AWS Startups Blog
IoT Primer: Telemetry on the Cloud
No single raindrop ever feels responsible for the flood.
– Anonymous
Welcome to the next post in the series of primers designed to help you achieve great solutions by bringing together a collection of “small things” within the Internet of Things (IoT) domain.
As mentioned in the first post in this series, the Pragma Architecture has four layers. This post continues our exploration of the Pragma Architecture’s Speed Layer; specifically some challenges that when left unaddressed turn telemetry into a flood.
Telemetry — Remotely Determine what a Device Senses
As stated previously, we’ve seen customers struggle with their telemetry solution if they start at a high-level and do not address these device-oriented questions:
- What should the device do with data if the device can’t send it to the stream?
- What happens if all the devices report at the same time and create massive peaks in reporting? What about a hundred, a thousand, or even ten thousand devices?
And these cloud-oriented questions:
- How does one gather data when HTTPS is too heavy for our resource-constrained small thing?
- How can a solution simultaneously provide more local network connections for devices in a global fleet?
- How can the solution scale globally but retain a centralized management and analysis capability spanning all the devices in the fleet?
We discussed the telemetry-related characteristics of a well-behaved fleet of small things. Specifically we noted how the use of randomly started reporting intervals, unique IDs, logging algorithms, and timestamps remove challenges that arise from a fleet of devices sending telemetry.
Now let’s explore the remaining cloud-oriented challenges of building a telemetry solution.
Multiprotocol Trickles Become a Stream
First, let’s say the devices in your existing product line are perfectly fine using HTTPS to send telemetry into your solution, but a new product is being designed that must hit a price point where there’s just not enough processing power or network resiliency available to the device for it to use HTTPS.
Second, instead of creating a whole new solution for the new non-HTTP-based devices, we need the cost and architectural benefit of supporting the new, resource-constrained product within the same solution as the first product.
In this situation, using machine-to-machine (M2M) protocols within a cloud-based, elastic solution can help reduce power and network considerations for the device while retaining regional communication capabilities. But introducing MQTT, CoAP, or other M2M protocols into your solution results in the challenge of managing a fleet of gateway servers for that particular protocol.
So let’s bring back the high-level diagram used in the Well Behaved Small Things post, but revise it to incorporate our thinking up to this point. With the revisions, an architecture comes into existence that is much more resilient in the real world of telemetry — specifically a regional, multiprotocol, stream-processing solution similar to the following diagram.
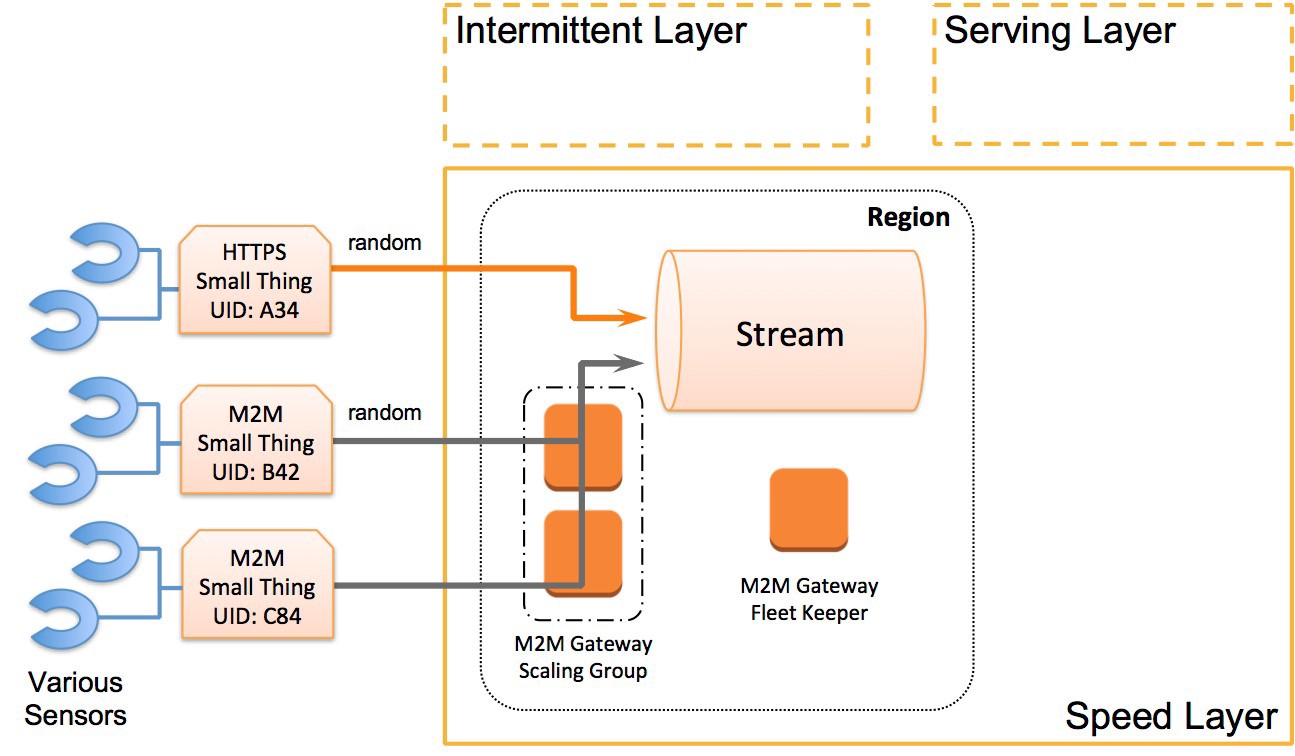
Since the HTTPS and M2M small things in our product line are well behaved, they have unique IDs and a random reporting behavior. These characteristics paired with an elastic stream processing solution (such as Kinesis) mean we have an architecture that will both smooth out the reporting spikes and meet the needs of the HTTPS-based small things. Then, by adding a M2M gateway-scaling group, we can support the new M2M-based product’s telemetry in the same solution.
By making these modifications to the high-level diagram we now have a “regional stream” architecture that addresses some of the most commonly experienced challenges. With an elastic stream processing solution at the core, we also have a single solution that can handle hundreds of thousands of devices. At this level of regional scale we’re now increasingly ready for the challenges of continued success of our small thing product line
Which leads us to the next challenge… what if we have a fleet of small things that span the globe? Let’s follow the flow into the next section.
Streams Flow into a River
Let’s address the potential for synchronized behavior challenges first.
When going global, the random reporting approach used by our well behaved devices will not avoid the fact that devices are often used on human waking or sunup / sundown cycles; therefore, our next solution iteration must address those globally synchronized behaviors.
To reduce global networking challenges we embrace the “regionality” of our current approach and setup a “regional stream” solution in each of the regions where our customers reside. This provides local network connectivity for the devices while keeping the global flock subdivided, thereby removing the potential for any globally synchronized device behavior. This “regional stream” approach does mean each device will have to determine its operating region, but we’ll speak to that challenge in the next post.
Now we have multiple regional streams all accepting telemetry from the small things within that region; however, we still need visibility of the global device fleet for customers and ourselves. This is even more of a need when a given customer’s devices are spread across the globe and the people who seek insights from the telemetry are using a single application.
To address this, let’s have each regional stream flow into a centralized river of telemetry data. That river is also well served by an elastic stream processing solution. Let’s take a look at such an approach in the following diagram.
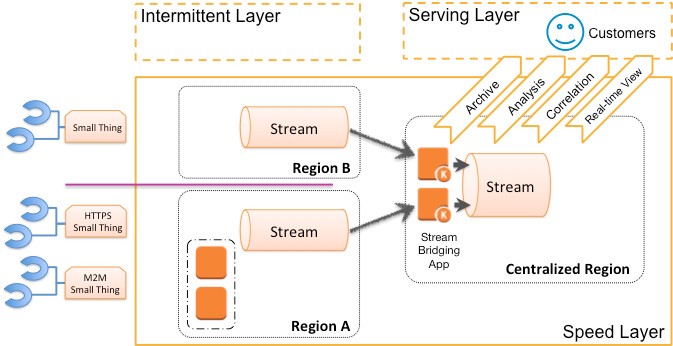
Some details have been omitted in order to emphasize each region in play in this diagram. Region A and region B both have small things reporting but there is a stream bridging application that is reading from each regional stream and then writing what is read into the centralized region’s stream.
The following picture captures the raucous and yet peaceful beauty of that forming river.

By going through a couple design iterations we’ve also organized the flood of sensor data into a peacefully flowing solution that is relatively straightforward, elastic, and scalable. But this river goes somewhere…
Rivers Flow into an Ocean
We have one more step, because if a river flows without any outlet we still end up with a flood. Also, we still don’t have an answer around how to deliver a centralized management and analysis capability spanning all the devices in the fleet.
To meet customer needs in this part of our telemetry exploration, we need to bring in one other concept from the Pragma Architecture, the Serving Layer. This layer is the access point for systems and humans to interact with data from the centralized region and devices in a global fleet.
Going deeper into the Serving Layer is where our exploration of telemetry stops and gives way to well worn, highly sophisticated approaches for working with this amount of data: big data.
Very simply put, from the big data perspective telemetry equals ingest.
Either driven by time, driven by device counts, or both, rivers of telemetry become big data ingest challenges. As mentioned in the first article, the Pragma Architecture is itself congruent with the real-time and batch-mode big data implementations possible on the AWS platform. The telemetry flowing into the centralized region in our solution is a fantastic source of data to ingest into the entire ecosystem of big data solutions. Once you have your rivers of data flowing and you’re looking at a growing ocean of data, you will want to explore the series of blog posts and content that exists on this topic.
Onward
In the last two posts, we have addressed challenges starting from getting devices sending well-behaved trickles of telemetry through how we can avoid a global sensor flood. We took a common high-level starting point and transformed it into a solution that supports both regional subdivisions of different devices and a global and elastic solution.
Now you might be asking, how do we change the behavior of our fleet of small things? And how does each device know in which region it should operate?
In the next post we’ll seek answers to those questions and continue into the second-most common source of small thing related challenges, as well as the other direction of data flow in the Pragma Architecture’s Speed Layer: Commands.
May your success be swift and your solution scalable.