AWS for Industries
Massive Parallel Processing of Financial Transactions with Amazon EKS and Amazon MSK
This post was co-authored by Asiel Bencomo Corona, Specialist Solutions Architect – Containers and Elamaran Shanmugam, Sr. Specialist Solutions Architect – Containers.
Financial services institutions process billions of transactions with extreme load variability. Traditional infrastructure forces a costly trade-off: over-provision for peak capacity and potentially waste up to 80% of resources during normal periods, or under-provision and risk processing backlogs that delay downstream systems and violate SLA commitments. These institutions need infrastructure that scales based on actual demand to handle massive parallel processing without maintaining expensive idle capacity.
In capital markets, back-office systems exemplify this challenge. After front-office execution, these systems must process millions of trade transactions for enrichment and validation during market hours. Transaction volume spikes are unpredictable and can surge to 10x normal load within seconds. After market close, firms face a second processing burst: netting hundreds of millions of trades for clearinghouse submission and reconciling positions against custodian records. These asynchronous workloads require infrastructure that scales up rapidly to prevent processing backlogs, then scales back down to control costs.
This pattern extends across financial services. Payment processors handle transaction surges during payroll cycles and holiday shopping seasons, processing millions of payment validations and fraud checks asynchronously after initial authorization. Retail banks face similar challenges: asynchronous ledger updates that spike during business hours, real-time fraud detection scoring that must scale with transaction volume, and regulatory reporting pipelines that process massive datasets during month-end closes.
These workloads share a critical characteristic: they process massive transaction volumes asynchronously with highly variable, unpredictable load patterns. Traditional infrastructure cannot economically scale for these peaks without maintaining expensive idle capacity.
Summary of requirements:
- The platform must scale based on actual transaction backlog detecting when work is piling up and provisioning compute accordingly
- It must scale to zero during idle periods to eliminate waste, then scale to hundreds of processors within minutes when load arrives
- The architecture must support massive parallel processing while maintaining ordering guarantees where needed
- It must provide durable message persistence to ensure no transaction is lost during scaling events or failures and meet audit compliance requirements
- For multi-tenant service providers, the platform must deliver workload isolation and independent scaling per client while maintaining cost efficiency across shared infrastructure
- The solution must minimize operational overhead while delivering consistent performance and security
Architecture
We architected an event-driven platform that addresses these requirements by decoupling message ingress, buffering, and processing into independent layers. The ingress layer handles high-volume client connections with minimal processing. The buffering layer utilizes Kafka’s partition model to enable massive parallelization, maintain message ordering per partition, provide durability, and support compliance replay. The processing layer maps pods to Kafka partitions to deliver hundreds of concurrent workers processing transactions simultaneously, with elastic scaling that responds to demand in minutes.
This article focuses on the Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Elastic Kubernetes Service (Amazon EKS) integration pattern that enable elastic, cost-efficient processing at scale. We reference the ingress and database layers to show the complete data flow, but implementation details for those components are out of scope.
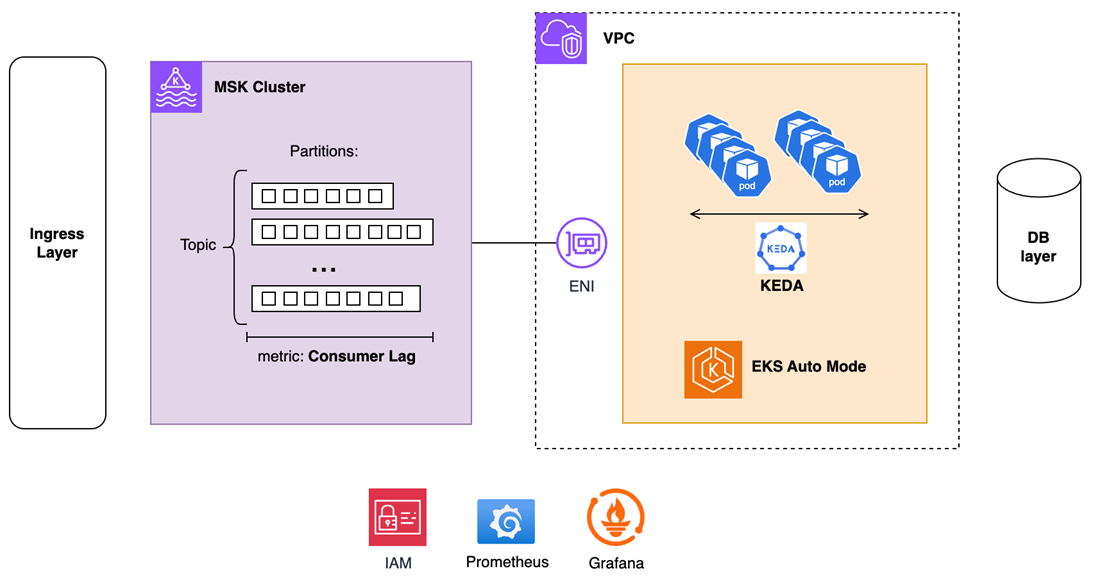
Figure 1 – Amazon EKS and Amazon MSK Integration pattern for Massive Parallel transaction processing.
Key Components:
- Amazon MSK – Provides durable message streaming that decouples ingestion from processing, absorbs traffic bursts without data loss, enables point-in-time replay for audit compliance, and isolates customer-facing services from database performance variability. AWS manages broker patching, version upgrades, and multi-AZ replication, eliminating operational overhead.
- Kubernetes Event-Driven Autoscaling (KEDA) – Scales processing pods based on Kafka consumer lag, which represents the actual backlog of unprocessed messages. This enables proactive capacity adjustment before processing falls behind, and cost-efficient scale-to-zero during idle periods when traditional CPU metrics would maintain unnecessary baseline capacity.
- Amazon EKS Auto Mode – Delivers elastic containerized compute with AWS-managed control plane and data plane infrastructure. Amazon EKS Auto Mode eliminates node group management, capacity planning, and Kubernetes version upgrade complexity, enabling teams to focus on application logic while AWS handles cluster operations, security patching, and infrastructure scaling.
- Micro-batching Pattern – Processing pods consume messages in batches rather than individually, optimizing both Kafka read operations and database writes through bulk inserts. This achieves order-of-magnitude throughput improvements per pod by reducing network round-trips and leveraging database bulk-insert optimizations, thus requiring fewer provisioned pods and directly lowering infrastructure costs per transaction.
Consider a trading back-office system where multiple broker-dealer clients generate millions of transactions with extreme load variability: market open surges, intraday lulls, and closing bursts.
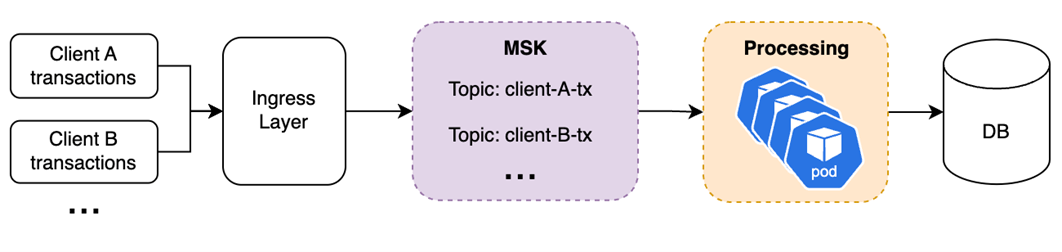
Figure 2 – Micro-batching pattern with Amazon MSK and Amazon EKS
The ingress layer receives these transactions, parses input data, and publishes messages to an MSK topic partitioned by client or transaction type to enable parallel processing. As messages accumulate during load spikes, Kafka consumer lag increases, which represents the number of unprocessed messages waiting in the Kafka topic queue.
KEDA continuously monitors this lag metric across all partitions. When lag exceeds configured thresholds (e.g., 5,000 messages per consumer), KEDA triggers horizontal pod scaling. EKS Auto Mode rapidly provisions the necessary compute capacity, launching nodes and scheduling pods, without manual node group configuration or capacity planning.
New processing pods read from MSK partitions in parallel, with each pod mapped to specific partitions to maintain ordering guarantees where required. Pods consume messages in micro-batches rather than individually, accelerating both Kafka polling operations and database writes through bulk inserts, delivering order-of-magnitude throughput improvements per pod.
As transaction volume subsides and lag decreases below thresholds, KEDA scales down pods and EKS Auto Mode deallocates and consolidates underutilized compute resources. The platform only consumes infrastructure proportional to actual demand eliminating potential wasted overprovisioned infrastructure and associated overspend.
Security is a top priority in every solution we build on AWS, and this architecture is no exception. Network connectivity occurs entirely within the customer VPC. MSK places elastic network interfaces in the same subnets as EKS processing pods, ensuring traffic never traverses the public internet. Access to MSK brokers uses IAM authentication with short-lived credentials, eliminating password management and rotation overhead. EKS pods leverage EKS Pod Identity to assume IAM roles, providing least-privilege access to MSK topics and downstream AWS services without embedding credentials in application code, and all traffic is encrypted at rest and in transit between services
Implementation Highlights
We’ve published a reference demo implementation at our AWS Samples GitHub repo. The repository includes producer and consumer applications, KEDA scaling configurations, and observability dashboards. For deployment prerequisites and step-by-step instructions, refer to the README.
This section highlights critical configuration decisions that enable the architecture’s performance, cost efficiency, and security characteristics.
Confluent Kafka Python Client and Cooperative-Sticky Rebalancing
The solution uses the Confluent Kafka Python client as a thin wrapper around the high-performance C library (librdkafka). For FSI workloads processing millions of messages, this translates to an optimized client that delivers higher throughput, and lower infrastructure costs per transaction.
This solution also leverages Cooperative Rebalancing to eliminate the “stop-the-world” behavior of traditional Kafka consumer groups. When KEDA scales pods up or down, only the consumers being reassigned pause processing, other processing pods continue uninterrupted. This is critical to avoid drops in processing throughput that can cascade into downstream delays.
trade-tx-consumer.py:
Micro-Batching
Batch size directly impacts throughput and latency trade-offs. Larger batches maximize database write efficiency through bulk inserts, but can also increase per-request processing time. Batch size must be tuned to meet per-message latency requirements. If your SLA requires latency-sensitive processing, batch sizes and database write times must stay within that budget.
trade-tx-consumer.py:
Define batch size to ensure high message counts while keeping total processing time (Kafka read + business logic + DB write) below your latency target. Also consider database-specific limits.
Lag-Based Autoscaling with KEDA
KEDA scales pods based on Kafka consumer lag, rather than CPU or memory utilization.
CPU-based autoscaling reacts after pods are overloaded, causing lag to accumulate before scaling triggers. Lag-based scaling is faster. It detects work piling up in the queue in near real-time and scales capacity before processing falls behind. For FSI workloads with variable load patterns, this prevents backlog accumulation that could violate SLAs.
However, scaling events also trigger Kafka consumer group rebalancing, which temporarily pauses processing while partitions are reassigned. This creates a counterintuitive challenge during scale-up: lag increases during rebalancing, potentially triggering additional scaling events before the current topology stabilizes, creating a feedback loop of repeated disruptions. To prevent this flapping, this solution provides two tuning strategies.
- Tune scaling configuration – Profile your application to measure consumer ramp-up time and rebalancing duration. Then use KEDA’s tuning options to give the system time to settle after each scaling decision, such as stabilizationWindowSeconds and periodSeconds. The guiding principle: scale up fast, scale down slowly.
- Use additional scaling metric: Inbound Message Rate – Lag alone tells that work is piling up, but not whether the situation is getting worse or resolving. By adding the broker-side inbound message rate (via Prometheus) as a second KEDA trigger, the system establishes a baseline processing capacity, maintaining enough pods to handle the current arrival rate regardless of lag. This prevents premature scale-down: replicas are only removed when both lag and inbound rate have dropped.
The minReplicaCount: 0 configuration enables scale-to-zero during idle periods (overnight, weekends), eliminating compute costs when no transactions are flowing.
Security with EKS Pod Identity
Consumer pods authenticate to MSK using EKS Pod Identity with IAM credentials, eliminating password management. Traditional Salted Challenge Response Mechanism (SCRAM) and Simple Authentication and Security Layer (SASL) authentication require storing and rotating credentials in Kubernetes Secrets. EKS Pod Identity uses short-lived IAM tokens automatically refreshed by the AWS SDK. This eliminates the need to store credentials in application code or container images, scopes down permissions for least-privilege access via IAM policies, and logs credentials access in AWS CloudTrail.
This approach eliminates credential sprawl in multi-tenant environments where different teams or clients require isolated topic access. IAM policies can enforce fine-grained permissions, critical for regulatory data segregation requirements and increased security policies.
Observability and Metrics
The consumer application exposes Prometheus metrics for comprehensive visibility.
This solution deploys Prometheus and Grafana using the kube-prometheus-stack for demo purposes. In a production setup, you can consider managed services such as Amazon Managed Service for Prometheus and Amazon Managed Grafana.
A custom Grafana dashboard visualizes:
- Kafka Inbound Messages (messages/sec published to MSK)
- Consumer Processing Rate (messages/sec consumed)
- Consumer Pod Count (current horizontal scale)
- Ready Node Count (metric: Ready Nodes Count – compute capacity provisioned by Auto Mode)
- Kafka Offset Lag (unprocessed message backlog)
- Kafka Inbound Msg Sec (processing throughput)
- Message Time in Kafka (time from publish to consumption)
- Consumer Processing Rate – Per Pod (messages/sec consumed)
These metrics provide a starting point for operational visibility. The image below shows how the solution scales after a spike in inbound client transactions, where inbound traffic jumps from 10msg/s to 1K msg/s and then to 5K msg/s. The offset lag closely follows this spike, and the system quickly scales up consumer pods and nodes to meet the new demand. Then demand decreases and consumer pods are scaled down accordingly.
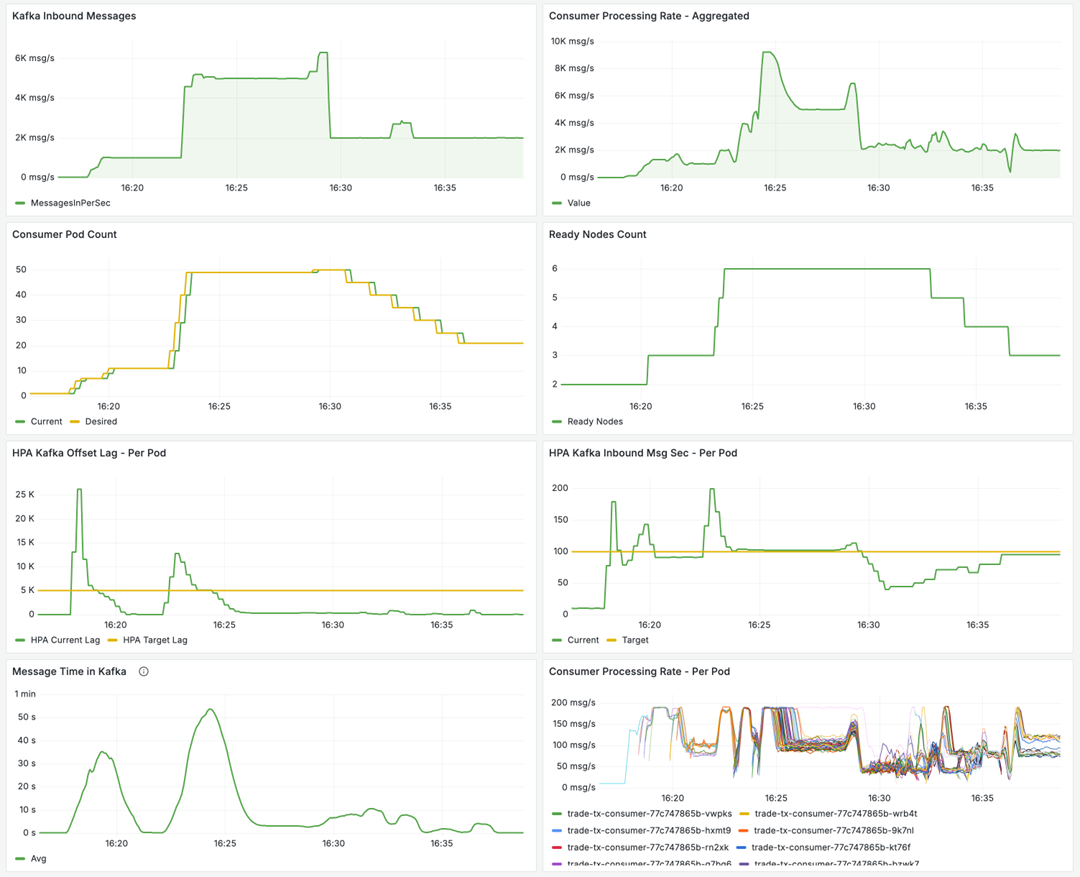
Figure 3 – Grafana Monitoring Dashboard showing Kafka, Processing, HPA and Other relevant metrics
Design Considerations
- This architecture extends naturally to support multiple concurrent workloads by creating different MSK topics with tailored partition strategies and independent consumer groups
- For workloads requiring strict ordering, such as trade settlement where transactions must process sequentially per account, topics use partition keys like
account_idto ensure all messages for a given entity land on the same partition, preserving FIFO guarantees - For workloads without ordering constraints, like reconciliation, fraud detection, or regulatory reporting, topics use random or null partition keys to maximize parallelism across hundreds of partitions
- Each consumer group scales independently: KEDA monitors lag per topic and consumer group, allowing real-time processors to scale based on market activity while overnight reconciliation processors scale separately based on file ingestion patterns
- Advanced implementations can introduce client tier differentiation: Tier 1 clients receive reserved pod capacity with
minReplicaCount> 0 for zero cold-start latency, while Tier 2/3 clients share elastic capacity that scales from zero, optimizing costs for less time-sensitive workloads
Conclusion
This event-driven architecture solves the infrastructure challenge facing financial services institutions. Organizations no longer need to choose between over-provisioning capacity or risking processing backlogs during load surges. The solution can scale elastically from zero to hundreds of processors based on actual demand, then scales back down to eliminate unnecessary costs. Find a reference implementation at our AWS Samples GitHub repo.
By leveraging Amazon MSK and Amazon EKS Auto Mode, organizations reduce operational overhead and shift engineering focus from infrastructure management to application development.
For FSI organizations processing billions of transactions across trade processing, payments, or banking operations, this architecture provides a production-ready blueprint for elastic, cost-efficient transaction processing.
Ready to explore more? Check out our Financial Services AWS Blogs to discover additional patterns and solutions designed specifically for the unique challenges of the financial services industry.