AWS for Industries
AI-powered patient profiles using AWS HealthLake and Amazon Bedrock
Healthcare providers face a significant challenge today: the overwhelming volume of patient data spread across electronic health records. Before each patient visit, clinicians must review extensive medical histories, lab results, medications, and previous diagnoses—often under severe time constraints. This data overload can lead to missed insights, reduced face-to-face time with patients, and clinician burnout.
We will illustrate an innovative solution developed by Amazon Web Services (AWS) in response to this industry-wide challenge. We’ll explore how AWS HealthLake, Amazon Bedrock, and other AWS services can be combined to create a generative AI-powered patient profile summarization solution. The solution helps healthcare providers quickly access and understand comprehensive patient information before, during, or after a visit.
The challenge: Information overload in healthcare
Recent research reveals that healthcare providers spend a significant portion of their workday interacting with electronic health record (EHR) systems. A time and motion study across four specialties found that physicians dedicate 49.2 percent of their time to EHR and desk work, while only 27 percent is spent on direct clinical face time with patients. This includes time spent searching for and synthesizing relevant patient information across multiple screens and documents. Administrative burden can contribute to clinician burnout, reduction of quality time spent with patients, and overlooked patient information.
Key challenges include:
- Data fragmentation: Patient information scattered across multiple systems and formats
- Time constraints: Limited time to review patient records before appointments
- Information overload: Difficulty identifying the most relevant information for a specific visit
- Context switching: Constant toggling between different sections of the EHR
- Cognitive load: Mental effort required to synthesize and remember key patient details
AWS HealthLake: Unifying healthcare data management and analysis
AWS HealthLake is a HIPAA eligible service that enables healthcare providers to store, analyze, and share health data in the cloud using the Fast Healthcare Interoperability Resources (FHIR) R4 specification. It addresses the key challenges of healthcare data management:
- Enterprise health data: Manage and share health care data in standardized FHIR format directly from the AWS Cloud, while preserving high performance and availability.
- Healthcare interoperability: Support customer conformance with the 21st Century Cures Act for patient access through a fully managed FHIR data store.
- Natural language processing (NLP): Utilize integrated NLP foundation models to extract medical information from unstructured health data.
- Multimodal integration: Combine HealthLake data with AWS HealthImaging data and AWS HealthOmics data to facilitate precision medicine.
By using AWS HealthLake as the foundation of our solution, we can leverage its powerful capabilities to enable storage, retrieval, and analysis of patient data in a standardized format. This makes it the ideal data layer for our generative AI-powered, summarization workflow.
Solution overview: Patient profile summarization
Our solution leverages AWS HealthLake as the core data layer of a consolidated clinical and financial record system along with other AWS services to create a serverless application. The solution retrieves comprehensive patient data and generates AI-powered summaries tailored to the healthcare professional’s role and the context of the patient visit.
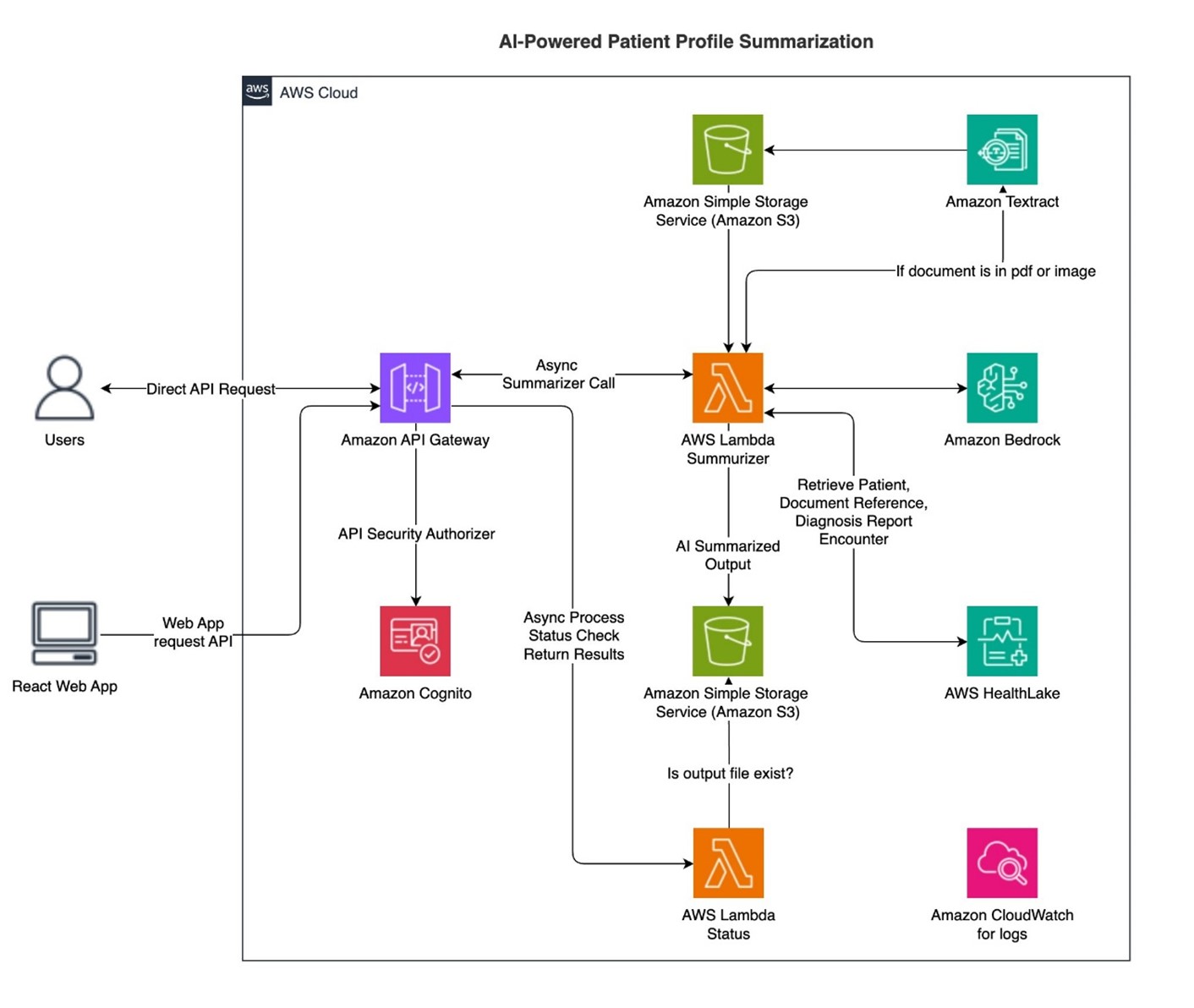 Figure 1 – Architecture of generative AI-powered patient profile summarization
Figure 1 – Architecture of generative AI-powered patient profile summarization
The solution follows a serverless architecture pattern, combining several AWS services:
- AWS HealthLake: AWS HealthLake serves as the solution’s foundation by providing a HIPAA-eligible healthcare data repository using FHIR R4 format. It offers capabilities such as: standardized storage, comprehensive records management, advanced search operations, and natural language processing. However, customers should always configure services according to HIPAA requirements.
- Amazon Bedrock: Provides generative AI capabilities using Anthropic Claude 3.5 Sonnet model
- AWS Lambda: Processes API requests and handles asynchronous operations
- Amazon API Gateway: Exposes Lambda functions as RESTful APIs
- Amazon Simple Storage Service (Amazon S3): Stores processing results and binary medical documents
- Amazon Textract: Extracts text from medical documents stored in Amazon S3
Key features
The solution incorporates several essential features designed to enhance healthcare professionals’ efficiency, while ensuring comprehensive patient care delivery. These key capabilities work together to deliver contextual, relevant, and timely information at every point of care:
1. Role-based summaries: Tailors information based on the healthcare professional’s specialization (such as cardiology, or dermatology)
2. Visit context awareness: Adapts summaries based on whether the visit is before, during, or after the patient encounter
3. Comprehensive data integration: Consolidates information from various FHIR resources (Patient, Encounter, Condition, Observation, and more)
4. Document processing: Extracts text from medical documents using Amazon Textract
5. Asynchronous processing: Handles long-running operations without timeouts
6. Structured output: Provides organized summaries with sections for patient overview, changes since last visit, medications, and follow-up recommendations
How the solution works
The solution uses the following workflow:
1. Request submission: A healthcare professional submits a request containing the patient ID, the doctor’s specialization, and the visit context
2. Data retrieval: The system queries AWS HealthLake to retrieve comprehensive patient data using native FHIR APIs
3. Document processing: Any binary documents (PDFs, images) are processed using Amazon Textract to extract text
4. Data structuring: The system organizes the patient data into a structured format
5. Generative AI summary generation: Amazon Bedrock with Claude 3.5 Sonnet generates a comprehensive summary tailored to the healthcare professional’s needs
6. Result delivery: The summary is delivered to the user interface for immediate review
Sample Output
Healthcare providers often need to review dozens of documents, lab results, and visit notes spanning multiple years of patient care. This can take considerable time and effort to synthesize. The solution dramatically streamlines this process by analyzing and consolidating information from:
- Multiple years of electronic health records
- Various specialist visits notes
- Laboratory results across numerous visits
- Diagnostic imaging reports
- Previous treatment plans and their outcomes
- Medication history and adjustments
- Patient-reported symptoms and concerns
- Social determinants of health data
The system distills this extensive dataset into a clear, actionable summary. A structured JSON file is output:
Implementation considerations
The quality of FHIR data directly impacts the effectiveness of the patient summaries created by the solution. To facilitate optimal results, consider the following data quality aspects:
- FHIR compliance: Confirm all data adheres to FHIR R4 standards for consistent processing.
- Data completeness: Verify that patient records include essential information across all relevant resource types. HealthLake validates all FHIR data by default.
- Temporal consistency: Validate dates and timestamps are accurate and consistent across resources.
- Document quality: Confirm scanned documents are legible for effective Amazon Textract processing.
- Reference integrity: Maintain proper references between related FHIR resources.
By addressing data quality proactively, healthcare organizations can significantly improve the accuracy and usefulness of the patient summaries. This can lead to more informed clinical decision-making and better patient experiences.
Technical deep dive
Our solution integrates AWS HealthLake using a flexible client that supports both AWS Signature Version 4 (AWS SigV4) and SMART on FHIR (requesting access tokens from OAuth 2.0 compliant authorization servers). These authentication methods allow for secure and efficient data retrieval.
The following code snippet defines a Python class called HealthLakeClient that serves as an interface for interacting with AWS HealthLake using FHIR operations:
Patient/$everything: Retrieves all resources related to a patient in a single request, providing a complete view of the patient’s health record. Following is the Python code snippet showing the function to receive the patient summary for a given AWS HealthLake patient ID:
- Resource-specific queries: The following Python code snippet shows a function to retrieve only specified FHIR R4 supported resource types for HealthLake (such as Observation, Condition, and so on):
- Document reference retrieval: Following is a Python code snippet to access clinical documents stored in the EHR:
By leveraging these AWS HealthLake capabilities, our solution can efficiently retrieve and process comprehensive patient data, providing the foundation for generative AI-powered summarization.
Prompt engineering for healthcare summaries
The solution uses carefully crafted prompts for Amazon Bedrock to generate clinically relevant summaries. The prompts include:
1. Role-based context: Adapts the summary based on the healthcare provider’s specialization
2. Visit-type awareness: Tailors information based on whether the visit is before, during, or after the encounter
3. Structured output guidance: Facilitates consistent formatting with specific sections
4. Clinical focus: Emphasizes medical information and follows healthcare terminology conventions
Following is a streamlined version of our prompt structure (remember to input the specifics that best match your use case for role, visit type and reason for visit):
You are a {role} reviewing a patient's medical information {visit_type} their visit.
{reason_for_visit}
Using the provided data, generate a comprehensive patient summary with these sections:
1. Patient Summary: Begin with patient demographics and medical assessment
2. Since Last Visit: Detail significant changes in health status
3. Medications: Current medications with recent changes
4. Patient Reports: Symptoms and subjective experience
5. Follow-Up: Recommended care plan and next steps
Use these data sources:
- Patient Demographics
- Allergies
- Current Medications
- Medical History
- Diagnoses & Problem List
- Recent Procedures
- Lab Results
- Imaging Results
- Care Plan
Asynchronous processing pattern
To handle potentially long-running operations without timeouts, the solution implements an asynchronous processing pattern:
1. The initial request returns immediately with a request ID and Amazon S3 location for results
2. Processing continues in the background using Lambda functions
3. Results are stored in Amazon S3 when complete
4. The client polls a status endpoint to check for completion
5. Once complete, the results are retrieved and displayed
Using an asynchronous processing pattern facilitates a responsive user experience, even for complex patient records that require significant processing time, while avoiding timeouts imposed by an Amazon API Gateway. The following is a JavaScript code snippet is used in a web frontend to submit a summarization request for a patient and periodically check the output location for the summarization:
Document processing with Amazon Textract
Medical records often include scanned documents, PDFs, and images that contain valuable information. Our solution uses Amazon Textract to extract text from these documents and include it in the patient summary.
The process includes:
1. Identifying binary attachments in DocumentReference and DiagnosticReportresources
2. Processing attachments with Amazon Textract
3. Caching the extracted text alongside the original documents
4. Including the extracted text in the data provided to the AI model
This approach verifies that information from all sources is considered when generating the patient summary.
Benefits and business value
Healthcare organizations implementing this solution can expect several key benefits:
1. Time savings: Reduces the time clinicians spend reviewing patient records from 1-2 hours in total daily to approximately 30 second for each patient
2. Improved clinical workflows: Enables more informed clinical decisions with comprehensive patient context, potentially reducing information gaps
3. Enhanced productivity: Helps healthcare providers to see more patients without sacrificing quality
4. Reduced burnout: Decreases administrative burden and cognitive load on clinicians
5. Better patient experience: Increases face-to-face time and improves the quality of patient interactions
Cost optimization
The solutions serverless architecture provides cost-effective operation with pay-as-you-go pricing.
Cost optimization strategies include:
1. Caching: Cache Amazon Textract results and summaries for frequently accessed patients
2. Prompt optimization: Reduce token usage with efficient prompt engineering
3. Model selection: Use Anthropic Claude 3.5 Haiku for less complex summarization tasks
4. Batch processing: Implement batch processing for document extraction
Scaling considerations
The solution scales automatically to handle varying workloads:
- Lambda concurrency: Handles multiple simultaneous requests
- Amazon S3 performance: Scales to store and retrieve thousands of patient summaries
- API Gateway throttling: Configurable to prevent overloading backend services
- Regional deployment: Can be deployed across multiple AWS Regions for global availability
Extending the architecture: Additional healthcare use cases
While our solution focused on patient visit preparation, the architecture we’ve developed may have broad applicability across various healthcare scenarios.
Following are several additional use cases that could leverage this combination of AWS HealthLake, Amazon Bedrock, and serverless components:
1. Clinical trial participant screening: Rapidly assess patient eligibility for clinical trials by summarizing relevant health data and matching against trial criteria. This could accelerate trial recruitment and improve matching accuracy.
2. Hospital discharge planning: Generate comprehensive discharge summaries based on the patient’s entire medical history, potentially improving post-discharge care coordination.
3. Chronic disease management: Create progress reports for patients with chronic conditions like diabetes or heart disease, enhancing long-term patient care and supporting patient wellness.
4. Telemedicine visit preparation: Generate concise patient summaries for remote healthcare providers before virtual consultations, enhancing the quality of telemedicine visits with comprehensive patient context.
5. Population health management: Summarize health trends and risk factors across patient populations to inform preventive care initiatives, improving community health outcomes and optimizing resource allocation.
These use cases demonstrate the versatility of combining the comprehensive data management of AWS HealthLake with the generative AI capabilities of Amazon Bedrock. By adapting the prompt engineering and data retrieval patterns we’ve established, healthcare organizations can address a wide range of challenges in patient care, operational efficiency, and clinical research.
Implementing these use cases would involve modifying the generative AI prompts to focus on the specific information needs of each scenario, and potentially expanding the types of FHIR resources queried from AWS HealthLake. The core architecture (with its emphasis on secure data handling, asynchronous processing, and generative AI-powered summarization) provides a solid foundation for these and many other healthcare applications.
Conclusion
Our patient profile summarization solution demonstrates how AWS HealthLake (serving as an interoperable data layer) can be combined with Amazon Bedrock and other AWS services to address critical challenges in healthcare. By leveraging the FHIR-native capabilities of AWS HealthLake for storing and querying healthcare data, organizations can build powerful solutions that transform how clinicians interact with patient information.
AWS HealthLake provides the foundation for this solution by:
- Storing standardized FHIR data in a secure, compliant environment
- Enabling comprehensive access to patient records through powerful query capabilities
- Supporting interoperability with existing healthcare systems
- Providing natural language processing to extract insights from unstructured clinical text
When combined with the generative AI capabilities of Amazon Bedrock, AWS HealthLake enables healthcare organizations to reduce administrative burden and enhance the patient experience.
This solution is just one example of how AWS is helping healthcare organizations harness the power of purpose-built services like HealthLake to transform healthcare delivery. As these technologies continue to evolve, we can expect even more innovative solutions that improve efficiency, reduce costs, and ultimately lead to better patient outcomes.
Contact an AWS Representative to know how we can help accelerate your business.