亚马逊AWS官方博客
Amazon Nova Lite Fine-Tuning: 高性价比的视觉检测模型微调案例与实践
摘要
本文介绍了在 Amazon Bedrock 上对 Amazon Nova Lite 1.0进行微调的两个实际应用案例,展示了在专业计算机视觉任务中如何在保持成本效益的同时实现显著的性能提升。通过对航拍视角检测和低光照监控场景的系统性评估,我们以最小的训练成本实现了增强的指令遵循能力和更高的检测准确率。
背景介绍
Amazon Nova Lite 1.0作为 AWS 多模态基础模型系列的一部分,在通用视觉任务中提供了卓越的性价比。然而,专业应用场景往往需要增强的指令理解能力和特定领域的优化。本研究评估了微调技术在两个不同用例中的有效性:
- 航拍视角群组检测:增强指令遵循能力以实现智能边界框分组,减少密集标注的视觉混乱
- 低光照检测准确率提升:提高夜间监控中的实体识别准确率,降低误报率
案例研究 1:航拍视角群组检测
问题定义
在客户项目实施过程中,我们遇到了航拍视角目标检测的特定业务需求。在某些应用场景下,当系统检测到密集分布的目标物体时,客户更希望智能输出少量大型边界框来标识目标区域或目标群组,而不是输出大量细粒度的小框。这一需求主要基于以下考虑:
- 提升用户体验:减少视觉干扰,突出关键区域
- 优化系统性能:降低后续处理的计算复杂度
- 成本控制:减少输出 token 数量,降低 API 调用成本
指令遵循方法
提示词如下:
在提示词中设计了一条关键控制指令:
该指令要求模型在检测到超过 10 个目标物体时自动切换到区域级检测模式,输出覆盖目标群组的大型边界框,而不是逐个标注每个物体。
目标输出行为
 |
基线性能分析
测试结果表明,Nova Lite 1.0模型未能有效遵循提示词中的控制指令。即使面对包含大量目标物体的图像,模型仍然倾向于输出细粒度的检测结果。
通过对相似图像检测结果的统计分析,我们发现 Nova Lite 1.0平均输出超过 60 个检测框。这种大规模输出不仅影响推理延迟,还会因生成过多的输出 token 而导致不必要的成本增加。
 |
为了定量评估 Nova Lite 和 Nova Pro 在航拍视角检测任务中的性能差异,我们对多个样本进行了系统性统计分析。通过比较两个模型版本在相同场景下的检测输出,我们获得了以下关键数据洞察。
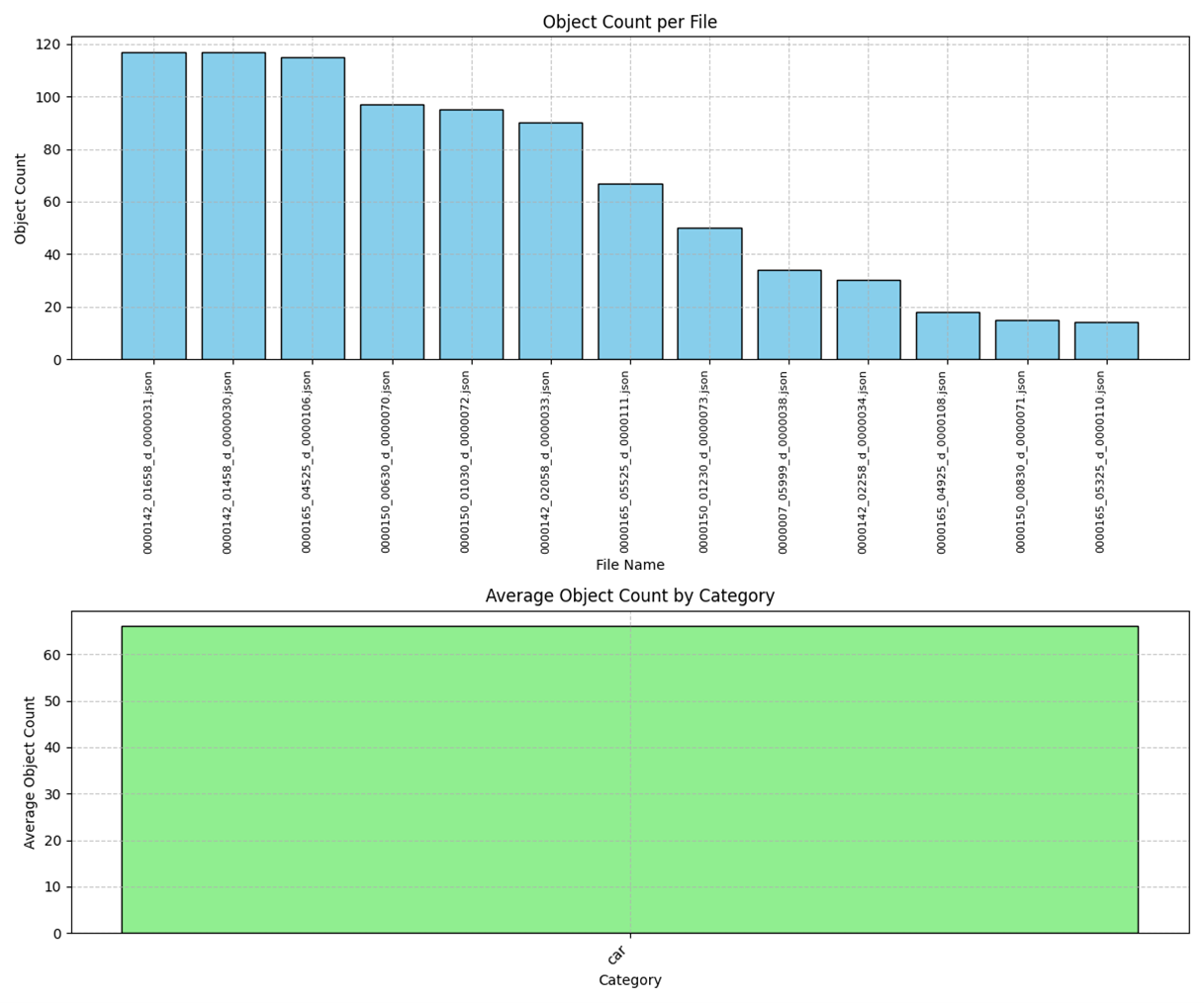 |
Nova Lite 输出统计分析:
对比Nova Pro 输出结果
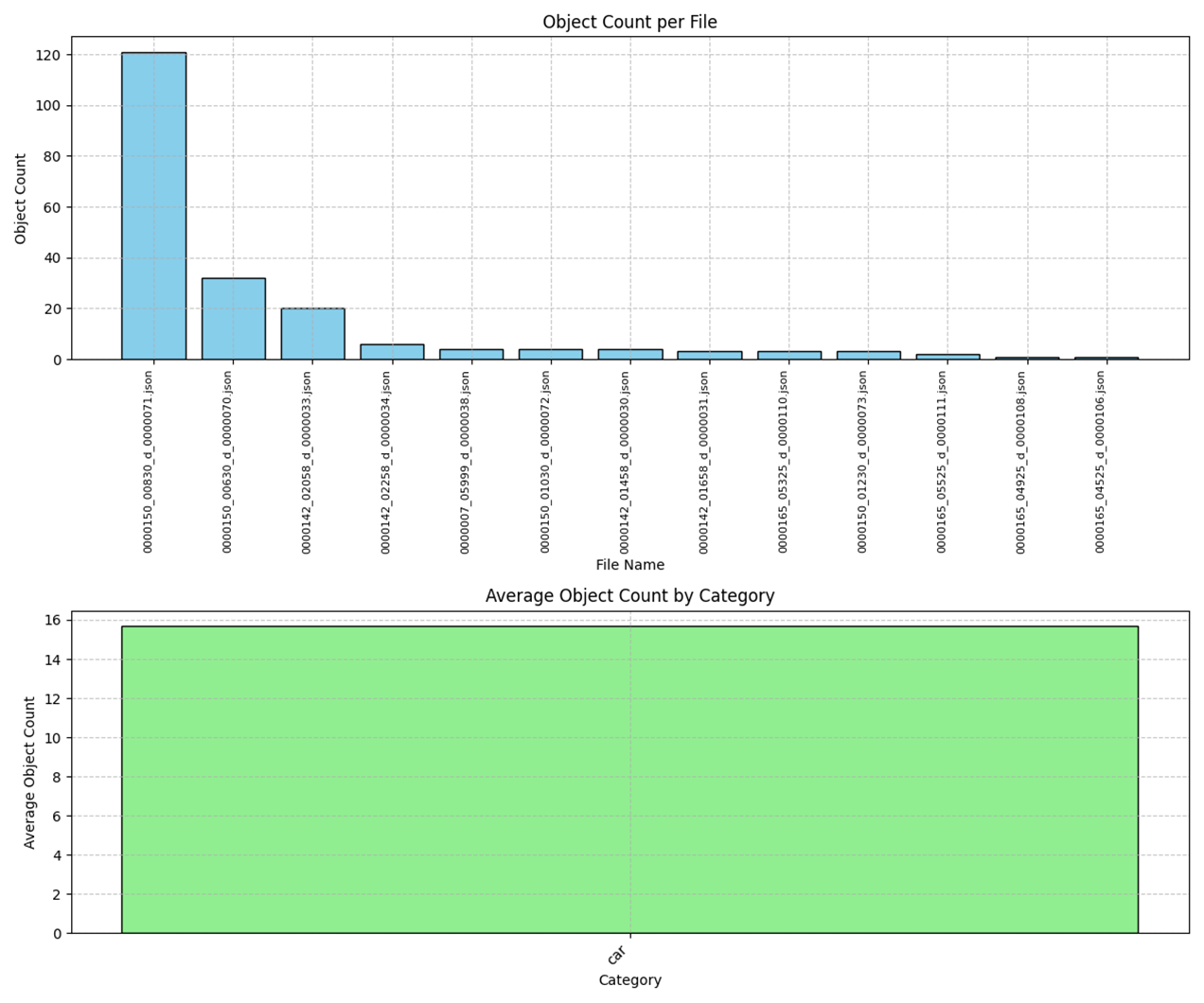 |
为什么Fine-Tuning Nova Lite
我们的基线分析揭示了性能与成本之间的权衡:Nova Pro 在指令遵循和复杂语义理解方面表现出色,但成本显著高于 Nova Lite(输入 token 成本:$0.0008 vs $0.00006)。然而,Nova Lite 1.0在我们的航拍视角群组检测场景所需的指令理解能力方面存在不足。
我们假设,通过微调 Nova Lite 可以解决这一困境,在我们的特定用例中实现 Pro 级别的指令遵循能力,同时保持 Lite 的成本效益。为了验证这一方法,我们对微调后的模型在这一专业检测任务中的性能进行了全面的测试和验证。
Fine-Tuning Nova Lite: 验证
Fine-Tuning 效果概览
基于基线分析中识别出的性能差距,我们开发了一个定制微调的 Nova Lite 模型,以增强航拍视角群组检测的指令遵循能力。
验证结果展示了显著的改进:
- 使用关键词提示时检测框数量减少 92%(平均从 91.47 降至 7.04 个)
- 增强的指令理解能力和输出一致性
- 以 Lite 的价格实现 Pro 级别性能的高性价比解决方案
Notes:
有关详细的微调实施步骤,请参阅本文后续章节。
验证架构设计
为了全面评估微调效果,我们设计了一个多维度测试验证框架:
场景覆盖
- 场景 1:训练集图像验证 – 评估模型在已见数据上的拟合性能
- 场景 2:泛化能力测试 – 评估模型在未见数据上的性能
提示词策略对比
每个测试场景采用双重提示词策略:
- 带关键词提示:包含基于群组的检测控制指令
- 不带关键词提示:标准目标检测提示词
Model invocation implementation reference: https://aws.amazon.com/blogs/machine-learning/implementing-on-demand-deployment-with-customized-amazon-nova-models-on-amazon-bedrock
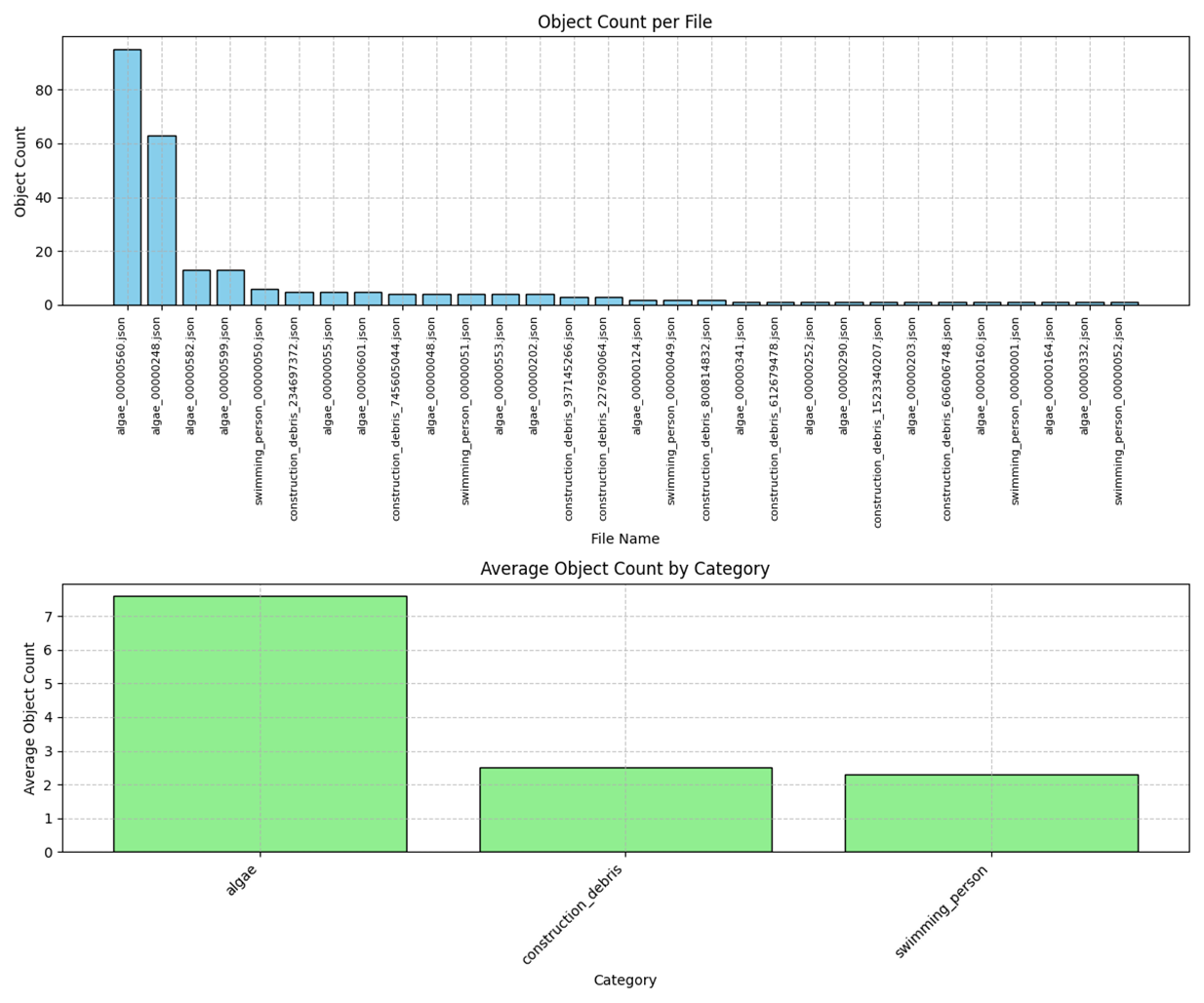 |
性能评估
通过对微调前后模型输出的初步对比分析,我们观察到:
微调前模型性能:检测目标物体数量普遍较高,存在明显的过度检测现象
微调后模型性能:检测框数量显著减少,数量分布相对均衡
整体测试中未出现极端多框输出情况,表明微调策略有效改善了过度检测问题。
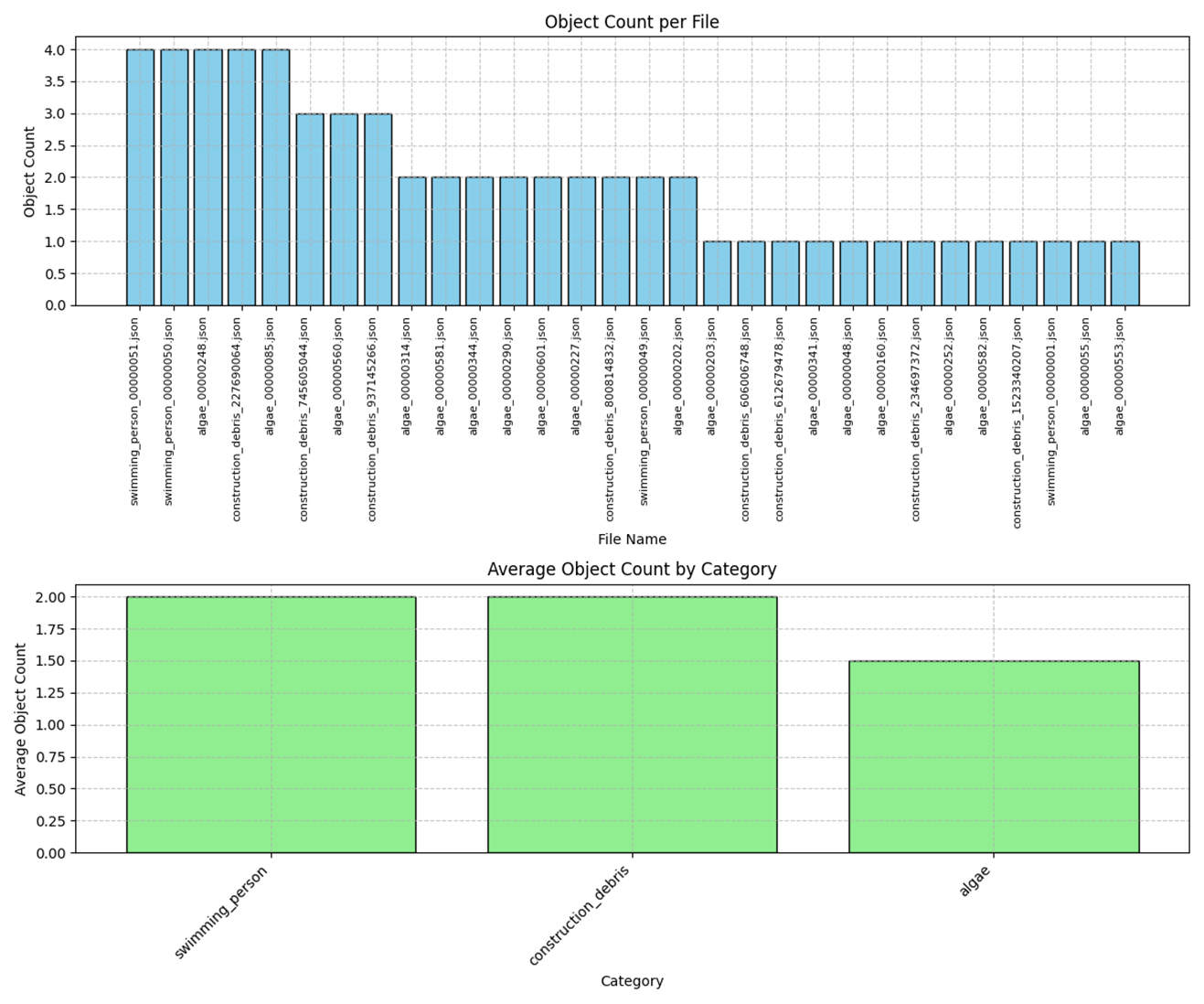 |
Fine-Tuning 效果对比
通过可视化对比,微调后的 Custom-Model 在检测框数量控制和目标区域识别方面均显示出显著改进。
典型示例
 |
 |
定量评估
测试配置
- 模型对比:Custom-Model(微调模型)vs Nova-Lite(原始模型)
- 提示词策略:带关键词提示 vs 不带关键词提示
- 测试数据:20 张航拍视角图像
- 重复验证:每个组合进行 5 轮测试
- 总计:4 种组合 × 5 轮 = 20 次测试,400 个样本测试结果
| Prompt Type | Model | Average Detection Boxes | Sample Count | |
| 1 | With Keywords | Custom-Model | 7.04 | 100 |
| 2 | With Keywords | Nova-Lite | 91.47 | 100 |
| 3 | Without Keywords | Custom-Model | 47.68 | 100 |
| 4 | Without Keywords | Nova-Lite | 94.17 | 100 |
测试结果分析
- 微调效果显著性验证
- 带关键词场景:检测框数量从 91.47 降至 7.04,降幅 92%
- 不带关键词场景:检测框数量从 94.17 降至 47.68,降幅 49%
- 提示词敏感度差异
- Custom-Model 对提示词高度敏感:带关键词时性能更优(7.04 vs 47.68)
- Nova-Lite 提示词响应有限:两种提示词类型下性能相似(91.47 vs 94.17)
以下对比数据展示对象检测的分布:
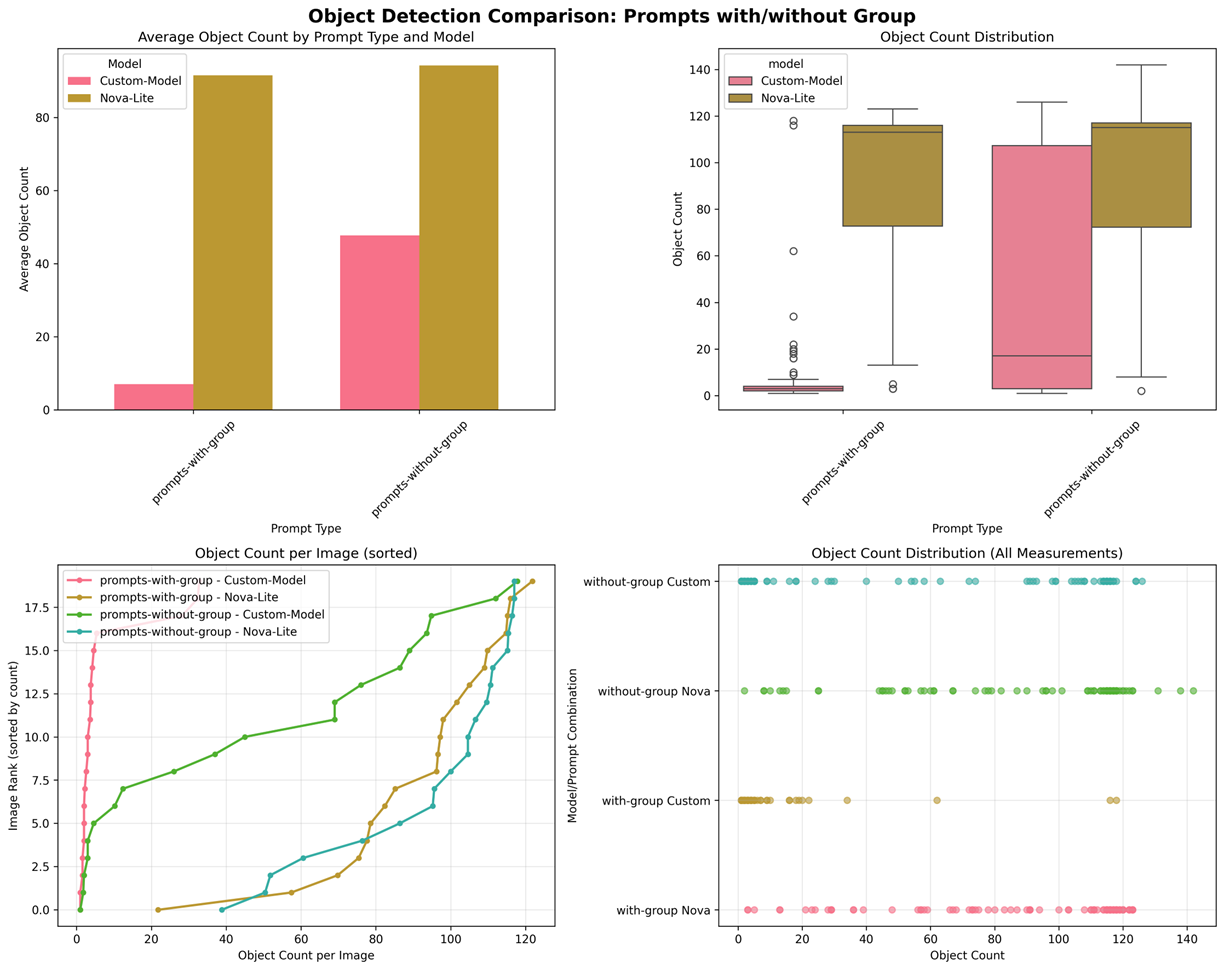 |
- 平均检测框数量对比(左上)
- Custom-Model 表现优异:在两种提示词类型下均显著低于 Nova-Lite
- 带关键词效果最佳:Custom-Model 配合关键词显示最少检测框(约 7 个)
- Nova-Lite 明显过度检测:两种提示词类型下均超过 90 个检测框
- 检测框数量分布(右上)
- Custom-Model 稳定性优异:
- 带关键词:分布集中在低值区间,异常值较少
- 不带关键词:中位数约为 50,但存在显著变异性
- Nova-Lite 分布一致:两种提示词类型下分布相似,集中在高值区间
- 每张图像检测框排序(左下)
- 四条曲线层次分明:验证了模型和提示词的不同效果
- Custom-Model + 关键词:曲线最平缓,大多数图像检测框数量低于 15
- Nova-Lite 两条重叠线:表明提示词对原始模型影响极小
- 所有测量值分布(右下)
- 数据密度可视化:清晰展示每种组合的分布特征
- Custom-Model 配合关键词:数据点高度集中在低值区域
- Nova-Lite:数据点广泛分布在高值区域,证实了过度检测问题
微调效果总结
- 增强的指令理解能力:Custom-Model 在特定场景下显著提升了对提示词指令的理解和执行能力
- 稳定性提升:Custom-Model 不仅减少了检测框数量,还提高了结果的一致性
案例研究 2:夜间低置信度检测优化
为了进一步验证 Nova Lite 微调技术在实际业务场景中的应用效果,我们在一个对准确率要求极高的实体检测和告警业务场景中进行了降低误报率和提高检测准确率的实验。该场景重点
测试模型在复杂环境下的智能决策能力和可靠性表现,特别是在应用滤镜的夜间低光照条件下。
问题定义
在复杂的监控环境中,光照变化、阴影、反射和植被移动等因素经常被误识别为可疑目标。当系统频繁产生误报时,不仅会增加人工验证工作量,更严重的是会降低操作人员对系统的信任度,可能导致真正的安全威胁被忽视。
当场景复杂且没有明显需要标注的目标实体时,Nova Lite 可能会以较低的准确率标注相对可疑的物体,产生误报。虽然在提示词中指示 Nova Lite 检测到的物体必须具有高置信度,并在置信度不足时避免标注,但效果有限,我们期望通过 Nova Lite 微调来解决这一问题。
Fine-Tuning 设计
采用 Nova Lite 微调策略:数据标注 → 创建训练任务 → 模型部署 → 效果验证
关键提示词片段
最小训练数据集与效果对比
Notes:
采用人工校准,针对不同的低置信度场景,手动标注 8-10 张图像即可
标准 Nova Lite 1.0识别结果
 |
(图片来自互联网)
微调后的模型展示了指令遵循能力,正确识别了低置信度场景并遵守了提示词中指定的高置信度要求:
 |
关键成果
通过对 Nova Lite 的针对性微调,我们在降低低置信度实体识别任务方面取得了显著改进:
False Positive Reduction: 微调后的模型能够准确区分高置信度和低置信度场景,有效消除了先前产生误报的不确定检测。
Enhanced Decision Intelligence: 模型学会了在未达到置信度阈值时适当选择”无检测”响应,显著提高了整体检测可靠性。
Operational Impact: 通过大幅降低误报率,系统获得了更好的实用性,并恢复了操作人员对自动化监控能力的信心。
Fine-Tune Job 设置与部署
fine-tuning数据集的质量直接决定模型优化效果。根据 Amazon Bedrock 微调文档要求:
https://docs.aws.amazon.com/nova/latest/userguide/fine-tune-prepare-data-understanding.html
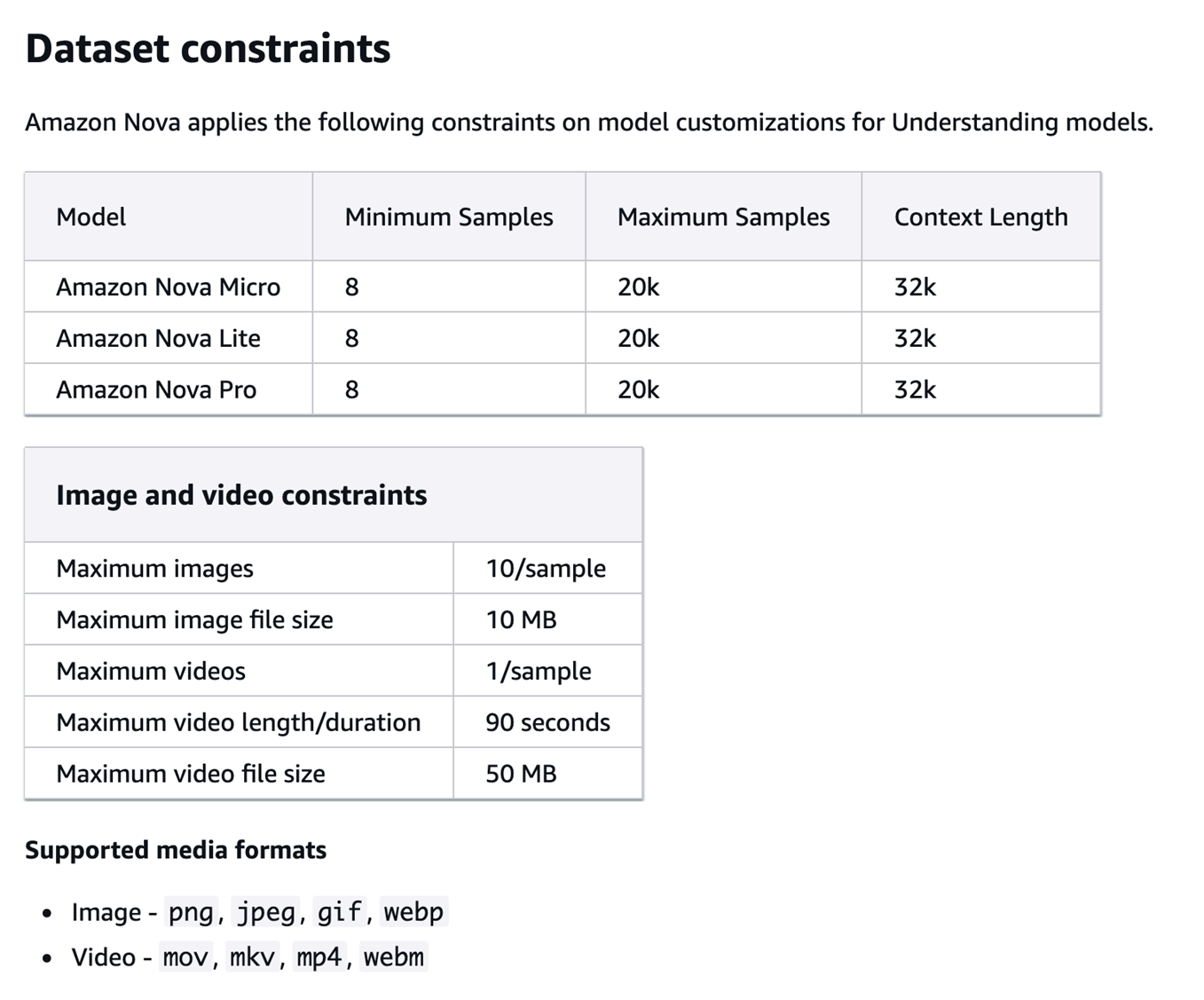 |
考虑到文档中规定的数据量限制,我们采用了 10-50 张图像的小样本微调策略,通过精心设计的数据标注流程确保高质量的训练数据。
数据准备与标注策略
利用 Nova Pro 作为教师模型为训练数据生成高质量标签
该脚本使用与测试场景相同的提示词,确保标注数据与实际应用场景的一致性。
通过上述流程,我们生成了符合 Amazon Bedrock 微调要求的 JSONL 格式标注数据。每个样本的数据结构严格遵循官方规范:
该格式确保了每个训练样本的结构完整性和数据质量可追溯性。
随后,我们将单个图像的 JSONL 文件合并为训练任务所需的统一数据集:
Training Job 创建和配置
基于准备好的 JSONL 数据集,创建一个 Nova Lite 微调训练任务:
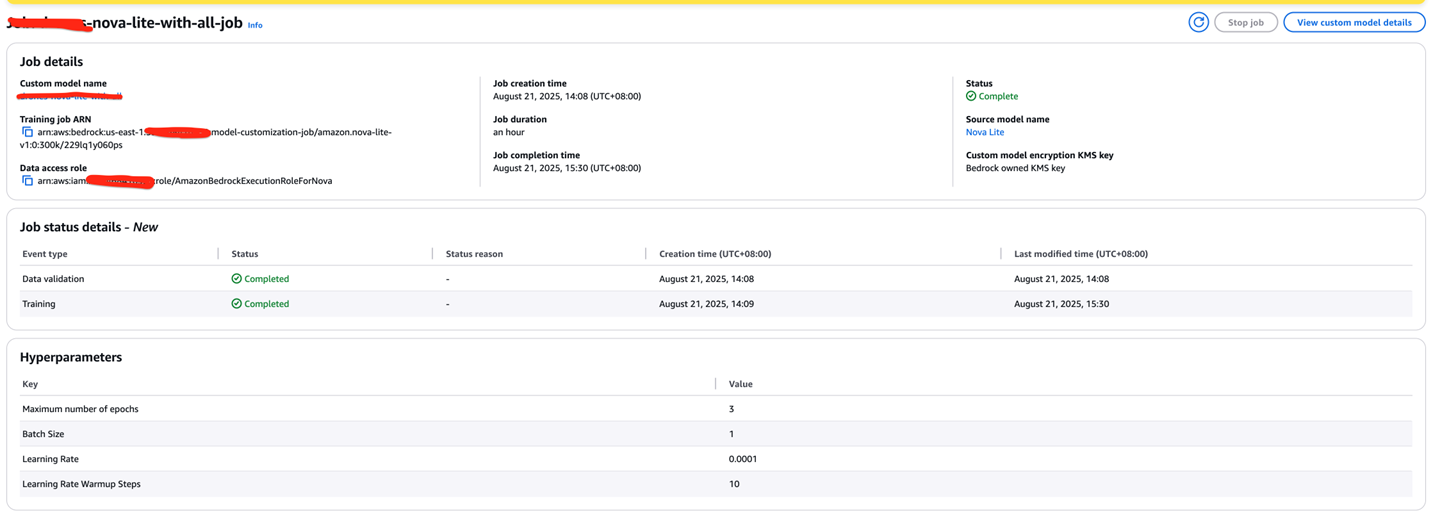
基于 50 张图像的训练数据集,预计训练时间为 90-300 分钟。
Notes:
- 支持基于 Nova Lite 基础模型创建微调任务
- 不支持对已微调的 Nova Lite 模型进行二次微调
Training Parameter Description
 |
After training completion, download training loss data from the job’s designated output directory for analysis and review.
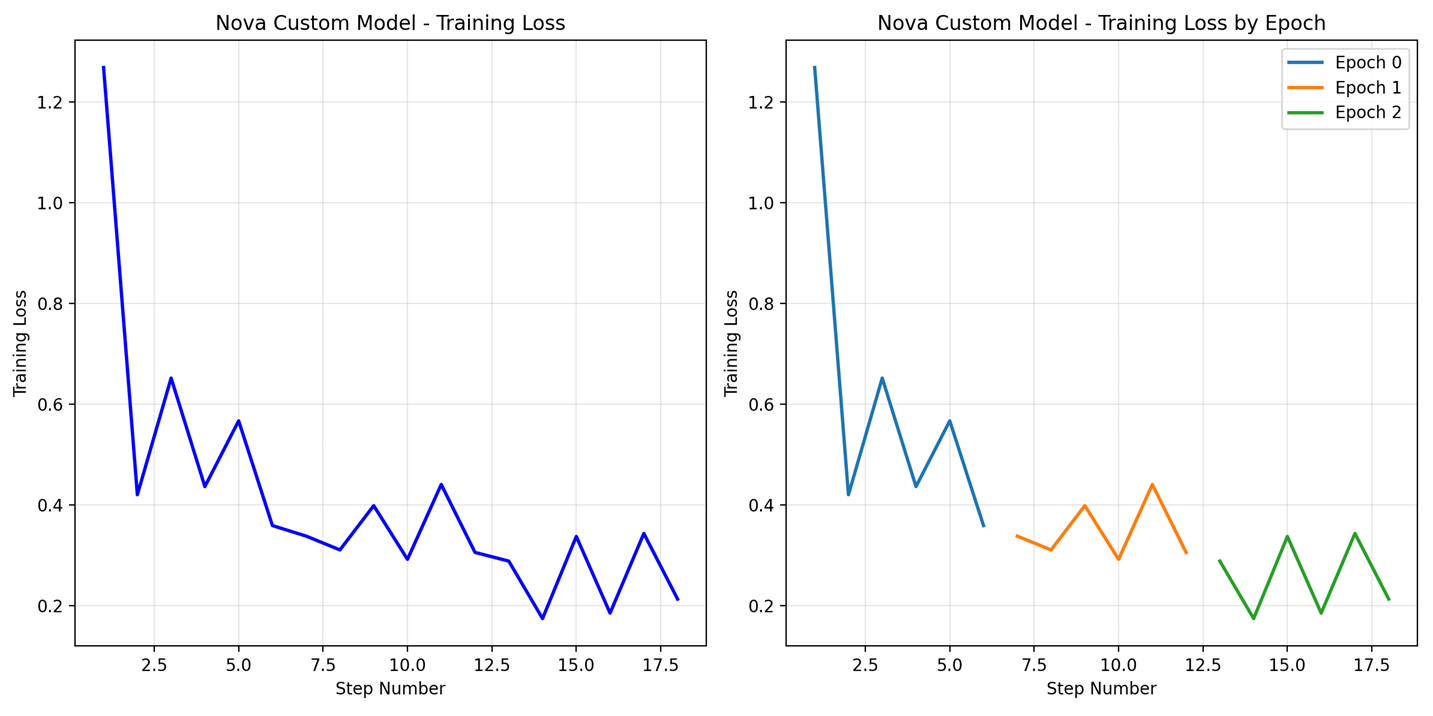 |
Technical Issue Troubleshooting: Image 格式兼容问题
在实施过程中,我们遇到了图像格式兼容性问题:
分析发现,一些标记为 JPEG 格式的图像实际上是 MPO 格式,导致训练失败
MPO (Multi Picture Format):
- JPEG 的扩展格式,用于存储多个相关图像
- 常用于结合左右眼图像的 3D 照片
- 需要专用软件或设备才能正确显示
JPEG (Joint Photographic Experts Group):
部署Fine-Tuned Model
使用按需部署(Deploy for On-Demand)方式进行部署
 |
选择 fine-tuned model 和部署
 |
Notes:
等待部署完成。部署完成后,您可以通过 Playground 进行简单验证或通过 Converse API 调用。预计等待时间约为 10 分钟,也可能需要等待更长时间。
成本分析与经济性
训练成本
- Nova Lite 微调:$0.002/1000 tokens
- 小型数据集(10K tokens):总训练成本约 $0.02
存储与推理
- 固定存储费用:$1.95/月(所有微调模型)
- 推理定价:与基础 Nova Lite 模型相同
Amazon Bedrock Nova 微调提供了卓越的成本效益,能够以最小的财务影响为企业运营带来显著的性能提升。
定价详情: https://aws.amazon.com/bedrock/pricing
参考文档
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
