背景与方案价值
为什么需要监控慢查询
在生产环境中,数据库性能直接影响应用的响应速度和用户体验。慢查询(SlowQuery)是数据库性能问题的主要根源之一,其影响包括:
- 资源消耗:慢查询会长时间占用数据库连接和计算资源,导致其他正常查询排队等待
- 连锁反应:单个慢查询可能引发连接池耗尽,进而影响整个应用的可用性
- 成本增加:为了应对慢查询,往往需要升级数据库实例规格,增加运营成本
无索引慢查询的特殊性
无索引慢查询(NoIndexSlowQuery)是指那些扫描了大量数据行但只返回少量结果的查询,这通常意味着:
- 缺少必要的索引:查询执行了全表扫描或大范围扫描
- 优化潜力巨大:通过添加合适的索引,性能可能提升数十倍甚至上百倍
- 易于识别和修复:相比其他类型的慢查询,无索引问题更容易定位和解决
通过监控 Rows_examined / Rows_sent 比率,我们可以快速识别出这类”高投入低产出”的查询,优先进行优化。
AWS 原生监控的局限性
AWS RDS/Aurora 提供了一些基础的性能监控指标,但存在以下不足:
缺少慢查询计数指标:
- AWS CloudWatch 没有提供开箱即用的慢查询数量指标
- Performance Insights 虽然可以查看慢查询,但无法设置自动化告警
- 需要手动登录控制台查看,无法实现主动监控
无法识别无索引查询:
- AWS 原生指标不提供
Rows_examined 和 Rows_sent 的比率分析
- 无法自动区分哪些慢查询是由于缺少索引导致的
- 缺少针对性的优化指导
告警能力有限:
- 无法基于慢查询数量设置阈值告警
- 无法针对特定类型的慢查询(如无索引查询)单独告警
- 缺少与现有告警系统(如 SNS、飞书)的集成
自定义方案的核心价值
通过自定义实现,我们可以:
- 精确监控:基于 Aurora Slow Log 实时分析每一条慢查询
- 智能分类:自动识别无索引慢查询,提供优化方向
- 灵活告警:支持自定义阈值,集成到现有告警体系
- 成本可控:使用 Lambda + CloudWatch 的 Serverless 架构,按需付费
方案架构与实现思路
整体架构
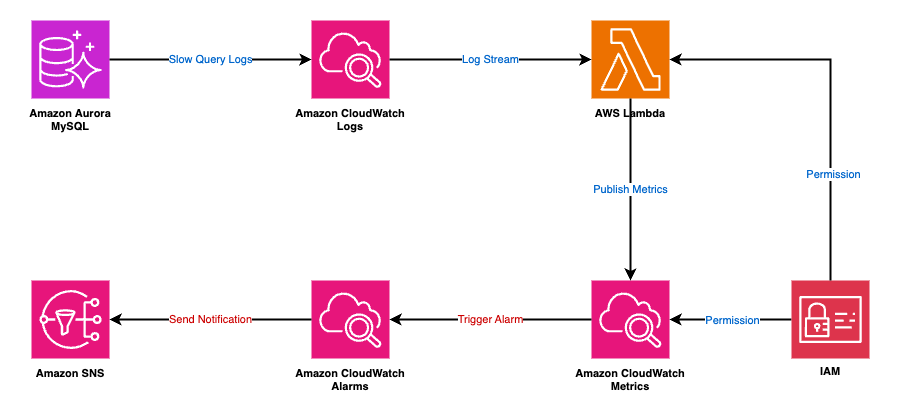
AWS 服务组件图
本方案使用以下 AWS 托管服务构建 Serverless 监控架构:
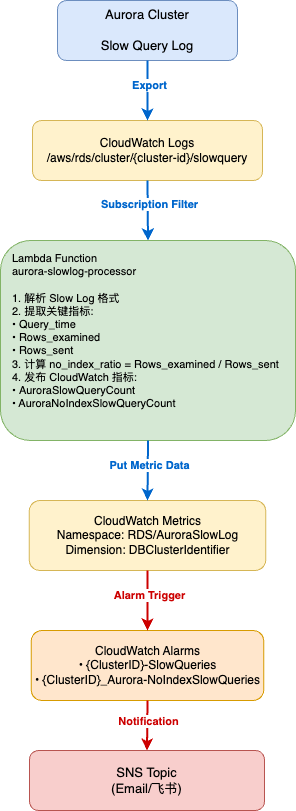
数据流架构图
核心指标与计算方法
慢查询判断
从 Aurora Slow Log 中提取 Query_time 字段,与配置的阈值比较:
# 默认阈值:1.0 秒
SLOW_QUERY_TIME = float(os.environ.get('SLOW_QUERY_TIME', '1.0'))
query_time_match = re.search(r'Query_time:\s+(\d+\.\d+)', message)
if query_time_match:
query_time = float(query_time_match.group(1))
if query_time > SLOW_QUERY_TIME:
slow_query_count += 1
无索引慢查询判断
计算 Rows_examined / Rows_sent 比率,判断是否存在索引缺失:
# 默认阈值:100
NO_INDEX_RATIO = float(os.environ.get('NO_INDEX_RATIO', '100.0'))
rows_examined_match = re.search(r'Rows_examined:\s+(\d+)', message)
rows_sent_match = re.search(r'Rows_sent:\s+(\d+)', message)
if rows_examined_match and rows_sent_match:
rows_examined = int(rows_examined_match.group(1))
rows_sent = int(rows_sent_match.group(1))
if rows_examined > 0 and rows_sent > 0:
no_index_ratio = rows_examined / rows_sent
if no_index_ratio > NO_INDEX_RATIO:
no_index_query_count += 1
比率解读:
- 1-2:优秀 – 索引使用接近最优
- 3-10:良好 – 索引使用合理
- 10-100:需关注 – 可能存在索引问题
- 100+:差 – 很可能缺少或索引无效
CloudWatch 自定义指标
发布两个自定义指标到 CloudWatch:
| 指标名称 |
命名空间 |
维度 |
说明 |
| AuroraSlowQueryCount |
RDS/AuroraSlowLog |
DBClusterIdentifier |
慢查询计数 |
| AuroraNoIndexSlowQueryCount |
RDS/AuroraSlowLog |
DBClusterIdentifier |
无索引慢查询计数 |
cloudwatch.put_metric_data(
Namespace='RDS/AuroraSlowLog',
MetricData=[{
'MetricName': 'AuroraSlowQueryCount',
'Dimensions': [
{'Name': 'DBClusterIdentifier', 'Value': cluster_id}
],
'Value': slow_query_count,
'Unit': 'Count',
'Timestamp': timestamp
}]
)
实现步骤详解
步骤一:启用 Aurora Slow Log 并导出到 CloudWatch
配置数据库参数组
重要说明:项目代码中仅检查这些参数是否已配置,不会自动修改参数组。
需要在 Aurora 集群的参数组中手动启用以下参数:
| 参数名称 |
推荐值 |
说明 |
| slow_query_log |
1 |
启用慢查询日志 |
| long_query_time |
1 |
慢查询阈值(秒),查询时间超过此值会被记录 |
| log_output |
FILE |
输出到文件(必须设置为 FILE 才能导出到 CloudWatch) |
| log_queries_not_using_indexes |
1 |
记录未使用索引的查询 |
| min_examined_row_limit |
0 |
最小扫描行数限制,0 表示记录所有慢查询 |
参数检查逻辑:
def _check_slowlog_config(self, cluster):
"""检查Aurora集群的慢查询日志是否启用并正确配置"""# 初始化默认配置
slowlog_config = {
'slow_query_log': None,
'long_query_time': None,
'log_output': None,
'min_examined_row_limit': None,
'log_queries_not_using_indexes': None
}
# 获取参数组名称
parameter_group_name = cluster.get('DBClusterParameterGroup')
# 从参数组读取当前配置if parameter_group_name:
paginator = self.rds.get_paginator('describe_db_cluster_parameters')
params = {'Parameters': []}
for page in paginator.paginate(DBClusterParameterGroupName=parameter_group_name):
params['Parameters'].extend(page['Parameters'])
for param in params['Parameters']:
if param['ParameterName'] in slowlog_config:
if 'ParameterValue' in param:
slowlog_config[param['ParameterName']] = param['ParameterValue']
return slowlog_config
检查条件:
# 只有当这两个关键参数都已启用时,才会继续配置日志导出if not config_status['slow_query_log'] or not config_status['log_queries_not_using_indexes']:
logger.info(f"Slowlog not configured for cluster {cluster['DBClusterIdentifier']}")
else:
# 继续配置日志导出和 Lambda 订阅
self._configure_slowlog_export(cluster)
启用日志导出
通过代码自动配置日志导出到 CloudWatch Logs:
def _configure_slowlog_export(self, cluster):
"""配置Aurora慢查询日志导出到CloudWatch LogGroup"""
cluster_id = cluster['DBClusterIdentifier']
# 获取当前导出配置
response = self.rds.describe_db_clusters(DBClusterIdentifier=cluster_id)
current_export_types = response['DBClusters'][0].get('EnabledCloudwatchLogsExports', [])
# 添加 slowquery 日志类型if 'slowquery' not in current_export_types:
current_export_types.append('slowquery')
self.rds.modify_db_cluster(
DBClusterIdentifier=cluster_id,
CloudwatchLogsExportConfiguration={
'EnableLogTypes': current_export_types,
'DisableLogTypes': []
},
ApplyImmediately=True
)
logger.info(f"Configured slowlog export for cluster {cluster_id}")
日志将自动导出到:/aws/rds/cluster/{cluster-id}/slowquery
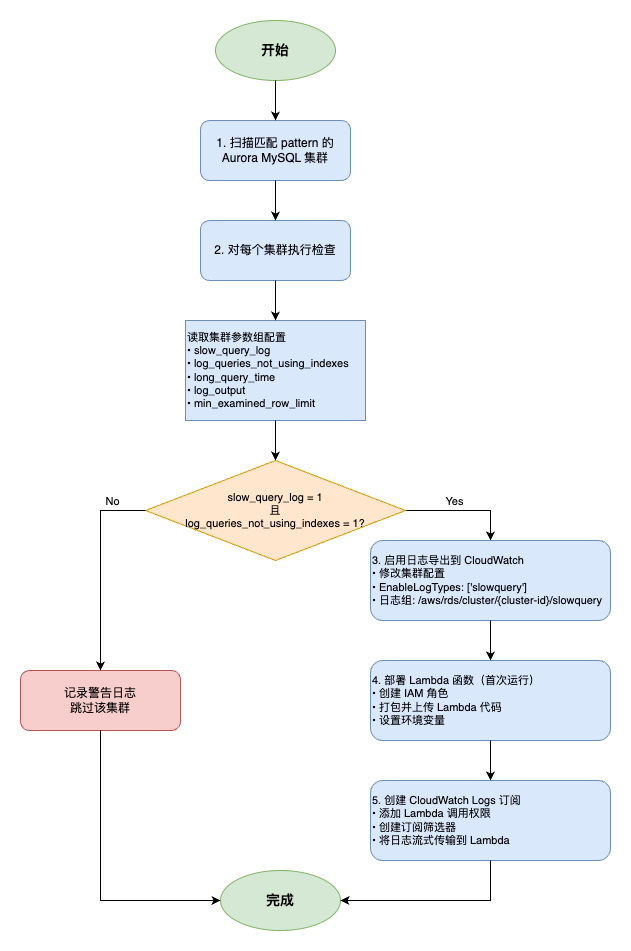
批量配置脚本
脚本功能:db_check_and_open_slowlog.py
这个脚本用于批量检查和配置匹配模式的 Aurora 集群,自动完成日志导出和 Lambda 订阅的设置。
使用方法:
# 语法
python job/check/db_check_and_open_slowlog.py <config_path> <cluster_pattern>
# 示例:为所有以 prod- 开头的集群配置 slowlog
python job/check/db_check_and_open_slowlog.py \
project_name/cloud_name/env_name \
"^prod-.*"# 示例:为特定集群配置
python job/check/db_check_and_open_slowlog.py \
project_name/cloud_name/env_name \
"prod-mysql-cluster-01"
参数说明:
config_path:项目配置路径,用于读取 AWS 认证信息
cluster_pattern:正则表达式,匹配需要配置的集群 ID
脚本执行流程:
重要提示:
- 脚本不会修改参数组:如果检测到参数未启用,脚本只会记录日志并跳过,不会自动修改参数组配置。
- 幂等性:脚本可以重复执行,已配置的资源不会重复创建。
建议操作顺序:
- 先在 AWS 控制台手动配置参数组
- 应用参数组更改(可能需要重启集群)
- 运行此脚本完成自动化配置
- 验证日志是否正常导出到 CloudWatch
完整操作示例:
# 步骤 1:手动配置参数组(在 AWS 控制台或使用 CLI)
aws rds modify-db-cluster-parameter-group \
--db-cluster-parameter-group-name prod-aurora-mysql-params \
--parameters \
"ParameterName=slow_query_log,ParameterValue=1,ApplyMethod=immediate" \
"ParameterName=log_queries_not_using_indexes,ParameterValue=1,ApplyMethod=immediate" \
"ParameterName=long_query_time,ParameterValue=1.0,ApplyMethod=immediate" \
"ParameterName=log_output,ParameterValue=FILE,ApplyMethod=immediate" \
"ParameterName=min_examined_row_limit,ParameterValue=0,ApplyMethod=immediate"# 步骤 2:等待参数生效(或重启集群)# 注意:某些参数可能需要重启集群才能生效# 步骤 3:运行配置脚本
python job/check/db_check_and_open_slowlog.py \
myproject/aws/production \
"^prod-.*"# 步骤 4:验证配置# 查看 CloudWatch Logs 日志组
aws logs describe-log-groups --log-group-name-prefix "/aws/rds/cluster/prod-"# 查看 Lambda 函数
aws lambda get-function --function-name aurora-slowlog-processor
# 查看订阅筛选器
aws logs describe-subscription-filters \
--log-group-name "/aws/rds/cluster/prod-mysql-cluster-01/slowquery"
步骤二:部署 Lambda 函数
Lambda 函数核心逻辑
Lambda 函数负责解析 Slow Log 并发布指标:
def lambda_handler(event, context):
"""处理Aurora慢查询日志并生成CloudWatch指标"""# 1. 解码 CloudWatch Logs 事件
compressed_payload = base64.b64decode(event['awslogs']['data'])
uncompressed_payload = gzip.GzipFile(fileobj=BytesIO(compressed_payload)).read()
payload = json.loads(uncompressed_payload)
# 2. 提取集群ID
log_group = payload['logGroup']
match = re.search(r'/aws/rds/cluster/([^/]+)/slowquery', log_group)
cluster_id = match.group(1)
# 3. 处理每条日志
slow_query_count = 0
no_index_query_count = 0for log_event in payload['logEvents']:
message = log_event.get('message', '')
# 提取查询时间
query_time_match = re.search(r'Query_time:\s+(\d+\.\d+)', message)
if query_time_match:
query_time = float(query_time_match.group(1))
if query_time > SLOW_QUERY_TIME:
slow_query_count += 1# 提取行数指标
rows_examined_match = re.search(r'Rows_examined:\s+(\d+)', message)
rows_sent_match = re.search(r'Rows_sent:\s+(\d+)', message)
if rows_examined_match and rows_sent_match:
rows_examined = int(rows_examined_match.group(1))
rows_sent = int(rows_sent_match.group(1))
if rows_examined > 0 and rows_sent > 0:
no_index_ratio = rows_examined / rows_sent
if no_index_ratio > NO_INDEX_RATIO:
no_index_query_count += 1# 4. 发布指标到 CloudWatchif slow_query_count > 0:
cloudwatch.put_metric_data(
Namespace='RDS/AuroraSlowLog',
MetricData=[{
'MetricName': 'AuroraSlowQueryCount',
'Dimensions': [{'Name': 'DBClusterIdentifier', 'Value': cluster_id}],
'Value': slow_query_count,
'Unit': 'Count'
}]
)
if no_index_query_count > 0:
cloudwatch.put_metric_data(
Namespace='RDS/AuroraSlowLog',
MetricData=[{
'MetricName': 'AuroraNoIndexSlowQueryCount',
'Dimensions': [{'Name': 'DBClusterIdentifier', 'Value': cluster_id}],
'Value': no_index_query_count,
'Unit': 'Count'
}]
)
return {
'statusCode': 200,
'body': f'Processed {slow_query_count} slow queries, {no_index_query_count} no-index queries'
}
创建 Lambda 执行角色
Lambda 需要以下权限:
def create_lambda_role(self, role_name='aurora-slowlog-processor-role'):
"""创建Lambda执行角色"""# 1. 创建角色
assume_role_policy = {
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "lambda.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}
response = self.iam.create_role(
RoleName=role_name,
AssumeRolePolicyDocument=json.dumps(assume_role_policy),
Description="Role for Aurora SlowLog Processor Lambda function"
)
# 2. 附加基础执行策略
self.iam.attach_role_policy(
RoleName=role_name,
PolicyArn="arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
)
# 3. 创建自定义策略 - 允许写入 CloudWatch 指标
policy_document = {
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": ["cloudwatch:PutMetricData"],
"Resource": "*"
}]
}
policy_response = self.iam.create_policy(
PolicyName=f"{role_name}-cloudwatch-policy",
PolicyDocument=json.dumps(policy_document)
)
self.iam.attach_role_policy(
RoleName=role_name,
PolicyArn=policy_response['Policy']['Arn']
)
return response['Role']['Arn']
部署 Lambda 函数
def create_or_update_lambda(self, function_name='aurora-slowlog-processor',
role_arn=None, zip_content=None):
"""创建或更新Lambda函数"""# 环境变量配置
environment_variables = {
'Variables': {
'SLOW_QUERY_TIME': '1.0', # 慢查询阈值(秒)'NO_INDEX_RATIO': '100.0' # 无索引比率阈值
}
}
try:
# 检查函数是否存在
self.lambda_client.get_function(FunctionName=function_name)
# 更新现有函数
self.lambda_client.update_function_code(
FunctionName=function_name,
ZipFile=zip_content,
Publish=False
)
self.lambda_client.update_function_configuration(
FunctionName=function_name,
Environment=environment_variables
)
except self.lambda_client.exceptions.ResourceNotFoundException:
# 创建新函数
response = self.lambda_client.create_function(
FunctionName=function_name,
Runtime='python3.9',
Role=role_arn,
Handler='lambda_function.lambda_handler',
Code={'ZipFile': zip_content},
Description='Aurora SlowLog Processor',
Timeout=60,
MemorySize=128,
Publish=True,
Environment=environment_variables
)
return response['FunctionArn']
步骤三:创建 CloudWatch Logs 订阅
添加 Lambda 调用权限
首先需要授权 CloudWatch Logs 调用 Lambda:
def add_lambda_permission(self, lambda_arn, function_name):
"""添加Lambda权限,允许CloudWatch Logs调用函数"""
account_id = self._get_account_id()
region = self.region
self.lambda_client.add_permission(
FunctionName=function_name,
StatementId='AllowCloudWatchLogsRDS',
Action='lambda:InvokeFunction',
Principal='logs.amazonaws.com',
SourceArn=f"arn:aws:logs:{region}:{account_id}:*"
)
logger.info(f"Added CloudWatch Logs permission for Lambda: {function_name}")
创建订阅筛选器
将 Slow Log 流式传输到 Lambda:
def create_log_subscription(self, cluster, lambda_arn):
"""为Aurora集群的慢查询日志组创建订阅筛选器"""
cluster_id = cluster['DBClusterIdentifier']
log_group_name = f"/aws/rds/cluster/{cluster_id}/slowquery"
filter_name = "AuroraSlowLogProcessor"# 检查日志组是否存在
log_groups = self.cloudwatch.describe_log_groups(
logGroupNamePrefix=log_group_name
)
if not any(lg['logGroupName'] == log_group_name
for lg in log_groups.get('logGroups', [])):
# 创建日志组
self.cloudwatch.create_log_group(logGroupName=log_group_name)
logger.info(f"Created log group: {log_group_name}")
# 检查订阅筛选器是否已存在
existing_filters = self.cloudwatch.describe_subscription_filters(
logGroupName=log_group_name,
filterNamePrefix=filter_name
)
if not existing_filters.get('subscriptionFilters'):
# 创建订阅筛选器
self.cloudwatch.put_subscription_filter(
logGroupName=log_group_name,
filterName=filter_name,
filterPattern='', # 处理所有日志事件
destinationArn=lambda_arn
)
logger.info(f"Created subscription filter for: {log_group_name}")
步骤四:配置 CloudWatch 告警
创建慢查询告警
def _create_slow_queries_alarm(self, cluster_info, alarm_topic, threshold, period=60):
"""为数据库集群创建慢查询告警"""
cluster_id = cluster_info['DBClusterIdentifier']
self.cloudwatch.put_metric_alarm(
AlarmName=f"{cluster_id}-SlowQueries",
AlarmDescription=f"Slow queries rate for cluster {cluster_id} exceeds {threshold} queries per second",
ActionsEnabled=True,
AlarmActions=[alarm_topic],
OKActions=[alarm_topic],
EvaluationPeriods=3, # 连续3个周期
DatapointsToAlarm=3, # 3个数据点都超过阈值
Threshold=threshold,
ComparisonOperator='GreaterThanThreshold',
MetricName='AuroraSlowQueryCount',
Namespace='RDS/AuroraSlowLog',
Statistic='Sum',
Period=period,
Dimensions=[
{'Name': 'DBClusterIdentifier', 'Value': cluster_id}
],
TreatMissingData="ignore"
)
logger.info(f"Created slow queries alarm for cluster: {cluster_id}")
创建无索引慢查询告警
def _create_no_index_slow_queries_alarm(self, aurora_info, sns_topic_arn,
threshold, period=60):
"""创建Aurora无索引慢查询数量告警"""
cluster_id = aurora_info['DBClusterIdentifier']
self.cloudwatch.put_metric_alarm(
AlarmName=f"{cluster_id}_Aurora-NoIndexSlowQueries",
AlarmDescription=f"当Aurora集群 {cluster_id} 的无索引慢查询数量连续3个周期超过{threshold}个时触发告警",
ActionsEnabled=True,
AlarmActions=[sns_topic_arn],
OKActions=[sns_topic_arn],
EvaluationPeriods=3,
DatapointsToAlarm=3,
Threshold=threshold,
ComparisonOperator="GreaterThanThreshold",
MetricName='AuroraNoIndexSlowQueryCount',
Namespace='RDS/AuroraSlowLog',
Statistic='Sum',
Period=period,
Dimensions=[
{'Name': 'DBClusterIdentifier', 'Value': cluster_id}
],
TreatMissingData="ignore"
)
logger.info(f"Created no-index slow queries alarm for cluster: {cluster_id}")
批量创建告警
使用脚本批量为多个集群创建告警:
# 创建慢查询告警# 参数:配置路径、集群匹配模式、阈值、SNS Topic ARN
python job/monitor/db/db_NoIndexSlowQuery.py \
project_name/cloud_name/env_name \
"^prod-.*" \
10 \
--alarm_topic arn:aws:sns:us-east-1:123456789012:db-alerts
步骤五:验证和测试
查看 CloudWatch 指标
# 查看慢查询指标
aws cloudwatch get-metric-statistics \
--namespace "RDS/AuroraSlowLog" \
--metric-name "AuroraSlowQueryCount" \
--dimensions Name=DBClusterIdentifier,Value=<cluster-id> \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%S) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%S) \
--period 60 \
--statistics Sum
# 查看无索引慢查询指标
aws cloudwatch get-metric-statistics \
--namespace "RDS/AuroraSlowLog" \
--metric-name "AuroraNoIndexSlowQueryCount" \
--dimensions Name=DBClusterIdentifier,Value=<cluster-id> \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%S) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%S) \
--period 60 \
--statistics Sum
查看 Lambda 执行日志
# 查看 Lambda 函数日志
aws logs tail /aws/lambda/aurora-slowlog-processor --follow
测试告警
可以通过执行一些慢查询来触发告警:
-- 执行一个慢查询(全表扫描)SELECT * FROM large_table WHERE non_indexed_column = 'value';
-- 等待几分钟后检查 CloudWatch 告警状态
总结
本方案通过 CloudWatch Logs + Lambda + CloudWatch Metrics/Alarms 的 Serverless 架构,实现了对 Aurora 慢查询的精准监控和智能分析。相比 AWS 原生监控能力,具有以下显著优势:
- 更精准:基于实际 Slow Log 分析,而非采样数据
- 更智能:自动识别无索引查询,提供优化方向
- 更灵活:支持自定义阈值和告警策略
- 更经济:Serverless 架构,按需付费,成本可控
- 更易用:提供批量配置脚本,一键部署多集群
通过实施这套监控方案,能够:
- 及时发现数据库性能问题
- 快速定位需要优化的查询
- 持续改进数据库性能
- 降低成本避免不必要的实例升级
希望这套方案能够帮助团队更好地管理 Aurora 数据库性能,提升应用的整体响应速度和用户体验。
Lambda 函数:lib/aws/alarm/lambda/aurora_slowlog_processor/lambda_function.py
告警管理器:lib/aws/alarm/db_alarm.py
Slow Log 管理器:lib/aws/alarm/db_slowlog.py
配置脚本:scripts/check/db_check_and_open_slowlog.py
告警创建脚本:scripts/monitor/db/db_NoIndexSlowQuery.py
参考资料
AWS Aurora Slow Query Log
CloudWatch Logs Subscription Filters
CloudWatch Custom Metrics
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |