AWS Big Data Blog
Authorize SparkSQL data manipulation on Amazon EMR using Apache Ranger
This post was last updated July 2022. With Amazon EMR 6.7, all Apache Spark DDL’s are now supported, except for CREATE VIEW. For details, see the section under “limitations”.
NOTE: You will need to redeploy Spark service definition (link) on your Apache Ranger server. Instructions on how to redeploy can be found here.
With Amazon EMR 5.32, Amazon EMR introduced Apache Ranger 2.0 support, which allows you to enable authorization and audit capabilities for Apache Spark, Amazon Simple Storage Service (Amazon S3), and Apache Hive. It also enabled authorization audits to be logged in Amazon CloudWatch. However, although you could control Apache Spark writes to Amazon S3 with these authorization capabilities, SparkSQL support was limited to only read authorization.
We’re happy to announce that with Amazon EMR 6.4, Apache Ranger SparkSQL integration supports authorizing capabilities for data manipulation statements (DML). You can now authorize INSERT INTO, INSERT OVERWRITE, and ALTER statements for SparkSQL using Apache Ranger policies.
Architecture overview
Amazon EMR support for Apache SparkSQL is implemented using the Amazon EMR record server, which reads Apache Ranger policy definitions, evaluates access, and filters data before passing the data back to the individual Spark executors.
The following image shows the high-level architecture.
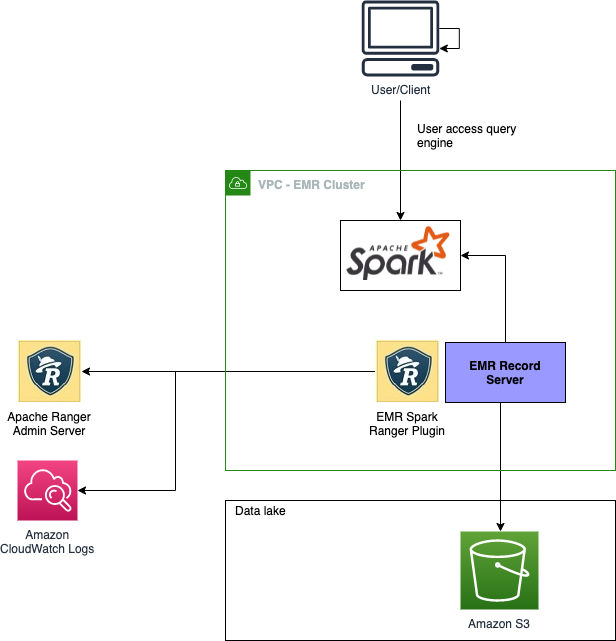
Implementation details
Before you begin, set up your Apache Ranger and EMR cluster. For instructions, see Introducing Amazon EMR integration with Apache Ranger. If you have an existing installation on Apache Ranger server with Apache Spark service definitions deployed, use the following code to redeploy the service definitions:
Now that the service definition has been updated, let’s test the policies.
For our use case, assume you have an external Amazon S3 backed partitioned Hive table. You want to use a SparkSQL DML statement to insert data into the table.
Use the following code for a table definition:
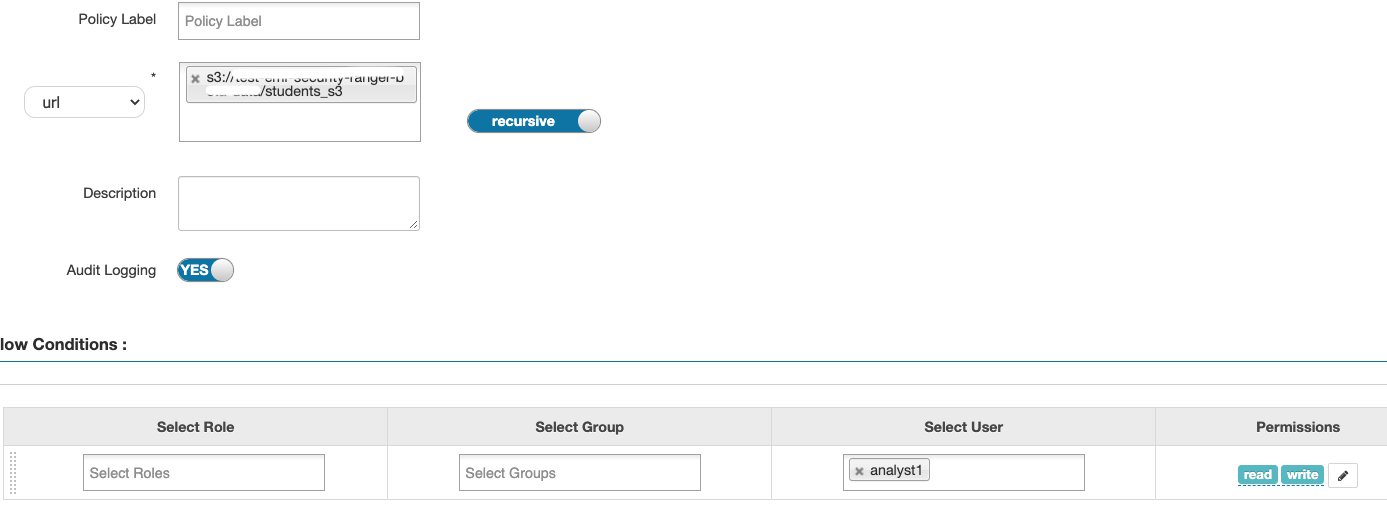
You can now set up the authorization policies on Apache Ranger. The following screenshots illustrate this process.
Because the table is externally backed by Amazon S3, we first need to enable read and write access to the Amazon S3 location of the table. If the location is on HDFS, the URL should have the HDFS path—for example, hdfs://xxxx.
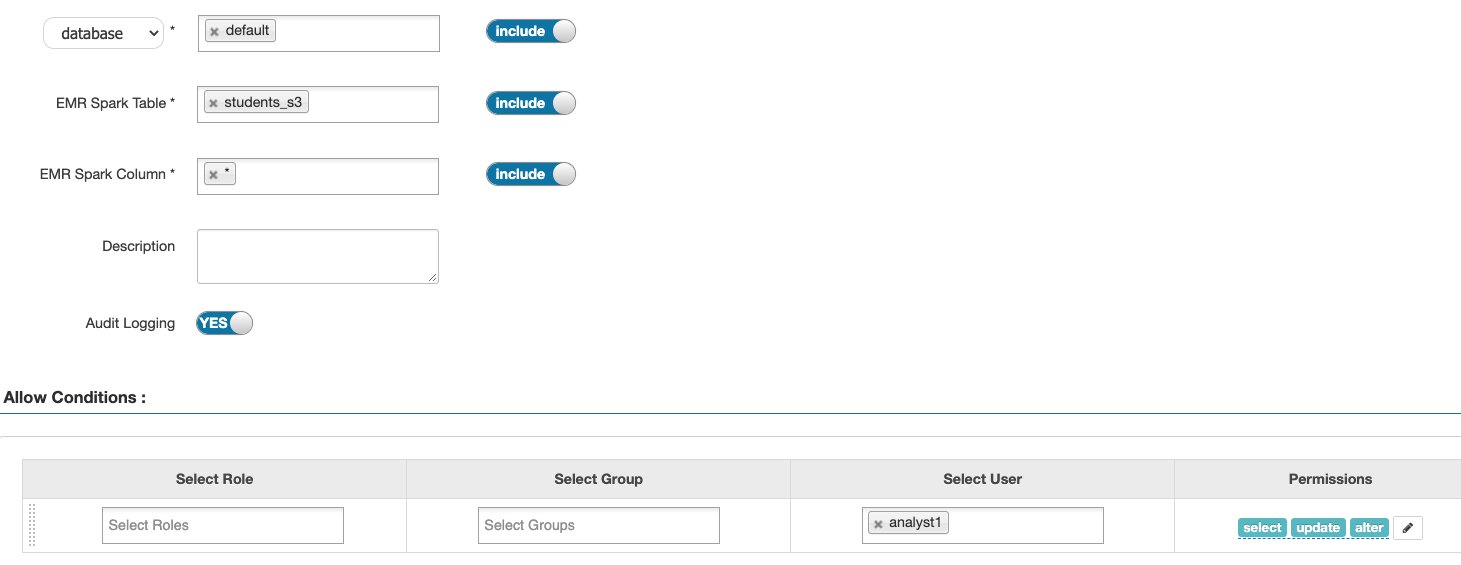
Next, we add SELECT, UPDATE, and ALTER permissions, allowing users to use the DML commands. Any update to the table metadata like statistics or partition information requires the ALTER permission.
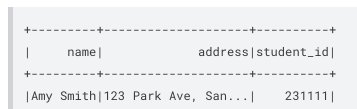
After we set up these Apache Ranger policies, we can start testing the DML statements. The following code is an example of an INSERT INTO statement:
The following screenshot shows our results.
We can audit this action on CloudWatch, similar to other actions.
![]()

Limitations
Inserting data into a partition where the partition location is different from the table location is not currently supported. The partition location must always be a child directory of the main table location.
| SQL statement/Ranger action | STATUS | Supported EMR release |
| SELECT | Supported | As of 5.32 |
| SHOW DATABASES | Supported | As of 5.32 |
| SHOW TABLES | Supported | As of 5.32 |
| SHOW COLUMNS | Supported | As of 5.32 |
| SHOW TABLE PROPERTIES | Supported | As of 5.32 |
| DESCRIBE TABLE | Supported | As of 5.32 |
| CREATE TABLE | Supported | As of 5.35 and 6.7 |
| CREATE DATABASE | Supported | As of 5.35 and 6.7 |
| INSERT OVERWRITE | Supported | As of 5.35 and 6.7 |
| INSERT INTO | Supported | As of 5.35 and 6.7 |
| ALTER TABLE | Supported | As of 6.4 |
| DROP TABLE | Supported | As of 5.35 and 6.7 |
| DROP DATABASE | Supported | As of 5.35 and 6.7 |
| DROP VIEW | Supported | As of 5.35 and 6.7 |
| CREATE VIEW | Not Supported | . |
Available now
Amazon EMR support for SparkSQL statements INSERT INTO, INSERT OVERWRITE, and ALTER TABLE with Apache Ranger is available on Amazon EMR 6.4 in the following AWS Regions:
- US East (Ohio)
- US East (N. Virginia)
- US West (N. California)
- US West (Oregon)
- Africa (Cape Town)
- Asia Pacific (Hong Kong)
- Asia Pacific (Mumbai)
- Asia Pacific (Seoul)
- Asia Pacific (Singapore)
- Asia Pacific (Sydney)
- Canada (Central)
- Europe (Frankfurt)
- Europe (Ireland)
- Europe (London)
- Europe (Paris)
- Europe (Milan)
- Europe (Stockholm)
- South America (São Paulo)
- Middle East (Bahrain)
For the latest Region availability, see the Amazon EMR Management Guide.
Conclusion
Amazon EMR 6.4 has introduced additional authorizing capabilities for data manipulation statements with Apache Ranger 2.0. You can use statements like INSERT INTO, INSERT OVERWRITE, and ALTER in SparkSQL and control authorization using Apache Ranger policies.
Related resources
To additional information, see the following resources:
- Introducing Amazon EMR integration with Apache Ranger
- Integrate Amazon EMR with Apache Ranger
- Amazon EMR 6.3 now supports Apache Ranger for fine-grained data access control
- Implementing Authorization and Auditing using Apache Ranger on Amazon EMR
About the Authors
 Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.
Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.
 Jalpan Randeri is a Senior Software Engineer at AWS. He likes working on performance optimization and data access controls for big data systems. Outside work, he likes watching anime & playing video games.
Jalpan Randeri is a Senior Software Engineer at AWS. He likes working on performance optimization and data access controls for big data systems. Outside work, he likes watching anime & playing video games.