亚马逊AWS官方博客
EC2 Spot实例中断引起的AWS Batch任务重试优化
前言
AWS Batch 是一组批量管理功能,可根据用户提交的批处理作业的卷和特定资源需求动态地预置最佳的计算资源(如 CPU优化、内存优化和/或加速的计算实例)数量和类型。AWS Batch 与 EC2 Spot 实例的原生集成意味着与按需定价相比,计算成本可以节省高达 90%。
在量化交易策略的开发中,量化回测任务在运行时需要大量计算的资源,任务运行完成后资源将会被释放。这样的场景非常适合利用AWS Batch服务,利用容器化技术,快速调度计算资源,完成回测任务,并且在任务计算完成后,快速释放资源,节约资源成本。在Blog 基于AWS Batch搭建量化回测系统 中有详细描述,这里不在展开。
Spot实例具有非常好的经济效益性, 在很多场景应用中受到用户的欢迎。但是我们也都注意到,Spot实例有个特点,也就是在Spot实例在市场价格超过用户的竞标价格时,或者在总体资源池不足时,会触发Spot实例资源回收事件。而在量化回测场景中,会导致量化回测的AWS Batch任务失败。这种失败虽然可以通过设置任务的重试次数进行缓解,但是1. 对于用户来说不能区分任务中断的原因是Spot实例的回收还是由于代码本身,如果是代码本身的问题,多次重试其实没有意义,也不利于问题的及时发现。2. AWS Batch的重试次数最多只能重试10次,超过这个次数后还是需要人工介入重新提交。 因此如果有自动化的方式,判断如果任务中断是由于Spot实例终止引起的任务失败,以自动化方式再次重新提交任务,那么可以缓解用户在由于Spot中断而必须手动提交任务上所付出的额外工作量。
本文的目标旨在通过AWS Batch任务的状态变更事件通知,结合Amazon EventBridge和Amazon Lambda,在Lambda中实现任务的再次提交,从而实现任务的自动化重新提交功能。另外,通过修改Spot Fleet请求的目标容量,实现了对Spot实例回收事件的模拟实现,从而在测试环境下验证了本方案的可行性。
前置条件
- 假定您已经有了AWS的海外或者中国区的账号,本文后面的实验在海外us-east-1区域进行的操作。但是本文中所有的服务和功能不限制运行区域。
- 本文假设您已经有了AWS的账号,并且对于通过AWS的控制台进行AWS Batch, Amazon EventBridge, Amazon Lambda, Spot Instance的操作有一定的了解。
- 如果您使用新 AWS 账户或从未用过 EC2 Spot 实例的账户,在您的账户中需要一组 IAM 角色:AmazonEC2SpotFleetRole、AWSServiceRoleForEC2Spot和 AWSServiceRoleForEC2SpotFleet。如果您的 AWS 账户中没有这些角色,请按照此处的说明进行创建。
- 本文还利用您的 AWS 账户的默认 VPC。如果您的账户没有默认 VPC,您可以使用您自己的 VPC。在最后一种情况下,确保您的子网符合此处记录的要求。
方案介绍
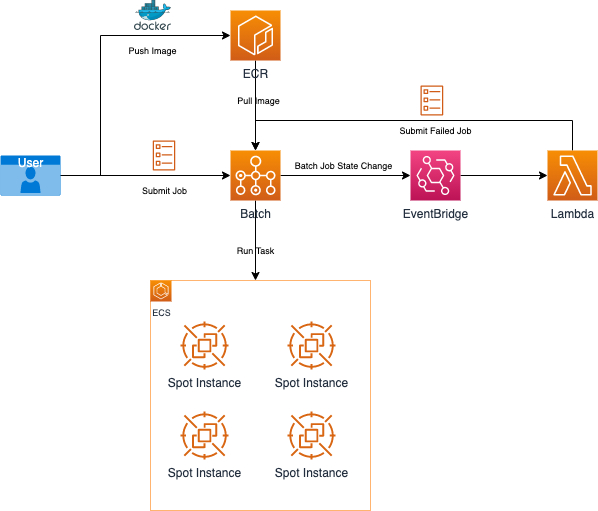
- 基于AWS Batch以及用户自定义的Docker 镜像运行批处理任务,在Blog 基于AWS Batch搭建量化回测系统 中已有详细描述,这里不再展开。
- AWS Batch 的任务状态包括:SUBMITTED,PENDIN,RUNNABLE,STARTING,RUNNING,SUCCEEDED ,AILED。 任务状态的任何变化都会推送状态变更事件到Amazon EventBridge。
- Spot实例回收会导致任务的失败,会产生任务失败的事件。在任务失败事件中,会包含失败任务的原因,以及任务名称、定义、任务队列等相关信息。Spot实例回收引起的任务失败事件示例如下:
- 在Amazon EventBridge的事件规则定义中,增加”status”:”FAILED”过滤,避免对Amazon Lambda函数的无效调用。
- 通过事件任务失败事件触发Amazon Lambda函数,在Lambda函数中再次判断statusReason,并重新提交任务。部分代码片段如下,完整的Lambda函数请参考附录。
实现步骤
第 1 步 创建计算环境
控制台导航到AWS Batch->Compute environments, 选择创建计算环境,进入计算环境创建页面。
选择托管环境类型,以及Service Role。
如果是初次使用Batch,参考文档创建对应Role。

下面的实例配置中:
Provisioning model 选择Spot;
Maximum % on-deman price 保持100不变;

下面的属性中,
Spot fleet role: 如果是初次使用,并在上一步中已经选用了Spot,参考文档创建对应Role;
Allowed Instance Type: 本实验中选的是m5.large。如果您根据自己的容器需要不同配置的计算资源,可以根据需要选择。


网络配置: 选择的是Default的VPC。实际测试中根据我们账户中的VPC进行选择。安全组选择默认安全组。
其他配置保持默认。
第 2 步 创建任务队列
控制台导航到AWS Batch->Job Queues, 选择创建,进入队列创建页面。
输入队列名称。

选中第 1 步中创建的计算环境。

第 3 步创建任务定义
控制台导航到AWS Batch->Job Definitions, 选择创建,进入任务定义创建页面。
Job type选择Single-node。

General Configuration中,
Name:输入名称。
Execution timeout:60000 这里输入到一个较长时间。主要是为了后续模拟的任务会运行较长时间,避免出现超时失败。

Platform compatibility 选择EC2。
Execution role选择已有的ecsTaskExecutionRole. 如果是初次使用Batch。参考文档创建对应Role。

Job Configuration中,
Image 保持默认。
Command syntax 选择Bash。
Command中,输入下面脚本,模拟一个处理任务。

其他配置保持默认,创建任务定义。
第 4 步 创建Lambda函数
控制台导航到Amazon Lambda-> Functions , 选择Create Function, 进入函数创建页面。
选择Author from scratch。

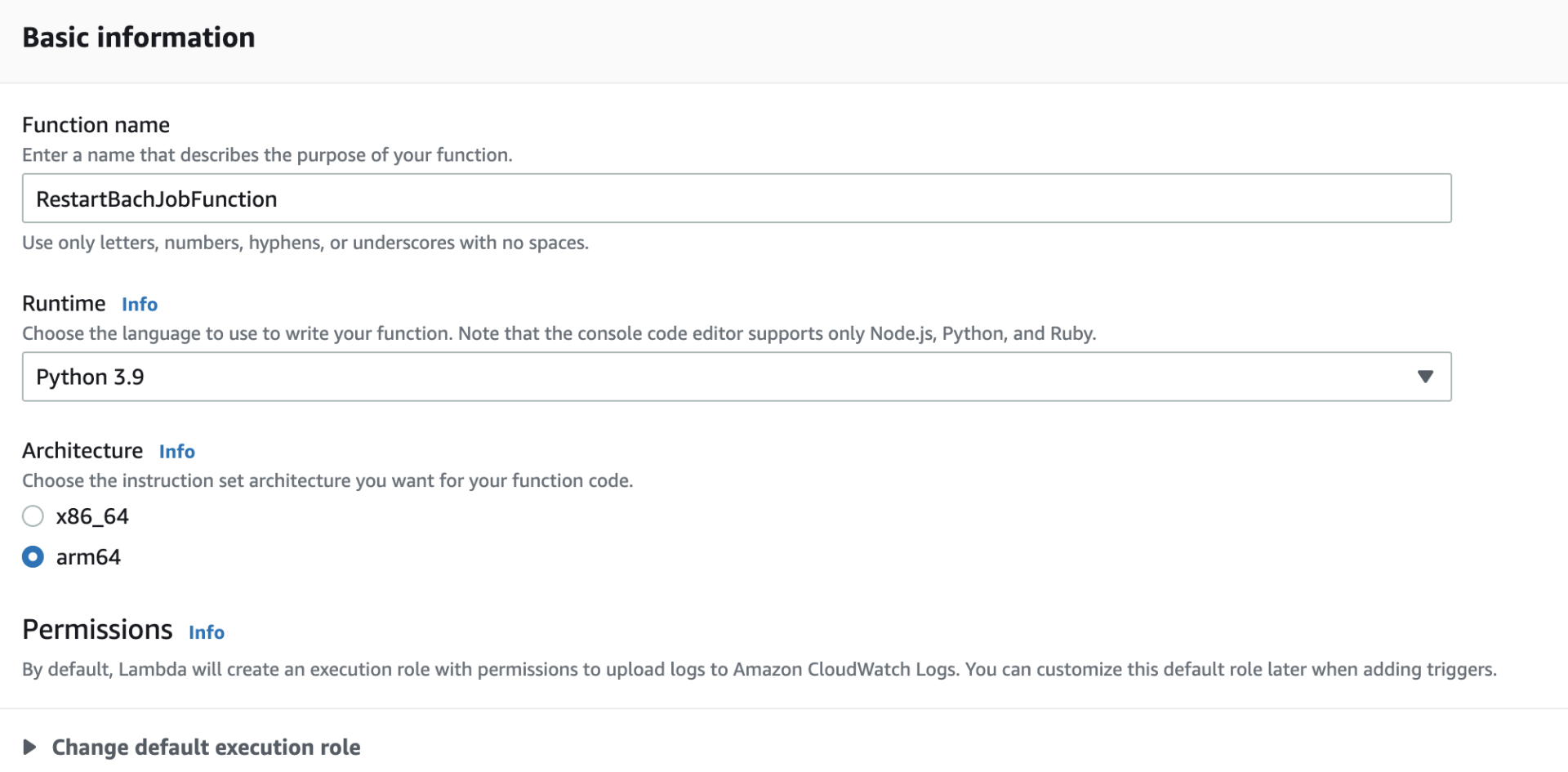
Function name: 输入函数名称。
Runtime: Python 3.9。
Architecture: arm64 Lambda函数支持运行在arm架构的计算环境中,在高频场景中能够节省运行成本,提升运行效率。
Permissions:选择默认创建。
其他不变,创建函数。
函数创建完成后,在Code Source中,拷贝下面附录中的Lambda函数代码到默认生成的代码文件:lambda_function中。
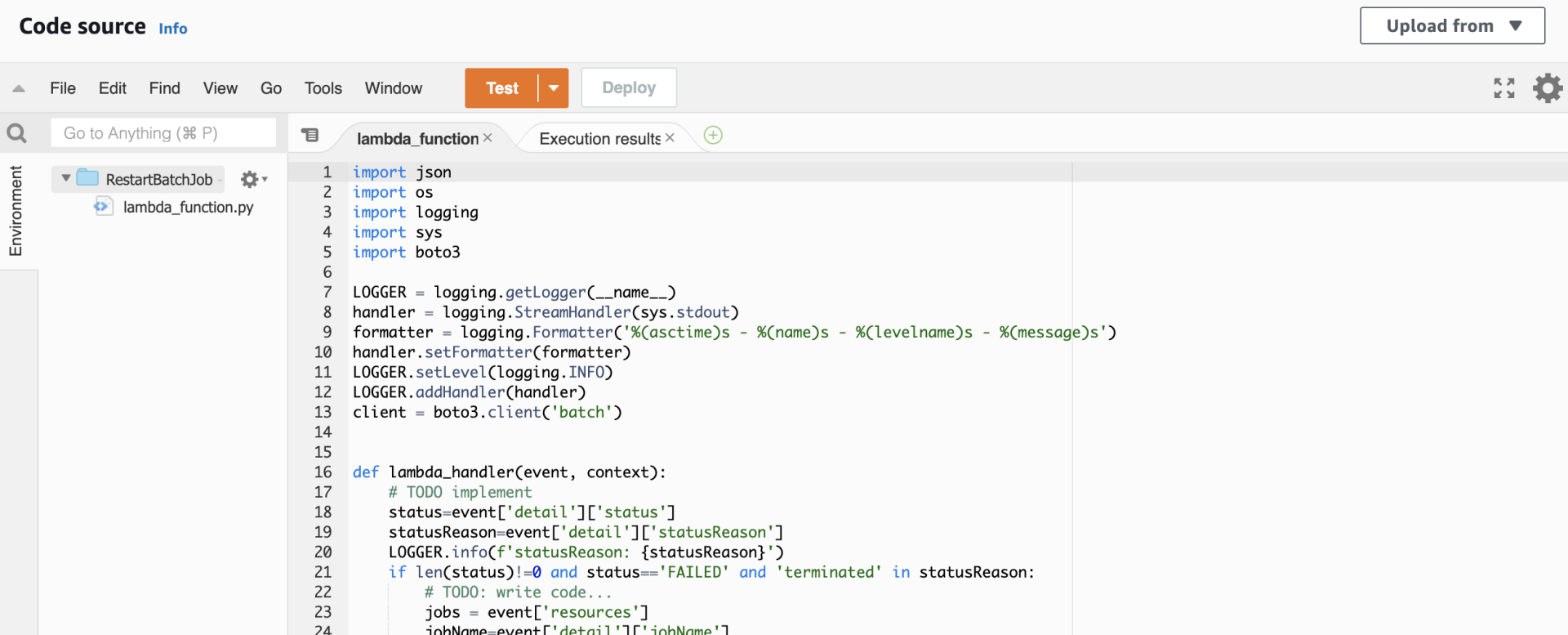
在Lambda函数编辑页面中,选择Configuration页签,Permission选项。

点击Role连接,进入IAM Role页面,通过Add permission功能增加AWS Batch的访问权限,如下所示。

第 5 步 创建 EventBridge 规则
控制台导航到Amazon EventBridge-> Rules , 选择Create Role, 进入规则创建页面。
首先输入规则名称。
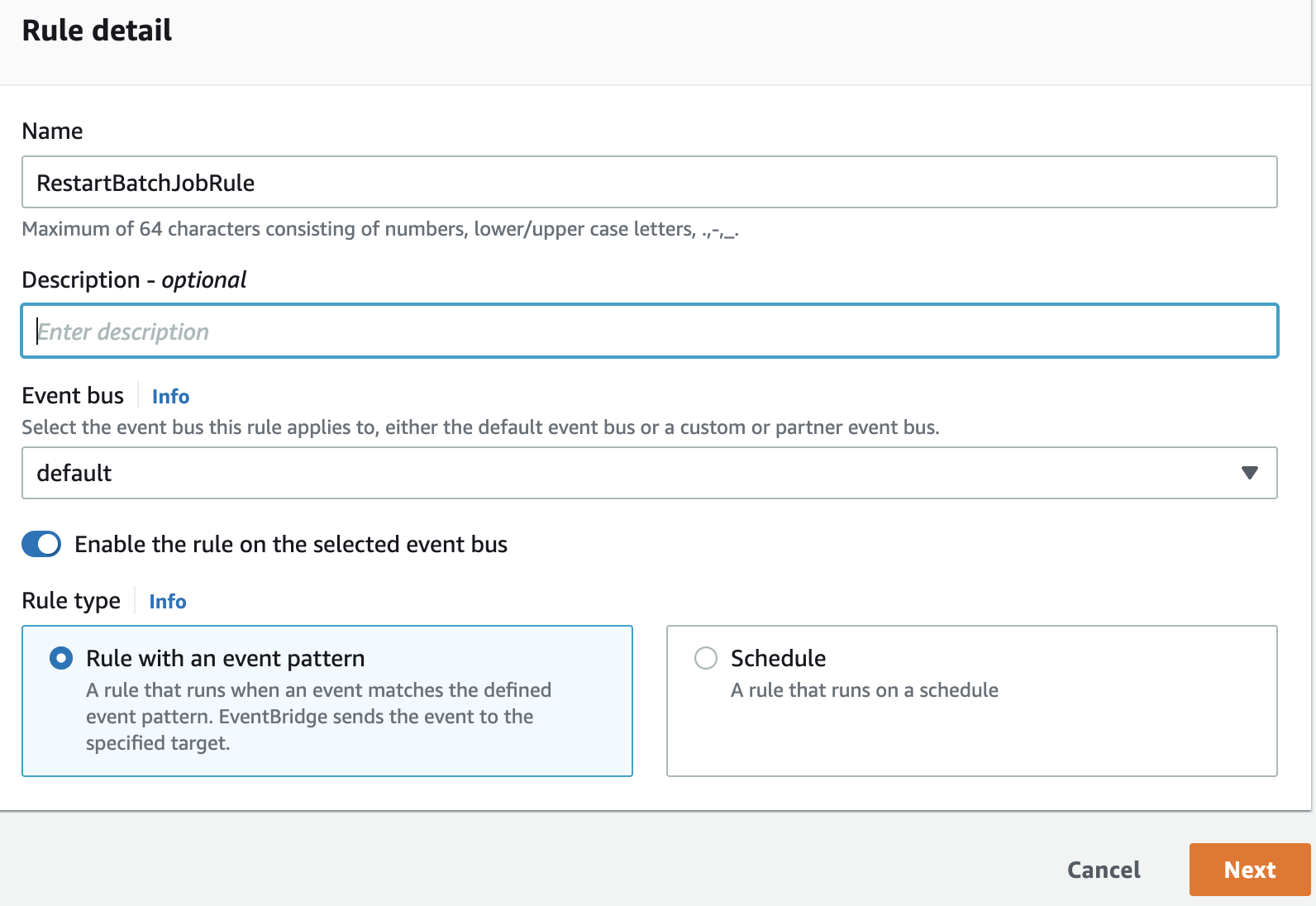
下一步,事件模式中,选择Custom Pattern(JSON editor)。

在输入框中输入如下事件模式。
下一步选择目标中,
Select a target中选择Lambda function。
Function中选择上一步创建的函数。

其他配置保持不变,创建规则。
第 6 步 提交任务
控制台导航到AWS Batch->Jobs , 选择Submit new job,进入提交任务页面。
输入任务名称。
Job definition 选择前面创建的Job 定义。
Job Queue 选择前面创建的队列。
Execution timeout 输入6000,避免任务运行超时错误。

其他保持不变,提交任务。
第 7 步 模拟验证Spot实例回收
AWS Batch后台是通过Spot feet请求创建的Spot实例。为了模拟Spot实例回收的场景,可以通过调整Spot请求的target capacity实现Spot实例的回收模拟。
控制台导航到Amazon EC2-> Spot Requests,选中当前的request。

Action中选择 选择Modify target capacity,进入下面的修改页面。
New target capacity设置为0。 这样,Spot fleet会触发spot实例回收操作。从而模拟真实场景由于其他原因触发的spot实例回收时间。
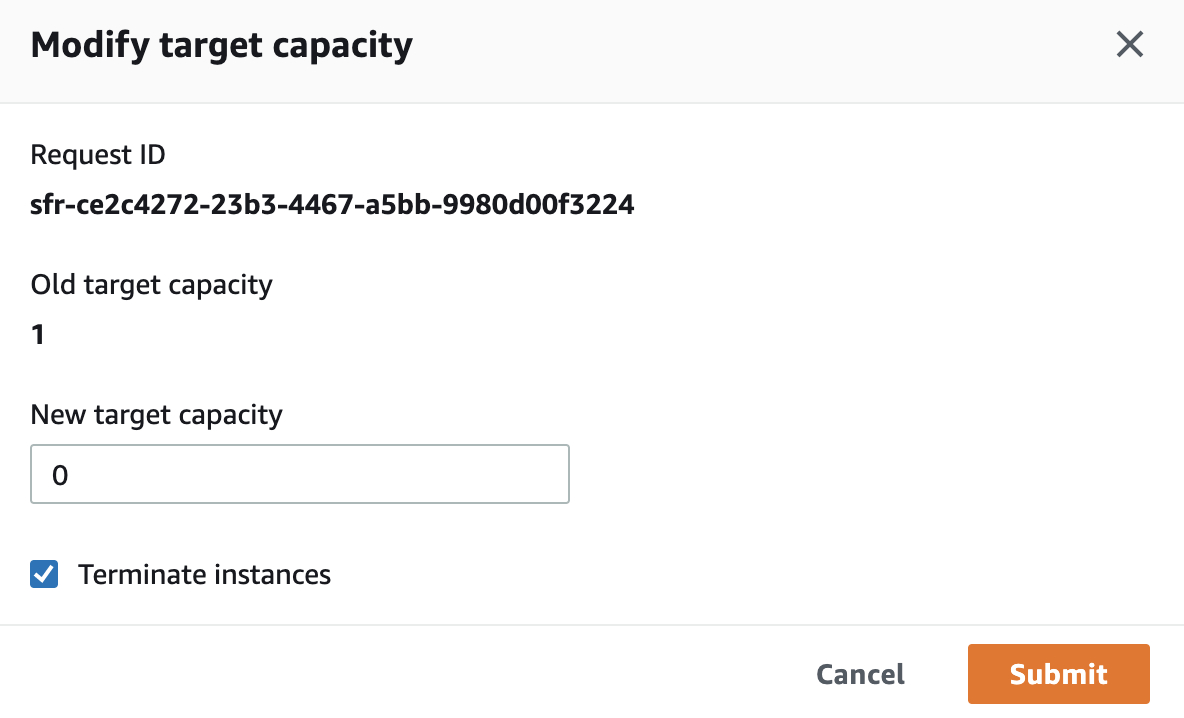
修改完成后,我们可以回到AWS batch->jobs页面,刷新页面,观察Job的状态可以发现。原来的Job在失败一段时间后,会产生一个同样的Job。
总结
通过AWS Batch 的状态变更事件,结合Amazon EventBridge 和 Amazon Lambda函数,可以自动的动态重新提交由于Spot回收引起的失败任务,有效节省任务开发人员在任务运维上的工作量,提升了任务开发人员的工作效率。
Amazon EventBridge 和 Amazon Lambda函数这样的Serverless组合,在类似的很多自动化运维的场景中可以发挥Lambda函数可以定制实现任何逻辑的特点,非常灵活的补充一些原生服务的功能的暂时性不足。 在具体的方案设计中,需要研究并验证相关服务的状态事件格式和数据内容是否匹配业务需求。在Lambda函数开发中,通过AWS 服务完备的API,实现对AWS服务的生命周期自动化管理。
另外,在一些异步事务处理,微服务解耦的应用中,事件驱动的Serverless模式同样适用很多的高并发、高可用的业务场景,能够有效降低业务运维的负担,同时Serverless的完全按调用的付费模式,还能够有效节省计算资源上的成本。
参考
Taking Advantage of Amazon EC2 Spot Instance Interruption Notices
附录
重新提交任务的 Lambda 函数Python代码如下。