亚马逊AWS官方博客
自动驾驶数据湖(一):场景检测
1.前言
在亚马逊云科技2020的re:Invent大会上,发布了在云上构建自动驾驶数据湖的参考架构(点击 这里 下载源文件),结合国内的实际业务场景,我们做了一些针对性的细化和调整,修改为如下的参考架构(以MDF4/Rosbag格式数据为参考)。

因为Rosbag数据文件里面包含了例如图片,音视频,雷达,GPS等内容,需要通过解析并识别出来例如带时间戳的图片数据,pcd点云数据等,解析和拆开了对应数据以后就可以进行对应的数据分析,机器学习等环节处理。
因此我们把上图中的自动驾驶数据湖参考架构拆分成一个系列的四篇博客(此处暂时未包括左上角的IoT相关部分),方便用户和读者理解和使用对应的解决方案,这是本系列博客的第一部分:场景检测(基于上图的1-3-4步骤实现)。
在本篇博客中,更加细化的场景检测的具体步骤和代码,可以参考如下图所示的参考步骤:

说明:此架构图来自参考文档2里面的步骤架构,我们未做修改。
接下来的博客内容详细代码和步骤参考上图的架构:
a)先把Rosbag文件通过ECS做拆解;
b)然后通过EMR对拆解后的数据进行分析和处理;
c)相关元数据写入DynamoDB,方便后续分析和使用;
d)最后我们通过Athena对数据进行简单的查询验证。
2.环境准备
我们使用的源代码位于 https://github.com/auto-bwcx-me/ (如果对亚马逊云科技的相关服务特别熟悉,也可以直接使用 官方的GitHub Repo)。
环境说明:
a)我们的操作环境为Cloud9,所有非控制台的操作都基于它完成;
b)因为是博客,为了突出自动驾驶数据湖相关的内容,我们直接给这个Cloud9配置了Administrator的权限,未遵循安全最佳实践里面的最小权限原则,大家在生产环境的时候要注意,尽量遵循最小权限分配的原则;
c)如果没有特别说明,我们的操作区域为新加坡区域;
d)如果没有特别说明,我们执行脚本的操作目录为代码目录。
2.1准备Cloud9
因为我们要在Cloud9里面编译更新Python3.9,所以部署Cloud9实例的时候可以选一个C系列的机型(如c5.2xlarge),这样编译速度会快很多,其他全部默认即可(注意部署到对应的区域,如新加坡区域即可)
创建一个Cloud9环境,取个名字,如“auto1”

确认如下红框选中的配置,其他保持默认即可

约等待1-2分钟即可打开Cloud9控制台,如果出现确实无法访问的情况(不排除是出口网络问题),可以把刚创建的Cloud9删除,重新创建一个。
2.2 安全配置
打开IAM控制台,点击左边的角色(Roles),选择创建新角色:
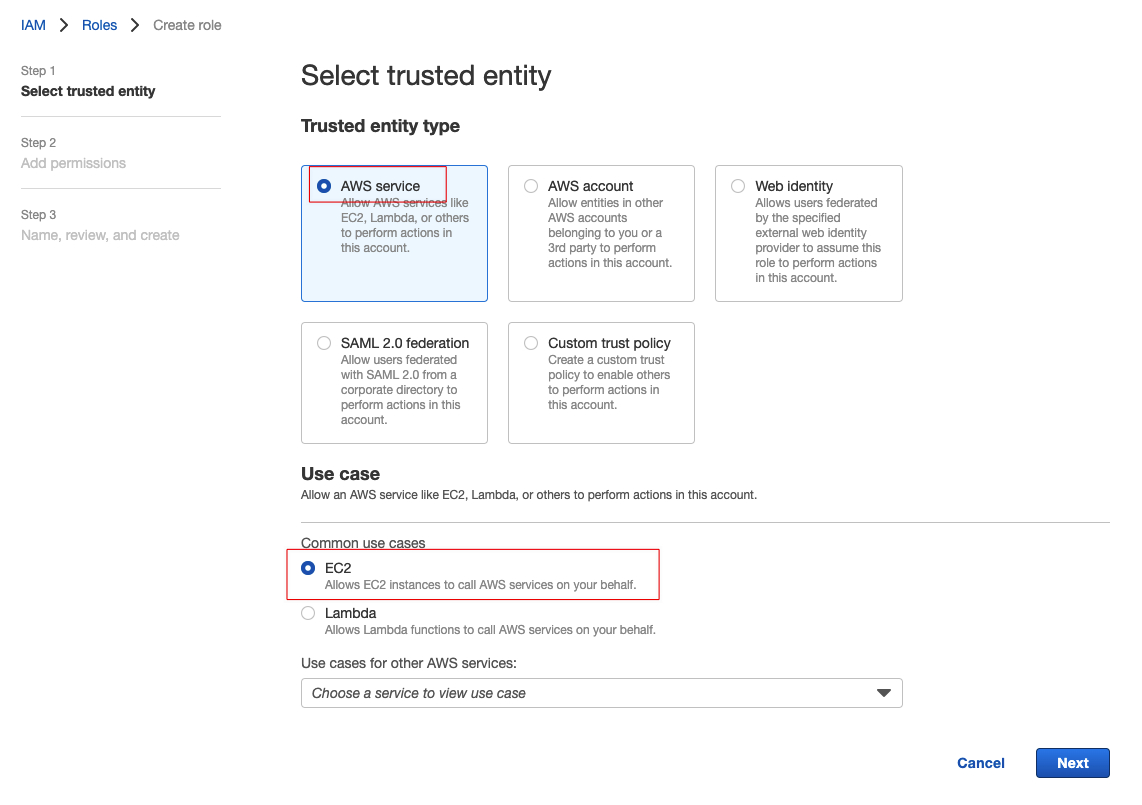
在添加权限的页面上可以输入“Administrator”进行搜索,然后选中结果里面的“AdministratorAccess”即可(注意:此处配置不符合安全最佳实践,生产环境慎用):
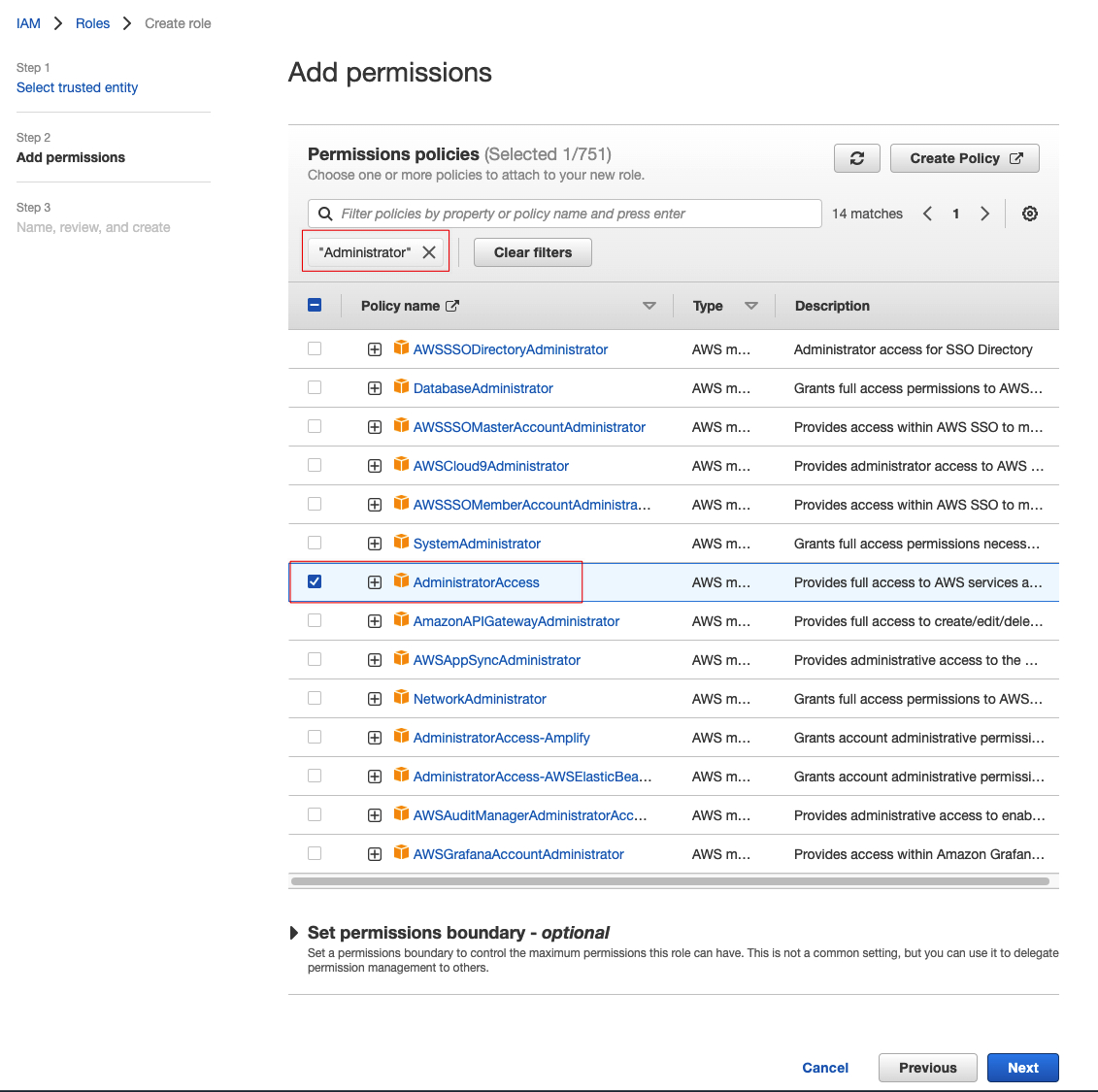
取个名字,例如叫“EC2-for-Cloud9”,然后创建即可。

打开EC2控制台(注意别选错了区域),然后选中对应Cloud9的实例,按下图所示找到修改IAM Role的位置:

选中刚才创建的IAM Role确认即可。

进入到Cloud9的Web控制台,点击右上角的配置按钮:
找到临时Credentials设置,把它关闭(默认是绿色打开的,调整为红色关闭的即可):

至此Cloud9配置完成,因为这是本系列博客的第一篇,所以配置步骤比较详细,后续的博客将做一定的裁剪。
2.3 拉取代码
进入Cloud9环境,执行如下脚步同步代码:
正常情况如下,如果有异常,请留意URL是否正确

2.4 更新Python3.9
在更新Python3.9之前先安装一些系统后续步骤需要用到的依赖包。打开Cloud9环境的命令行执行:
然后更新安装配置,删除临时Crendentials:
如果返回类似如下内容表示权限配置成功(中间的EC2-for-Cloud9是我们之前配置的IAM角色):
接下来使用如下方式安装和更新Python3.9:
大概需要5分钟左右的时间。
3.测试过程
默认情况下,部署的Cloud9的磁盘只有10G,我们需要打包好几个Docker镜像,很容易把磁盘撑爆了,所以通过执行这脚本可以把磁盘调整到例如1000G(其实如果只是做这一个实验,100G以上就可以满足),确保在代码目录下执行(如果使用的是普通SSD硬盘,记得更换对应脚本文件):
默认情况下,我们选择和设置的区域是新加坡区域,如果不确定可以这样显式指定:
3.1配置CDK
通过如下方式配置Python3.9环境
更新CDK的相关包
创建ECR的docker 镜像存储库
然后开始CDK的初始化(要注意的是,一个Region初始化一次即可,不需要重复操作,如下的整个命令是一行,注意复制执行的时候不要折行了):
3.2部署环境
初始化CDK后,然后执行CDK环境合成(大概需要3-5分钟)
bash deploy.sh synth true |
接下来部署文章开头架构图所示的测试环境(大概需要10-20分钟)
bash deploy.sh deploy true |
3.3测试验证
因为我们使用EMR(PySpark)来处理Rosbag解析出来的数据,所以需要创建EMR集群运行相关的角色和权限(如果之前使用过EMR服务,则可以跳过这一步,执行命令时注意折行的问题):
上述部署的EMR集群会自动终止,所以不用担心,直接按如下的脚本准备测试数据即可
因为我们的S3存储桶设置了Lambda触发,所以只要把文件丢上去,就会自动触发流程,流程跑完了就会自动结束和清理环境(如Lambda自动结束,ECS自动结束,EMR自动终止等)。
3.4过程监控
打开Step Functions控制台,可以看到如下所示的状态机(因为我们刚才只上传了一个测试文件,所以每个状态机都只执行了一次,且都执行成功了):
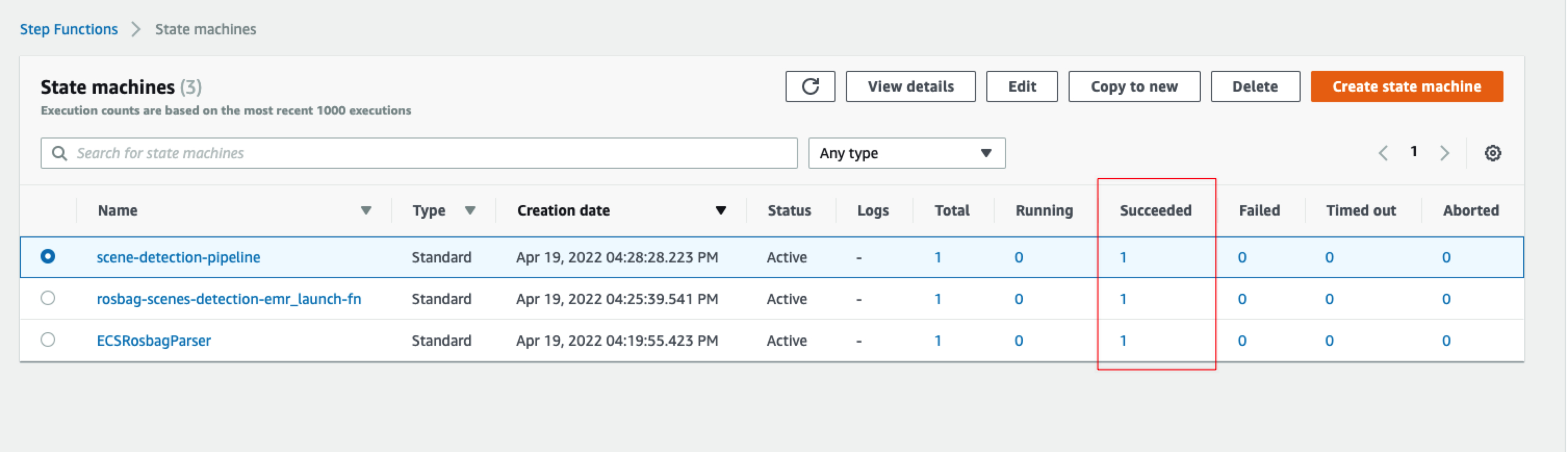
点开里面的状态机(如整个场景检测pipeline的),可以看到具体的步骤和每一步的执行结果(注意:如果中间有某个/些步骤执行失败,可以查看对应的错误日志):
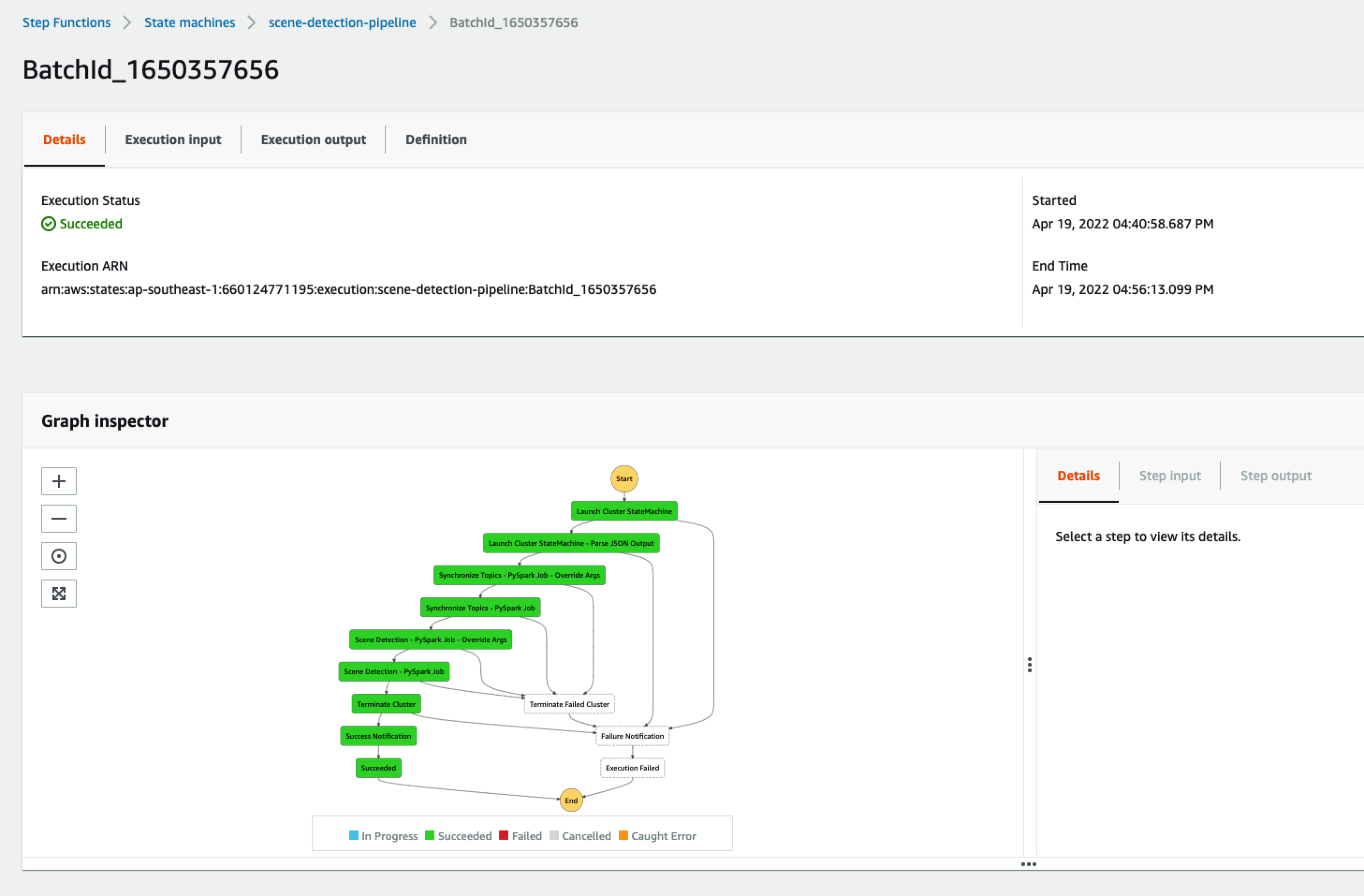
点开例如启动EMR集群的状态机,可以看到对应的流程和执行情况:

打开CloudWatch控制台,选择左边的日志组,然后查看对应的日志组里面的日志输出,可以更好的核对和理解对应处理过程(截图为其中一个):

打开DynamoDB的控制台,即可看到对应的元数据的表,如下图所示:

可以找到对应的元数据信息

打开S3的控制台,会看到多个由“rosbag-scenes”开头的存储桶:

名字里面带input的是我们上传的原始数据:

名字里面带synchronized的桶是我们处理后的数据(后面用Athena来查询结果)

名字里面output的是我们ECS解析出来的原始数据,如下所示:

4.结果查询
4.1配置元数据
打开Glue控制台,选择左边的“crawlers”菜单,然后创建任务,表名可以设置为例如: “tbl_synchronized”,然后选择对应的S3目录

选取结果如下

设置IAM角色的时候,设置一个标识符即可:

然后配置存放的数据库(例如此处为auto1):

其他未截图的部分均使用默认值即可,创建完任务后直接运行它。
4.2查询结果
上述任务运行结束后,打开Athena控制台,选择Query editor(查询编辑器),即可在数据库和表列表里面发现我们刚才爬取的数据库和表:

第一次使用Athena的话需要配置临时存储位置(S3存储桶),否则会收到类似如下的提醒:

点击并配置即可,如下图所示,我们配置到output目录下(选中S3存储桶以后,我们手工添加了/athena目录(因为里面还有别的数据,为了方便区分,当然也可以创建一个新的S3存储桶来单独存放)

然后在SQL查询框例如输入查询SQL,或者点击表名右边的三个点,并选择预览表(Preview Table),即可查询并获得样例数据,如下图所示:

我们的博客内容差不多就到此结束了,感兴趣细节的客户或者读者可以在Cloud9和亚马逊云科技的控制台就各个步骤的细节做深入研究或客户化定制。
5.环境清理
虽然绝大部分分配和使用资源型的服务(如ECS,EMR等)会自动终止资源使用,但是如果客户想手工清除环境的话,可以先清空上述测试过程中创建的S3存储桶里面的数据(以rosbag-scenes开头的S3存储桶,当然手工删除这些存储桶也是可以的),然后在代码目录下执行如下脚本即可(大概需要10分钟):
cdk destroy --all |
参考文档
参考1: 在亚马逊云科技上构建自动驾驶数据湖:
参考2: 自动驾驶数据湖之场景检测:
参考3: 自动驾驶数据湖(二):图像处理和模型训练:
参考4: 自动驾驶数据湖(三):图像处理流程管道:
参考5: 自动驾驶数据湖(四):可视化:
https://aws.amazon.com/cn/blogs/china/autonomous-driving-data-lake-visualization-using-webviz/