1.前言
在亚马逊云科技2020的re:Invent大会上,发布了在云上构建自动驾驶数据湖的参考架构(点击 这里 下载源文件),结合国内的实际业务场景,我们做了一些针对性的细化和调整,修改为如下的参考架构(以MDF4/Rosbag格式数据为参考)。
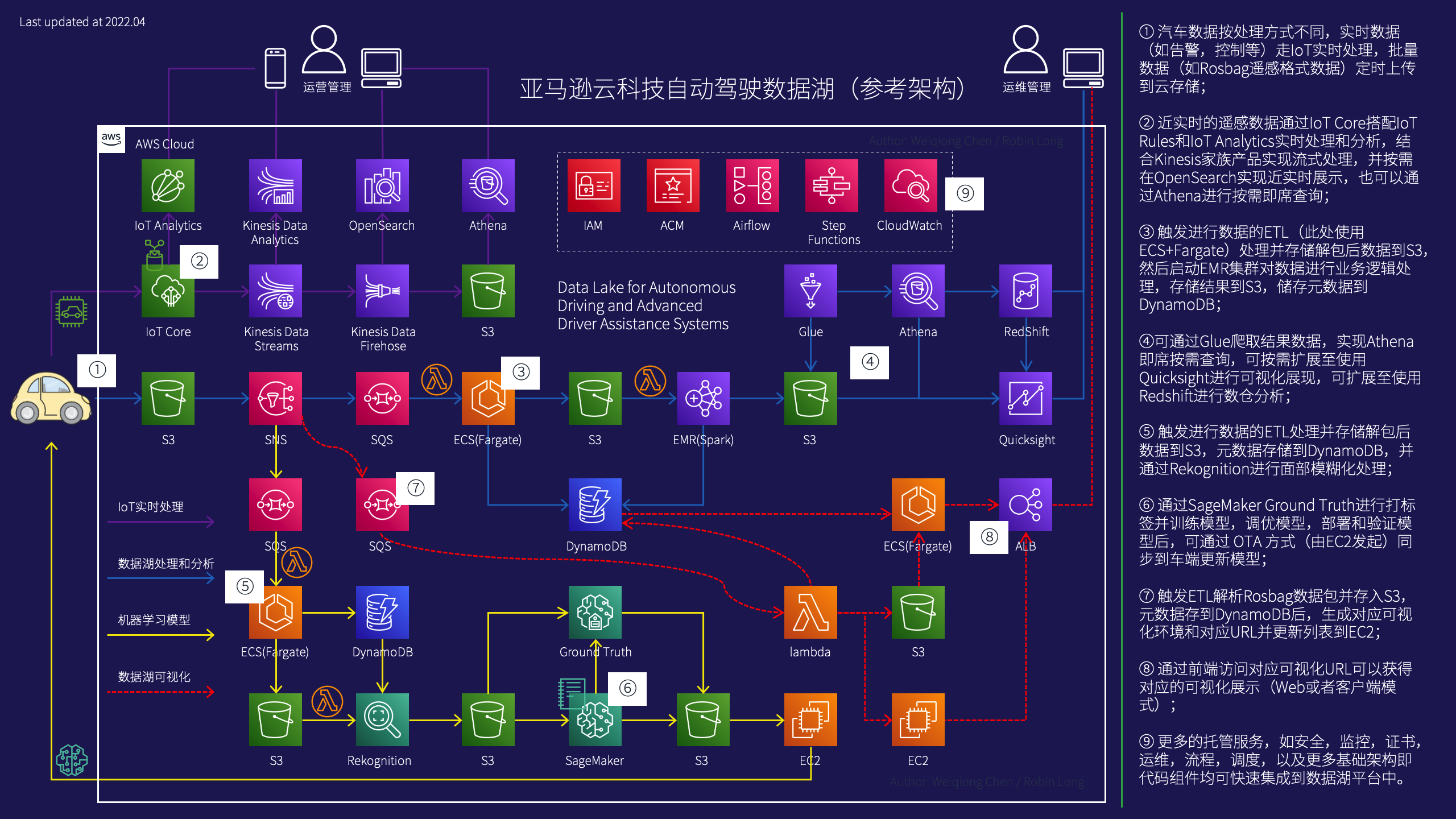
因为Rosbag数据文件里面包含了例如图片,音视频,雷达,GPS等内容,需要通过解析并识别出来例如带时间戳的图片数据,pcd点云数据等,解析和拆开了对应数据以后就可以进行对应的数据分析,机器学习等环节处理。
因此我们把上图中的自动驾驶数据湖参考架构拆分成一个系列的四篇博客(此处暂时未包括左上角的IoT相关部分),方便用户和读者理解和使用对应的解决方案,这是本系列博客的第二部分:图像处理和模型训练(基于上图的1-5-6步骤实现)。
在本篇博客中,更加细化的图像处理和模型训练的具体步骤和代码,可以参考如下图所示的参考步骤:

说明:此架构图来自参考文档2里面的步骤架构,我们未做修改。
接下来的博客内容详细代码和步骤参考上图的架构:
a)当我们把Rosbag文件放到S3以后(模拟汽车文件上传)后,会触发一个SQS消息并放入队列里面;
b)后端有一个Lambda函数会被SQS消息触发,然后调用ECS(基于Fargate)对Rosbag数据进行解析(此处使用SQS有个好处就是万一执行失败,SQS消息还在,可以被重复消费,执行Lambda);
c)数据解析出来后存储dest的数据桶,并触发消息到另外的SQS(png格式数据)和Lambda函数(json格式数据数据);
d)上面的SQS会触发一个新的Lambda对png图片数据进行处理(通过调用Rekognition),识别对应的数据(识别结果存入DynamoDB);
e)上面的Lambda(和SQS同期那个)会根据json数据内容调用Rekognition直接进行识别,不需要自定义模型和标注就可以识别这四种:“Bicycle”,“Motorcycle”,“Motorbike”,“Bike”;
f)这些都处理完毕后(数据会全部存回S3),此时可以通过SageMaker里面的笔记本,结合如Ground Truth对图片进行自动标注,训练模型,部署模型和验证等操作。
2.环境准备
我们使用的源代码位于 https://github.com/auto-bwcx-me/ (如果对亚马逊云科技的相关服务特别熟悉,也可以直接使用 官方的GitHub Repo)。
环境说明:
a)我们的操作环境为Cloud9,所有非控制台的操作都基于它完成;
b)因为是博客,为了突出自动驾驶数据湖相关的内容,我们直接给这个Cloud9配置了Administrator的权限,未遵循安全最佳实践里面的最小权限原则,大家在生产环境的时候要注意,尽量遵循最小权限分配的原则;
c)如果没有特别说明,我们的操作区域为新加坡区域;
d)如果没有特别说明,我们执行脚本的操作目录为代码目录。
注意:如果做过别的实验(如自动驾驶数据湖(一):场景检测),有留存的Cloud9,可以继续使用,各项关于Cloud9的详细配置可以有选择的确认后跳过。
2.1准备Cloud9
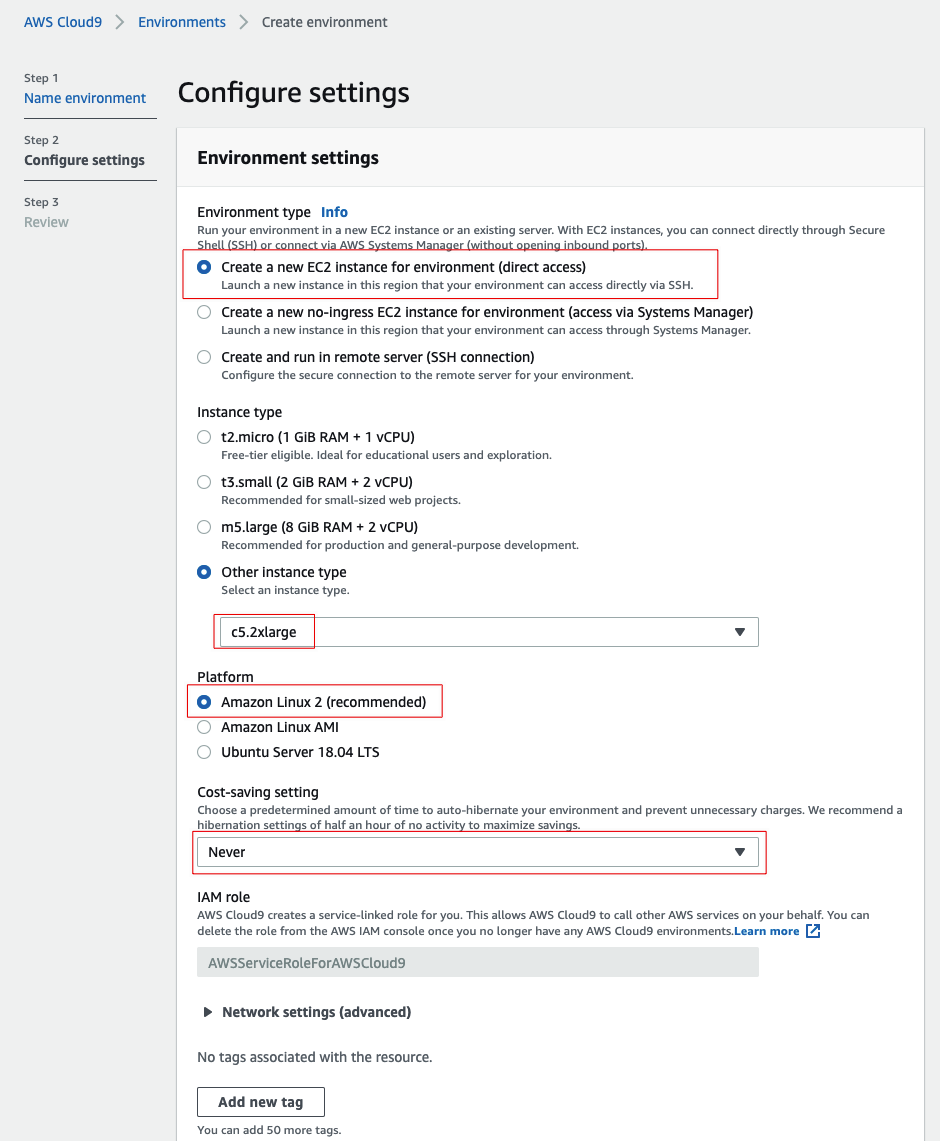
因为我们要在Cloud9里面编译更新Python3.9,所以部署Cloud9实例的时候可以选一个C系列的机型(如c5.2xlarge),这样编译速度会快很多,其他全部默认即可(注意部署到对应的区域,如新加坡区域即可)
创建一个Cloud9环境,取个名字,如“auto2”
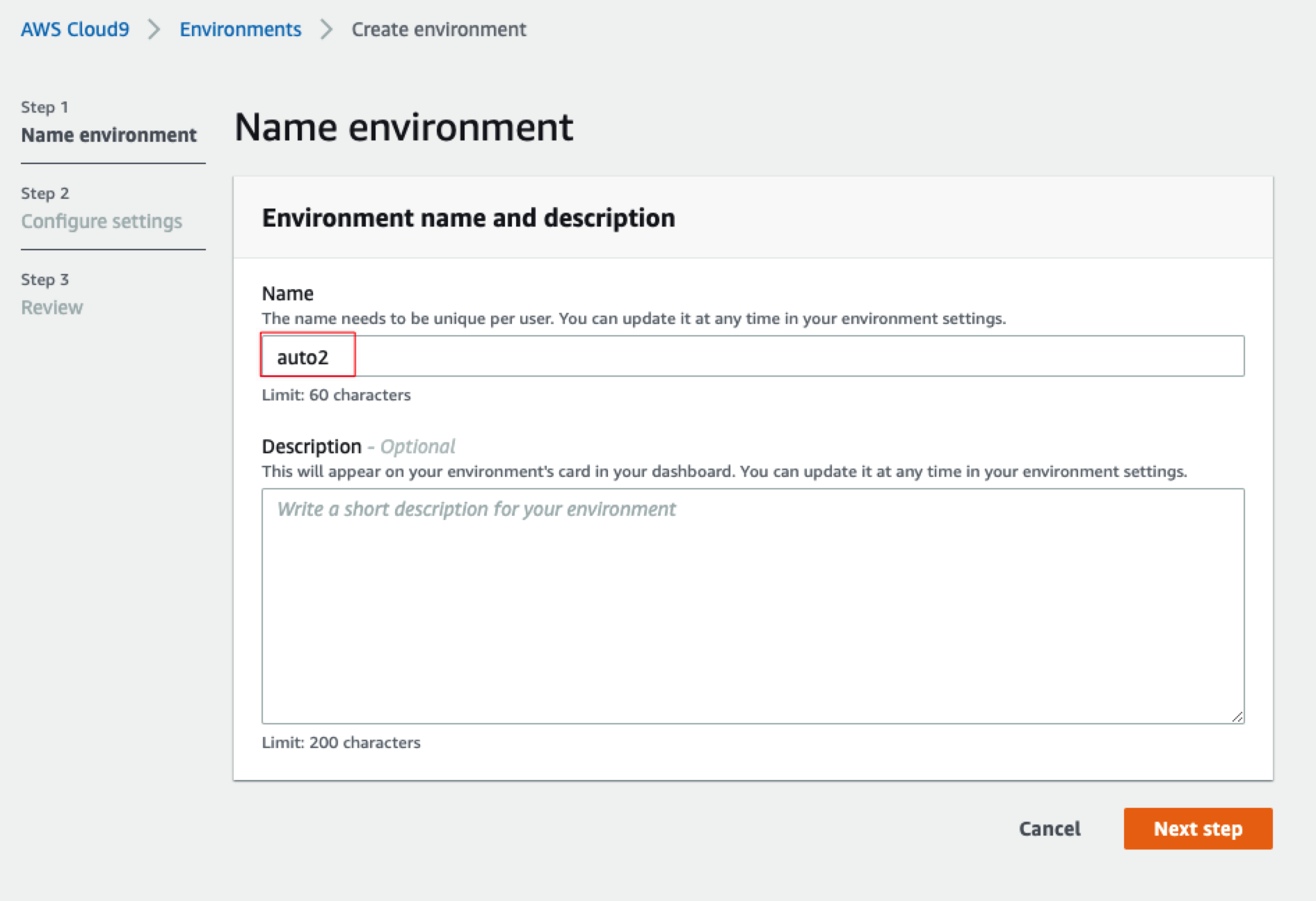
确认如下红框选中的配置,其他保持默认即可
约等待1-2分钟即可打开Cloud9控制台,如果出现确实无法访问的情况(不排除是出口网络问题),可以把刚创建的Cloud9删除,重新创建一个。
2.2 安全配置
打开IAM控制台,点击左边的角色(Roles),选择创建新角色:
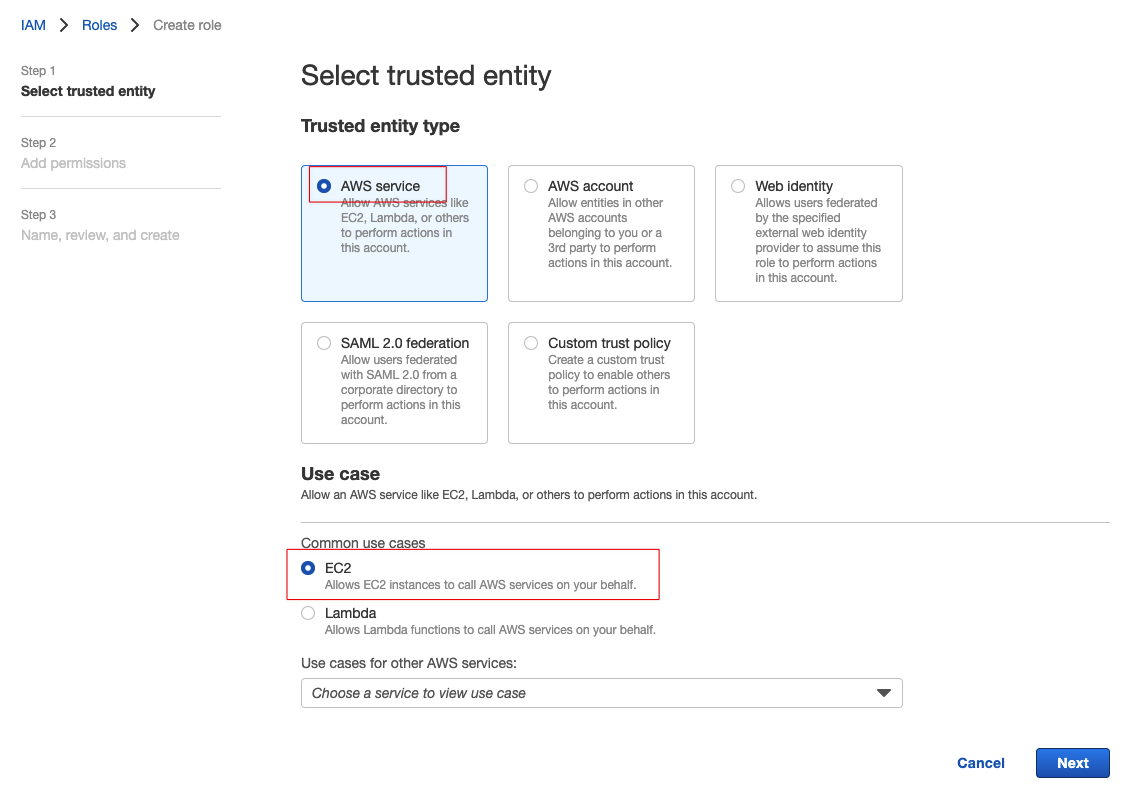
在添加权限的页面上可以输入“Administrator”进行搜索,然后选中结果里面的“AdministratorAccess”即可(注意:此处配置不符合安全最佳实践,生产环境慎用):
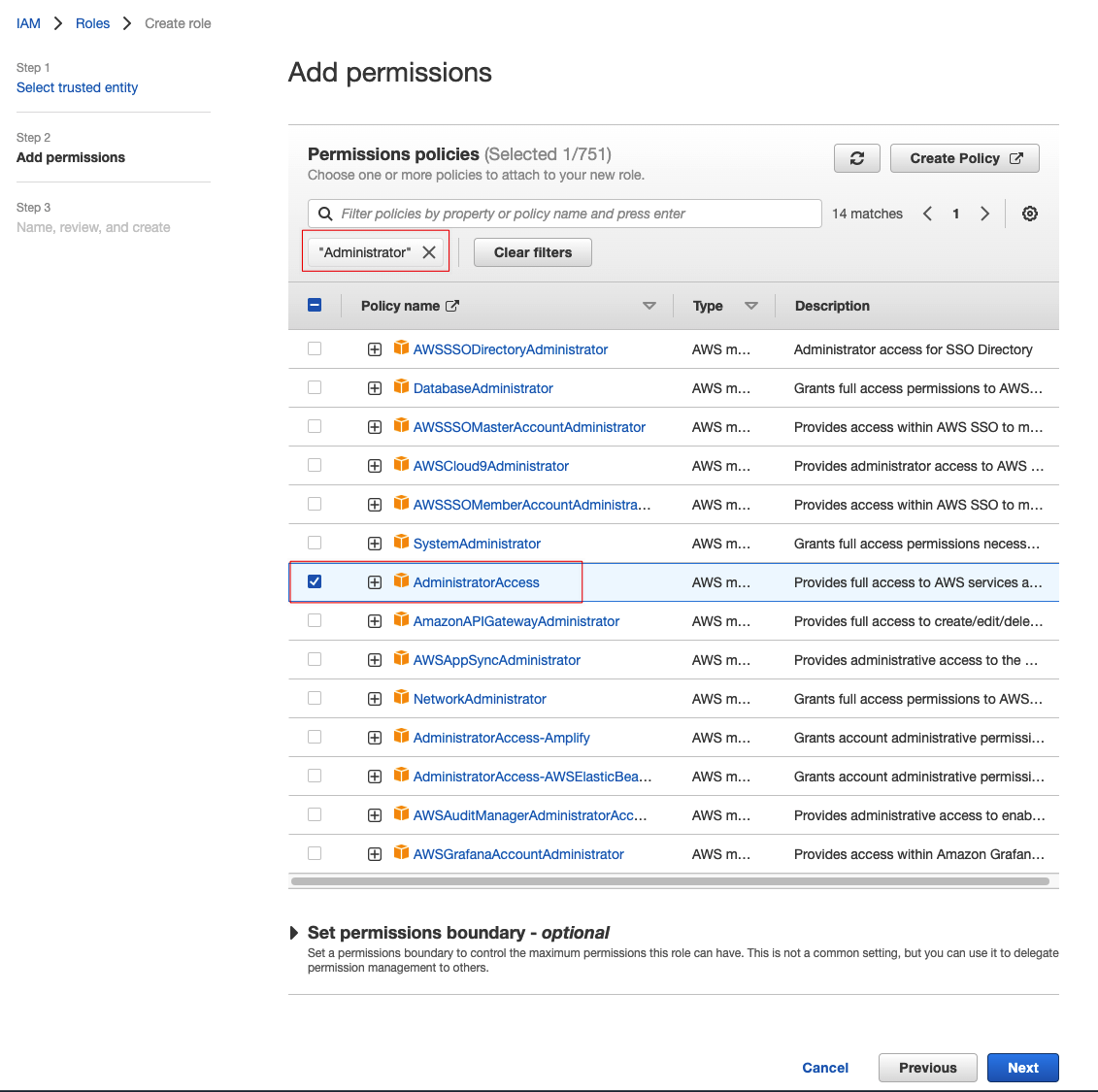
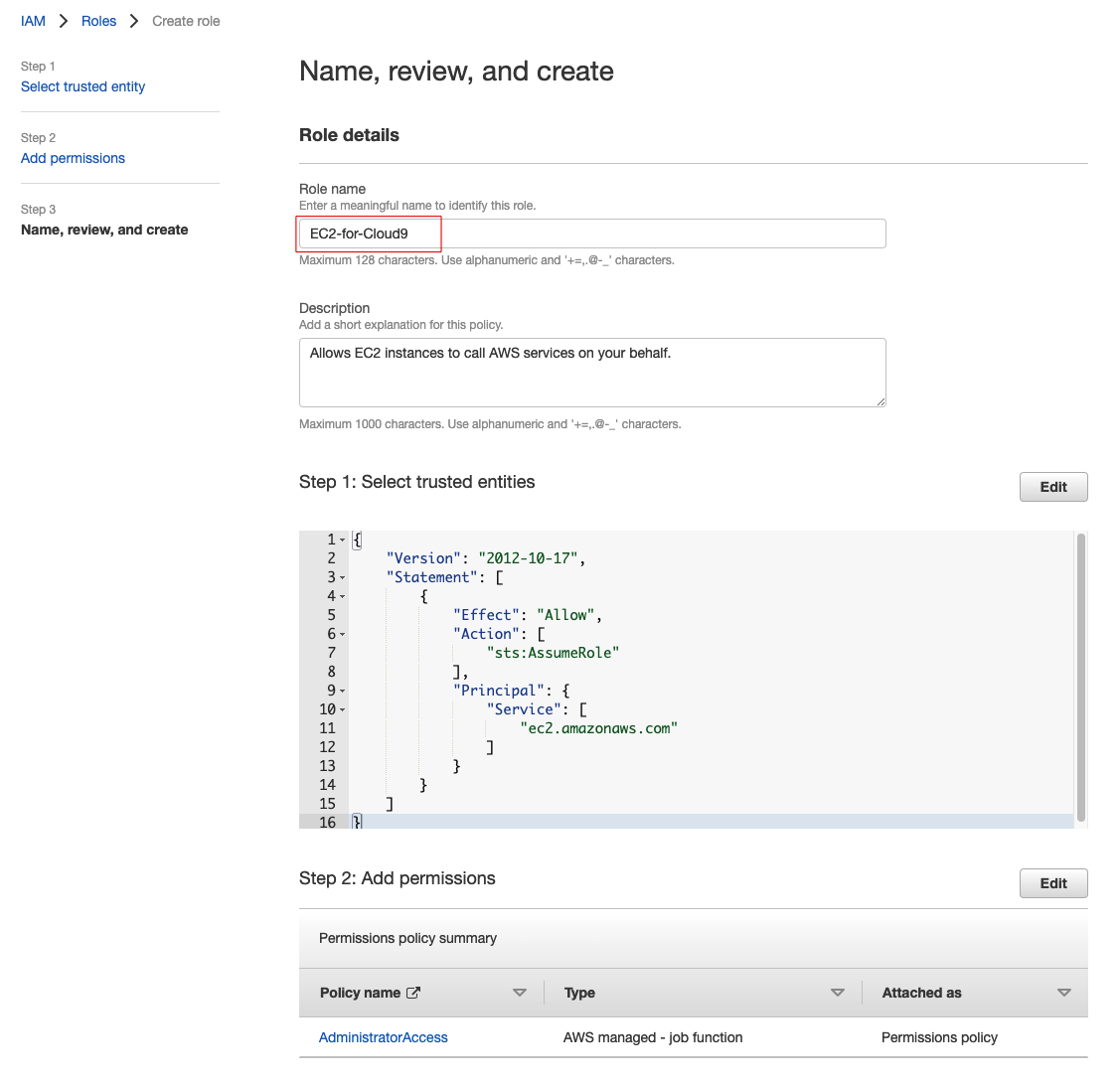
取个名字,例如叫“EC2-for-Cloud9”,然后创建即可。
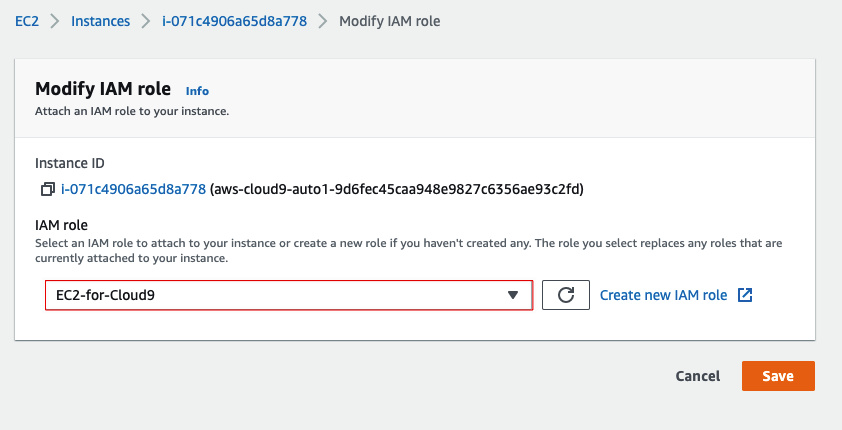
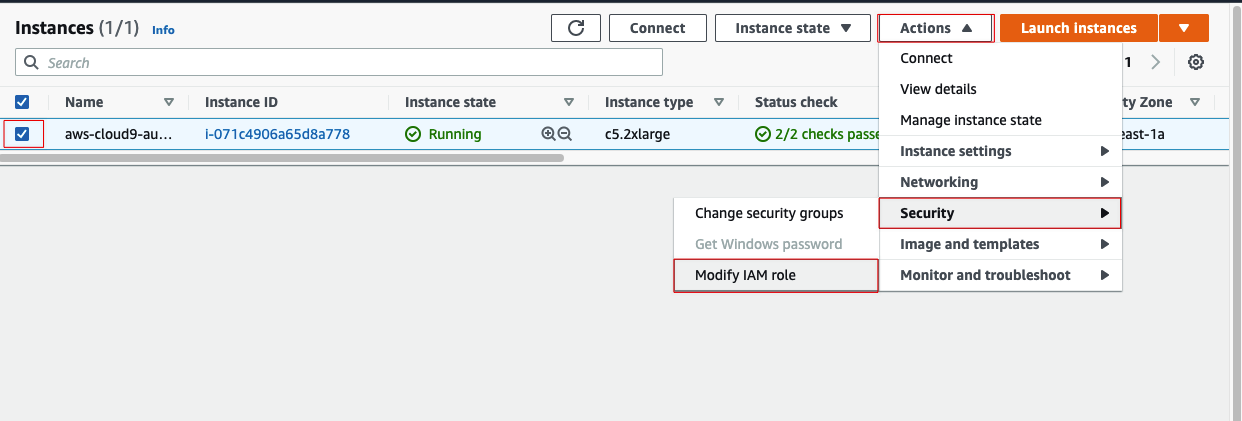
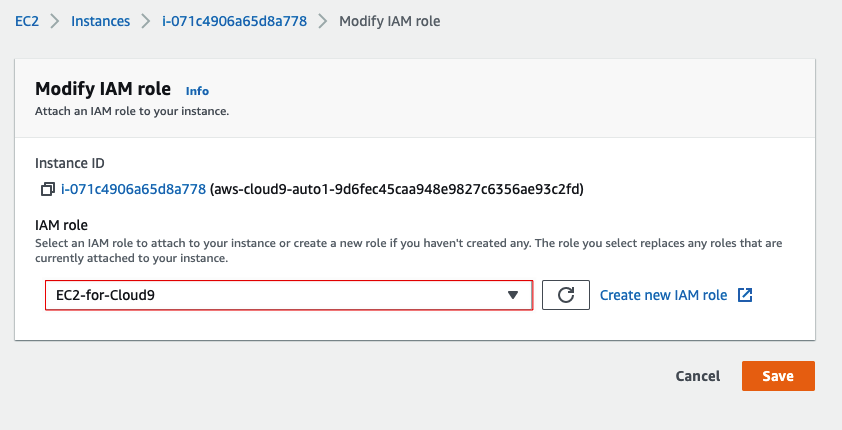
打开EC2控制台(注意别选错了区域),然后选中对应Cloud9的实例,按下图所示找到修改IAM Role的位置:
选中刚才创建的IAM Role确认即可。
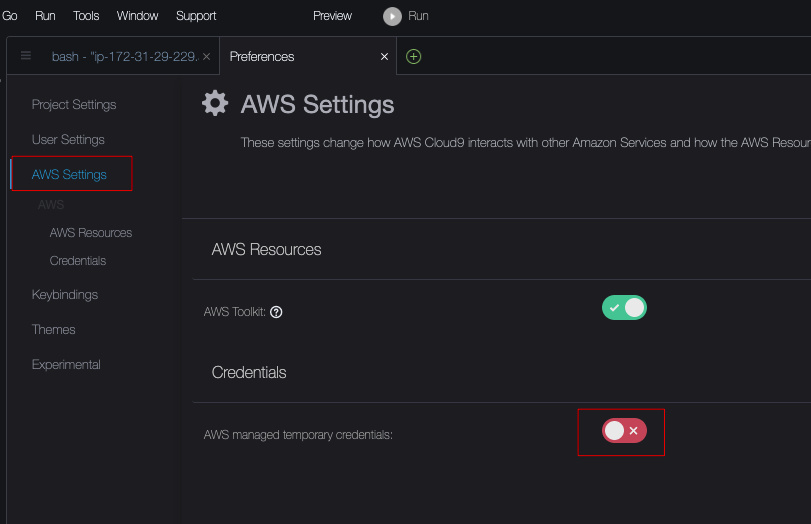
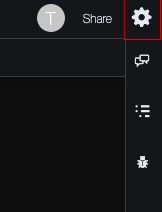
进入到Cloud9的Web控制台,点击右上角的配置按钮:
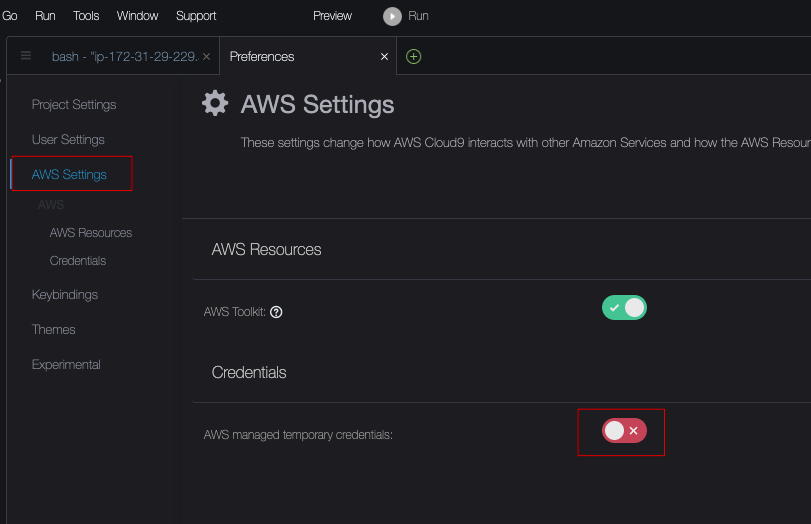
找到临时Credentials设置,把它关闭(默认是绿色打开的,调整为红色关闭的即可):
至此Cloud9配置完成。
2.3 拉取代码
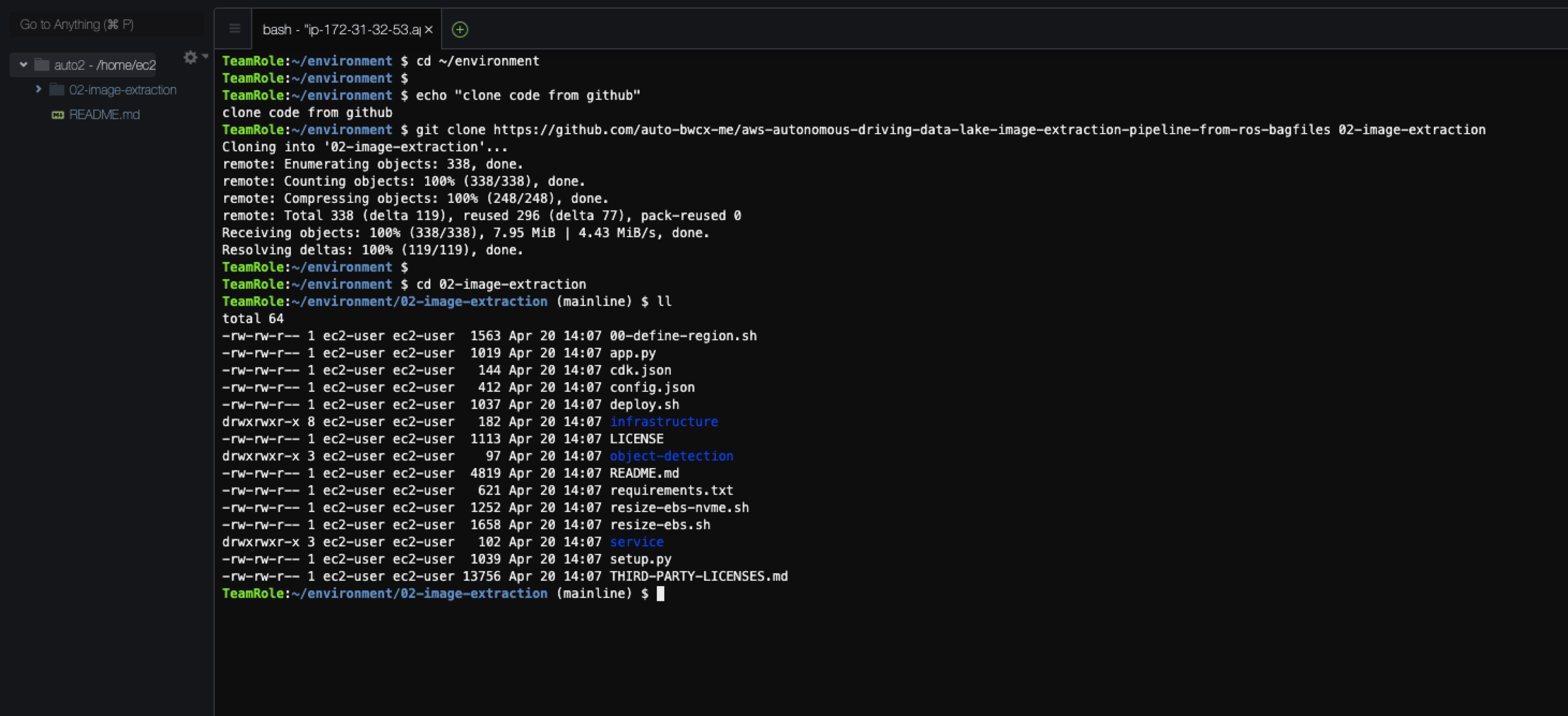
进入Cloud9环境,执行如下脚步同步代码:
cd ~/environment
echo "clone code from github"
git clone https://github.com/auto-bwcx-me/aws-autonomous-driving-data-lake-image-extraction-pipeline-from-ros-bagfiles 02-image-extraction
cd 02-image-extraction
|
正常情况如下,如果有异常,请留意URL是否正确
2.4 更新Python3.9
在更新Python3.9之前先安装一些系统后续步骤需要用到的依赖包。打开Cloud9环境的命令行执行:
sudo yum -y update
sudo yum -y install jq gettext bash-completion moreutils telnet git
|
然后更新安装配置,删除临时Crendentials:
echo "delete temp credentials"
rm -vf ${HOME}/.aws/credentials
echo "config cloud9 env"
export ACCOUNT_ID=$(aws sts get-caller-identity --output text --query Account)
export AWS_REGION=$(curl -s http://169.254.169.254/latest/meta-data/placement/region)
echo "export ACCOUNT_ID=${ACCOUNT_ID}" | tee -a ~/.bash_profile
echo "export AWS_REGION=${AWS_REGION}" | tee -a ~/.bash_profile
aws configure set default.region ${AWS_REGION}
aws sts get-caller-identity
|
如果返回类似如下内容表示权限配置成功(中间的EC2-for-Cloud9是我们之前配置的IAM角色):
{
"Account": "123456789012",
"UserId": "ARSKWX1234FFAC893KKQK:i-12345678",
"Arn": "arn:aws:sts::123456789012:assumed-role/EC2-for-Cloud9/i-12345678"
}
|
接下来使用如下方式安装和更新Python3.9:
cd ~/environment
echo "get python 3.9 packages"
wget https://www.python.org/ftp/python/3.9.10/Python-3.9.10.tgz
tar xzf Python-3.9.10.tgz
cd Python-3.9.10
echo "compile and install"
./configure --enable-optimizations
sudo make altinstall
echo "config python3.9"
sudo rm -f /usr/bin/python3
sudo ln -s /usr/local/bin/python3.9 /usr/bin/python3
|
大概需要5分钟左右的时间。
3.测试过程
注意:如果在别的环节调整过Cloud9的默认磁盘大小,可以有选择跳过对应步骤。
默认情况下,部署的Cloud9的磁盘只有10G,我们需要打包好几个Docker镜像,很容易把磁盘撑爆了,所以通过执行这脚本可以把磁盘调整到例如1000G(其实如果只是做这一个实验,100G以上就可以满足,或者曾经调整过磁盘就可以跳过了),确保在代码目录下执行(如果使用的是普通SSD硬盘,记得更换对应脚本文件):
sh resize-ebs-nvme.sh 1000
# sh resize-ebs.sh 1000
|
默认情况下,我们选择和设置的区域是新加坡区域,如果不确定可以这样显式指定:
sh 00-define-region.sh ap-southeast-1
|
3.1配置CDK
通过如下方式配置Python3.9环境
pip install --upgrade pip
python3 -m venv .env
pip3 install -r requirements.txt
|
更新CDK的相关包
npm install -g aws-cdk --force
cdk --version
|
创建ECR的docker 镜像存储库
cat config.json |jq .
aws ecr create-repository --repository-name rosbag-images-extract
|
然后开始CDK的初始化(要注意的是,一个Region初始化一次即可,不需要重复操作,如下的整个命令是一行,注意复制执行的时候不要折行了):
cdk bootstrap aws://$(curl -s http://169.254.169.254/latest/dynamic/instance-identity/document/ |jq -r .accountId)/$(curl -s http://169.254.169.254/latest/meta-data/placement/region)
|
3.2部署环境
接下来部署文章开头架构图所示的测试环境(大概需要10-20分钟)
bash deploy.sh deploy true
|
3.3测试验证
按如下的脚本准备测试数据即可
# get s3 bucket name
s3url="https://auto-bwcx-me.s3.ap-southeast-1.amazonaws.com/my-vsi-rosbag-stack-srcbucket"
echo "Download URL is: ${s3url}"
s3bkt=$(aws s3 ls |grep rosbag-images-extract-srcbucket |awk '{print $3}')
echo "S3 bucket is: ${s3bkt}"
# create saving directory
cd ~/environment
mkdir -p ./data/rosbag-images-extract/{industry,test1,test2}
save_dir="./data/rosbag-images-extract"
# download testing files
wget ${s3url}/industry-kit/v1/2020-10-05-11-11-58_1.bag -O ${save_dir}/industry/2020-10-05-11-11-58_1.bag
wget ${s3url}/industry-kit/v1/test_file_2GB_2021-07-14-12-00-00_1.bag -O ${save_dir}/industry/test_file_2GB_2021-07-14-12-00-00_1.bag
wget ${s3url}/industry-kit/v1/test_file_7GB_2021-07-14-12-30-00_1.bag -O ${save_dir}/industry/test_file_7GB_2021-07-14-12-30-00_1.bag
wget ${s3url}/test-vehicle-01/072021/2020-11-19-22-21-36_1.bag -O ${save_dir}/test1/2020-11-19-22-21-36_1.bag
cp ${save_dir}/test1/2020-11-19-22-21-36_1.bag ${save_dir}/test2/2020-11-19-22-21-36_1.bag
# wget ${s3url}/test-vehicle-02/072021/2020-11-19-22-21-36_1.bag -O ${save_dir}/test2/2020-11-19-22-21-36_1.bag
# upload testing file
aws s3 cp ${save_dir}/industry/2020-10-05-11-11-58_1.bag s3://${s3bkt}/industry-kit/v1/2020-10-05-11-11-58_1.bag
aws s3 cp ${save_dir}/industry/test_file_2GB_2021-07-14-12-00-00_1.bag s3://${s3bkt}/industry-kit/v1/test_file_2GB_2021-07-14-12-00-00_1.bag
aws s3 cp ${save_dir}/industry/test_file_7GB_2021-07-14-12-30-00_1.bag s3://${s3bkt}/industry-kit/v1/test_file_7GB_2021-07-14-12-30-00_1.bag
aws s3 cp ${save_dir}/test1/2020-11-19-22-21-36_1.bag s3://${s3bkt}/test-vehicle-01/072021/2020-11-19-22-21-36_1.bag
aws s3 cp ${save_dir}/test2/2020-11-19-22-21-36_1.bag s3://${s3bkt}/test-vehicle-02/072021/2020-11-19-22-21-36_1.bag
|
因为我们的S3存储桶设置了Lambda触发,所以只要把文件丢上去,就会自动触发流程,流程跑完了就会自动结束和清理环境(如Lambda自动结束,ECS自动结束等)。
3.4过程监控
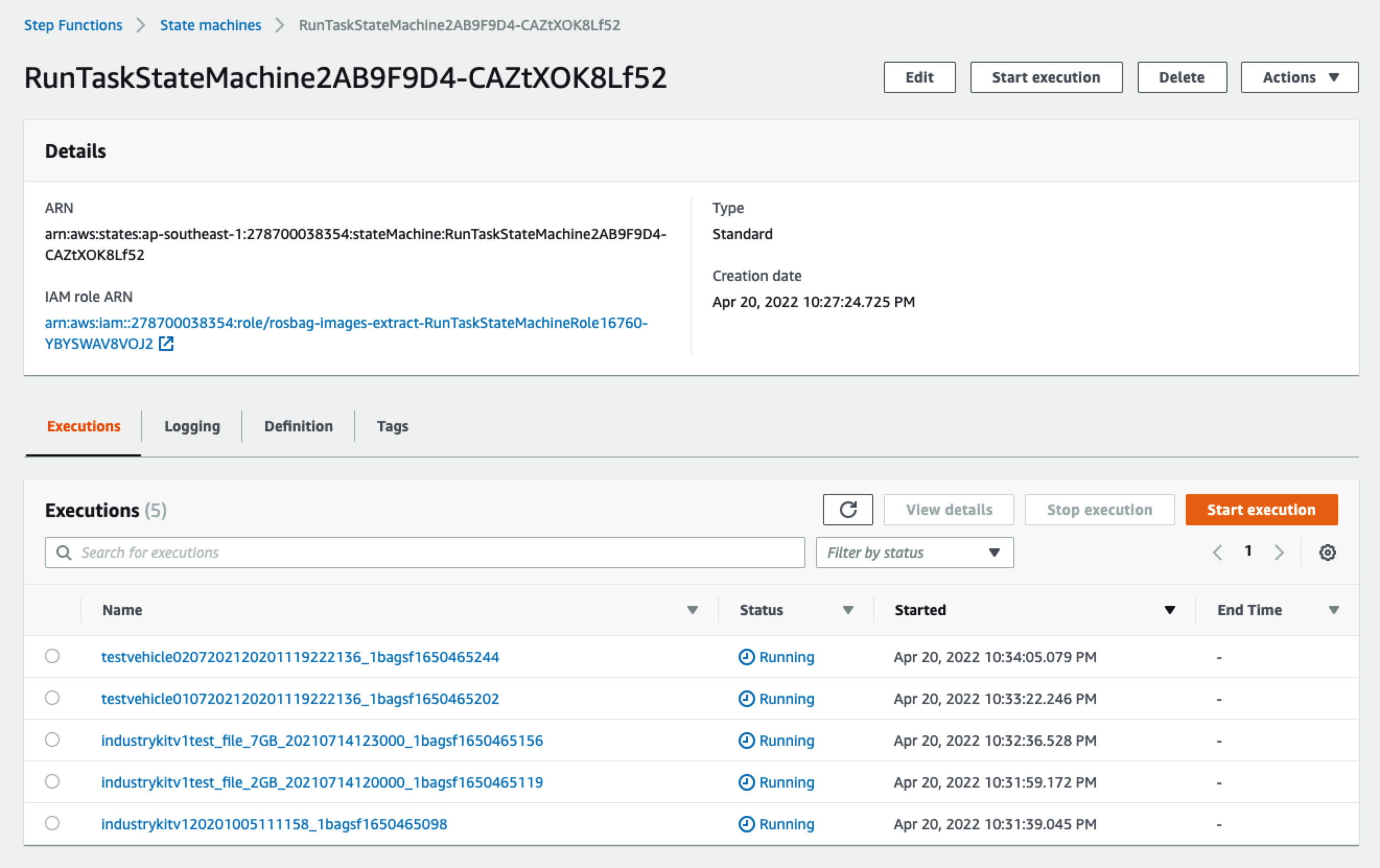
打开Step Functions控制台,可以看到一个以“RunTaskStateMachine”开头的状态机,点开以后,可以看到被触发的列表(因为我们上面上传了5个文件,所以有5次执行记录):
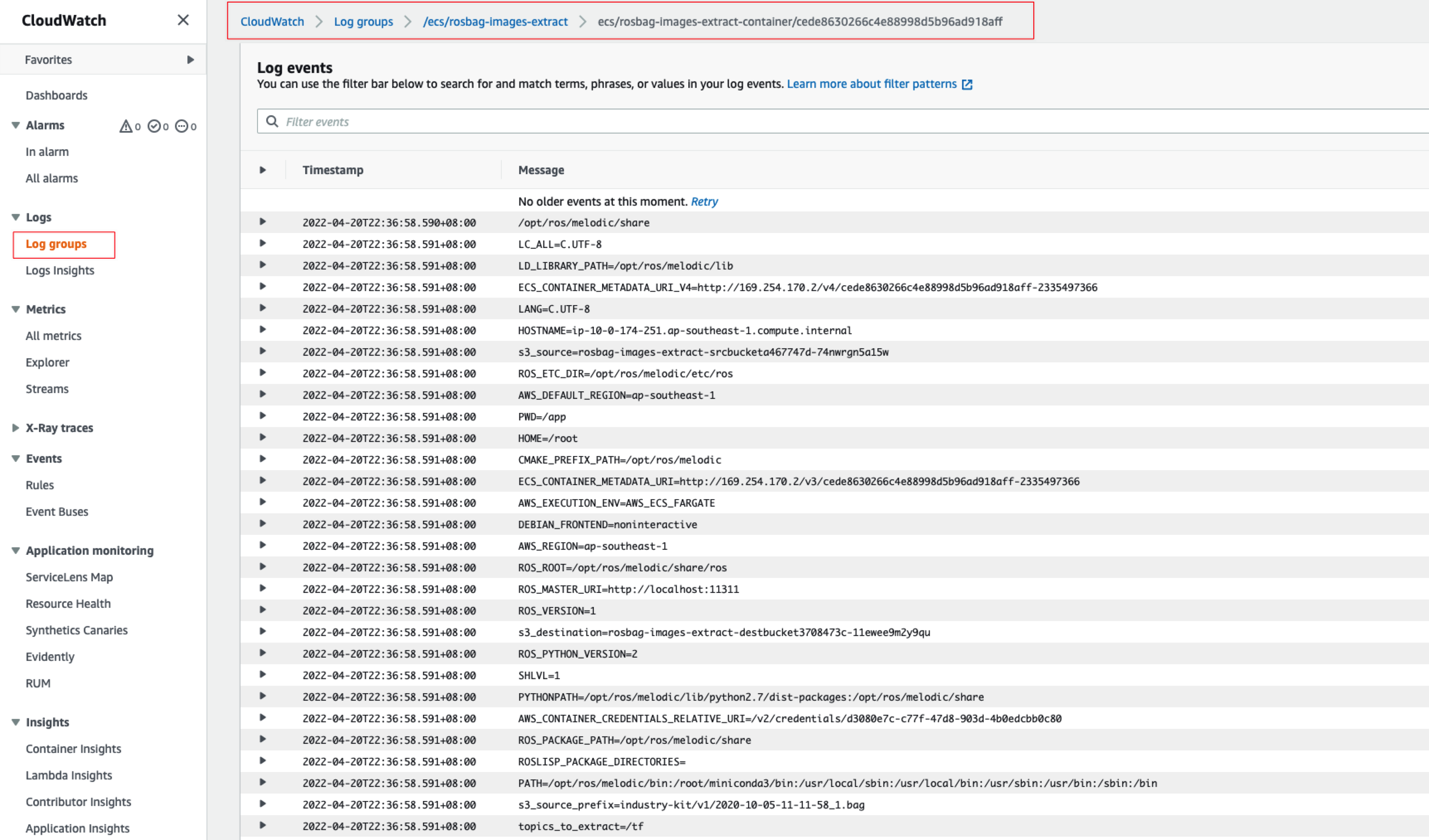
打开CloudWatch控制台,选择左边的日志组,然后查看对应的日志组里面的日志输出,可以更好的核对和理解对应处理过程(截图为其中一个):
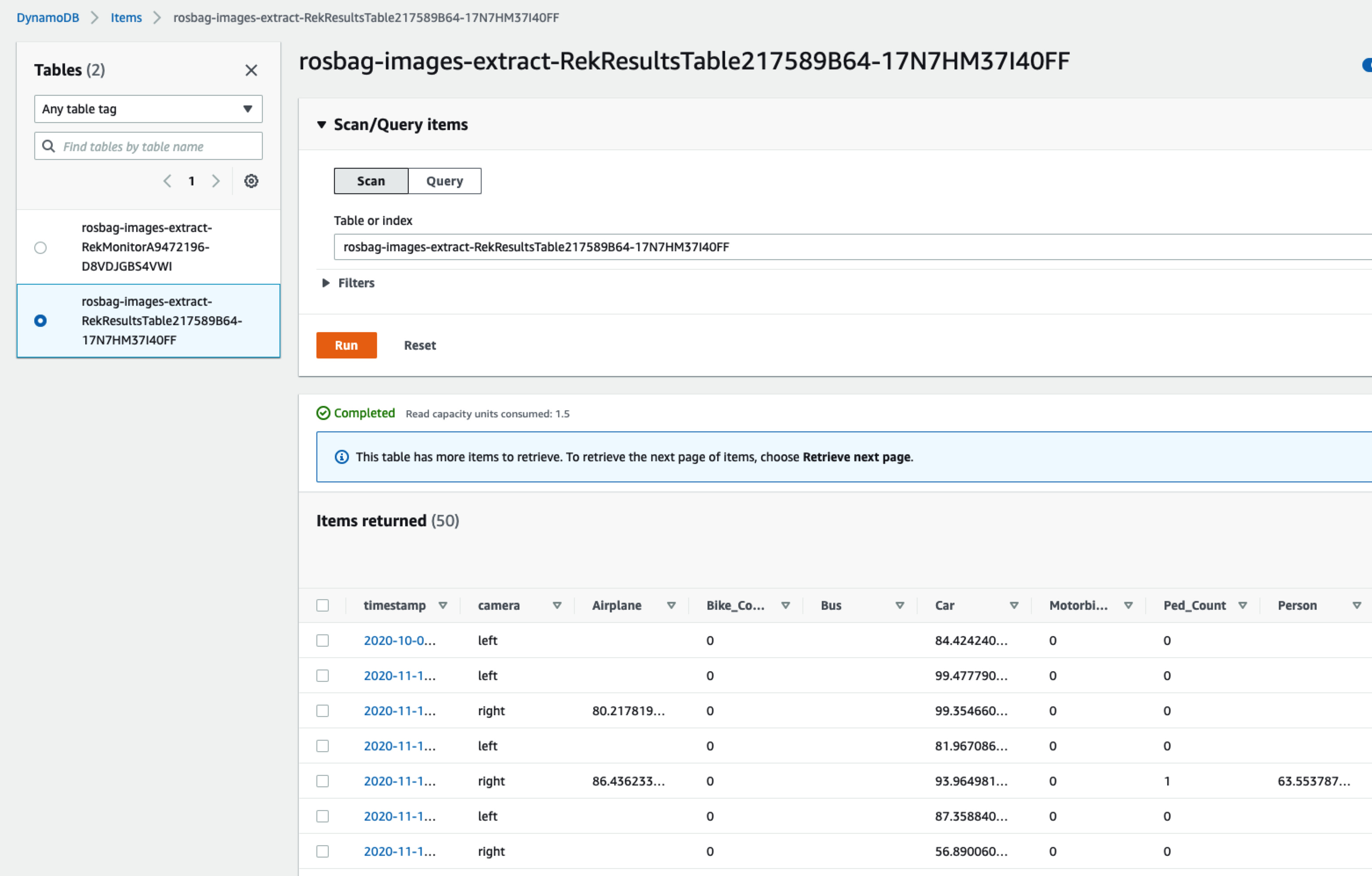
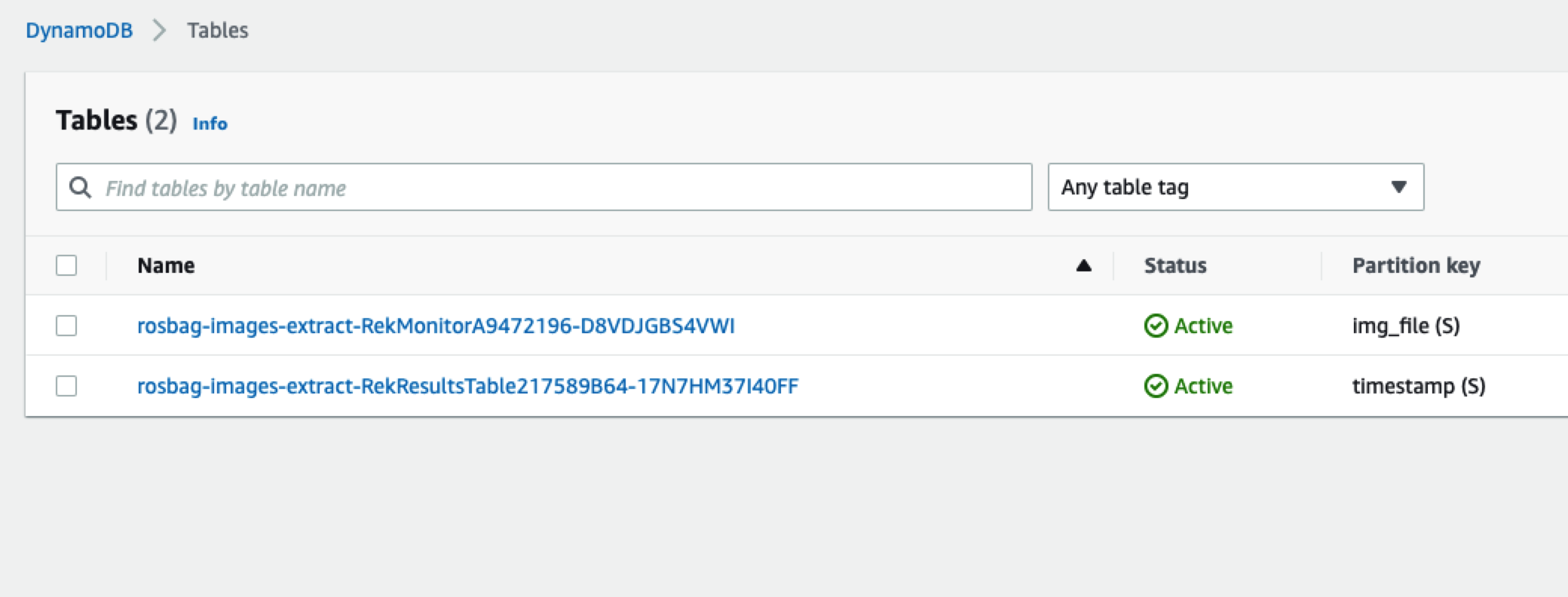
打开DynamoDB的控制台,即可看到对应的元数据的表,如下图所示:
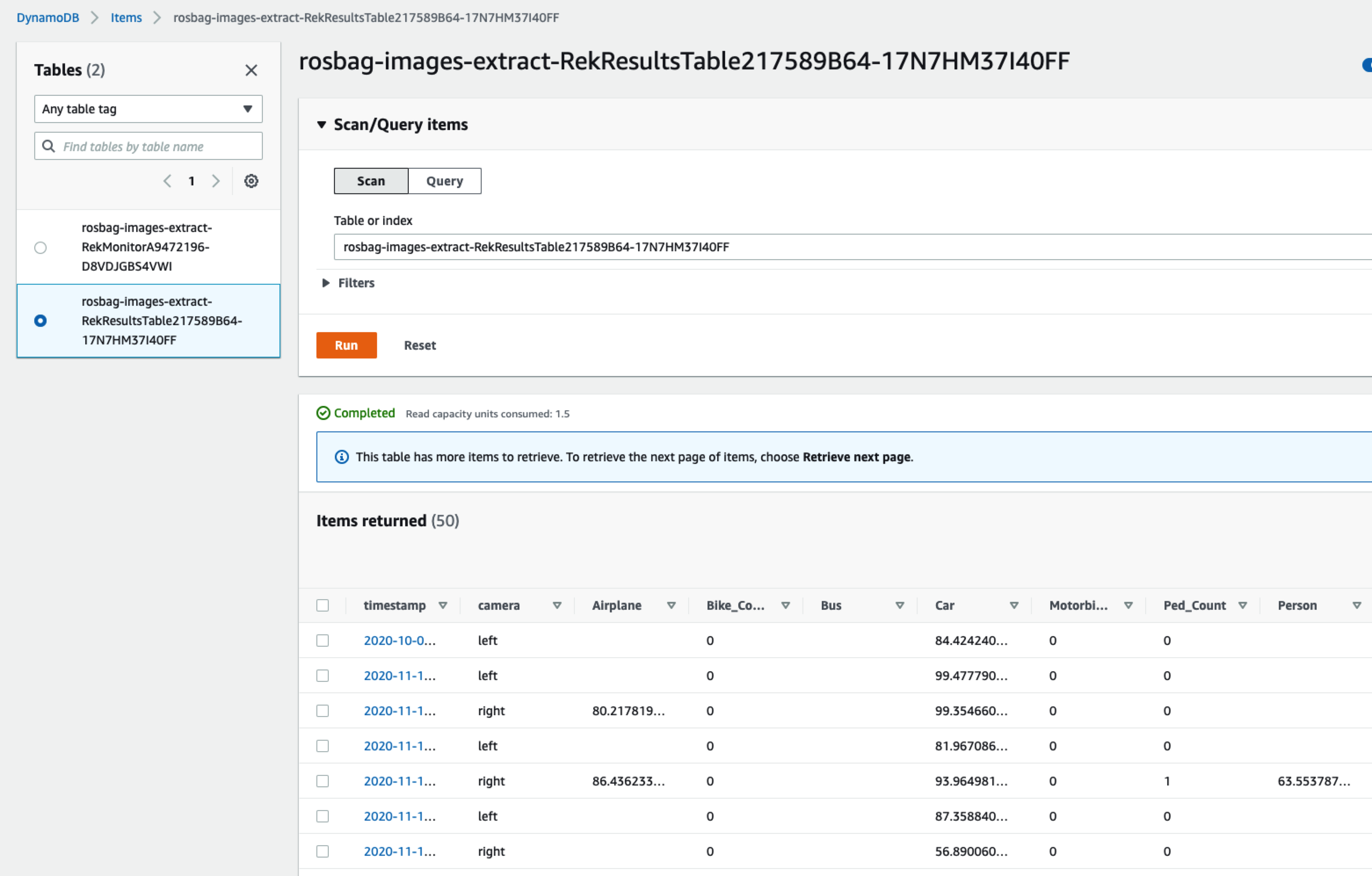
可以找到对应的Rekognition处理后的数据信息
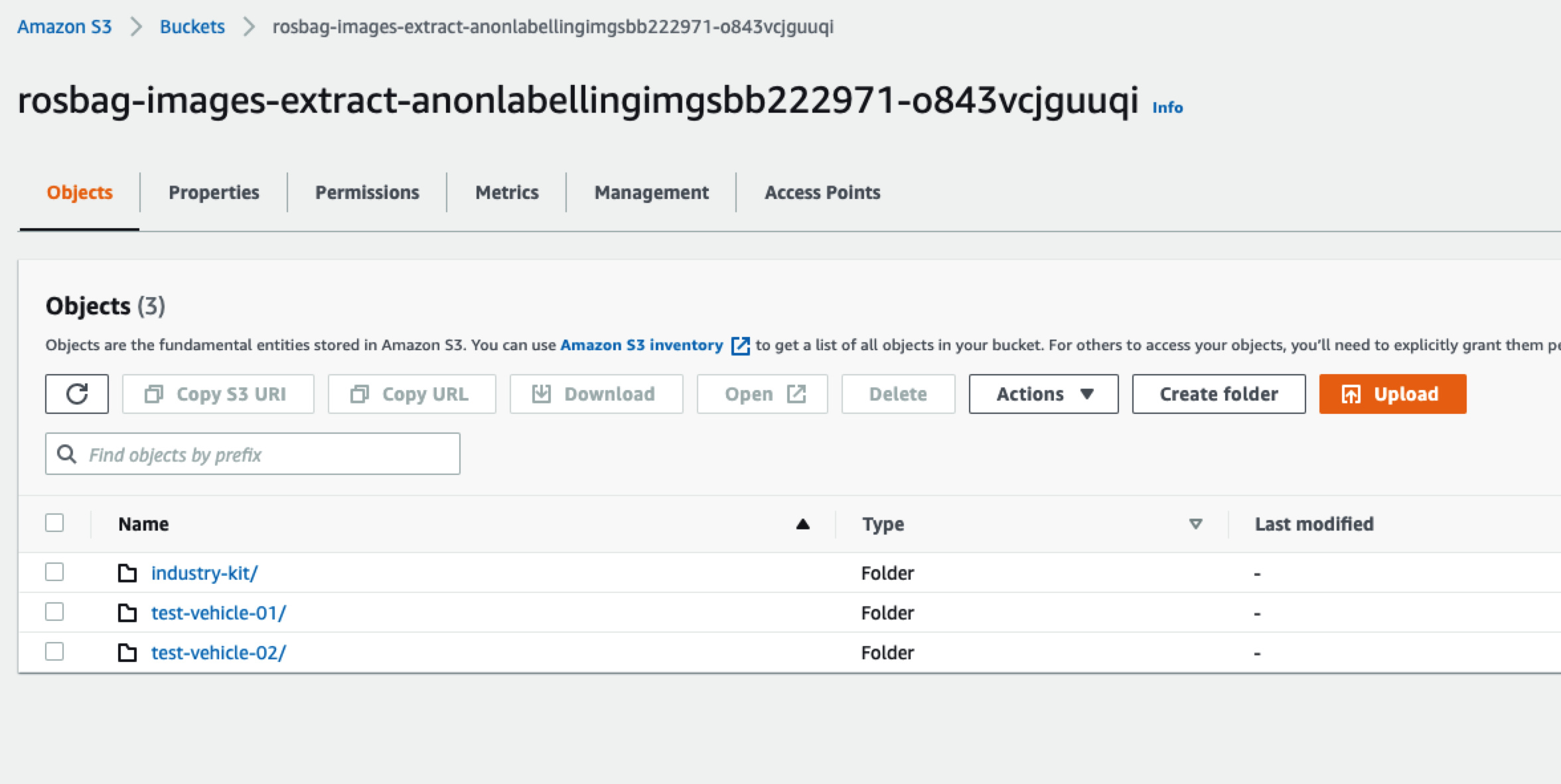
打开S3的控制台,会看到多个由“rosbag-images-extract”开头的存储桶:
名字里面带src的桶里面是我们上传的原始数据:
名字里面带dest的桶里面是我们使用ECS处理后的目标数据
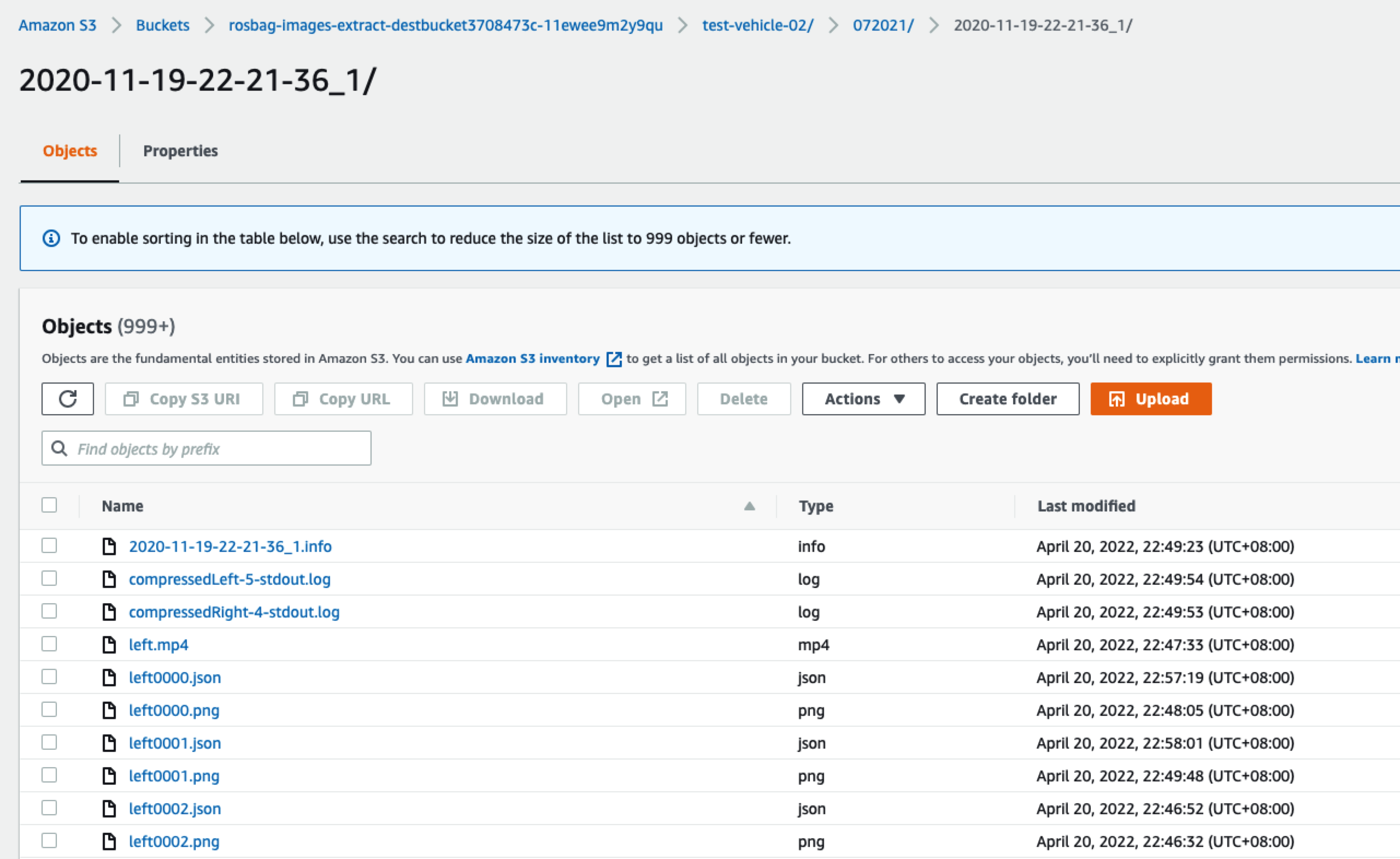
解析出来的数据量比较大,如下图所示:
名字里面包含label的桶里面是我们使用Rekognition识别出来的数据(后面用模型训练需要用到这些数据):
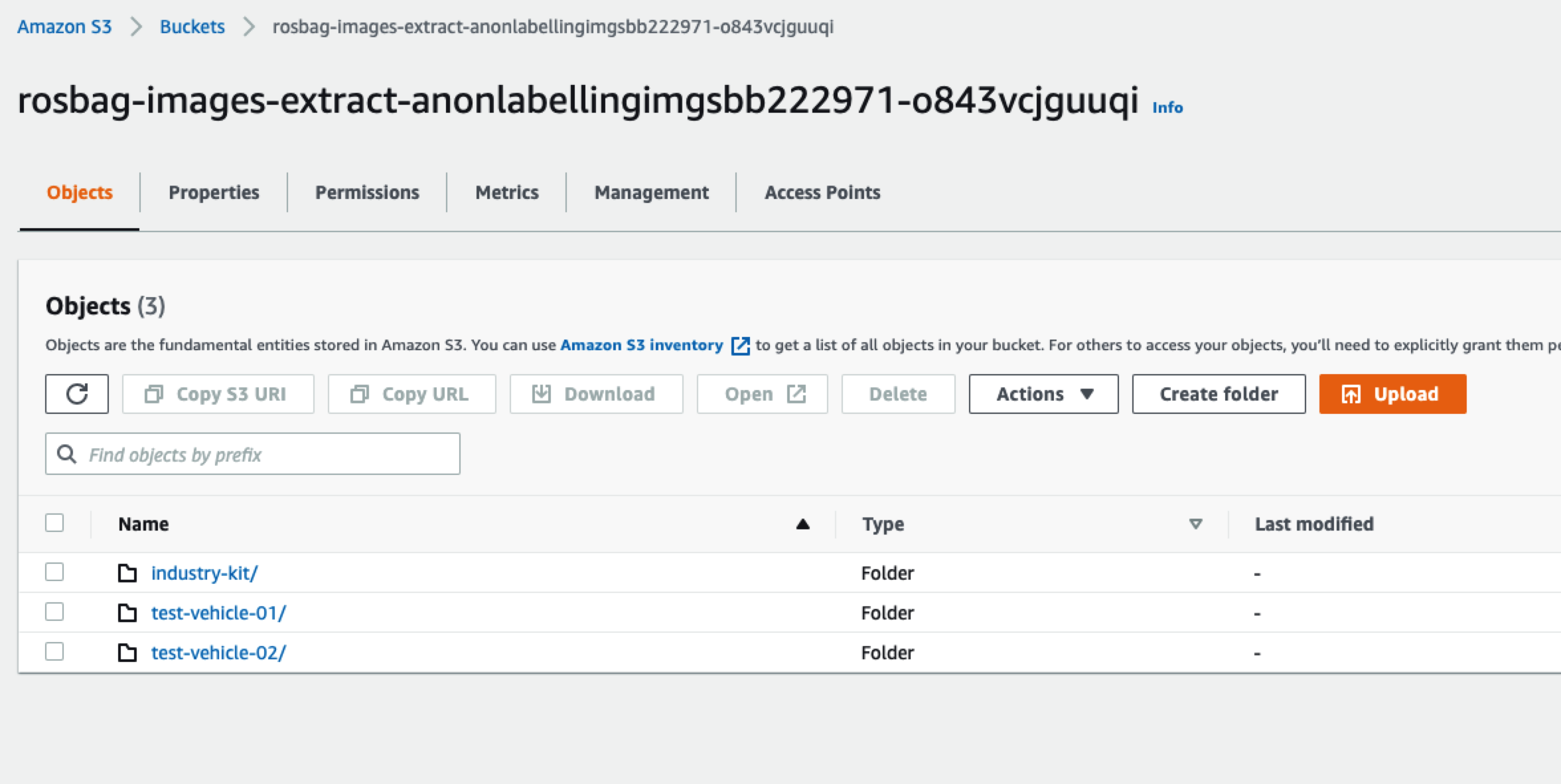
例如我们下载left0050.png这个图片
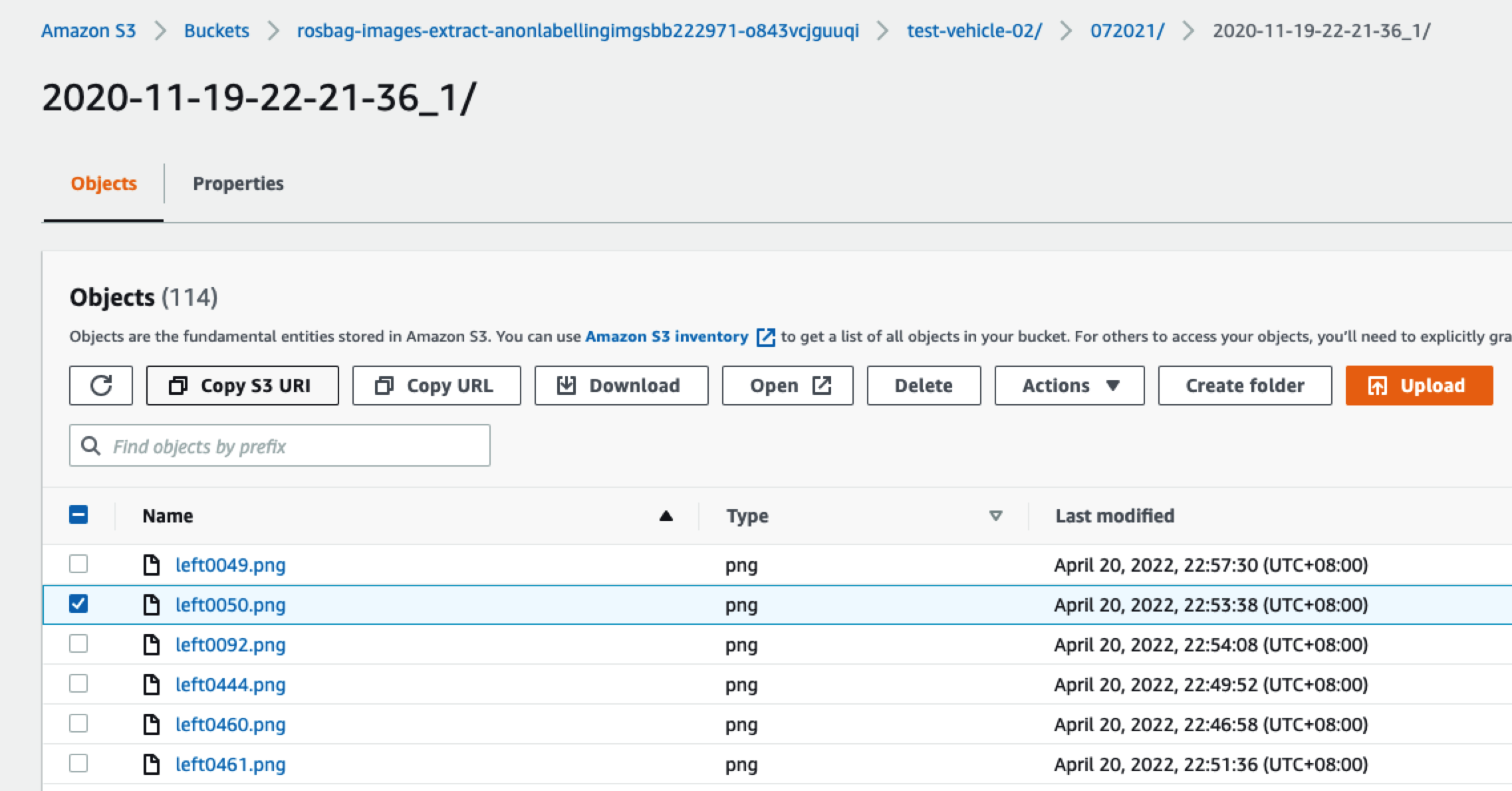
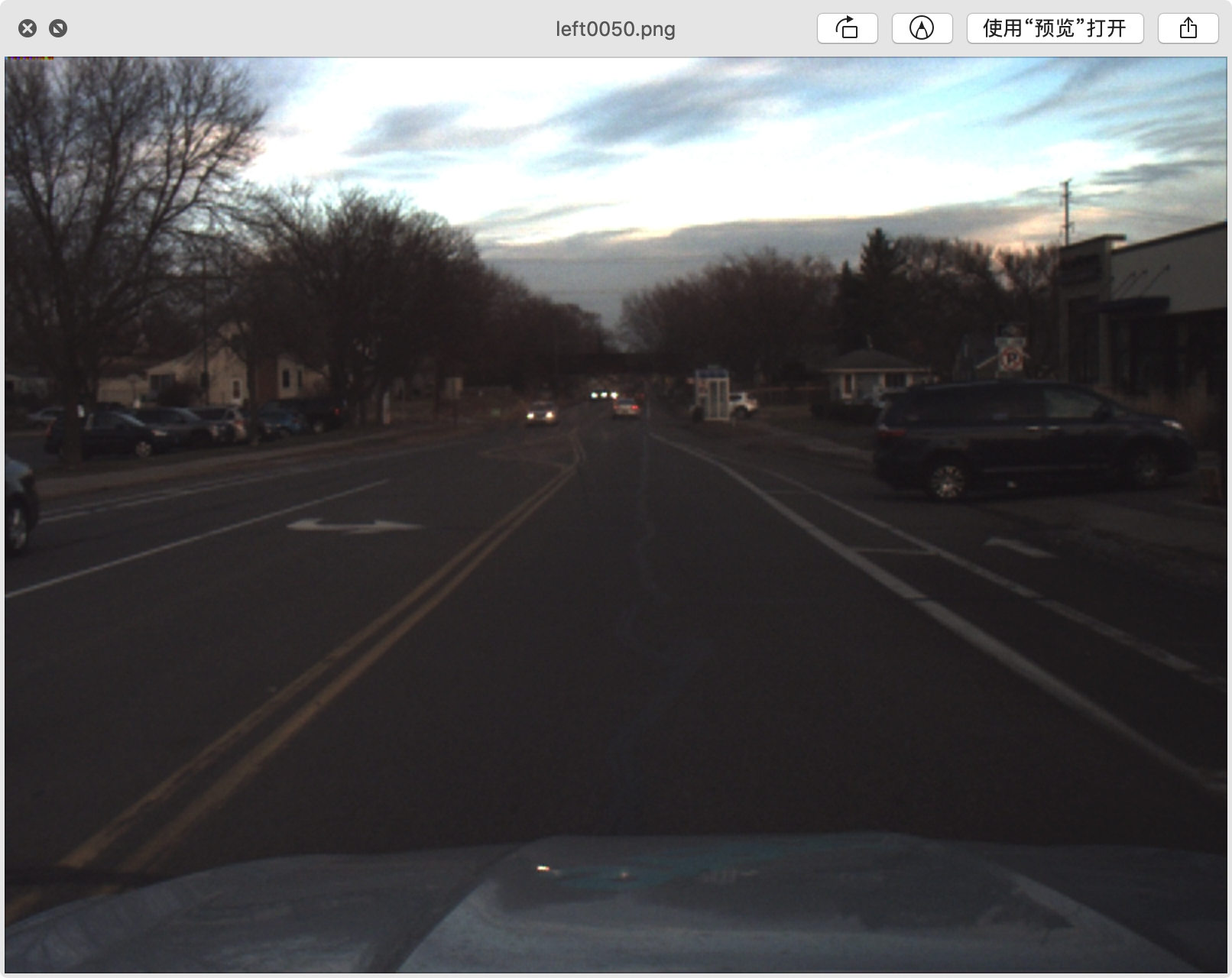
它的原始内容如下
4.模型训练
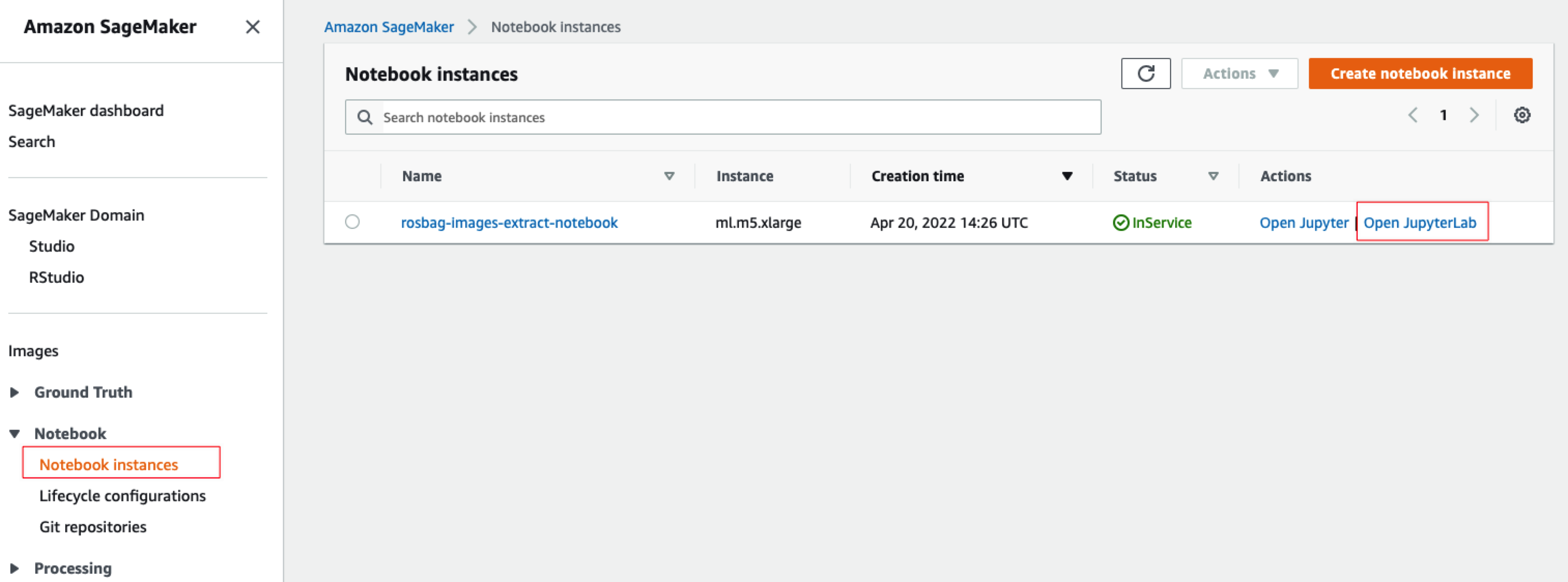
4.1准备Jupyter笔记本
打开SageMaker控制台,选择左边的Notebook instances菜单,然后看到系统准备好的Jupyter笔记本,点击如下图所示的“Open JupyterLab”:
打开后,默认里面是空的,可以通过单击如下图所示的Terminal打开终端shell环境:
并执行如下脚本获取Jupyter笔记本和测试数据:
cd SageMaker
git clone https://github.com/auto-bwcx-me/aws-autonomous-driving-data-lake-image-extraction-pipeline-from-ros-bagfiles.git image-extraction
cp -Rv image-extraction/object-detection/* ./
|
结果如下所示
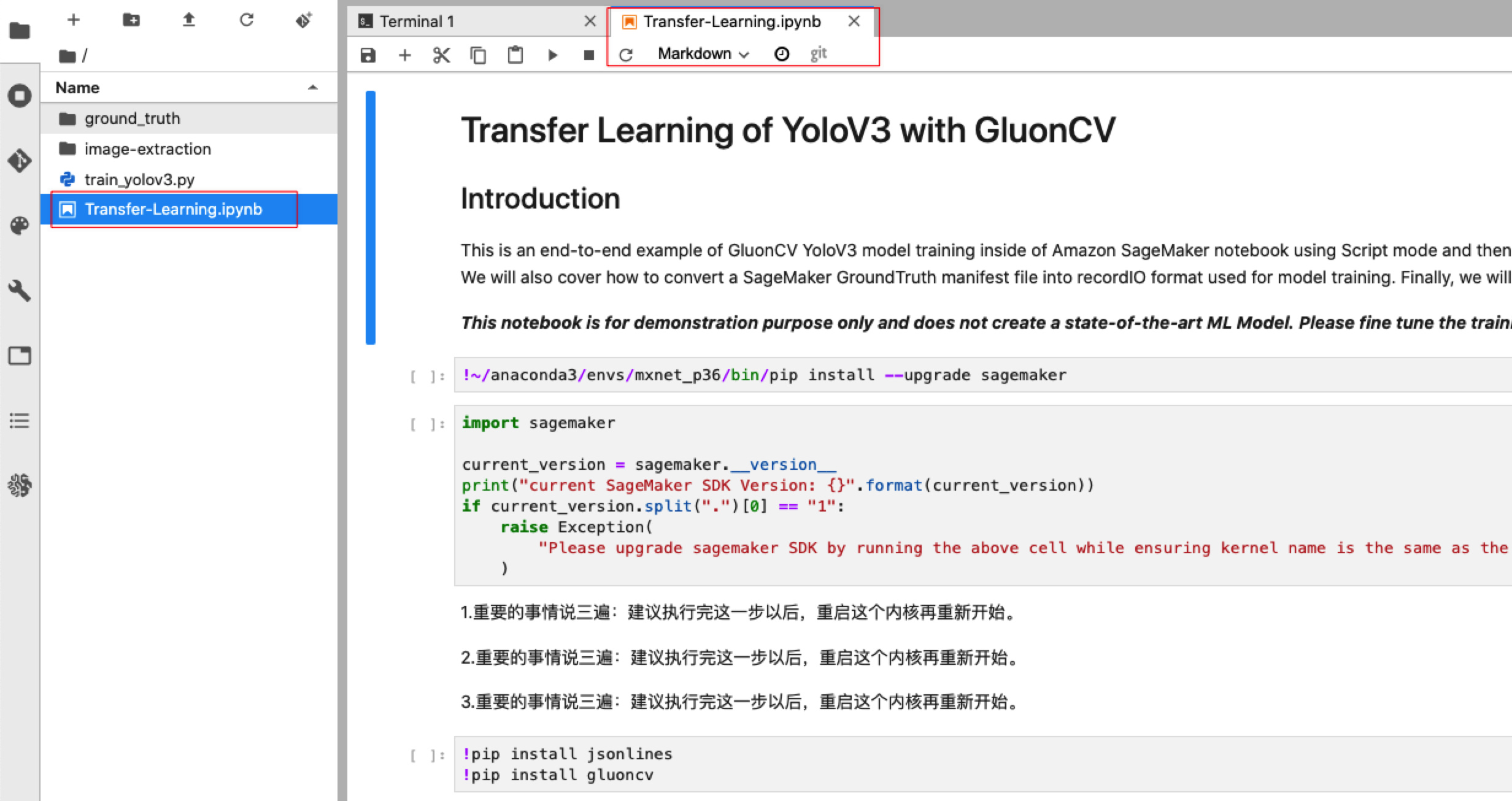
双击左边的Transfer-Learning.ipynb即可打开新的tab页面,开始模型训练,部署和测试的过程,如下图所示:
4.2训练和部署模型
按照Jupyter笔记本的步骤,进行模型的训练,部署和验证,中间过程也可以切换页面到SageMaker控制台,通过查看对应的训练任务,部署任务,在线推理环境等信息,具体细节本文不再赘述。
注意:在训练模型的过程中,如果碰到例如某个机型没有了(默认机型是ml.p3.8xlarge),可以通过调整这一段代码实现修改后重新从这一段开始执行即可:
model_estimator = MXNet(
entry_point="train_yolov3.py",
role=role,
instance_count=1, # value can be more than 1 for multi node training
instance_type="ml.p3.2xlarge",
framework_version="1.8.0",
metric_definitions=metric_definitions,
output_path=s3_output_path,
code_location=s3_code_path,
py_version="py37")
|
5.环境清理
虽然绝大部分分配和使用资源型的服务(如ECS,Lambda等)会自动终止资源使用,但是如果客户想手工清除环境的话,可以先清空上述测试过程中创建的S3存储桶里面的数据(以rosbag-images-extract开头的S3存储桶,当然手工删除这些存储桶也是可以的),然后在代码目录下执行如下脚本即可(大概需要10分钟):
参考文档
参考1: 在亚马逊云科技上构建自动驾驶数据湖:
https://aws.amazon.com/cn/blogs/architecture/field-notes-building-an-autonomous-driving-and-adas-data-lake-on-aws/
参考2: 自动驾驶数据湖之图像处理和模型训练:
https://aws.amazon.com/cn/blogs/architecture/field-notes-building-an-automated-image-processing-and-model-training-pipeline-for-autonomous-driving/
参考3: 自动驾驶数据湖(一):场景检测:
https://aws.amazon.com/cn/blogs/china/autonomous-driving-data-lake-scene-detection/
参考4: 自动驾驶数据湖(三):图像处理流程管道:
https://aws.amazon.com/cn/blogs/china/autonomous-driving-data-lake-image-extraction-pipeline-using-airflow/
参考5: 自动驾驶数据湖(四):可视化:
https://aws.amazon.com/cn/blogs/china/autonomous-driving-data-lake-visualization-using-webviz/
本篇作者