亚马逊AWS官方博客
Amazon EMR 的 Graviton2 初体验
Amazon EMR 现在支持 Amazon EC2 M6g 实例,以便为云工作负载提供最佳性价比。Amazon EC2 M6g 实例由 AWS Graviton2 处理器提供支持,此类处理器由 AWS 设计定制设计并配备 64 位 Arm Neoverse N1内核。与前一代实例相比,对于基于 Graviton2 的实例上的 Spark 工作负载,Amazon EMR 可实现高达 35% 的成本降低和 15% 的性能改进。
本文将介绍如何在Amazon EMR中采用M6g实例并通过TPC-DS进行基本的性能测试。TPC-DS基准测试是一个决策支持基准测试,它模拟了决策支持系统的几个普遍适用的方面,包括查询和数据维护。作为一个通用的决策支持系统,TPC-DS基准测试提供了一个有代表性的性能评估。基准测试结果度量在受控、复杂、多用户决策支持工作负载下给定硬件、操作系统和数据处理系统配置的单用户模式下的查询响应时间、多用户模式下的查询吞吐量和数据维护性能。TPC基准的目的是向行业用户提供相关的、客观的性能数据。TPC-DS采用星型、雪花型等多维数据模式。TPC-DS模拟电商销售,库存等数据且模拟数据倾斜。它包含7张事实表,17张纬度表。另外包含99个SQL查询语句,覆盖SQL99和2003的核心部分以及OLAP。
测试环境采用EMR发行版6.1.0,在集群上安装的应用程序包括:Ganglia、Hive、Spark、Hadoop(默认安装)

作为对比测试我们选择部署了M5实例和M6g实例两套集群。
| 实例类型 | vCPU | 内存 (GiB) | EBS(GiB) | 网络带宽 (Gbps) | EBS 带宽 (Mbps) | 实例数量 |
| m6g.xlarge | 4 | 16 | 4 * 128GiB GP2卷 | 最高 10 | 最高 4750 | 1* Master; 5 * Core |
| m5.xlarge | 4 | 16 | 4 *128GiB GP2卷 | 最高 10 | 最高 4750 | 1* Master; 5 * Core |
M5 集群:
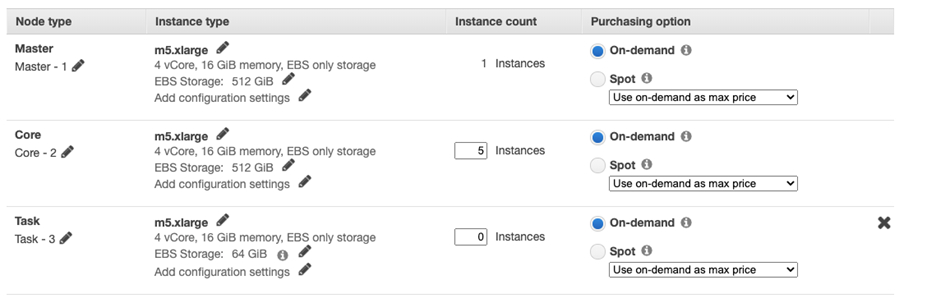
M6g 集群:
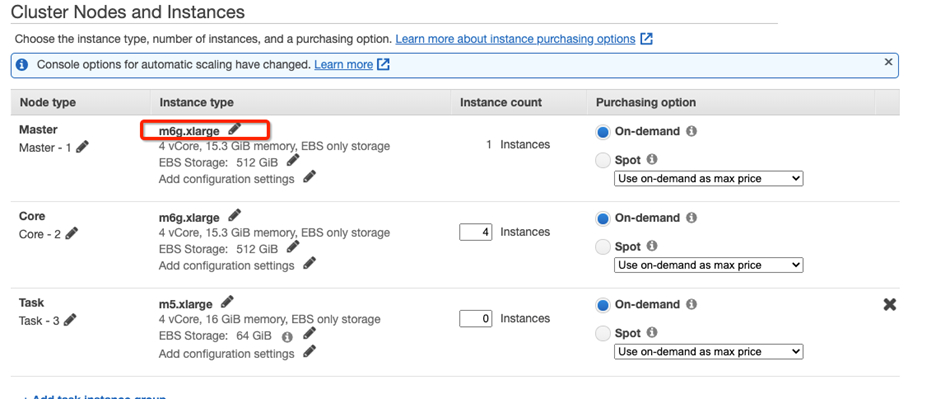
测试工具我们选择了Hive Testbench。Hive Testbench由数据生成器和一组查询测试用例组成,可以实现在一定规模上对Apache Hive进行实验。Hive Testbench可以帮助您在大型数据集上体验Hive的性能,并能够查看配置优化参数和高级设置等方法对Hive的性能影响。
安装Hive Testbench的过程非常简单,从GitHub官网clone hive-testbench源码,Git地址如下:https://github.com/hortonworks/hive-testbench.git
生成测试数据集,因为整个创建测试数据集的时间比较长,这里建议大家使用screen命令。
cd hive-testbench
./tpcds-build.sh

在本地HDFS上生成1TB的hive表数据集: ./tpcds-setup.sh 1000

成功生成测试数据并创建测试数据集,如果不指定数据目录则默认生成到/tmp/tpcds目录下。我们可以使用如下命令查看数据集创建的情况。
hadoop fs -ls /tmp/tpcds-generate/1000

hadoop fs -du -h /tmp/tpcds-generate/1000

另外,很多客户通过在 Amazon S3上构建数据湖以加速创新,并使用就地查询、分析和机器学习工具提取有价值的洞察。为了应对数据湖的增长,可使用 S3 访问点配置对数据的访问,并赋予每个应用程序或应用程序组特定的使用权限。您还可使用 AWS Lake Formation 快速创建数据湖,然后集中设定并实施安全、监管及审计策略。收集数据库和 S3 资源中的数据,并使用机器学习算法对其进行清理和分类。所有 AWS 资源容量均可扩展,以适应不断增大的数据存储,且无需前期投资。
因此这里我们也在S3上创建了数据集作为测试用例。在S3上生成1TB数据集的命令如下:
FORMAT=parquet ./tpcds-setup.sh 1000 s3://<bucket-name>/tpcds

导入数据到hive中,正常情况下数据和表应该是自动创建并加载到hive的,但是如果没有自动创建的话,可以执行以下sql手工创建。
cd ~/hive-testbench/ddl-tpcds/text
hive -d DB='数据库名' -d LOCATION='数据文件目录' -f alltables.sql
导入HDFS上的数据文件:hive -d DB='<database name>' -d LOCATION='<data files path>' -f alltables.sql

导入S3上的数据文件:hive -d DB='<database name>' -d LOCATION='s3://<bucket-name>/<prefix>/' -f alltables.sql

创建数据库和表之后,可以使用下面的命令查看:

在开始正式的测试之前,我们要对数据库中表的情况进行一个统计分析以提高SQL计划的执行效率。anlyze.sql 主要是用于这项分析工作,可以提高后续的查询速度。

具体的测试可以跑sample-queries-tpcds目录下的99个SQL。或者运行根目录下的runSuite.pl 执行所有测试SQL。例如可以直接执行query<编号>.sql测试性能。

我们对TPC-DS 1TB数据集在HDFS上简单测试了8个SQL,结果如下:
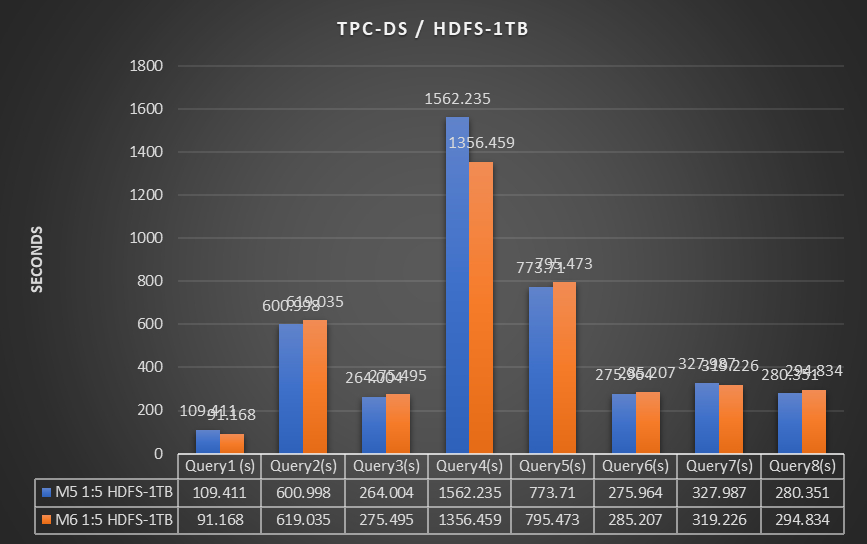
另外对TPC-DS 2TB数据集在S3上同样测试了8个SQL,结果如下:

从Cloudwatch中查看M5和M6g的core node实例CPU的负载情况如下:

测试结论:
从Cloudwatch的CPU利用率来看,M5的CPU利用率很高基本都在80%以上。M6g的CPU并没有打满,只有50%左右的利用率,可见M6g的EMR集群可以承载更多的并发负载。
Amazon EMR 现在支持 Amazon EC2 M6g 实例,以便为云工作负载提供最佳性价比。Amazon EC2 M6g 实例由 AWS Graviton2 处理器提供支持,此类处理器由 AWS 设计定制设计并配备 64 位 Arm Neoverse 内核。与前一代实例相比,对于基于 Graviton2 的实例上的 Spark 工作负载,Amazon EMR 可实现高达 35% 的成本降低和 15% 的性能改进。此外,与在前一代实例上运行开源 Apache Spark 相比,此适用于 Apache Spark 的 EMR 运行时与 EC2 M6g 实例的组合可将总成本降低多达 76% 并将性能提高 3.6 倍。
面向 Amazon EC2 M6g 实例的 Amazon EMR 现已支持下列区域的 6.1.0 和 5.3.10 及更高版本的 EMR:美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、欧洲(爱尔兰)、欧洲(法兰克福)和亚太地区(东京)。
参考资料:
- Amazon EMR now provides up to 30% lower cost and up to 15% improved performance for Spark workloads on Graviton2-based instances Link
- TPC-DS Specification Link
- Hive-testbench Link