亚马逊AWS官方博客
使用 AWS Glue、Apache Hudi 和 Amazon S3 构建无服务器管道以分析串流数据
- 从上游系统摄入持续更改(例如客户订单)
- 将表捕获到数据湖中
- 在摄入新数据时启用一致的数据视图,在数据湖上提供 ACID 属性,从而支持交互式分析
- 因上游数据布局的变化和数据延迟到达的预置而实现架构灵活性
为了满足这些要求,企业必须构建自定义框架来处理就地更新(也称为upsert),处理由于不断从上游系统(例如数据库)摄入更改而创建的小文件,处理架构演变,以及在为其数据湖提供 ACID 保证方面的妥协。
像 Apache Hudi 这样的处理框架是解决此类挑战的好方法。借助 Hudi,您可以使用增量数据管道构建串流数据湖,并支持对存储在数据湖中的数据执行事务、记录级更新和删除。Hudi 与各种 AWS 分析服务(例如 AWS Glue、Amazon EMR、Athena 和 Amazon Redshift)集成。这有助于通过批量流式传输从各种来源摄入数据,同时为 Amazon S3(或 HDFS)等适合于追加的存储系统启用就地更新。在这篇文章中,我们会讨论一种无服务器方法,用于将 Hudi 与流式传输使用场景集成,并在 Amazon S3 上创建可就地更新的数据湖。
解决方案概览
我们使用 Amazon Kinesis 数据生成器将样本串流数据发送到 Amazon Kinesis Data Streams。为了使用这个串流数据,我们设置了一个 AWS Glue 串流 ETL 任务,该任务使用适用于 AWS Glue 的 Apache Hudi 连接器将摄入和转换的数据写入 Amazon S3,并在 AWS Glue 数据目录中创建一个表。
摄入数据后,Hudi 会将数据集整理到指向 Amazon S3 中某个位置的基本路径下的分区目录结构中。这些分区目录中的数据布局取决于摄入期间使用的 Hudi 数据集类型,例如写入时复制(CoW)和读取时合并(MoR)。有关 Hudi 存储类型的更多信息,请参阅使用 Athena 查询 Apache Hudi 数据集和存储类型与视图。
CoW 是 Hudi 的默认存储类型。在这种存储类型中,数据以列式格式(Parquet)存储。每次摄入都会在写入过程中创建新版文件。使用 CoW,每次记录有更新时,Hudi 都会使用更新后的值重写包含记录的原始列式文件。因此,这更适合对更改频率较低的数据进行大量读取的工作负载。
MoR 存储类型使用列式(Parquet)和行式(Avro)格式的组合进行存储。更新会记录到行式增量文件中,并进行压缩以创建新版列式文件。使用 MoR,每次记录有更新时,Hudi 只会将已更改记录的行写入行式(Avro)格式,该格式会进行压缩(同步或异步)以创建列式文件。因此,MoR 更适合读取量较少而写入或更改更频繁的工作负载。
在这篇文章中,我们使用 CoW 存储类型来说明我们创建 Hudi 数据集并通过各种读取器提供相同服务的使用场景。您可以通过在摄入期间选择特定的存储类型来扩展此解决方案,从而支持 MoR 存储。我们使用 Athena 来读取数据集。我们还说明了这个解决方案的就地更新、嵌套分区和架构灵活性方面的功能。
下图展示了我们解决方案的架构。

使用适用于 AWS Glue 的 Apache Hudi 连接器创建 Apache Hudi 连接
要使用 AWS Glue 自定义连接器创建 AWS Glue 任务,请完成以下步骤:
- 在 AWS Glue Studio 控制台上,通过导航窗格选择 Marketplace(市场)。
- 搜索并选择 Apache Hudi Connector for AWS Glue(适用于 AWS Glue 的 Apache Hudi 连接器)。

- 选择 Continue to Subscribe(继续订阅)。
- 查看 terms and conditions(条款与条件),然后选择 Accept Terms(接受条款)。
- 确保订阅已完成,并且您看到产品旁边填入了 Effective date(生效日期),然后选择 Continue to Configuration(继续配置)。
- 对于 Delivery Method(交付方式),选择 Glue 3.0。
- 对于 Software Version(软件版本),选择最新版本(在本文写作之时,适用于 AWS Glue 的 Apache Hudi 连接器的最新版本是 0.9.0)。
- 选择 Continue to Launch(继续启动)。
- 在 Launch this software(启动此软件)下面,单击 Usage Instructions(使用说明),然后单击 Activate the Glue connector for Apache Hudi in AWS Glue Studio(在 AWS Glue Studio 中激活适用于 Apache Hudi 的 Glue 连接器)。

系统会将您重新导向至 AWS Glue Studio。
- 对于 Name(名称),输入连接的名称(例如,hudi-connection)。
- 对于 Description(描述),输入描述。
- 选择 Create connection and activate connector(创建连接并激活连接器)。

此时会显示一条消息,提示已成功创建连接,并且现在可以在 AWS Glue Studio 控制台上看到该连接。

配置资源和权限
在这篇文章中,我们提供了一个 AWS CloudFormation 模板来创建以下资源:
- 一个名为
hudi-demo-bucket-<your-stack-id>的 S3 存储桶,其中包含从您账户之外的另一个公有 S3 存储桶复制的 JAR 构件。然后,此 JAR 构件用于定义 AWS Glue 串流任务。 - 一个名为
hudi-demo-stream-<your-stack-id>的 Kinesis 数据流。 - 一个名为
Hudi_Streaming_Job-<your-stack-id>的 AWS Glue 串流任务,具有名为hudi-demo-db-<your-stack-id>专用 AWS Glue 数据目录。有关任务的完整代码,请参阅 aws-samples github 存储库。 - 具有适当权限的 AWS Identity and Access Management(IAM)角色和策略。
- AWS Lambda 函数用于将构件复制到 S3 存储桶,并在删除堆栈时先清空存储桶。
要创建您的资源,请完成以下步骤:
- 选择 Launch Stack(启动堆栈):

- 对于 Stack name(堆栈名称),输入
hudi-connector-blog-for-streaming-data。 - 对于 HudiConnectionName,请使用您在上一部分指定的名称。
- 将其他参数保留为默认值。
- 选择 Next(下一步)。

- 选择 I acknowledge that AWS CloudFormation might create IAM resources with custom names(我确认 AWS CloudFormation 可以使用自定义名称创建 IAM 资源)。
- 单击 Create stack(创建堆栈)。
设置 Kinesis 数据生成器
在此步骤中,您将配置 Kinesis 数据生成器以将样本数据发送到 Kinesis 数据流。
- 在 Kinesis 数据生成器控制台上,选择 Create a Cognito User with CloudFormation(使用 CloudFormation 创建 Cognito 用户)。

系统会将您重新导向至 AWS CloudFormation 控制台。
- 在 Review(审查)页面的 Capabilities(功能)部分,选择 I acknowledge that AWS CloudFormation might create IAM resources(我确认 AWS CloudFormation 会创建 IAM 资源)。
- 单击 Create stack(创建堆栈)。
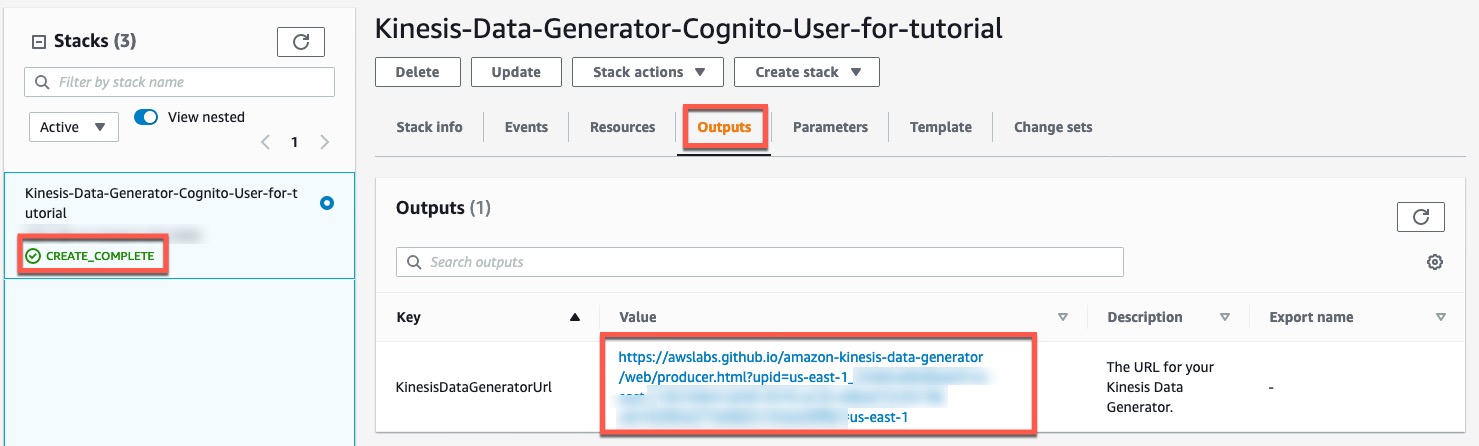
- 在 Stack details(堆栈详细信息)页面的 Stacks(堆栈)部分,确认状态显示为
CREATE_COMPLETE。 - 在 Outputs(输出)选项卡上,复制
KinesisDataGeneratorUrl的 URL 值。
- 在浏览器中导航到此 URL。
- 输入提供的用户名和密码,然后选择 Sign In(登录)。
启动 AWS Glue 串流任务
要启动 AWS Glue 串流任务,请完成以下步骤:
- 在 AWS CloudFormation 控制台中,导航到您创建的堆栈的 Resources(资源)选项卡。
- 复制与 AWS::Glue::Job 资源对应的物理 ID。

- 在 AWS Glue Studio 控制台中,使用物理 ID 找到任务名称。
- 选择要查看其脚本和任务详细信息的任务。

- 选择 Run(运行)以启动任务。

- 在 Runs(运行)选项卡上,验证任务是否成功运行。

将样本数据发送到 Kinesis 数据流
Kinesis 数据生成器根据您提供的模板使用随机数据生成记录。Kinesis 数据生成器对开源随机数据生成器 faker.js 进行扩展。
在此步骤中使用 Kinesis 数据生成器,通过采用 faker.js 文档的示例模板将样本数据发送到以前创建的数据流,该数据流以每秒一条记录的速率创建。在本教程结束之前,您将持续摄入,以便在执行其余步骤时获得合理的数据进行分析。
- 在 Kinesis 数据生成器控制台中,对于 Records per second(每秒记录数),选择 Constant(常数)选项卡,然后将值更改为
1。 - 对于 Record template(记录模板),选择 Template 1(模板 1)选项卡,然后在文本框中输入以下代码示例:
- 选择 Test template(测试模板)。

- 验证示例 JSON 记录的结构,然后选择 Close(关闭)。

- 选择 Send data(发送数据)。
- 使 Kinesis 数据生成器页面保持打开,以确保将随机记录持续流式传输到数据流。
在生成数据时继续执行剩余步骤。

验证动态创建的资源
在生成用于分析的数据时,您可以验证您创建的资源。
Amazon S3 数据集
当 AWS Glue 串流任务运行时,使用 Kinesis 数据流中的记录并存储在 S3 存储桶中。在 Amazon S3 中创建 Hudi 数据集时,串流任务还可以创建嵌套的分区结构。通过在串流任务定义中使用 Hudi 配置属性 hoodie.datasource.write.partitionpath.field 和 hoodie.datasource.write.keygenerator.class 来实现。
在此示例中,按名称、年、月和日创建嵌套分区。这些属性的值在 AWS Glue 串流任务的脚本中设置如下。

有关 CustomKeyGenerator 如何生成此类分区路径的更多详细信息,请参阅 Apache Hudi 密钥生成器。
以下屏幕截图显示了在 Amazon S3 中创建的嵌套分区。

AWS Glue 数据目录表
还会在 AWS Glue 数据目录中创建一个 Hudi 表,并将其映射到 Amazon S3 上的 Hudi 数据集。请参阅 AWS Glue 串流任务中的以下代码。

下表提供了有关配置选项的更多详细信息。
| hoodie.datasource.hive_sync.enable | 指示表是否已同步到 Apache Hive 元存储。 |
| hoodie.datasource.hive_sync.sync_as_datasource | 避免通过 HUDI-1415(JIRA)引入无法兼容的更改。 |
| hoodie.datasource.hive_sync.database | 数据目录的数据库名称。 |
| hoodie.datasource.hive_sync.table | 数据目录中的表名称。 |
| hoodie.datasource.hive_sync.use_jdbc | 使用 JDBC 进行 Hive 同步。有关更多信息,请参阅 GitHub 存储库。 |
| hoodie.datasource.write.hive_style_partitioning | 使用 <partition_column_name>=<partition_value> 格式创建分区。 |
| hoodie.datasource.hive_sync.partition_extractor_class | 嵌套分区所必需。 |
| hoodie.datasource.hive_sync.partition_fields | 表中用于 Hive 分区列的列。 |
以下屏幕截图显示了数据目录中的 Hudi 表和关联的 S3 存储桶。

使用 Athena 读取结果
通过将 Hudi 与 AWS Glue 串流任务结合使用,我们可以对 Amazon S3 数据湖进行就地更新(upsert)。此功能允许进行增量处理,从而实现更快、更高效的下游管道。Apache Hudi 通过以下步骤启用就地更新:
- 定义索引(使用摄入记录的列)。
- 使用此索引将每个后续摄入映射到之前摄入的记录存储位置(在本例中为 Amazon S3)。
- 执行压缩(同步或异步)以允许保留给定索引的最新记录。
关于我们的 AWS Glue 串流任务,以下 Hudi 配置选项使我们能够为生成的架构实现就地更新。

下表提供了突出显示的配置选项的更多详细信息。
| hoodie.datasource.write.recordkey.field | 指示要在 Hudi 索引的摄入记录中使用的列。 |
| hoodie.datasource.write.operation | 定义对 Hudi 数据集执行的操作的性质。在此示例中,它设置为 upsert,表示就地更新。 |
| hoodie.datasource.write.table.type | 指示要使用的 Hudi 存储类型。在此示例中,它设置为 COPY_ON_WRITE。 |
| hoodie.datasource.write.precombine.field | 当两条记录具有相同的键值时,Apache Hudi 会为预组合字段选择具有最大值的记录。 |
要演示就地更新,请考虑通过 Kinesis 数据生成器发送到 AWS Glue 串流任务的以下输入记录。突出显示的记录标识符表示 AWS Glue 配置中的 Hudi 记录密钥。在此示例中,Person3 接收两个更新。在第一个更新中,column_to_update_string 设置为 White;在第二个更新中,它设置为 Red。

串流任务会处理这些记录,并在 Amazon S3 中创建 Hudi 数据集。您可以使用 Athena 查询数据集。在下面的示例中,我们获得了最新的更新。

架构灵活性
AWS Glue 串流任务允许自动处理摄入过程中遇到的不同记录架构。这在记录架构会经常更改的情况下特别有用。为了详细说明这一点,请考虑以下情况:
- 案例 1 – 在时间为 t1 时,摄入记录的布局为
<col 1, col 2, col 3, col 4> - 案例 2 – 在时间为 t2 时,摄入记录有一个额外的列,新的布局为
<col 1, col 2, col 3, col 4, col 5> - 案例 3 – 在时间为 t3 时,摄入记录丢弃多余的列,因此其布局为
<col 1, col 2, col 3, col 4>
对于案例 1 和案例 2,AWS Glue 串流任务依赖于 Hudi 的内置架构演进功能,该功能可使数据目录更新为包括额外的列(在本例中为 col 5)。此外,Hudi 还在输出文件(写入到 Amazon S3 的 Parquet 文件)中添加了额外的列。从而使查询引擎(Athena)可以使用额外的列来查询 Hudi 数据集,而不会出现任何问题。
由于案例 2 摄入会更新数据目录,因此在后续摄入的每条记录中都应存在额外的列(col 5)。如果我们不解决这个差异,任务会失败。
为了克服这个问题并实现案例 3,串流任务定义了一个名为 evolveSchema 的自定义函数,用于处理记录布局不匹配的问题。该方法在 AWS Glue 数据目录中查询每条待摄入的记录并获取当前 Hudi 表架构。然后,它将 Hudi 表架构与待摄入记录的架构合并,并在使用 Hudi 数据集公开之前丰富记录的架构。

在此示例中,待摄入记录的架构 <col 1, col 2, col 3, col 4> 修改为 <col 1, col 2, col 3, col 4, col 5>,其中额外的值 col 5 设置为 NULL。
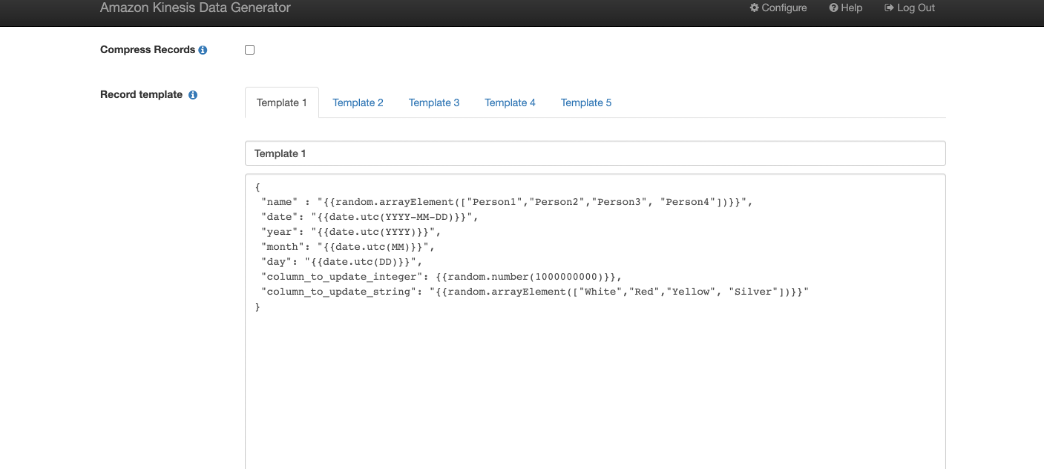
为了说明这一点,我们停止 Kinesis 数据生成器的现有摄入,并修改记录布局以发送一个名为 new_column 的额外列:

数据目录中的 Hudi 表更新如下,其中包含新添加的列(案例 2)。
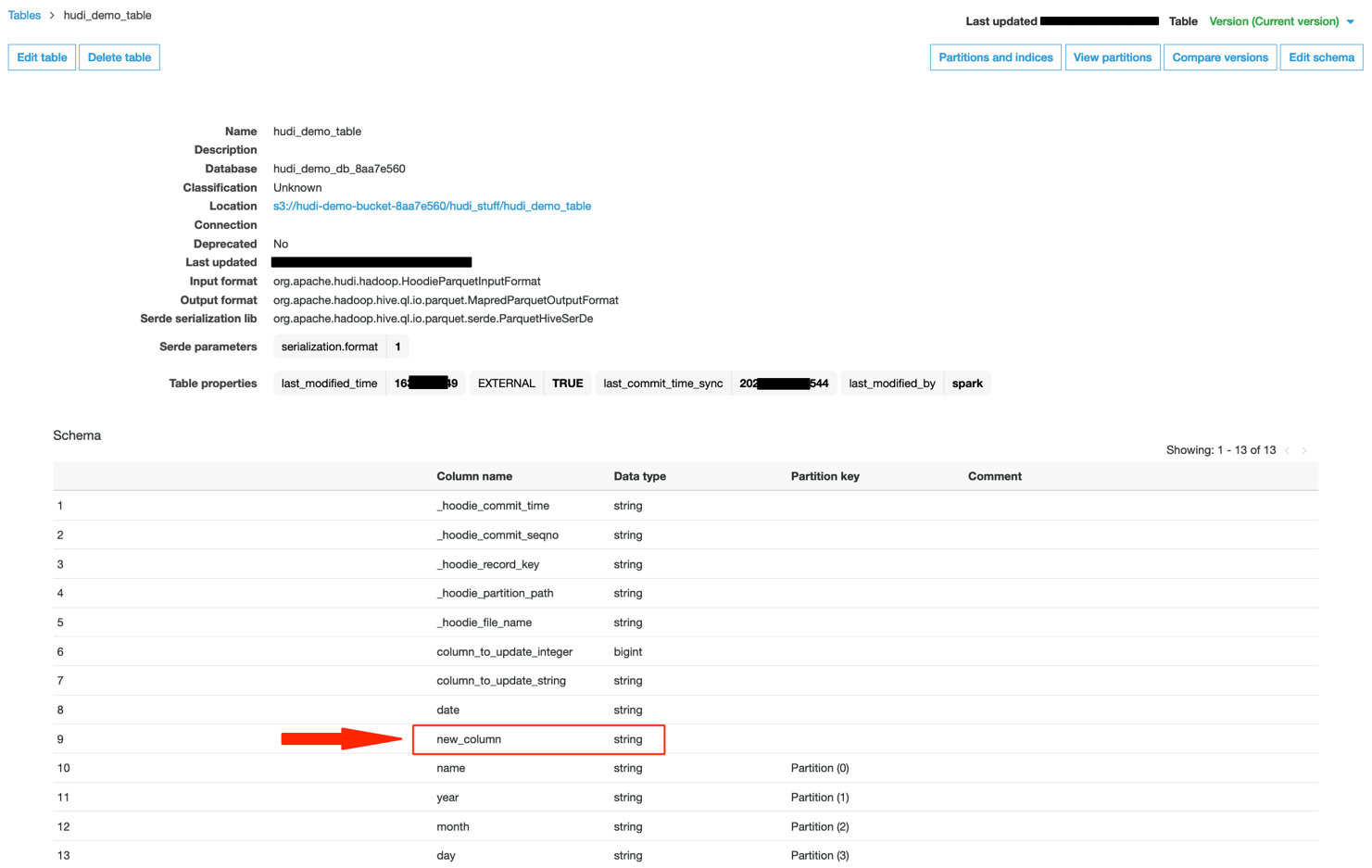
当我们使用 Athena 查询 Hudi 数据集时,我们可以看到出现了一个新列。

现在,我们可以使用 Kinesis 数据生成器来发送带有旧架构的记录,而没有新添加的列(案例 3)。
在这种情况下,我们的 AWS Glue 任务继续运行。当我们使用 Athena 进行查询时,额外添加的列会填入 NULL 值。

如果我们停止 Kinesis 数据生成器并开始发送架构中包含额外列的记录,则任务会继续运行,且 Athena 查询会继续返回最新值。

清理
为避免将来产生费用,请删除您在 CloudFormation 堆栈中创建的资源。
小结
这篇文章说明了如何使用适用于 AWS Glue 的 Apache Hudi 连接器来设置使用 AWS Glue 串流任务的无服务器管道,该连接器持续运行和使用 Kinesis 数据流中的数据,以创建支持就地更新、嵌套分区和架构灵活性的近实时数据湖。
此外,您还可以使用 Apache Kafka 和 Amazon Managed Streaming for Apache Kafka(Amazon MSK)作为类似串流任务的来源。我们建议您使用此方法来设置近实时数据湖。AWS 一如既往地欢迎您提供反馈,请在评论中留下您的想法或问题。