亚马逊AWS官方博客
AWS云上混沌工程实践之启动篇
工程师团队最不愿碰到的便是大半夜被电话叫醒,开始紧张地查验问题,处理故障以及恢复服务。也许就是因为睡前的一个很小的变更,因某种未预料到的场景,引起蝴蝶效应,导致大面积的系统混乱、故障和服务中断,对客户的业务造成影响。特别是近几年,尽管有充分的监控告警和故障处理流程,这样的新闻在 IT 行业仍时有耳闻。问题的症结便在于,对投入生产的复杂系统有多少信心。监控告警和故障处理都是事后的响应与被动的应对,那有没有可能提前发现这些复杂系统的弱点呢?
混沌工程 Chaos Engineering
在分布式系统上进行由经验指导的受控实验,观察系统行为并发现系统弱点,以建立对系统在规模增大时因意外条件引发混乱的能力和信心。
混沌工程发展简介
2008年8月, Netflix 主要数据库的故障导致了三天的停机, DVD 租赁业务中断,多个国家的大量用户受此影响。之后 Netflix 工程师着手寻找替代架构,并在2011年起,逐步将系统迁移到 AWS 上,运行基于微服务的新型分布式架构。这种架构消除了单点故障,但也引入了新的复杂性类型,需要更加可靠和容错的系统。为此, Netflix 工程师创建了 Chaos Monkey ,会随机终止在生产环境中运行的 EC2 实例。工程师可以快速了解他们正在构建的服务是否健壮,有足够的弹性,可以容忍计划外的故障。至此,混沌工程开始兴起。
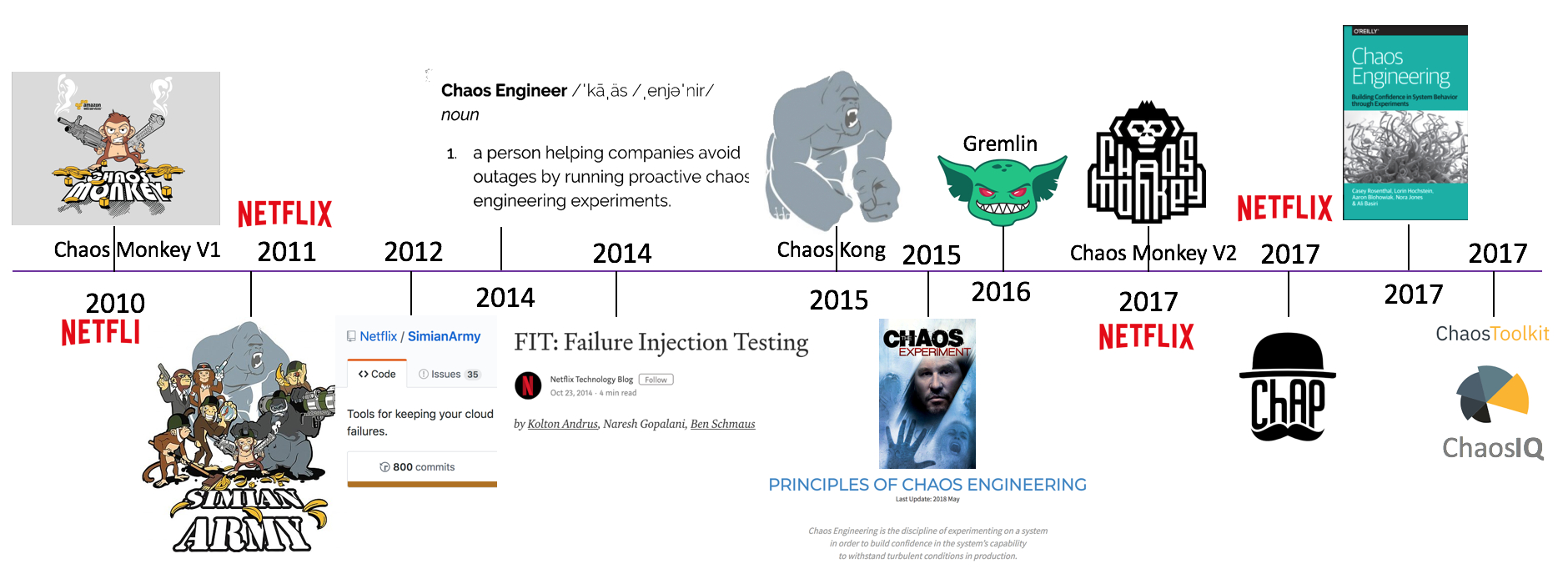
图1 – 混沌工程演进时间线
图1中展示了混沌工程从2010年演进发展的时间线:
- 2010年 Netflix 内部开发了 AWS 云上随机终止 EC2 实例的混沌实验工具: Chaos Monkey
- 2011年 Netflix 释出了其猴子军团工具集: Simian Army
- 2012年 Netflix 向社区开源由 Java 构建 Simian Army,其中包括 Chaos Monkey V1 版本
- 2014年 Netflix 开始正式公开招聘 Chaos Engineer
- 2014年 Netflix 提出了故障注入测试(FIT),利用微服务架构的特性,控制混沌实验的爆炸半径
- 2015年 Netflix 释出 Chaos Kong ,模拟AWS区域(Region)中断的场景
- 2015年 Netflix 和社区正式提出混沌工程的指导思想 – Principles of Chaos Engineering
- 2016年 Kolton Andrus(前 Netflix 和 Amazon Chaos Engineer )创立了 Gremlin ,正式将混沌实验工具商用化
- 2017年 Netflix 开源 Chaos Monkey 由 Golang 重构的 V2 版本,必须集成 CD 工具 Spinnaker 来使用
- 2017年 Netflix 释出 ChAP (混沌实验自动平台),可视为应用故障注入测试(FIT)的加强版
- 2017年 由Netflix 前混沌工程师撰写的新书“混沌工程”在网上出版
- 2017年 Russell Miles 创立了 ChaosIQ 公司,并开源了 chaostoolkit 混沌实验框架
今天,许多公司包括 FANG,都有自己的 Chaos Engineer ,使用某种形式的混沌工程实验,来提高现代架构的可靠性。由于混沌工程的目的是给复杂的分布式系统引入扰动,并观察系统行为,借此发现系统弱点。因此,混沌工程实验中涉及的可行性调研、实验场景和环境的设计与计划、工具的选型和配合方式、系统行为的观测方法、以及找到问题后如何改善系统架构和运维模式,都需要科学的分析和有经验的混沌工程专家指导。根据笔者的观察,多数用户对混沌工程实践踌躇不前,总绕不开下面这几个问题:
问题1:
混沌工程是不是只适合像 FANG 这样技术成熟的大公司,拥有复杂的分布式系统,很强的研发和运维能力?
答:否。混沌工程进行的是探索系统复杂性的开放实验,目的是改善原有的系统架构和运维模式,加强业务服务的健壮性。没有像 FANG 那样复杂的分布式系统,一样需要混沌工程实践来达到健壮性的目的,只是混沌工程设计实施的复杂性不同、实践的成熟度不同:技术成熟的大公司,由于其系统的复杂性更大,无法完全理解透彻其上下游纷繁的依赖关系,因此更需要借助混沌工程实践,并利用自身较强的研发和运维能力,来深入了解系统行为以提高稳定性。另外,从资源获取的角度上看,在云上实施混沌工程实验,对其他公司而言,更加便捷有效。
问题2:
混沌工程实验像 Chaos Monkey 只是杀杀机器而已,运维看看就好了吧?
答:否。回溯混沌工程发展的时间线,业界对混沌工程的理解是逐步深入的。 Netflix 开发的 Chaos Monkey 成为了混沌工程的开端,但混沌工程不仅仅是 Chaos Monkey 这样一个随机终止 EC2 实例的实验工具。随后混沌工程师们发现,终止 EC2 实例只是其中一种实验场景。因此, Netflix 提出了 Simian Army 猴子军团工具集,除了 Chaos Monkey 外还包括:
- Latency Monkey 在 RESTful 客户端到服务器通信中引入随机延迟,以模拟服务降级并测量上游服务是否正确响应。
- Conformity Monkey 在发现不符合最佳实践的实例时将其关闭。
- Doctor Monkey 会在每个实例中运行健康检查,同时也通过其他外部监控指标来检测不健康的实例。一旦检测到不健康的实例,将它们从服务中删除,并且在实例所有者找到问题的原因后终止。
- Janitor Monkey 搜索未使用的资源并按规则处理,以确保AWS上的环境资源有效避免浪费。
- Security Monkey 在发现安全违规或漏洞时,如发现未正确配置的AWS安全组,并终止使用该违规安全组的实例。此外,还会确保所有的 SSL 和 DRM 证书有效且无需续订。
- 10-18 Monkey (l10n-i18n)针对多个区域和国家的客户提供服务的实例,检查有关语言和字符集的配置。
- Chaos Gorilla 模拟了 AWS 可用区域(AZ)的中断,以验证服务是否会自动平衡至可用的 AZ ,而无需人工干预,也不会给用户带来可见的影响。
使用 Simian Army 进行混沌工程实验,看起来似乎已经很完美。类似像 Latency Monkey 的引入,由于服务之间的调用链传递,到最后这个小的扰动到底会引发多大的故障,没有人可以预测。在生产上做这样不可控的实验,是很危险的。随着故障注入测试(FIT)的提出,社区开始关注利用应用架构的特性,特别是微服务架构,来控制实验的爆炸半径,比如 Netflix 使用 Zuul 强大的流量检查和管理功能,将受影响的请求隔离到特定的测试帐户或特定设备,避免100%的混乱。
进一步分析发现, FIT 的执行过程也影响了整个系统的监控指标,即实验群体与其他非实验群体的统计指标混合不可分辨:无法确定实验的进行时间,无法评估其影响是否超过了系统本身的噪音。为了进一步的区分,则需要进行更多更大的实验,这将有可能给用户带来不必要的中断。因此需要对实验集群和非实验群集的流量配比进行精细控制,同时因应无人值守的实验要求,则引入微服务架构中的断路器,如其超出预定义的误差预算,自动结束实验。这就是为何 Netflix 提出了新的 ChAP (混沌实验自动平台)以加强故障注入测试。
综上所述,混沌工程的发展不是一蹴而就的, Chaos Monkey 是其开端,但社区对混沌工程的理解在逐步深入,从对基础设施的扰动( EC2 实例随机终止等),到利用应用网关控制爆炸半径,再到精细化流量配比以区分影响,直至引入断路器实现真正的无人值守。混沌工程9年来的发展,由浅入深,由基础设施演进到应用架构,不是单单运维看看就好。
问题3:
混沌工程实验的概念听着很吸引人,可是不知道从而下手。有没有什么实际可落地的框架和工具呢?
答:笔者有幸参与了混沌工程的革新实践,总结起来对混沌工程的理解有两点特别重要:
- 尽量减少实验的爆炸半径(故障注入测试的引入)
为了确保不会破坏生产业务,工程团队需“精心策划”混沌工程实验。
- 混沌实验不只是测试,而是生成新知识的过程( Chaos Monkey -> Simian Army -> FIT -> ChAP )
混沌工程试验不仅仅是测试系统的一个案例。另一方面,混沌工程是一种产生新知识的方法。正是因为现代软件系统往往太复杂,任何人都无法完全理解它们,所以工程师通过混沌工程实验以揭示系统的更多面。
当然混沌工程实验有其自身的技术门槛,因此必须专家的指导并配以完善的混沌实验框架和工具。此为整个系列的首篇,后面笔者会深入探讨有关混沌工程实验中涉及的可行性调研、实验场景和环境的设计与计划、工具的选型和配合方式、系统行为的观测方法、以及找到问题后如何改善系统架构和运维模式等等问题 – stay tune for next episode!