亚马逊AWS官方博客
使用Amazon Nova模型实现自动化视频高光剪辑
本方案旨在利用Amazon自研的Nova多模态理解类模型(Vision‑Language Model,简称VLM)和多模态嵌入模型(Multimodal Embedding Model,简称MME),实现自动化的视频高光识别与剪辑。输入视频文件,通过多模态模型理解或结合语义摘要与嵌入检索实现素材定位,识别高光片段,并合成剪辑。
 |
方案概览:
| 方案 | 概述 |
|---|---|
| 纯 VLM | 使用视觉-语言模型(VLM)直接对完整视频进行理解,输出高光片段的开始和结束时间点。 |
| VLM + MME(视频嵌入/ 降低成本版:视频抽帧图片嵌入) | 首先用 VLM/LLM生成视频摘要或高光描述;将视频切片生成视频嵌入表示;然后将描述文本与视频嵌入匹配,定位高光片段。 |
文章概览:
- 模型介绍:Nova 多模态理解类模型(VLM)及多模态嵌入模型(MME)
- 视频高光剪辑的主要方法:
- 纯VLM: 用Nova LLM直接进行视频理解,输出高光片段的开始和结束时间点
- 方案架构与案例代码
- Nova理解类模型输出视频精准时间戳(timestamp)的提示词工程技巧
- 效果优化:通过切片增加识别精准度
- VLM+MME(video):结合语义摘要与视频嵌入检索
- 方案架构与案例代码(2.1 基础:高光压缩; 2.2 跨视频内容驱动的高光剪辑; 2.3 历史素材驱动的模板化高光生成)
- 成本与效果优化思路:片段聚类,初筛,去重
- 降本方案:2.4 VLM+MME(image): 视频抽帧,结合语义摘要与抽帧嵌入检索
- 附加考虑:背景音乐,转场动画,字幕及其他效果自动化
- 总结与讨论:实际应用场景,方案特点和选型思路
- 可用性与定价
模型介绍
Amazon Web Services(AWS)推出的 Amazon Nova 自研模型系列,是一组基础模型(foundation models),覆盖文本、图像、视频、语音和智能代理等多模态输入与输出,旨在为企业构建生成式 AI 应用提供性能优越、成本更低、可定制性更强的选择。现已在 Amazon Bedrock 上提供。更多模型全系列信息:https://aws.amazon.com/nova/
 |
本方案涉及两类Nova模型:理解类模型和多模态嵌入模型。
理解类模型(Nova LLM)
Amazon Nova Lite 和 Amazon Nova Pro 是 Amazon Nova理解类模型系列(Nova Micro/Lite/Pro/Premier)中两款高性价,低延迟的多模态模型,支持文本、图像、视频等多种格式,并输出文本响应。
Nova Lite:定位为 “极低成本” 的多模态理解模型,能够以极快的响应速度处理图像、视频和文本输入,生成文本输出。
Nova Pro:在精度、速度与成本之间取得平衡,是面向广泛任务的高能力多模态理解模型。
二者均支持 200 多种语言,并且可通过 Amazon Bedrock 进行定制、微调、结合检索增强生成(RAG)等,适合企业级应用。
在本文方案中,我们将使用Nova LLM的视频理解能力,输入视频,通过提示词工程,获得高光片段时间点的输出。
多模态嵌入模型(Nova MME)
Amazon Nova 多模态嵌入模型(Amazon Nova Multimodal Embeddings)是一款最先进的多模态嵌入模型,支持文本、文档、图像、视频和音频的统一嵌入模型,可实现高精度的跨模态检索。模型细节与使用方法可阅读博客。
在本文方案中,我们将使用Nova MME的视频嵌入生成能力,通过语义相似度检索片段嵌入,以此定位高光片段。
高光剪辑方案
1. 纯VLM:多模态模型识别高光
该方案作为视频高光剪辑的基础方案,主要使用Nova 理解类模型(如 Nova Lite/Pro等版本),利用其视觉–语言模型(VLM,Vision-Language Model)能力直接对视频输入进行理解,通过其内部的视觉编码、时序建模与语言理解能力,输出高光片段的“开始时间点”和“结束时间点”。
a. 方案架构与案例代码
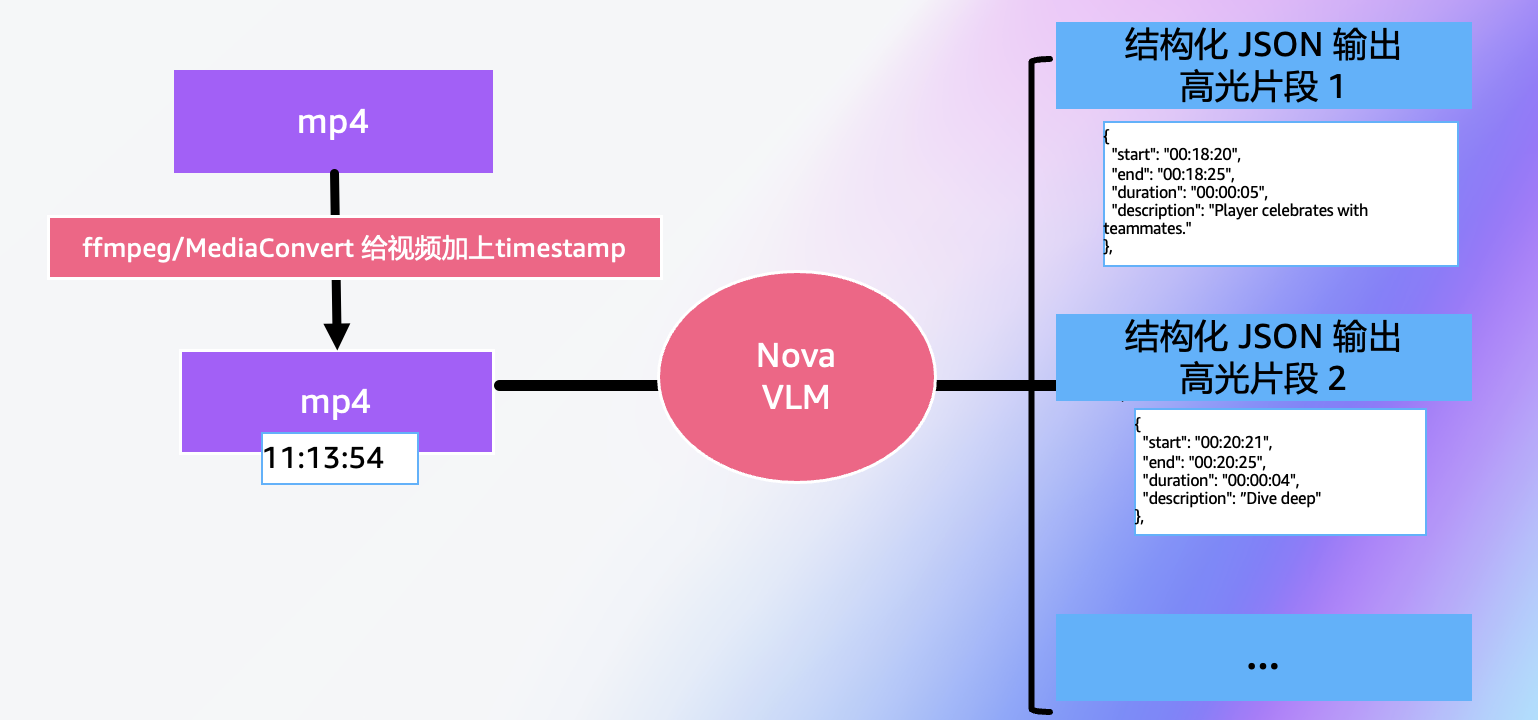
纯VLM方案的核心思路是:直接让Nova模型读取整个视频,理解其内容后输出高光片段的时间戳(开始时间和结束时间),然后使用FFmpeg等工具按时间戳切分并拼接视频 。
 |
应用案例1:足球比赛高光提取
以一段1分钟的足球比赛视频(视频来源)为例,我们使用Nova Lite模型自动识别进球等精彩时刻。原始视频包含完整的比赛片段,其中穿插了多个进球瞬间、精彩扑救和关键传球。通过纯VLM方案,模型能够自动定位这些高光时刻并生成浓缩版视频。
下图展示了处理前后的对比效果。左侧为原始1分钟视频,包含了大量的中场传球和跑位等常规画面;右侧为自动生成的高光视频,精准保留了4个进球瞬间,总时长压缩至约25秒,压缩比达到60%。有效提取了视频中最具观赏价值的片段。
 |
 |
1min 原始视频 25s 高光视频
识别准确度评估
为了量化评估模型的表现,我们使用IoU (Intersection over Union) 指标将模型输出与人工标注的Ground Truth进行对比。IoU衡量预测片段与真实片段的重叠程度,当IoU > 0.5时视为成功匹配。测试结果如下 :
| Ground Truth片段 | 模型识别片段 | IoU | 匹配状态 |
| 02-09秒(Team 1 开场进球) | 04-09秒(Team 1 通过快速反击打入首球,进球者热烈庆祝) | 0.71 | 匹配 |
| 20-27秒(Team 2 扳平比分) | 20-27秒(Team 2 扳平比分,一名红衣球员带球突破防守队员后将球送入网窝,Team 2 球员疯狂庆祝) | 1 | 完美匹配 |
| 30-36秒(Team 2 反超进球) | 30-38秒(Team 2 反超比分,另一名红衣前锋得分,张开双臂庆祝,队友纷纷冲过来加入庆祝) | 0.75 | 匹配 |
| 53-57秒(Team 1 扳平进球) | 53-58秒(Team 1 再次扳平,通过定位球得分,球员们在角旗附近拥抱庆祝这一迟来的逆转) | 0.8 | 匹配 |
从效果来看,模型实现了100%的召回率,不仅准确识别了所有进球时刻,还自动过滤掉了中场传球、球员跑位等非高光内容。生成的高光视频节奏紧凑,适合在社交媒体上快速分享,这正是自动化高光剪辑的核心价值所在。
核心代码实现
应用案例2:小狗动画高光提取
为了验证纯VLM方案在不同视频类型上的泛化能力,我们进一步测试了一段1分钟的动画视频。这段视频的特点是大部分时间画面相对静态——一只橙色的小狗在蓝色大门前休息,而真正的高光时刻集中在三个动态片段:一只黄色的小狗出现捡球、另一只小狗从门内探出、以及黄色小狗追逐球的场景。下图展示了处理效果。左侧为原始60秒视频,右侧为自动生成的17秒高光视频。模型成功识别了所有三个动态时刻,并准确过滤掉了长时间的静态画面 。
 |
 |
1min 原始视频 17s 高光视频
识别准确度评估
为了量化评估模型的表现,我们同样使用IoU 指标将模型输出与人工标注的Ground Truth进行对比,测试结果如下:
| Ground Truth片段 | 模型识别片段 | IoU | 匹配状态 |
| 16-24秒(秋田犬捡球) | 16-23秒(一个蓝色的球滚入场景,一只黄色狗跑过来追逐着球。) | 0.88 | 匹配 |
| 26-32秒(小狗开门) | 26-32秒(一只小的白色和棕色相间的狗从蓝色门中出现,站在熟睡的橙色狗旁边,然后又消失回门内。) | 1 | 完美匹配 |
| 46-52秒(秋田犬追球) | 46-50秒(一只黄色的狗精力充沛地从右向左跑过院子,跑过了休息中的橙色狗。) | 0.67 | 匹配 |
可以观察到,模型成功识别了所有3个真实高光片段,并且所有时间戳均准确且在有效范围内。特别值得注意的是,第二个片段(小狗开门)实现了完美匹配,说明模型对这类明确的动作转折点有很强的识别能力。即使在第一和第三个片段中存在1-2秒的时间偏差,时间重叠率仍然达到0.67-0.88的高水平,这对于实际应用已经完全足够。
综上,对比足球比赛和动画视频两个案例,我们可以看到纯VLM方案展现出良好的跨场景泛化能力,无论是真实拍摄的体育赛事,还是制作精良的动画内容,Nova Lite都能准确理解视频语义,识别出符合”动作精彩、戏剧性强、叙事价值高”等标准的高光时刻。这种泛化能力使得同一套技术方案可以应用于多种业务场景,从体育直播、游戏录像到教育视频、产品演示等,大幅降低了开发和维护成本。
b. 使用Nova理解类模型输出视频精准timestamp的提示词工程技巧
在将Amazon Nova模型应用于视频高光提取时,我们面临的核心挑战是如何让模型准确输出结构化的时间戳数据。基于对Nova Lite的系统性测试,发现模型在视频时间定位任务中的表现高度依赖于prompt的设计策略,基于大量测试经验和视频理解任务的标准prompt模板,可以总结出以下关键技巧:
采用分步骤的任务分解策略。参考视频密集描述(Dense Captioning)任务的prompt设计,将复杂的时间戳提取任务分解为清晰的步骤序列,引导模型建立系统化的分析流程:
这种结构化指引帮助模型建立”观察→定位→验证→输出”的工作流程,显著减少时间戳错误。
针对特定任务定制分析维度。参考视频标注(Video Tagging)任务的prompt设计,在高光提取时应明确定义分析的多个维度,帮助模型全面理解什么是”高光”:
明确定义输出格式并提供具体示例。在视频检索(Video Retrieval)和时间定位任务中,标准做法是明确指定时间戳的格式要求。我们建议同时提供格式说明和具体示例,对于需要更结构化的场景,使用JSON格式:
强调时间边界约束以防止幻觉。测试表明,模型在长视频中容易产生超出实际时长的时间戳。必须在prompt中明确视频的实际时长:
通过系统性地应用这些提示词工程技巧,我们能够显著提升Nova模型在视频时间戳识别任务中的表现。在实际应用中,我们还建议结合代码层面的后处理机制——例如验证时间戳是否在有效范围内、合并时间上相邻的片段等,这种通过结合prompt设计+工程化验证的组合策略能够构建更稳健的生产系统。
除了提示词优化,对于长视频场景,我们还可以从架构层面进一步提升处理效果,接下来我们将详细介绍这一优化方案。
c. 效果优化:通过切片增加识别精准度
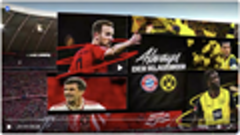
在实际生产环境测试中,我们发现对于长视频场景,采用视频切片策略能够显著提升时间戳定位精度和高光识别准确率。该策略的核心思路是将长视频按固定时长切分成多个片段,对每个片段独立调用Nova模型进行并行分析,然后将识别结果映射回原视频的绝对时间轴。这种方法不仅显著提升了时间戳精度,还带来了意外的性能收益——通过并行处理多个片段,整体处理时间反而缩短了。
应用案例3:长视频足球比赛高光提取
以一段9分3秒的足球比赛视频为例(视频来源),我们将其切分为18个30秒片段和1个3秒片段,通过Amazon Nova Lite模型并行处理后,自动生成了包含所有进球时刻的高光视频。下图展示了原始视频与自动生成的高光视频对比:
 |
切片策略处理流程图
 |
 |
9m3s 原视频 1m58s 高光视频
效果验证
为量化评估切片策略的效果,我们使用人工标注的Ground Truth进行对比测试。结果显示,切片策略在时间戳精度和召回率两个关键指标上均有显著提升:30秒切片策略成功识别了全部4个进球(召回率100%),时间戳精度提升至±1秒以内。
| 进球事件 | Ground Truth | 原始策略 (未切分) 结果 | 优化策略 (30秒切分)结果 | 评价 |
| #1 Team 1 进球 (0:1) | 197-204秒 | 190-200s (匹配,时间范围接近) | 195-208s (匹配,时间更精确) | 优化: 都能匹配,切分策略的时间覆盖更准确 |
| #2 Team 2 进球 (1:1) | 297-303秒 | 290-300s (匹配,时间范围接近) | 300-305s (匹配,时间更精确) | 优化: 都能匹配,切分策略的时间覆盖更准确 |
| #3 Team 2 进球 (2:1) | 338-342秒 | 未检测到 (漏检) | 334-344s (匹配) | 优化: 成功检测到,召回率提升 |
| #4 Team 1 进球 (2:2) | 373-383秒 | 470-480s (时间错误) | 372-382s (匹配) | 优化: 成功检测并精确定位,纠正了原始策略的时间错误的不足 |
切片策略的另一个优势是通过并行处理提升了整体处理效率。需要注意的是,虽然召回率得到了显著提升,但由于每个片段独立分析,可能会产生较多冗余标记(本案例中输出了14个候选片段),建议在后处理阶段增加去重及筛选逻辑以优化最终输出。
总体而言,纯VLM方案的优势在于流程简洁、模块精简、实现路径短,非常适合快速原型开发和中短视频场景。然而,当面对超长视频,这一方案对模型能力和提示词工程的要求会显著提升。此外,对于需要从海量视频素材库中全局筛选最佳片段的场景,纯VLM方案难以提供跨视频的语义检索能力。
在接下来的章节中,我们将介绍:当VLM对高光片段的提取不是那么精准时,通过引入多模态嵌入模型(MME)在语义空间上进行相似度匹配,不仅能提升系统的容错能力,弥补VLM在精准性方面的部分不足,同时也提供了跨视频片段检索定位的可能性,实现更强大的视频高光剪辑能力。
2. VLM+MME:语义摘要+嵌入检索
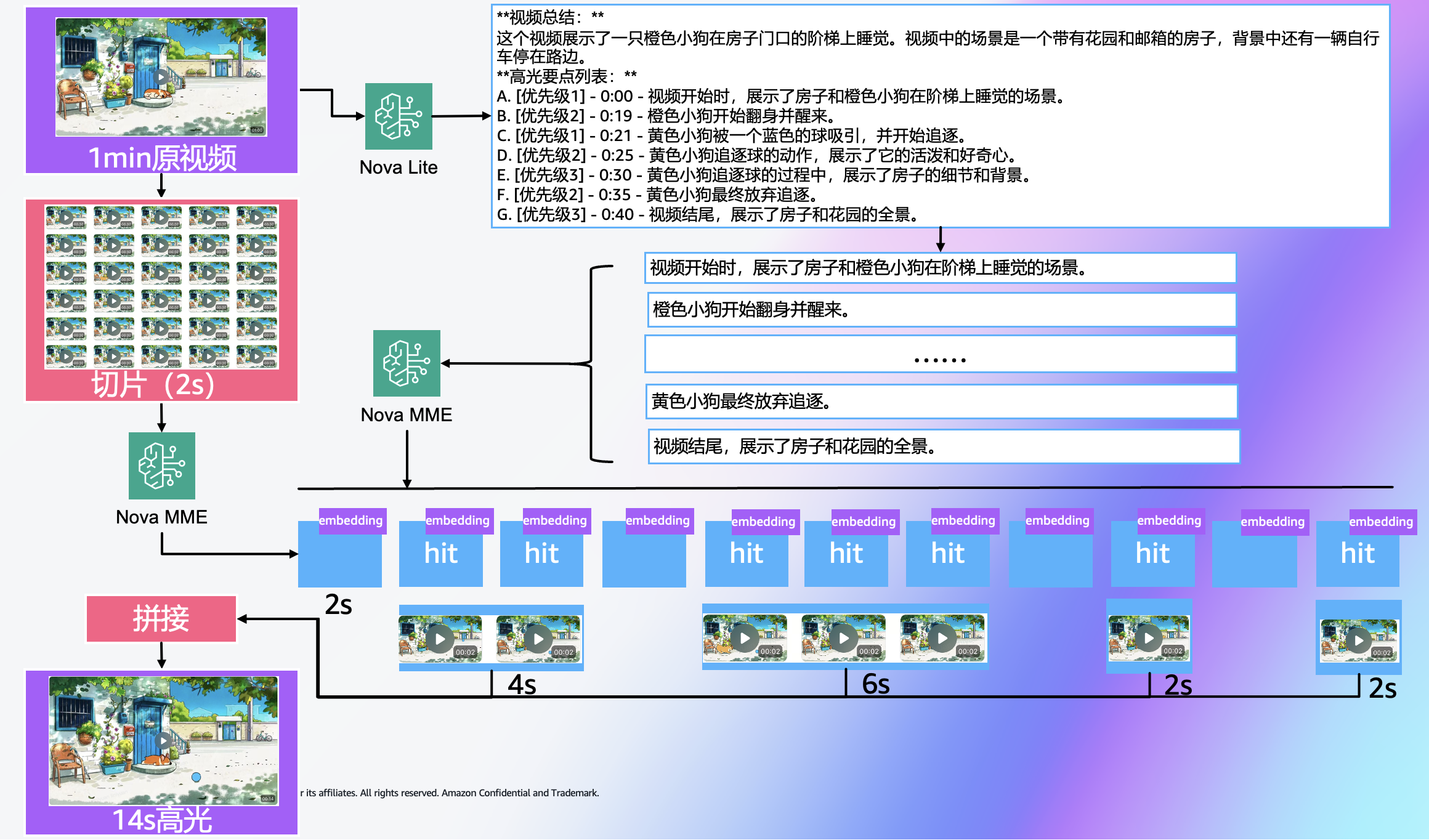
该方案结合了两类技术:首先由 VLM(Nova理解类模型,如Nova Lite/Pro)对视频整体进行理解,生成高光要点或描述;其次,将视频切片(如每2-3秒一段,具体切片时长根据业务要求和检索颗粒度决定)生成视频嵌入向量(通过多模态嵌入模型,Nova MME)——每个片段取得视觉/时序特征之后形成向量。然后系统将高光描述(文本)作为查询,与视频片段的嵌入向量进行相似度匹配,从而精确定位那些“语义上与高光描述最接近”的片段。
 |
a. 方案架构
该方案的需要视频切片、嵌入生成与匹配机制, 可用于跨视频的剪辑需求。基于嵌入向量的可复用性,提供从冷启动(2.1, 2.2)到基于素材累积(2.3)的方案进阶路径。如果成本敏感可以考虑(2.4)将视频抽帧,用图片向量检索。
2.1 基本方案:高光压缩
在不强调原始视频情节顺序的情况下,我们可以采用一种高光压缩的方法,将视频内容提炼为精华片段。具体步骤如下:
- 视频内容总结:将视频输入到VLM模型(例如AWS的 Nova Lite/Pro 模型),生成对视频主要内容的摘要描述,并以要点(bullet points)的形式呈现。这一步让模型从全局上理解视频内容的重点。(也可以与方法1. 纯VLM( 用Nova VLM直接进行视频理解,输出高光片段的开始和结束时间点)方法结合,对VLM生成的高光点查漏补缺。)
- (可选)打重要性标签:每条摘要要点可以附加一个优先级标签(如重要程度1、2、3)以表示相对重要性(这一步需要在 system prompt 中明确高光片段的判定标准)。
- 视频切片与嵌入:将视频按时间顺序分割成短片段,如2-3秒(具体切片时长根据业务要求和检索颗粒度决定),并对每个片段生成向量嵌入表示(使用Nova MME,多模态嵌入模型,每个片段的嵌入向量都代表了该片段的语义内容)。
- 语义匹配选取高光片段:利用第一步中VLM生成的摘要要点作为查询,根据语义相似度在嵌入向量空间中检索最相关的影片片段。换言之,我们在嵌入向量库中查找与每条摘要要点语义最接近的若干片段。这些匹配上的片段即被视为视频的高光片段集合。由于摘要要点概括了视频的重要内容,检索出的片段也就对应了视频中最精彩或最重要的瞬间。
- (可选)初筛:如高光描述过多,可以根据高光点的优先级筛选需要匹配的文字。
- (可选)去重:若出现多个要点匹配到同一段视频(即某片段对多条要点都有高相似度),则根据要点的优先级决定该片段应归属哪个要点(确保重要的要点获得独特片段)
- 高光片段导出:将选定的高光片段按原视频中的时间顺序组合导出,形成一个压缩版的视频。如果不关注片段顺序,也可以按照相似度得分等权重来自由组合。但通常由于摘要要点源自原始视频顺序,此方法下导出的高光片段天然保持了原视频的大致顺序。
该基本方案不依赖任何外部素材库,流程简单直接。VLM提供语义摘要,嵌入向量提供精确检索,使模型能够“理解”视频内容并找到对应片段。此方法依赖第一步VLM的摘要质量和提示词工程,若VLM未能抓住真正的精彩之处,检索结果可能欠佳。
案例代码
使用Amazon Nova Lite进行视频理解与高光要点生成,Amazon Nova MME进行文本和视频片段的嵌入生成,开源音视频处理库FFmpeg进行视频处理,该流程的核心代码架构如下:
应用案例:小狗动画高光提取
 |
 |
1min 原始视频 14s 高光视频
该动画的大部分时间是一只橙色小狗在蓝色大门前睡觉,有3个主要的高光片段:
- 第16s到第24s:一只黄色小狗出现在画面中捡球
- 第26s到第32s:一只小的白色和棕色相间的小狗从门内探出
- 第46s到第52s:黄色小狗继续出现在画面中追逐球
按照架构设计进行第1步,将整个视频作为输入,使用VLM进行视频分析,提取高光要点以及优先级:
VLM 提取的高光要点包含7条,每条有对应优先级与描述,可以观察到视频的大部分高光情节被提取出且故事较为连贯。在语义匹配阶段,Nova MME进行多模态嵌入生成,能够捕捉到视频片段中的核心动作和场景特征,而不完全依赖于具体的身份识别。例如,当VLM描述中提到”黄色小狗追逐球”时,无论执行这个动作的是橙色小狗还是黄色小狗,由于”追逐球”这一动作在嵌入空间中产生相似的语义表示,相似度计算都能够匹配到包含此类动作的视频片段,从而实现准确的语义关联。这种语义层面的匹配机制使得系统具有一定的容错能力:即使文本描述在细节上存在偏差,只要核心的动作、场景或情感特征保持一致,相似度计算仍能找到正确的视频片段,保证了语义上的连贯性。最后拼接时根据视频片段的时间顺序拼接保证了时序上的连贯性。
接下来进行第2~4步的视频片段切分(2s为切分间隔),Nova MME嵌入生成以及语义匹配,每个要点匹配的视频片段结果如下表所示:
| 选中片段 | 时间范围 | 相似度 | 匹配的高光要点 |
| clip_0010_20s.mp4 | 20-22s | 0.192 | 黄色小狗追逐球的动作,展示了它的活泼和好奇心。 |
| clip_0011_22s.mp4 | 22-24s | 0.241 | 黄色小狗被一个蓝色的球吸引,并开始追逐。 |
| clip_0013_26s.mp4 | 26-28s | 0.26 | 视频开始时,展示了房子和橙色小狗在阶梯上睡觉的场景。 |
| clip_0014_28s.mp4 | 28-30s | 0.202 | 黄色小狗追逐球的过程中,展示了房子的细节和背景。 |
| clip_0015_30s.mp4 | 30-32s | 0.193 | 橙色小狗开始翻身并醒来。 |
| clip_0025_50s.mp4 | 50-52s | 0.204 | 黄色小狗最终放弃追逐。 |
| clip_0029_58s.mp4 | 58-60s | 0.14 | 视频结尾,展示了房子和花园的全景。 |
从实际结果看,尽管VLM在狗的品种识别上存在混淆,但最终选中的片段(20-24秒、26-32秒、50-52秒等)仍然准确覆盖了预期的高光时段,证明了这种基于语义匹配的方法在处理描述不精确问题上的鲁棒性。生成的高光视频中包含了提到的3个高光片段,且片段之间的衔接也较为自然。
2.2 跨视频内容驱动的高光剪辑
当高光剪辑场景有较高的自定义剧本需求,需要微调视频拼接顺序,以及需要基于大量视频媒体库优选片段的时候,我们可以对2.1方案生成的嵌入基于用户定义的剧本文字(可选:再用prompt增强)进行检索。
比如在媒体行业场景中,当剪辑需求不仅仅是“提取高光”,而是要按照品牌或用户定义的“剧本”来迈出叙事、结构和风格的步伐,并且拥有一个庞大的素材库时,我们便可以采用“用户输入的剪辑需求 + 跨视频检索”这一技术路径。具体来说,用户首先输入其剪辑意图,例如“先展示产品问世、再展示用户体验、最后展示品牌口号”,这一剧本会被系统转化为一系列描述性事件(如“产品亮相”、“用户微笑试用”、“品牌Logo出现”)。接着系统对整个素材库中的每条视频或片段生成嵌入向量,进而将用户的每一个事件描述作为检索查询,与库中各片段的嵌入进行相似度匹配。这样,系统不仅限于从单个视频选取高光,而是可以跨视频检索:比如,事件1可能匹配竟然是品牌拍摄片,事件2可能匹配直播片段,事件3来自宣传片。最后,按照用户剧本设定的顺序,将这些匹配出的来自不同视频的片段组合起来,形成一个结构化、连贯而富有品牌风格的高光剪辑。
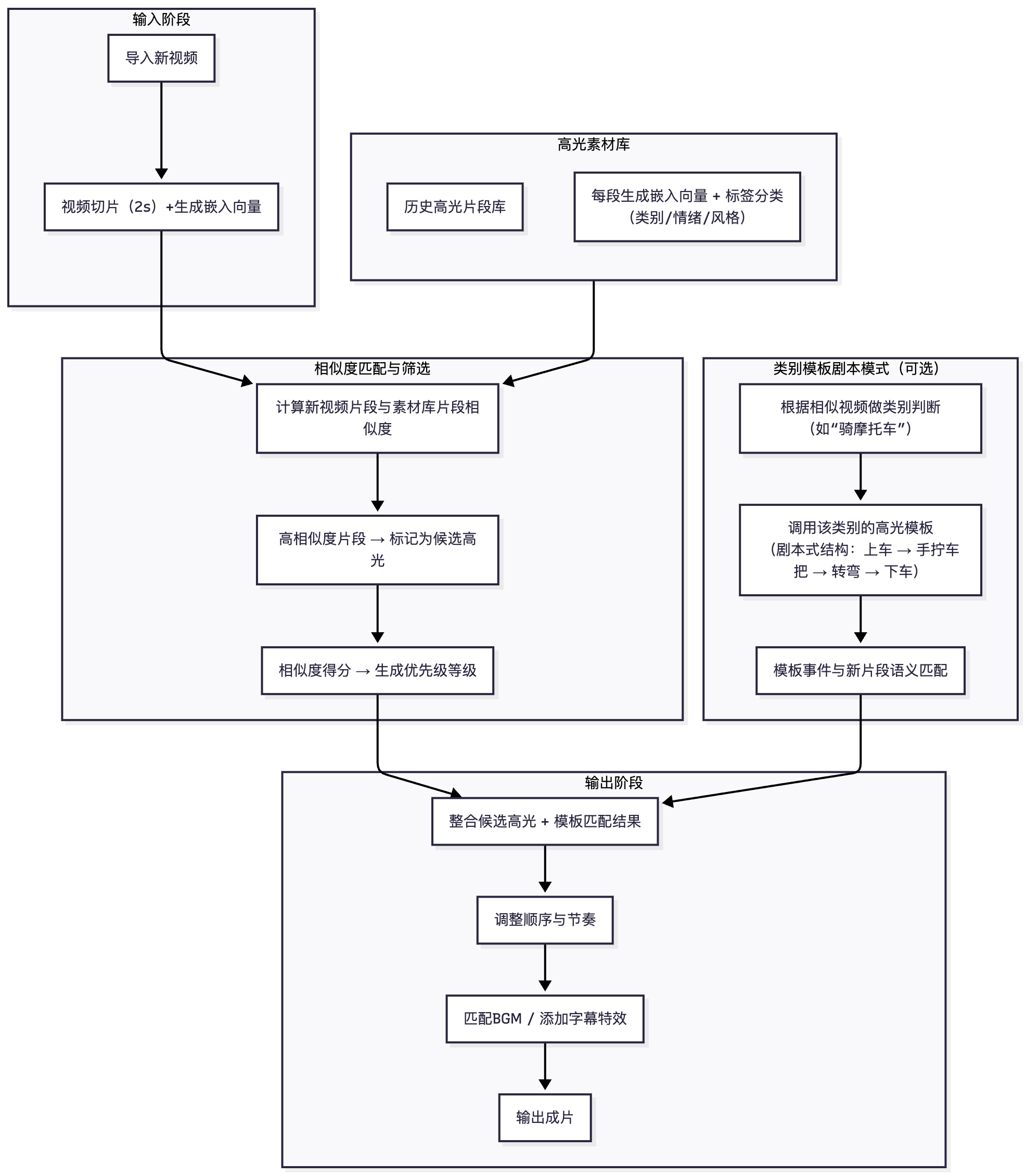
2.3 历史素材驱动的模板化高光生成
视频嵌入技术展现了极高的可复用性。我们可以将历史上已经被剪辑为高光的片段——或被人工判断为“精彩时刻”的素材——系统地收集起来,形成一个样本库。样本库搭建可选择如AWS Opensearch Service(博客),AWS的partner向量数据库如Zilliz(partner marketplace link)。
对于库中每一个高光片段,我们不仅为其生成嵌入向量表示,还可按类别或风格进行标签(例如 “体育比赛”“游戏直播”“演讲访谈” 等),并为片段附加丰富的元数据,如所属视频类别、片段简介、精彩评分等。这一机制使得后续的新视频可以跨视频检索:在面对一条新拍摄视频时,系统首先对其进行分析(包括 VLM 摘要或粗分类),然后将其切分为2–3 秒的片段并生成嵌入向量。接下来,这些片段将与样本库中已有的高光嵌入进行相似度匹配——如果某个新视频片段在视觉或语义上与历史高光片段高度相似,就可将其标记为高光候选。同时,如果新视频所属类别明确(比如篮球比赛),系统还可参考该类别过去形成的“高光剧本”——例如典型进球、扣篮、关键三分、绝杀这一顺序——并在样本库选片中优先匹配这些典型事件。将匹配出的片段(可能来自不同原视频)按剧本顺序组合拼接,就能生成符合观众预期节奏、结构连贯的高光成片。
以下为流程图:
 |
b. VLM+MME链路优化思路
在系统设计阶段,成本考量非常重要。如不需要为视频 embedding 支付持久化存储费用,仅需要考虑模型推理费用(即 Nova 或嵌入模型 MME 的运行费用)。如需储备历史素材库——需要存储 embedding,因此还要考虑存储和检索成本。除了存储外,还有一些成本优化手段,可以在整个流程中降低计算/存储/带宽等资源消耗。以下是几项建议:
视频压缩 + 再识别
可以先将原始视频做轻量压缩或降帧处理(降低分辨率、降低帧率)以减少计算/存储开销。利用压缩后的视频用VLM识别哪些片段可能是高光,然后在原始视频中按照排序结果选取对应高分片段,再拼接成最终剪辑。这样可以避免对高分辨率视频VLM理解/MME嵌入。
初筛过滤 + 再嵌入
在做精细的嵌入匹配之前,先做一个粗筛阶段以减少待处理片段数量,从而降低后续嵌入计算量。粗筛可通过几种方式实现:
- 靠 VLM 输出大致 timestamp:结合方法1,调用 VLM 先对视频做快速分析,输出可能的高光时间段(例如“00:12–00:16”、“04:30–04:35”),然后只对这些候选区段做切片 + 嵌入匹配。提升方法1的精度,同时无需对全部视频做嵌入处理。
- 靠去重:如果视频存在大量“平淡”“重复”的片段,可以先用帧差异规则做去重,删除重复内容,剩余片段即为“亮点候选”:如帧之间变化率、场景切换检测、视觉差异阈值做快速过滤,仅保留“变化大”的区段供后续处理。
- 靠前置逻辑:利用其他模态(如音频、运动检测)做预筛。比如音频音量变大、频率变化剧烈可能对应“高潮、高光”片段(如赛车轰鸣、演唱高潮);或视觉中检测到快速运动/剪辑变化也可作为候选。这样可减少对视觉嵌入的遍历。
这种“粗 → 精”两级筛选方式能显著降低整体系统负载。
效果优化思路
切片粒度与高光时长弹性
实际场景中,高光时长并不固定(可能为 3 秒/5 秒/15 秒等),因此在切片设计时需要灵活。一个简明工程实现方式是:
先用最小细粒度切片(例如 1-2 秒)遍历全视频。对于每个高光描述(来自 VLM),在匹配出的片段基础上,可合并相邻切片、或者根据优先级扩展时间段,以形成较长的高光片段。匹配逻辑可为:对于某一高光描述,找到所有相似度 ≥ 阈值(例如 0.5) 的细切片集合;然后合并这些相邻切片(时间上连续或相近)为一个完整高光区间,再按时间顺序拼接。
这样既保证了系统能够灵活应对不同长度的高光,又避免硬编码“高光必为3 秒”的限制。
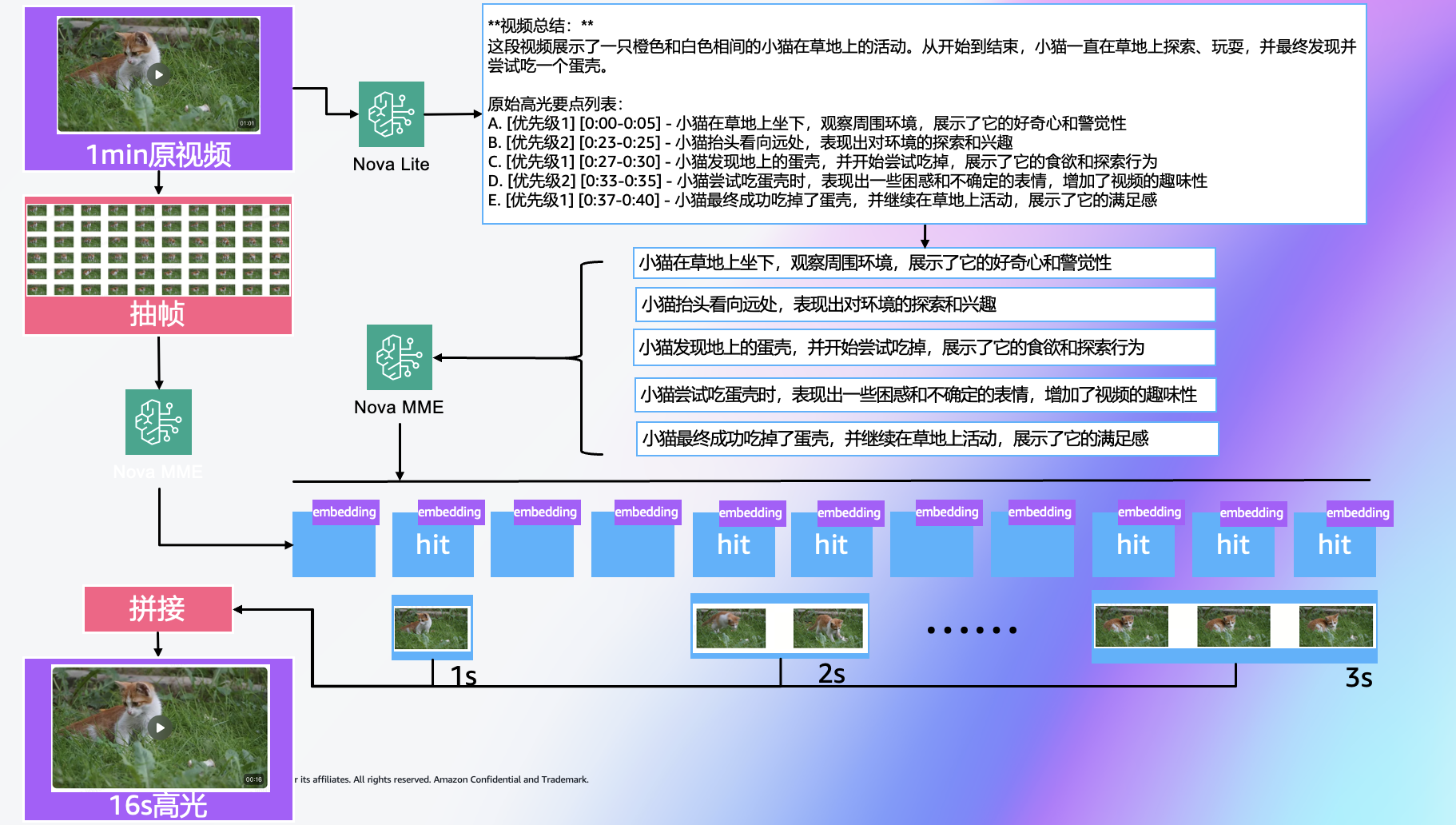
2.4 VLM+MME(视频抽帧-图片嵌入)
此方案与方案 2 的流程类似,但区别在于“嵌入对象”从视频片段变为“抽帧图片”。也就是说:对视频抽取关键帧,对这些静态帧生成图片嵌入;同时由 VLM 生成高光描述文本;然后对图片嵌入与描述文本做匹配,从这些匹配结果推断高光的时间点。技术上这种方法降低了对完整视频切片和时序建模的依赖,使实现更轻量。
 |
案例代码:
应用案例:小猫草地玩耍高光提取
 |
 |
1min 原始视频 16s 高光视频
该视频的大部分时间是小猫在草地上张望,主要高光片段为:
- 在第21s到第28s:小猫有向前扑的动作
- 第37s到第43s:小猫回到原位坐下回头看向镜头
和2.1 基本方案类似,进行第1步将整个视频作为输入,使用VLM进行视频分析,提取高光要点以及优先级:
接下来进行的2~4步的处理,以1s为间隔对视频进行抽帧,对高光要点与抽帧后的图片进行嵌入生成与语义匹配,最后根据抽帧间隔与帧起始时间合并连续片段。最终提取出9个连续的高光片段(总时长16秒)如下表所示:
| 片段序号 | 时间范围 | 时长 | 相似度 | 匹配要点 | 优先级 |
| 1 | 4.0s-5.0s | 1.0s | 0.274 | A. 小猫在草地上坐下,观察周围环境,展示了它的好奇心和警觉性 | 1 |
| 2 | 7.0s-9.0s | 2.0s | 0.278-0.280 | A. 小猫在草地上坐下,观察周围环境,展示了它的好奇心和警觉性 | 1 |
| 3 | 23.0s-24.0s | 1.0s | 0.167 | B. 小猫抬头看向远处,表现出对环境的探索和兴趣 | 2 |
| 4 | 25.0s-28.0s | 3.0s | 0.240-0.250 | C. 小猫发现地上的蛋壳,并开始尝试吃掉,展示了它的食欲和探索行为 | 1 |
| 5 | 29.0s-30.0s | 1.0s | 0.247 | E. 小猫最终成功吃掉了蛋壳,并继续在草地上活动,展示了它的满足感 | 1 |
| 6 | 31.0s-32.0s | 1.0s | 0.164 | B. 小猫抬头看向远处,表现出对环境的探索和兴趣 | 2 |
| 7 | 40.0s-41.0s | 1.0s | 0.175-0.259 | C/E. 小猫发现蛋壳并尝试吃掉/成功吃掉蛋壳并继续活动 | 1/2 |
| 8 | 43.0s-46.0s | 3.0s | 0.214-0.257 | D/E. 小猫尝试吃蛋壳时表现困惑/成功吃掉蛋壳并继续活动 | 1/2 |
| 9 | 48.0s-51.0s | 3.0s | 0.273-0.276 | A. 小猫在草地上坐下,观察周围环境,展示了它的好奇心和警觉性 | 1 |
从结果上看,高光视频短片包含了原视频中2个主要高光瞬间(扑抓动作和看向镜头),同时也整合了VLM分析中关于小猫“靠近、玩弄/咬住蛋壳”的高优先级动作片段(对应片段4、5、7、8),跳过了较长的静态张望部分同时保持了一定的动作连贯性。
总结:该方案优点是资源消耗更低、实现速度更快;但缺点在于抽帧可能丢失动作延续或动态效果,因此定位精度可能略逊于方案 2,适合快速试验或成本/资源受限的场景。
附加考虑:BGM,转场动画,字幕及其他自动化
背景音乐匹配:高光剪辑常配以恰当的背景音乐(BGM)增强观赏性。我们可以利用上述文本描述和嵌入技术来自动挑选BGM。例如,将高光片段的文字描述(来自VLM总结的高光要点)输入音乐库的嵌入查询,寻找语义上契合的音乐片段。音乐库中每首背景音乐可事先标注情绪、风格或含有描述文本,按需检索。举例来说,如果高光描述提到“激动人心的绝杀时刻”,系统可能选择一首节奏紧凑、激昂的配乐与之对应。
视觉转场和特效:生成剪辑时还可考虑自动添加一些转场效果或字幕说明。例如,在片段衔接处插入快速淡入淡出或动感转场,以增强流畅度(这里可以用大模型基于提示词直接生成剪辑剧本和转场动画标签);增加字幕: 字幕可用各方案第一阶段的VLM输出的描述增加到对应的高光片段上,或进一步用LLM优化,在对应片段下方叠加字幕或标题,提示观众这个片段精彩之处(例如“最后三秒绝杀进球!”)。
迭代优化:在实际应用中,可以根据用户反馈或观看数据,不断优化高光选择规则和效果处理。例如统计哪些自动生成的高光片段留存率高,哪种BGM搭配更受欢迎,反过来调整VLM的提示词和相似度匹配的阈值,形成反馈循环,逐步提高高光剪辑的质量。
总结与讨论:应用场景,方案特点和选型思路
综上所述,本方案提出了一套利用AI进行视频高光剪辑的思路:从基本的纯大语言模型识别高光节点,到语义摘要+嵌入检索实现跨素材的检索和剪辑,并提供了随着素材积累逐步提升的思路。
VLM 直接识别 vs 嵌入模型检索:
随着模型规模与多模态预训练技术的发展,现代 VLM (比如本文案例中使用的Nova理解类模型)擅长同时处理视觉内容、语义信息与时序结构。它们能够从整段视频中快速提取“哪些时刻是高光”“这些高光的起止时间在哪里”,因为它们在训练阶段已学习到“动作/事件 → 关键帧”与“视觉+语言语义”之间的对应关系。在现实剪辑任务中,如果视频结构相对简单、动作明显、视觉变化突出,VLM 直接识别的路径可能几乎一步到位:模型读取视频,识别出“高光动作”或“精彩节点”,并直接标出时间戳。在这种场景下,少了切片、分割、索引、匹配等环节,流程更短、响应更快。
那么为什么我们在解决方案里引入嵌入模型?其价值主要体现在以下几个方面:第一,在素材库规模大、跨视频检索需求高的场景,嵌入模型使你能够为每个视频片段或帧生成可索引的向量,从而构建“素材库可复用+检索加速”的结构。通过这种方式,无论未来你要处理多少条视频或多少次剪辑任务,都可以依赖已生成的向量库进行高效检索,而不是每次都让 VLM 全面扫描。第二,对于高度定制化剪辑需求(如品牌剧本、风格统一、跨视频片段拼接)来说,嵌入模型提供了更强的“匹配”能力:你可以用描述或事件提示作为查询,在向量空间中查找与之最相似的片段,再组合成成片。这种方法更适用于“从大量素材中选”“按照用户剧本拼接”这类复杂任务。
为方便产品或技术团队快速决策,下面是选型建议:
| 方案 | 简要描述 | 特点 | 选择策略/适用场景 |
|---|---|---|---|
| 纯 VLM | 使用视觉-语言模型(VLM)直接对完整视频进行理解,输出高光片段的开始和结束时间点。 | 流程最简;依赖模型对时序与视觉理解的能力强;实现快速。 | 视频较短、结构简单、无需跨视频、资源有限、希望快速上线。(如视频长也可以分段处理) |
| VLM + MME(视频嵌入/ 降低成本版:视频抽帧图片嵌入) | 首先用 VLM/LLM生成视频摘要或高光描述;将视频切片生成视频嵌入表示;然后将描述文本与视频嵌入匹配,定位高光片段。 | 语义理解+嵌入检索结合;全局检索,可控性较强。 | 视频长度中等或偏长、跨视频检索,希望复用嵌入,定制化需求高 |
自动高光剪辑技术方案可用于制造业如相机云存剪辑, 媒资场景如明星高光,电视剧摘要等。在未来,我们期待这种自动化高光剪辑能够大幅减少人工剪辑耗时,实现“一键生成精彩瞬间”,为内容创作者和观众带来更高效的体验,为AWS客户产品带来创新和效益。
可用性与定价
Amazon Nova理解类模型和多模态嵌入模型现已在Amazon Bedrock上线,可用区域包括美国东部(弗吉尼亚北部)的亚马逊云科技区域。如需详细定价信息,请参阅Amazon Bedrock定价页面(Amazon Bedrock pricing page)。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。