Artificial Intelligence
Author: Kareem Syed-Mohammed

Deploy SageMaker AI inference endpoints with set GPU capacity using training plans
In this post, we walk through how to search for available p-family GPU capacity, create a training plan reservation for inference, and deploy a SageMaker AI inference endpoint on that reserved capacity. We follow a data scientist’s journey as they reserve capacity for model evaluation and manage the endpoint throughout the reservation lifecycle.
Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference
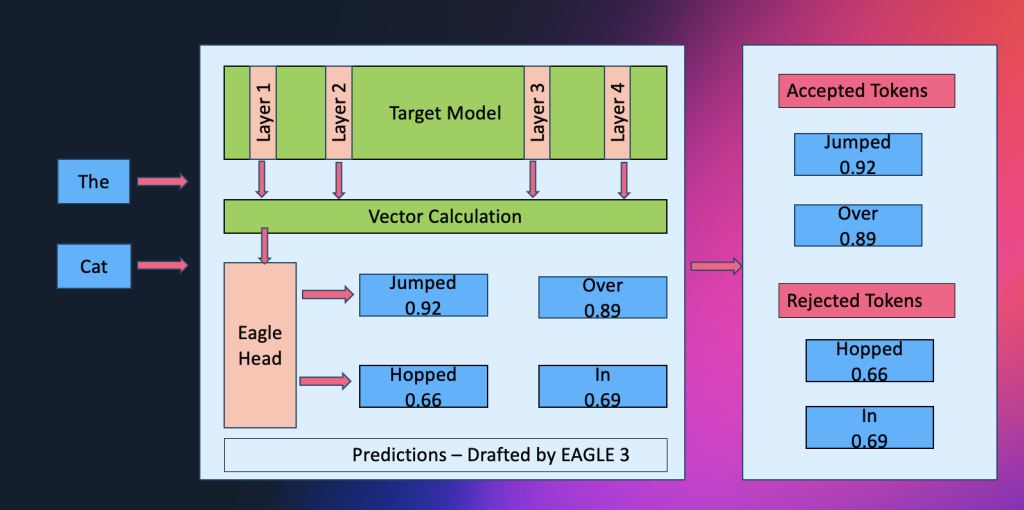
Amazon SageMaker AI now supports EAGLE-based adaptive speculative decoding, a technique that accelerates large language model inference by up to 2.5x while maintaining output quality. In this post, we explain how to use EAGLE 2 and EAGLE 3 speculative decoding in Amazon SageMaker AI, covering the solution architecture, optimization workflows using your own datasets or SageMaker’s built-in data, and benchmark results demonstrating significant improvements in throughput and latency.