without maintaining complex infrastructure, while benefiting from consistent logging, monitoring, access controls, and file system integration.
The following are some of the elements of the AWS Batch parallel processing.
Compute environment: This is where we define the EC2 instance type, launch template, and the minimum/maximum number of nodes. AWS Batch provisions an Auto Scaling Group (ASG) for GPU nodes and deploys containers to these EC2 nodes based on their availability and health. This abstraction means we rarely touch low-level infrastructure. Scaling is automatic—if job volume increases or decreases, the ASG adjusts node count within the defined limits, ensuring we never pay for idle capacity.
Job queue: This determines the order in which jobs are executed against the associated Compute Environment. For example, if queue A is mapped to compute environment (CE) A, jobs in that queue will be dispatched based on available GPU capacity and queue priority. The job queue also enforces high-level execution rules, such as terminating jobs that exceed timeouts, fail due to insufficient GPU availability, or encounter other resource constraints.
Job definition: The job’s execution blueprint, like a docker run command. This specifies the Docker image, required GPU/CPU resources, disk mounts, and any environment variables or runtime configurations needed for the container to run on the EC2 host. It also defines the number of job attempts, or how many times to try to restart the container in case of failure.
Job: The process of submitting a job definition into a job queue. This triggers the provisioning of the required infrastructure. Each node in a multi-node job is automatically assigned two key environment variables—AWS_BATCH_JOB_NODE_INDEX and AWS_BATCH_JOB_NUM_NODES—used to shard data so that each node processes its specific portion of the workload.
When a job is submitted to AWS Batch, every job node receives the same environment variables, including an S3 URI where all data is stored. The EC2 instance from the ASG pulls the Docker image containing our inference model and logic. Once the container is up and healthy, it uses the node’s AWS_BATCH_JOB_NODE_INDEX and AWS_BATCH_JOB_NUM_NODES values to determine exactly which shard of data it should download and process. After the inference step completes, results are immediately stored in the search index. The container then exits with a success code and terminates, freeing the EC2 host. If additional jobs are waiting in the queue, the host picks up the next job; otherwise, the ASG scales down to release unused resources. By default, each job index also creates an AWS CloudWatch log stream, allowing us to observe container activity in real time and debug issues when needed.
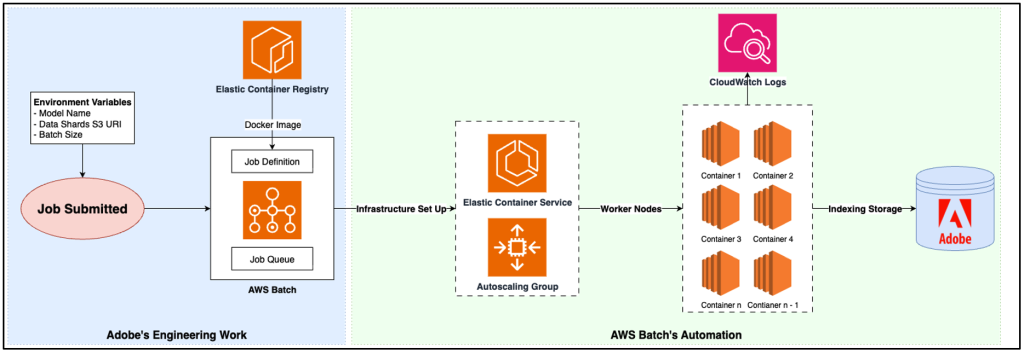
Figure 3 – AWS Batch data flow diagram used with Adobe solution.
Results
By redesigning a sequential workflow into a multi-step sharding and distributed parallel compute pipeline, and by implementing an efficient onload/offload mechanism for data to GPUs, we achieved 10x faster execution. From our monitoring dashboards, we often see our GPUs now consistently run at 100% utilization, delivering extremely high throughput and maximizing hardware efficiency.
AWS Batch allowed us to support this at scale by provisioning ephemeral compute with no fixed infrastructure or standing costs. AWS Batch handles the operational heavy lifting, and its flexibility to support both CPU and GPU workloads has saved us substantial engineering effort while reducing cloud spend.
In one of our largest runs—computing image embeddings for Adobe Stock—we reduced compute time from 30 days to under 20 hours, while realizing a 95%+ reduction in cost, covering not only compute but also engineering investment. This capability empowers our engineering team to accelerate production workloads and run large-scale experiments quickly and cost-effectively.
Lessons Learned
Data Organization
- Efficient Data Sharding:
To process a large number of assets efficiently, pre-organizing data into smaller, manageable shards is critical. Without this, even simple operations like listing assets in S3 can take hours or may hang entirely. By organizing the data into smaller shards, we enabled parallel nodes to consume the data more effectively. - Handling S3 Rate Limits:
After organizing the data, parallel downloading by multiple nodes initially resulted in rate limit errors (HTTP 429). To address this:
- We collaborated with the AWS S3 team to increase the throughput of the S3 bucket, which significantly reduced the rate limit errors.
- Despite these measures, occasional 429 errors persisted. To mitigate this:
- We implemented immediate retries within the same processing loop.
- We added a final retry mechanism at the end of the processing. By this stage, each node was making fewer calls to S3, reducing the likelihood of 429 errors.
- Batch Processing on GPUs:
When working with GPUs, processing data in optimal batches is mandatory. This applies to preprocessing, processing, and post-processing. This optimal batch size varies across applications. We experimented with various batch sizes before the big run and found an optimal size. Batch processing saved significant GPU time and reduced the overall processing time. - Data Localization:
We ensured that the data resided in the same AWS region as the batch computing clusters. This approach:
- Avoided cross-region data transfer charges, which can be substantial.
- Reduced latency and improved the overall operation time.
Compute
- GPU Availability Challenges:
Due to the rising demand for ML computing, obtaining a high number of GPUs on demand is challenging. To address this:
- We created compute definitions for various GPU instance families such as G5s, G6es, and G6s.
- We leveraged hybrid compute definitions in AWS Batch to maximize flexibility.
- Throughput Optimization:
Understanding the throughput of a single pod was essential. Based on this:
- We defined the minimum and maximum number of vCPUs/GPUs required.
- This ensured that even if the full compute capacity was unavailable, AWS Batch could start processing with the available resources and scale up as more compute became available.
Key Takeaways:
- Data Organization: Proper sharding and localization of data are critical for efficient processing and cost optimization.
- Error Handling: Implementing robust retry mechanisms helps mitigate rate limit errors.
- Batch Processing: Processing data in batches is essential for GPU efficiency.
- Compute Flexibility: Adapting to available compute resources ensures uninterrupted processing and scalability.
Conclusion
By integrating AWS Batch with Amazon ECS and GPU-based EC2 instances, Adobe has significantly enhanced its asset processing (images, video) infrastructure while extending support to additional content types, including text and video. The result is unmatched scalability, cost-efficiency, and operational simplicity—enabling faster execution of massive workloads and accelerating innovation. For organizations aiming to scale high-performance computing and speed up time-to-market, AWS Batch offers a compelling path to optimal total cost of ownership (TCO).