亚马逊AWS官方博客
基于Amazon Bedrock 上实现 Dynamic Filtering Web Search 与 Web Fetch
摘要:介绍最新的模型API服务端托管工具:Dynamic Filtering (动态过滤) Web Search 与 Web Fetch,以及如何使用亚马逊云科技上服务进行自建。
一、前言
在上一篇博客《使用 Amazon Bedrock + 自建 ECS Docker Sandbox 实现 Agent 程序化工具调用 Programmatic Tool Calling》中,我们介绍了如何通过自建 Docker Sandbox 在 Amazon Bedrock 上实现 Programmatic Tool Calling(PTC),让LLM能够生成 Python 代码来编排工具调用,绕过上下文反复传递,从而大幅降低 Token 消耗(至多达90%)并提升推理准确率。本篇是该《自建生产级Bedrock-Anthropic Message API转接方案》系列的第二篇,介绍最新的模型API服务端托管工具:Dynamic Filtering (动态过滤) Web Search 与 Web Fetch,以及如何使用亚马逊云科技上服务进行自建。
Claude近期推出的 web_search 和 web_fetch 是一种Server-Managed Tools(服务端托管工具)。与传统的 Client-Side Tool(客户端工具)不同,这类工具由模型API 服务端直接执行 —— 客户端只需在请求的 tools 列表中声明工具类型,LLM便会在推理过程中自主调用搜索引擎或抓取网页,将实时信息融入回答。
本文将详细介绍我们如何在自建 Proxy 的中间层实现 Web Search 和 Web Fetch 这两个服务端工具,并结合服务端代码执行沙盒实现同样的Dynamic Filtering功能,使得客户端使用 Anthropic Python SDK 无需任何代码修改,即可在 Bedrock 上获得与官方 API 完全一致的搜索和抓取体验,并且可扩展到其他非Claude模型,如Qwen, Kimi, Minimax等。文章涵盖实现原理、架构设计,以及详细对比验证。
除此之外该方案还有其他额外的益处:
- 通过转接方案接入Claude Code/ Claude Agent SDK仅需更改Base URL,符合官方Message API格式,尽可能的还原CC官方版本行为,例如:通过转接方案,消息请求里会带上一些例如 beta header [“context-management-2025-06-27”] 服务端上下文裁剪工具等,而直连Amazon Bedrock,则不会使用这些header(虽然bedrock已经支持)。
- 还可以按API KEY 自动开启1小时TTL Prompt Cache,更大程度节省综合费用。
二、背景
2.1 Web Search 简介
Web Search 工具提供搜索互联网、获取实时信息的能力。当开发者在请求中声明 web_search 工具后,Claude 可以在推理过程中主动发起搜索查询,获取最新的网页内容,并基于搜索结果生成带有来源引用的回答。
目前Claude提供了两个版本的 Web Search 工具:
| 版本 | 类型标识 | 核心特性 |
| 标准版 | web_search_20250305 | Web 搜索 + 结构化引用(citation) |
| 增强版 | web_search_20260209 | 标准搜索 + Dynamic Filtering(代码执行过滤) |
标准版提供了基础的搜索与引用能力,而增强版在此基础上加入了 Dynamic Filtering (动态过滤)特性,让 Claude 能够通过编写和执行代码来进一步过滤、分析搜索结果,显著提升了复杂查询场景下的回答准确率。
2.2 什么是Dynamic Filtering (动态过滤):搜索结果的智能过滤
Dynamic Filtering 是 Anthropic 于 2026 年 2 月推出的增强搜索能力。根据 Anthropic 官方博客(Improved Web Search with Dynamic Filtering)公布的基准测试数据:
- BrowseComp 基准和DeepsearchQA 基准测试中,平均准确率提升 11%,Token 效率提升 24%.
- BrowseComp 基准:Sonnet 从 33.3% 提升至 46.6%,Opus 从 45.3% 提升至 61.6%
[图1] |
- DeepsearchQA 基准:F1 Score,Sonnet 从 52.6% 提升至 59.4%,Opus 从 69.8% 提升至 77.3%
[图2] |
Dynamic Filtering 的核心思想是:当 Web Search 或 Web Fetch 返回原始结果后,LLM 会自己判断是否需要编写 Python 代码对结果进行过滤、分析和交叉引用,只保留与问题最相关的内容,然后基于精炼后的数据生成最终回答。
这种方法在需要数值计算、数据对比或精确信息提取的场景中尤为有效。例如查询两家公司的财务指标对比时,LLM 可以编写代码从搜索结果中提取具体数字并进行计算,而非依赖模型自身的数值推理能力,从而提高精准性。
2.3 Web Fetch 简介
Web Fetch 允许 Claude 直接抓取指定 URL 的完整页面内容。与Web Search有所不同,两者对比如下:
| 对比维度 | Web Search | Web Fetch |
| 输入 | 搜索关键词(query) | 具体 URL |
| 输出 | 多条搜索结果摘要 | 单个 URL 的完整页面内容 |
| 典型场景 | “搜索 Python 最新版本” | “读取 docs.python.org 的发布说明” |
| 内容深度 | 每条结果的部分内容 | 完整文档内容 |
| 结果数量 | 每次搜索返回 5 条(可配置) | 每次抓取 1 个 URL |
Web Fetch 同样提供标准版(web_fetch_20250910)和增强版(web_fetch_20260209,支持 Dynamic Filtering)。典型应用场景包括:读取技术文档的具体页面、获取 API 参考的详细内容、抓取特定网页进行数据提取等。
2.4 当前的局限
跟PTC (Programmatic Tool Calling) 需要的code_execution工具一样,这2个工具也是服务端工具,目前通过非Anthropic官网 Amazon Bedrock 调用时还无法直接使用 Web Search 和 Web Fetch 这两项能力。特别是新版的动态过滤特性的Web Search和Web Fetch,还依赖于code_execution工具,因此我们基于已有支持PTC的Proxy 层,接入三方搜索引擎弥补这一能力,让 Amazon Bedrock 上的 Claude及其他非Claude模型(如Qwen3,Minimax, Kimi 2.5等) 也能具备带动态过滤的搜索和网页抓取能力。
三、整体架构概览
3.1 核心思路
自建Proxy服务作为中间层,拦截包含 server-managed tool 声明的请求,将 Bedrock 无法识别的工具类型(如 type: “web_search_20250305″)替换为标准的 tool definition(包含 name、description、input_schema 字段),再通过 Agentic Loop(代理循环) 自行编排搜索或抓取的执行过程——包括调用 Bedrock 模型、调用外部搜索/抓取提供商获取真实数据,以及将结果注入对话上下文后继续推理——最终将整个多轮执行过程的最终结果组装为与 Anthropic 官方 API 完全一致的响应格式,对客户端完全透明。
3.2 架构总览
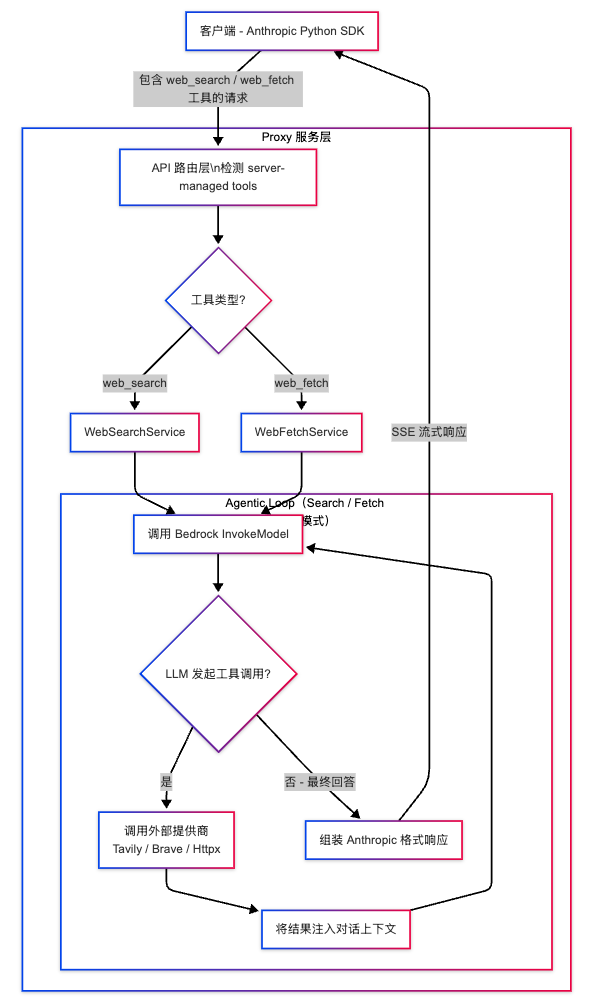
[图3] |
3.3 关键设计说明
1. 客户端透明
使用 Anthropic Python SDK 的客户端无需任何代码修改。Proxy 对外暴露与 Anthropic 官方 API 完全相同的端点和响应格式,包括流式事件类型、引用(citation)字段结构以及 stop_reason 语义,使得现有代码可以零改动迁移至 Bedrock。
2.工具替换策略
将 server-managed tool(如 type: "web_search_20250305")替换为标准的 tool definition(包含 name、description、input_schema 三个字段),让 Bedrock InvokeModel API 能正常处理请求。Claude 模型本身理解这些工具的语义,因此仅凭标准定义即可正确生成工具调用指令,无需修改模型行为。
3.4 支持的工具版本
| 工具类型 | 类型标识 | 特性 |
| Web Search 标准版 | web_search_20250305 | Web 搜索 + 引用 |
| Web Search 增强版 | web_search_20260209 | 搜索 + Dynamic Filtering |
| Web Fetch 标准版 | web_fetch_20250910 | URL 抓取 + 引用 |
| Web Fetch 增强版 | web_fetch_20260209 | 抓取 + Dynamic Filtering |
四、Web Search 实现
本节深入剖析 Web Search 功能的实现细节,包括工具替换策略、Agentic Loop 编排逻辑、搜索提供商方案、Citations引用系统。
4.1 工具替换
Bedrock 的 InvokeModel API 要求每个工具必须包含标准的 name、description 和 input_schema 字段。Anthropic 的 server-managed tool 声明(如 type: "web_search_20250305")不符合这一格式,直接发送会导致验证错误。
Proxy 在每次调用 Bedrock 之前,会将请求中的 web_search 工具声明替换为标准的 tool definition,其他用户自定义工具则原样透传。
客户端发送给 Proxy的工具定义:
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": ["example.com"]
}Proxy进行内部替换后再发送给 Bedrock:
{
"name": "web_search",
"description": "Search the web for current information. Returns search results with titles, URLs, and content snippets.",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "The search query"}
},
"required": ["query"]
}
}替换逻辑还会额外追加 bash_code_execution 工具,用于 Dynamic Filtering 代码执行(见第五节)。
这一替换对客户端完全透明—-Proxy 内置了对 web_search 工具语义的理解,与此同时,max_uses、allowed_domains、blocked_domains 等配置参数被 Proxy 保存在 WebSearchToolDefinition 结构中,在 Agentic Loop 执行阶段由 Proxy 负责这些约束条件,而不是传给 Bedrock。
4.2 Agentic Loop 核心编排
Agentic Loop 是实现服务端 Web Search 功能的核心,负责在 Proxy 层完成多轮推理与工具执行的编排,对客户端完全透明。
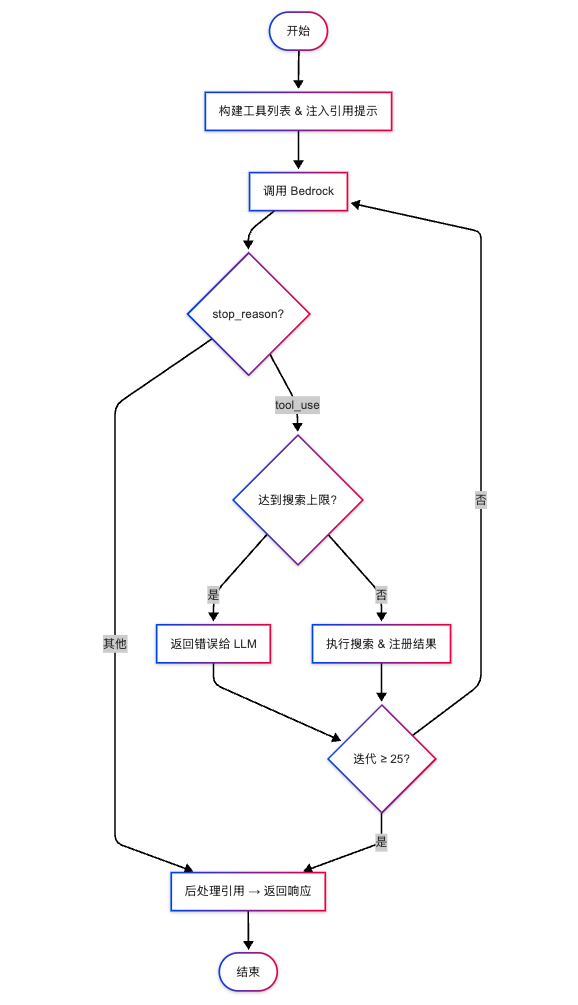
[图4] |
流程说明:
1. 构建工具列表 → 替换 web_search 工具,注入Citations (引用系统)提示
2. 调用 Bedrock InvokeModel(非流式模式)
3. 检查 stop_reason:
-
- 若
stop_reason == tool_use→ 查找 web_search 工具调用 → 检查是否超出max_uses限制- 若已超限 → 返回
max_uses_exceeded错误给 LLM - 若未超限 → 调用搜索提供商 → 构建带编号的搜索结果 → 注册到
result_registry→ 追加tool_result到消息历史
- 若已超限 → 返回
- 若
stop_reason != tool_use→ 后处理引用标记,组装最终响应 → 结束
- 若
4. 检查迭代次数:若 iteration >= 25 → 强制终止;否则回到步骤 1
Token 累计
每次迭代的 input_tokens 和 output_tokens 均会累加到 total_input_tokens / total_output_tokens,确保最终响应中的 usage 字段反映整个多轮推理过程的实际 Token 消耗,与 Anthropic 官方 API 的计费方式保持一致。
4.3 搜索提供商
Proxy 通过抽象基类 SearchProvider 统一封装不同的搜索后端,使得上层 Agentic Loop 代码与具体搜索服务解耦。目前支持以下2种搜索提供商:
TavilySearchProvider(默认)
Tavily 是专为 AI 应用场景设计的搜索引擎,返回的内容经过清洗和结构化处理,非常适合作为 LLM 的上下文输入。
核心特性:
- 使用
tavily-pythonSDK,设置search_depth: "advanced"以获取更丰富的页面内容 - 原生支持
include_domains和exclude_domains参数,可直接传入域名白名单/黑名单,无需额外处理
BraveSearchProvider(备选)
Brave Search 提供独立于 Google/Bing 的搜索索引
域名过滤实现:Brave Search API 不直接支持域名过滤参数,因此 Proxy 通过在查询字符串中注入 site: 前缀来实现白名单过滤:
if allowed_domains:
site_filter = " OR ".join(f"site:{d}" for d in allowed_domains)
search_query = f"({site_filter}) {query}"对于黑名单过滤(blocked_domains),则交由后续的 DomainFilter 在搜索结果上进行二次过滤。
二次域名过滤
无论使用哪个提供商,Proxy 在搜索结果返回后均会调用 __ICODE__DomainFilter__/ICODE__ 进行二次过滤,作为最终的安全保障。DomainFilter 支持子域名匹配(docs.__ICODE__example.com__/ICODE__ 可以被 example.com 规则匹配),确保域名过滤行为的一致性。
4.4 Citations 引用
Anthropic 官方 API 在返回 Web Search 结果时,会将 Claude 的回答拆分为多个 text 块,每块附带一个 citations 数组,精确标注回答中每句话所引用的来源 URL 和原始内容片段。
Proxy 通过三步机制在 Bedrock 上还原这一行为。
三步引用机制
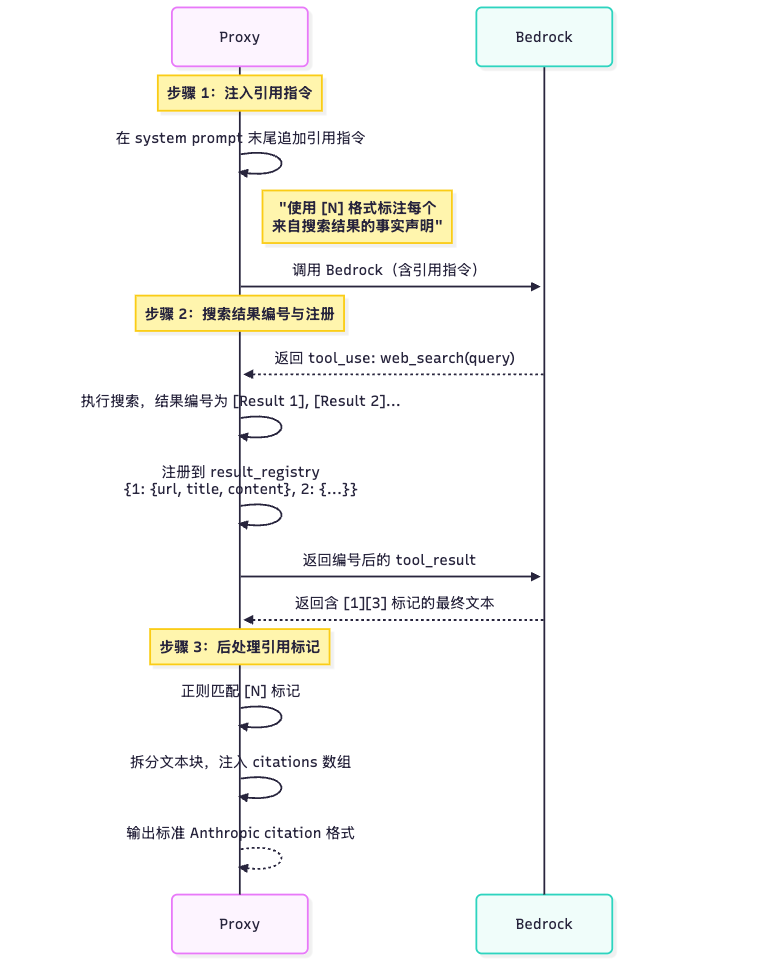
[图5] |
步骤 1:系统提示注入
在每次 Bedrock 调用前,Proxy 向 system prompt 末尾追加引用指令,要求 Claude 在引用搜索结果时使用 [N] 格式标注来源编号:
“When you use web search results to answer questions, you MUST cite sources using numbered references in square brackets. After each factual claim based on a search result, append the result number like this: ‘Python 3.13 was released in October 2024 [1].'”
步骤 2:搜索结果编号与注册
将搜索结果传给 LLM 时,每条结果添加 [Result N] 前缀,并注册到 result_registry(一个以 1 为起始下标的字典),记录每条结果的 url、title 和 content。多轮搜索中,编号在整个会话内累积递增,避免引用混淆。
步骤 3:后处理引用标记
Claude 返回的最终文本中包含如 [1]、[3]、[1][3] 这样的引用标记。通过正则表达式定位所有标记的位置,将文本拆分为多个片段,每个引用标记前的文本片段附带对应的 citations 数组:
最终输出的 citation 格式与 Anthropic 官方 API 完全一致:
{
"type": "text",
"text": "Python 3.13 was released in October 2024",
"citations": [{
"type": "web_search_result_location",
"url": "https://docs.python.org/3/whatsnew/3.13.html",
"title": "What's New In Python 3.13",
"encrypted_index": "MQ==",
"cited_text": "Python 3.13 is the latest stable release of the Python programming language, with a mix of changes to the language, the implementation..."
}]
}其中 encrypted_index 是对结果编号(整数)的 Base64 编码,cited_text 取自来源内容的前 150 个字符。
五、Web Fetch 实现
Web Fetch 的实现完全遵循 Web Search 的 Agentic Loop 模式,共享工具替换、引用系统和 Agentic Loop等核心机制——这些机制在第三节已有详细介绍,本节不再重复。
两者的 Proxy 编排逻辑在结构上高度一致:都在请求入口处将客户端声明的工具类型替换为 Bedrock 可识别的标准 tool definition,都通过相同的 Agentic Loop 驱动多轮推理,都在响应组装阶段进行 Tool ID 前缀转换和引用后处理。
5.1 工具替换
Web Fetch 则将 type: "web_fetch_20250910" 或 type: “web_fetch_20260209” 替换为接受 url 参数的标准 tool definition。
Web Fetch 替换后的 tool definition:
{
"name": "web_fetch",
"description": "Fetch the content of a specific URL. Returns the full page content as plain text.",
"input_schema": {
"type": "object",
"properties": {
"url": {"type": "string", "description": "The URL to fetch"}
},
"required": ["url"]
}
}5.2 Fetch 提供商
与 Web Search 的 SearchProvider 体系类似,Web Fetch 通过抽象基类 FetchProvider 统一封装不同的 URL 抓取后端,使 Agentic Loop 与具体抓取实现解耦。
目前提供两种实现:HttpxFetchProvider(默认)和 TavilyFetchProvider。
HttpxFetchProvider(默认,无需 API Key,跟官方保持一致)
HttpxFetchProvider 是 Web Fetch 功能的默认实现,无需任何外部 API Key,直接使用 Python 标准生态完成 URL 抓取与内容提取,是零依赖部署的首选方案。
核心处理流程分为三个阶段:
阶段一:URL 验证
在发出任何网络请求前,首先对目标 URL 进行格式检查:必须以 http:// 或 https:// 开头,且总长度不超过 250 个字符。不合法的 URL 在此阶段即被拒绝,避免无效的网络请求。
阶段二:HTTP 请求
使用 httpx.AsyncClient 发起 GET 请求,配置 follow_redirects=True 以自动处理 301/302 等跳转,并设置合理的超时时间。响应的 Content-Type 头部决定后续的内容处理策略。
阶段三:内容处理(按 Content-Type 分支)
| Content-Type | 处理策略 |
| text/html | 完整 HTML 解析管道(见下文) |
| application/pdf | base64 编码后作为二进制数据返回 |
| text/*、application/json、text/csv | 直接返回原始文本 |
Proxy 将 HTML 清洗为纯文本,供 LLM 读取:
1. 提取 `<title>` 作为文档标题
2. 移除 `<script>`、`<style>` 标签及 HTML 注释
3. 将块级元素(`<p>`、`<div>`、`<h1>`–`<h6>` 等)转为换行符,保留段落结构
4. 移除剩余 HTML 标签,解码 HTML 实体(`&` → `&`)
5. 压缩连续空白,按 `max_content_tokens` 截断,控制 Token 消耗
HttpxFetchProvider 零外部依赖——整个抓取和清洗流程仅依赖 Python 标准库和 httpx,无需注册任何第三方服务或配置 API Key,使用成本较低。
TavilyFetchProvider(可选,需付费 API Key)
TavilyFetchProvider 调用 Tavily 的 Extract API(/extract 端点),由 Tavily 服务端负责完整的网页内容提取。与 HttpxFetchProvider 相比,Tavily 对 JavaScript 渲染页面和反爬机制有更好的兼容性,适用于需要处理动态内容的场景。但该方案需要 Tavily 的付费 API Key,且引入了外部服务依赖。
5.3 Web Fetch 结果格式
Web Fetch 的结果采用 Anthropic document block 格式,与官方 API 类型完全对应。以下是一个完整的结果示例:
{
"type": "web_fetch_tool_result",
"tool_use_id": "srvtoolu_01Abc...",
"content": {
"type": "web_fetch_result",
"url": "https://docs.python.org/3/whatsnew/3.13.html",
"retrieved_at": "2026-03-03T08:30:00Z",
"content": {
"type": "document",
"source": {
"type": "text",
"media_type": "text/plain",
"data": "What's New In Python 3.13\n..."
},
"title": "What's New in Python 3.13"
}
}
}对于 PDF 内容,source.type 变为 "base64",media_type 为 "application/pdf",data 字段包含 base64 编码后的 PDF 二进制数据,Claude 可直接解析 PDF 文档内容。
5.4 Web Search和Web Fetch的对比差异如下:
| 维度 | Web Search | Web Fetch |
| citations激活方式 | 始终启用 | 按需启用(citations: {enabled: true}) |
| 引用类型 | web_search_result_location | char_location |
| 定位模型 | URL 级别(指向搜索结果 URL) | 字符级别(指向文档内字符范围) |
| 核心字段 | url, title, encrypted_index | document_index, start_char_index, end_char_index |
| 文档元数据 | 无 | document.citations = {enabled: true} |
| 编号前缀 | [Result N] | [Document N] |
| cited_text | 来源内容前 150 字符 | 来源内容前 150 字符 |
六、实现Dynamic Filtering 关键 —— 代码沙箱执行
6.1 实现机制
工具注入
当 Proxy 在工具替换阶段检测到请求中包含 __ICODE__web_search_20260209__/ICODE__ 或 __ICODE__web_fetch_20260209__/ICODE__ 类型的工具声明时,除了将其替换为标准的 web_search 或 web_fetch tool definition 之外,还会额外追加一个 bash_code_execution 工具定义:
{
"name": "bash_code_execution",
"description": "Execute a bash command to process or filter data. Use this to write Python or shell scripts that filter, sort, or analyze the web search results. The command runs in a secure sandbox.",
"input_schema": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "The bash command to execute (e.g., python3 -c '...')"
},
"restart": {
"type": "boolean",
"description": "Whether to restart the shell before executing (default: false)"
}
},
"required": ["command"]
}
}这使得 LLM 在获取搜索或抓取结果后,可以选择调用 bash_code_execution 工具来编写并执行代码,对数据进行二次处理。
执行流程
在 Agentic Loop 中,Proxy 同时监听 web_search(或 web_fetch)和 __ICODE__bash_code_execution__/ICODE__ 两种工具调用。当 Claude 发起 bash_code_execution 调用时,Proxy 将命令发送到 Docker 沙箱中执行,并将 stdout/stderr 作为工具结果注入对话上下文,供 Claude 在下一轮推理中使用。
以下时序图展示了一个典型的 Dynamic Filtering 流程——用户查询两家公司的市盈率对比,LLM 先搜索获取原始数据,再通过代码执行提取和计算关键指标:
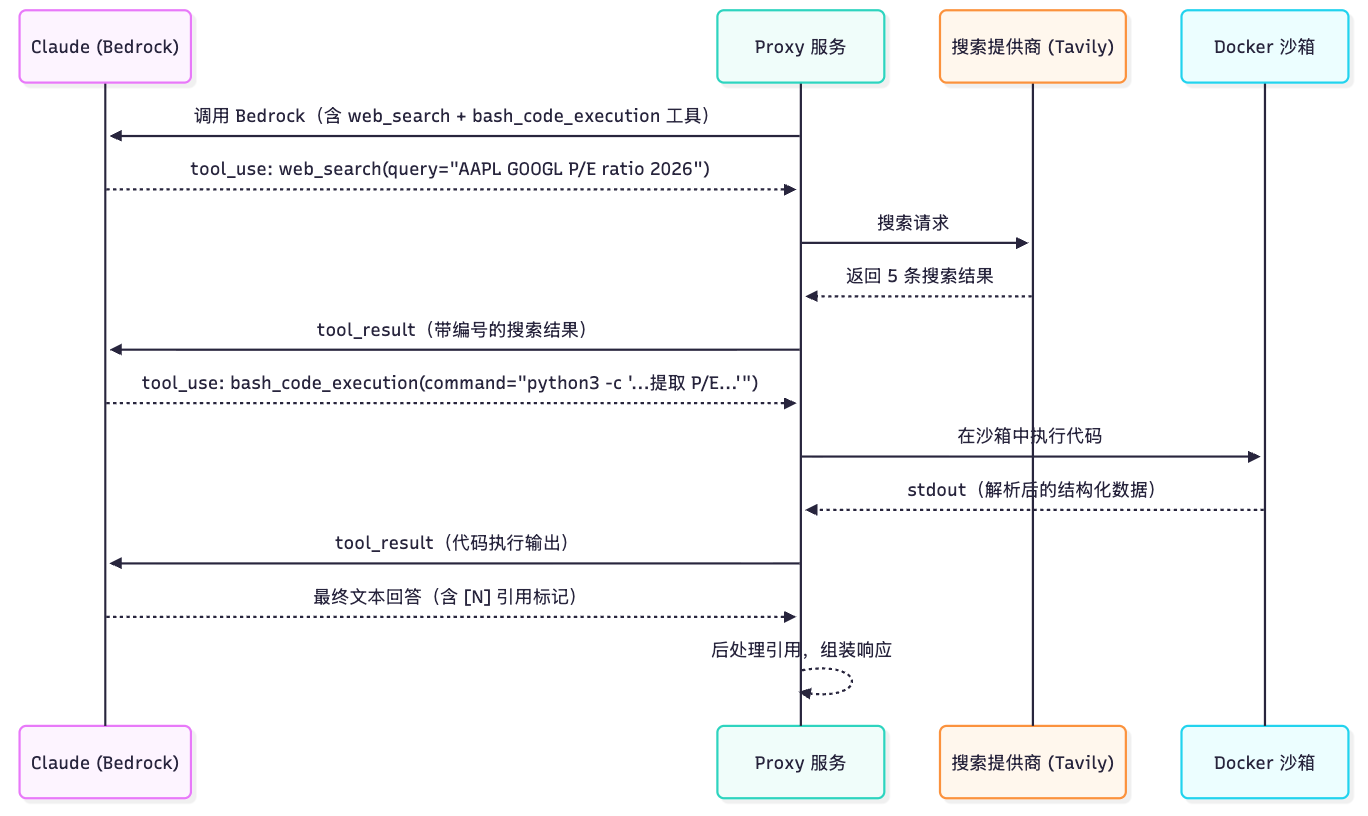
[图6] |
沙箱复用
Dynamic Filtering 的代码执行沙箱复用了我们在上一篇博客《使用 Amazon Bedrock + 自建 ECS Docker Sandbox 实现 Agent 程序化工具调用 Programmatic Tool Calling》中详细介绍的 Docker 沙箱基础设施。沙箱提供以下安全保障:
- 网络隔离(
network_disabled=True):禁止容器内的任何网络访问 - 权限限制(
security_opt=["no-new-privileges"],cap_drop=["ALL"]):防止权限提升 - 资源限制:内存上限(默认 256MB)和 CPU 限制,防止资源滥用
读者可参考上一篇博客了解 Docker 沙箱的完整实现细节,包括容器创建、文件注入(put_archive 方式避免 Docker-in-Docker 绑定挂载问题)和会话管理等内容。
与 PTC 沙箱的关键差异
尽管复用了相同的沙箱基础设施,Dynamic Filtering 的执行模式与 PTC(Programmatic Tool Calling)存在以下区别:
| 对比维度 | PTC 沙箱 | Dynamic Filtering 沙箱 |
| 执行模式 | 暂停/恢复(pause/resume) | 一次性执行(one-shot) |
| 工具调用 | 代码中可调用外部工具,沙箱暂停等待客户端返回结果 | 代码仅处理已有数据,不调用外部工具 |
| 交互方 | 沙箱 ↔ 客户端(工具结果由客户端执行并返回) | 沙箱 → Proxy(输出直接返回给 Proxy) |
6.2 响应格式
Dynamic Filtering 在响应中引入了两种专属的content block类型,均遵循 Anthropic 官方 API 的格式规范。
server_tool_use content block ——Claude 发起的代码执行调用:
{
"type": "server_tool_use",
"id": "srvtoolu_01Xyz...",
"name": "bash_code_execution",
"input": {
"command": "python3 -c \"import json; data = [...]; print([d for d in data if 'P/E' in d])\""
}
}
bash_code_execution_tool_result content block——沙箱执行结果:
{
"type": "bash_code_execution_tool_result",
"tool_use_id": "srvtoolu_01Xyz...",
"content": {
"type": "bash_code_execution_result",
"stdout": "===== AAPL vs GOOGL =====\nAAPL P/E: 33.42\nGOOGL P/E: 28.10\nDifference: 5.32",
"stderr": "",
"return_code": 0
}
}这两种content block类型与 server_tool_use(web_search)和 web_search_tool_result 一样,都会包含在最终响应的 content 数组中,客户端可以通过检查 type 字段来区分不同类型的block,完整还原 Claude 从搜索到代码过滤再到生成回答的全过程。
七、对比验证:Bedrock vs 官方 API
为了验证 Proxy for Bedrock 实现的功能正确性和格式兼容性,我们设计了一组对比测试,分别针对 Web Search Dynamic Filtering 和 Web Fetch Dynamic Filtering 两个核心场景,将 Bedrock与 Anthropic 官方 API 的响应进行逐项对比。
7.1 测试方法
所有测试使用相同的模型(claude-sonnet-4-6)和相同的工具版本(web_search_20260209 / web_fetch_20260209,均启用 Dynamic Filtering)。对于每个测试场景,我们向Bedrock和 Anthropic 官方 API 发送完全相同的 prompt 和工具配置,然后从以下维度进行对比:
- Token 消耗:
input_tokens和output_tokens的差异幅度 - Agentic Loop 行为:搜索查询内容、迭代次数、工具调用序列是否一致
- Dynamic Filtering 结果:代码执行是否被正确触发,计算结果是否一致
- 响应格式兼容性:block types、ID 前缀(
srvtoolu_)、citation 格式、usage字段结构等是否完全匹配 - 数据准确性:最终提取的数据和分析结论是否一致
7.2 Web Search Dynamic Filtering 对比
测试场景: “Compare the current stock prices and P/E ratios of AAPL and GOOGL. Which one has a better P/E ratio?”
这是一个典型的需要数值提取和计算的复杂查询,能够充分验证 Dynamic Filtering 的搜索、代码执行和数据分析全链路。
基本指标对比
| 指标 | 官方 API | Proxy (Bedrock) | 差异 |
| input_tokens | 18,521 | 18,426 | -0.50% |
| output_tokens | 1,373 | 1,420 | 0.034 |
| web_search_requests | 2 | 2 | 相同 |
| server_tool_use blocks | 3 | 3 | 相同 |
| bash_code_execution | 1 | 1 | 相同 |
| stop_reason | end_turn | end_turn | 相同 |
Token 消耗差异在 4% 以内,属于模型生成的自然波动范围。两者的工具调用次数和类型完全一致,说明内部Agentic Loop 的编排行为是一致的。
搜索行为对比
两者生成了完全相同的搜索查询:
1. AAPL current stock price and P/E ratio 2025
2. GOOGL current stock price and P/E ratio 2025
核心数据源(fullratio.com、macrotrends.net、yahoo finance)在两端保持一致,部分次要来源因搜索引擎返回顺序的不确定性略有差异——这是搜索引擎本身的特性,与 Proxy 实现无关。
Dynamic Filtering 计算结果
两者均正确触发了 1 次 bash_code_execution,Claude 编写 Python 代码从搜索结果中提取股价和市盈率数据,并进行计算。最终结果完全一致:
| 指标 | 官方 API | Proxy | 一致性 |
| AAPL Stock Price | $264.72 | $264.72 | 完全一致 |
| AAPL P/E Ratio | 33.42 | 33.42 | 完全一致 |
| GOOGL Stock Price | $306.52 | $306.52 | 完全一致 |
| GOOGL P/E Ratio | 28.1 | 28.1 | 完全一致 |
| 结论 | GOOGL P/E 更低 | GOOGL P/E 更低 | 完全一致 |
格式兼容性
| 特性 | 兼容性 |
| server_tool_use ID 前缀 (srvtoolu_) | 完全一致 |
| Citation 类型 (web_search_result_location) | 完全一致 |
| Citation 字段 (url, title, cited_text, encrypted_index) | 完全一致 |
| bash_code_execution_result 格式 | 完全一致 |
| usage.server_tool_use 字段 | 完全一致 |
响应的 JSON 结构在所有关键字段上与 Anthropic 官方 API 保持 100% 兼容,客户端代码无需任何适配即可正确解析 Proxy 返回的响应。
7.3 Web Fetch Dynamic Filtering + Citations 对比
测试场景: “Please fetch the content at https://httpbin.org/html and count how many times ‘hammer’ appears”
该测试抓取 httpbin.org 提供的 Herman Melville《Moby-Dick》HTML 页面片段,要求 Claude 统计其中 “hammer” 一词的出现次数,并启用 citations 引用功能(citations: {enabled: true})。这一场景覆盖了 Web Fetch 的完整链路:URL 抓取、HTML-to-text 转换、代码执行统计以及字符级引用标注。
基本指标对比
| 指标 | 官方 API | Proxy (Bedrock) | 差异 |
| input_tokens | 5,911 | 5,954 | 0.007 |
| output_tokens | 1,307 | 1,318 | 0.008 |
| content blocks 总数 | 9 | 9 | 相同 |
| server_tool_use blocks | 2 | 2 | 相同 |
| web_fetch_tool_result blocks | 1 | 1 | 相同 |
| bash_code_execution_tool_result | 1 | 1 | 相同 |
| text blocks | 5 | 5 | 相同 |
| text blocks with citations | 2 | 2 | 相同 |
| web_fetch_requests | 1 | 1 | 相同 |
| stop_reason | end_turn | end_turn | 相同 |
Token 差异不到 1%,属于 Bedrock 与 Anthropic 原生 API 之间 token 计算的正常波动范围。
抓取内容对比
| 字段 | 官方 API | Proxy | 一致性 |
| content.type | web_fetch_result | web_fetch_result | 完全一致 |
| content.url | https://httpbin.org/html | https://httpbin.org/html | 完全一致 |
| source.type | text | text | 完全一致 |
| source.media_type | text/plain | text/plain | 完全一致 |
| source.data 长度 | 3,602 chars | 3,602 chars | 完全一致 |
| content.content.citations | {“enabled”: true} | {“enabled”: true} | 完全一致 |
| title | null | null | 完全一致 |
抓取的文本在两者之间逐字节一致,这也验证了官方API背后大概率也用的http直接抓取方案,而没有使用类似tavily extract的额外内容抓取服务
Citations 格式对比
两者的 citations 格式完全一致,均使用 char_location 类型进行字符级精确引用:
{
"type": "char_location",
"cited_text": "Herman Melville - Moby-Dick\n\n \n\n \n\n Availing himself of the mild...",
"document_index": 0,
"document_title": "",
"start_char_index": 0,
"end_char_index": 150,
"file_id": null
}Dynamic Filtering 代码执行对比
两者均正确触发了 bash_code_execution,Claude 编写 Python 代码从抓取内容中统计 “hammer” 出现次数。代码逻辑相同,结果完全一致:
| 字段 | 官方 API | Proxy | 一致性 |
| return_code | 0 | 0 | 完全一致 |
| hammer 出现次数 | 3 | 3 | 完全一致 |
| 匹配 #1 | …patient hammer wielded by a patient arm… | 相同 | 完全一致 |
| 匹配 #2 | …heavy beating of his hammer the heavy beating… | 相同 | 完全一致 |
| 匹配 #3 | …old husband’s hammer; whose reverberations… | 相同 | 完全一致 |
7.4 跨模型兼容性验证
前面三节的对比测试均使用 Claude 模型(claude-sonnet-4-6)。由于 Proxy 的 Web Search / Web Fetch 功能完全在中间层编排——工具替换、Agentic Loop、搜索/抓取执行、引用后处理均由 Proxy 自身完成,Bedrock 端只需要一个能理解标准 tool definition 并正确生成 tool_use 调用的模型——因此理论上,任何支持 Bedrock 工具调用能力的模型都可以使用这些功能。
我们在以下 Bedrock 托管的非 Claude 模型上进行了验证测试:
| 模型 | 模型 ID on Bedrock | Web Search | Web Fetch | Dynamic Filtering |
| Qwen3-Coder 480B | qwen.qwen3-coder-480b-a35b-v1:0 | 通过 | 通过 | 通过 |
| Kimi K2.5 | moonshot.kimi-k2.5 | 通过 | 通过 | 通过 |
| MiniMax M2.1 | minimax.minimax-m2.1 | 通过 | 通过 | 通过 |
| GLM-4.7 | zai.glm-4.7 | 通过 | 通过 | 通过 |
| DeepSeek 3.2 | deepseek.v3.2 | 通过 | 通过 | 通过 |
这一结果验证了 Proxy 架构设计的一个核心优势:Web Search 和 Web Fetch 的能力不再绑定于特定模型。客户端可以在不修改任何工具配置的前提下,仅通过切换 model 参数即可在不同模型间切换,同时保留完整的搜索、抓取和 Dynamic Filtering 能力。
⚠️ 注意:
不同模型在工具调用的指令遵从能力上存在差异。Claude 对 [N] 引用标记的遵从率最高,Dynamic Filtering 的代码生成质量同样因模型而异。
7.5 Dynamic Filtering vs 本地 Agent 模式:精确性和效率对比
前面几节验证了 Bedrock 通过Proxy 与 Anthropic 官方 API 的格式兼容性。本节从另一个角度验证 Dynamic Filtering 的实际价值:当任务涉及精确数值计算时,代码执行与纯 LLM 推理之间的差距有多大?
测试设计
| 维度 | 方案 A:Dynamic Filtering (Proxy) | 方案 B:本地 Agent(无代码执行) | 方案 C:本地 Agent + 代码执行 |
| 框架 | Anthropic SDK + Proxy web_fetch_20260209 | Strands Agent SDK + Tavily MCP | Strands Agent SDK + Tavily MCP + AgentCore CodeInterpreter |
| 抓取方式 | Proxy 内置 httpx 直接抓取 | Tavily tavily_extract API | Tavily tavily_extract API |
| 代码执行 | 内置 Docker 沙箱 bash_code_execution | 无 | Bedrock AgentCore code_interpreter |
| 分析方式 | LLM写代码 → 沙箱执行 → 输出回传 LLM | 纯 LLM 推理估算 | LLM 写代码 → AgentCore 执行 → 输出回传 Claude |
Prompt: “Please fetch the content at https://httpbin.org/html and find which 3 words have the highest frequency?”
方案 A:使用 Dynamic Filtering
Claude 在获取抓取内容后,自动选择调用 bash_code_execution 编写 Python 代码进行分析:
import re
from collections import Counter
text = '''Herman Melville - Moby-Dick ...'''
words = re.findall(r"[a-z']+", text.lower())
freq = Counter(words)
print('Top 10 most frequent words:')
for word, count in freq.most_common(10):
print(f' {word!r}: {count}')
代码在 Docker 沙箱中执行,输出精确结果, LLM 直接基于代码输出生成最终回答:the=35, and=28, of=22,100% 精确。
方案 B:本地 Agent(无代码执行)
用一个简单的Strands SDK(亚马逊开源的轻量级Agent SDK)开发的Agent,通过 Tavily MCP 抓取页面内容后,LLM 直接推理估算词频,没有任何代码执行环节,给出了完全错误的结果。
方案 C:本地 Agent + 代码执行
如果本地 Agent 框架也有代码执行能力,能否达到 Dynamic Filtering 同等的效果?我们为Strands Agent 也配置了代码执行工具(Amazon Bedrock AgentCore 的 code_interpreter),使其在工具层面与 Dynamic Filtering 具备相同的能力,并进行对比实验,正确结果。
但总 Token 消耗为 24,669——是方案 A 的 3.7 倍。这一开销的主要来源是工具定义的上下文膨胀:Tavily MCP 暴露完整 5 个工具,加上 code_interpreter 的工具定义,工具上下文合计约 ~2,500 tokens。每次模型调用都携带这些定义,3 轮迭代仅工具定义就多消耗约 ~7,000 tokens。
结果对比
| 指标 | 方案 A:Dynamic Filtering | 方案 B:本地 Agent(无代码执行工具) | 方案 C:本地Agent + CodeInterpreter |
| 总 Token | 6,731 | 6,745 | 24,669 |
| vs 方案 A | 基准 | ≈ 持平 | +266%(3.7 倍) |
| 工具调用 | web_fetch + bash_code_execution | tavily_extract | tavily_extract + code_interpreter |
| 结果准确性 | 100% 精确 ✅ | 全部错误 ❌ | 100% 精确 ✅ |
这一对比体现出Dynamic Filtering 的核心价值:
1. 精确性提升:对于涉及计数、排序、数值提取、数据对比等需要精确计算的任务,LLM 的自然语言推理天然不可靠—模型会”数错”、”估错”、甚至遗漏项目。而代码执行结果是确定性的。
2. Token 效率提升:
方案 A 与 C 结果相同,但 Token 消耗差距达 3.7 倍(6,731 vs 24,669),主要源于工具定义的上下文膨胀,MCP 将完整工具描述暴露给模型,而 Proxy 方案可按需注入最小化定义,将无关接口隐藏在内部。
- Dynamic Filtering :仅注入 2 个极简 tool definition(
web_fetch+bash_code_execution),合计约 ~185 tokens。实际逻辑由 Proxy 处理,无需在模型上下文中暴露复杂接口。 - 传统 Agent + MCP:Tavily MCP 暴露完整 5 个工具,加上
code_interpreter的详细参数,工具上下文合计约 ~2,500 tokens。每次模型调用都携带这些定义,3 轮迭代仅工具定义就多消耗约 ~7,000 tokens。
3. 开发体验提升
Dynamic Filtering 对开发者透明——声明工具类型即可,代码执行能力自动就绪。方案 C 则需自行集成配置独立工具(Tavily MCP、CodeInterpreter),并确保 Agent 框架正确编排调用链路。
在方案 A 和 C 中,LLM 在获取抓取内容后均自主判断当前任务适合用代码来完成(而非纯推理),并自动生成了词频统计脚本。
⚠️ 适用场景提示:
当任务涉及精确数值(词频统计、价格对比、数据提取、排名计算等)时,应优先使用增强版工具(web_search_20260209 / web_fetch_20260209)以启用 Dynamic Filtering。对于纯摘要或内容理解类任务,标准版工具(web_search_20250305 / web_fetch_20250910)已足够。
7.6 对比结论
综合 Proxy 与 Anthropic 官方 API 的直接对比(6.2、6.3)、跨模型兼容性验证(6.4)以及 Dynamic Filtering 与传统模式的精确性对比(6.5),总结如下:
| 评估维度 | Web Search (6.2) | Web Fetch + Citations (6.3) |
| Token 消耗差异 | <4% | <1% |
| Agentic Loop 行为 | 搜索查询/迭代次数完全一致 | 抓取/迭代次数完全一致 |
| Dynamic Filtering | 代码执行结果完全一致 | 代码执行结果完全一致 |
| 响应格式 | 100% 兼容 | 100% 兼容 |
| Citations 格式 | web_search_result_location 一致 | char_location 一致(字段名/值/拆分策略完全匹配) |
| 数据准确性 | 提取相同数据,得出相同结论 | 抓取内容逐字节一致,计算结果相同 |
| 跨模型兼容性 | Qwen3 / Kimi / MiniMax 均通过 | Qwen3 / Kimi / MiniMax 均通过 |
此外,6.5 节的三方对比也揭示了Dynamic Filtering 的双重优势。首先,代码执行是精确数值任务的关键——有代码执行的方案 A 和 C 均 100% 正确。其次,Dynamic Filtering 在相同准确率下 Token 消耗比本地 Agent + CodeInterpreter 方案的低。
另外,通过Proxy层适配后,不仅与 Anthropic 官方 API 在功能和格式上完全兼容,还将 Web Search 和 Web Fetch 能力扩展到了 Bedrock 上所有支持工具调用的模型,打破了这些服务端工具与特定模型提供商的绑定。
八、部署与配置注意事项
8.1 搜索提供商选择
Proxy 目前支持两家搜索提供商,可通过 WEB_SEARCH_PROVIDER 环境变量切换:
- Tavily(推荐):专为 AI 应用设计的搜索引擎,返回内容经过清洗和结构化处理,原生支持域名过滤参数(
include_domains/exclude_domains),设置search_depth: "advanced"可返回更丰富的页面内容。适合作为生产环境的首选方案。 - Brave:基于独立搜索索引(非 Google/Bing)的搜索引擎,提供差异化的搜索结果来源。
8.2 Docker 沙箱要求
Dynamic Filtering 需要在代码沙箱中执行 LLM 生成的 Python 脚本,因此对运行环境有以下要求:
- ECS 部署须使用 EC2 launch type:Amazon Fargate 不提供 Docker daemon 访问权限,无法创建沙箱容器。
- 部署命令:
ENABLE_WEB_SEARCH=true \
WEB_SEARCH_PROVIDER=tavily \
WEB_SEARCH_API_KEY=tvly-your-api-key \
./scripts/deploy.sh -e prod -r us-west-2 -p arm64 -l ec2关于 Docker 沙箱的完整部署细节(包括容器创建、文件注入、Docker-in-Docker 绑定挂载问题的解决方案等),请参考本系列的上一篇博客:《使用 Amazon Bedrock + 自建 ECS Docker Sandbox 实现 Agent 程序化工具调用 Programmatic Tool Calling》。
⚠️ 提示:
如果仅使用标准版工具(web_search_20250305 / web_fetch_20250910),则不需要 Docker 运行环境。标准版的 Agentic Loop 仅涉及搜索/抓取提供商的 API 调用,无代码执行环节。
8.3 客户端使用示例
Proxy 对外暴露与 Anthropic 官方 API 完全相同的端点和响应格式,因此客户端代码无需任何修改——仅需将 base_url 指向 Proxy 地址即可。以下是使用 Anthropic Python SDK 通过 Proxy 调用 Web Search 的示例:
import anthropic# 仅需修改 base_url 指向 Proxy,其余代码与调用 Anthropic 官方 API 完全相同client = anthropic.Anthropic(
base_url="https://your-proxy-endpoint.com",
api_key="your-proxy-api-key",
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
}],
messages=[{"role": "user", "content": "2026年 AWS re:Invent 有哪些重要发布?"}],
)
# 响应格式与 Anthropic 官方 API 完全一致for block in response.content:
if block.type == "text":
print(block.text)
从 Anthropic 官方 API 迁移至 Bedrock 时,只需在客户端配置中替换一行 base_url,即可无缝切换,无需修改任何业务逻辑代码。
九、总结与展望
9.1 回顾
本文详细介绍了如何在 Amazon Bedrock 上通过自建 Proxy 服务实现 Anthropic 的 Web Search 和 Web Fetch 两个 Server-Managed Tools。且Proxy 不仅与 Anthropic 官方 API 在功能和格式上兼容,还将 Web Search 和 Web Fetch 能力扩展到了 Bedrock 上所有支持工具调用的模型,打破了这些服务端工具与特定模型提供商的绑定。
9.2 系列回顾
结合本系列的上一篇博客(Programmatic Tool Calling),Proxy 目前已完整实现了 Anthropic API 的三大服务端特性:
- Programmatic Tool Calling(程序化工具调用):大模型生成 Python 代码编排工具调用,降低 Token 消耗,提升推理准确率
- Web Search(实时搜索):大模型自主搜索互联网获取实时信息,生成带来源引用的回答
- Web Fetch(网页抓取):大模型直接抓取指定 URL 的完整页面内容,支持文档级精确引用
这使得通过 Amazon Bedrock 使用能够获得与 Anthropic 官方 API 几乎完全一致的能力体验——客户端代码无需任何修改,仅需将 base_url 指向 Proxy 即可。
9.3 已知局限性
- 搜索结果质量依赖第三方提供商:Tavily 和 Brave 的搜索结果可能与 Anthropic 自有搜索引擎存在差异,尤其在特定领域的覆盖深度和结果排序上
- 引用系统基于提示工程:通过 system prompt 注入引用指令并后处理
[N]标记,极少数情况下引用标记可能缺失或格式偏差 - Dynamic Filtering 依赖 Docker 环境:增强版工具需要 Docker 运行环境,增加了部署复杂度,且 ECS 部署必须使用 EC2 launch type
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon ECS — 完全托管的容器编排服务
- Amazon EC2 — 安全且可调整大小的计算容量
- Amazon Bedrock AgentCore — 加快代理投入生产的速度
- Amazon Fargate — 适用于容器的无服务器计算
相关文章:
十、参考资料
- 使用 Amazon Bedrock + 自建 ECS Docker Sandbox 实现 Agent 程序化工具调用 Programmatic Tool Calling — 本系列前作,介绍 PTC 和 Docker 沙箱实现
- Improved Web Search with Dynamic Filtering — Anthropic 官方博客,介绍 Dynamic Filtering 特性及基准测试数据
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
