亚马逊AWS官方博客
基于 Redshift 和 Grafana 搭建实时大屏应用
前言
大屏应用是以大屏幕为载体的视觉显示总称,通过可视化创建图表、图形和图像,帮助用户更深入地理解。大屏应用的最终目的是通过可视化帮助用户洞察业务数据,高效处理信息,快速响应。目前,大屏广泛应用于运维洞察、实时监控、企业前台、运营作战室等场景。随着数据可视化大屏幕的广泛应用,可视化大屏幕技术也在不断完善。本文将从涉及的技术要点入手,通过一个具体的日志场景,详细论述如何在亚马逊云科技上建立实时大屏应用的案例。
解决方案概述
本篇博客会基于 Kinesis 和 Redshift stream ingestion 以及 Amazon 托管的 Grafana 来实现实时大屏,具体业务场景可以满足比如运维实时监控,物联网,APP 埋点实时分析,黑五,双11, 618等电商平台的实时数据可视化展示等。以下是构建实时大屏应用的架构流程 。
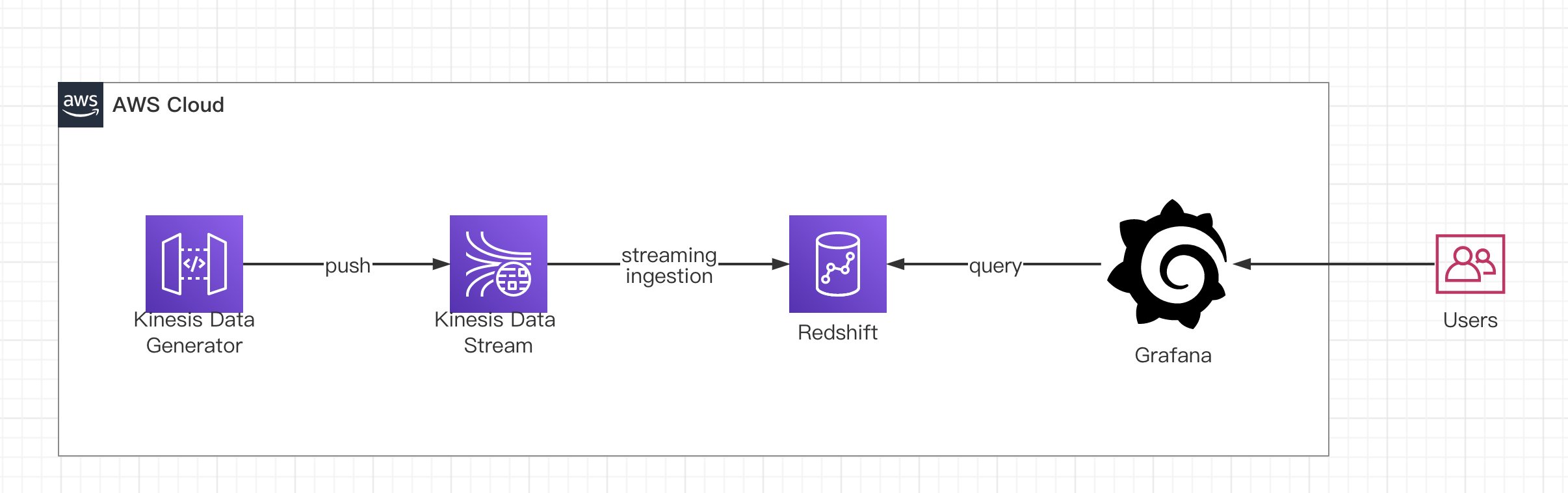 |
Amazon Kinesis Data Generator
Amazon Kinesis Data Generator(KDG)是亚马逊云科技无服务器实时数据生成器工具,它很擅长生产模拟数据,您只需要配置模版和速率,就可以轻松地利用 KDG 将数据发送到 Kinesis Streams 或 Kinesis Firehose。本实验中,它将承担海量数据生成模拟过程。
Amazon Kinesis Data Stream
 |
Amazon Kinesis 可让您轻松收集、处理和分析实时流数据,以便您及时获得见解并对新信息快速做出响应。借助 Amazon Kinesis,您可以即刻对收到的数据进行处理和分析并做出响应,无需等到收集完全部数据后才开始进行处理。目前 Redshift 支持基于 KDS 的流式摄入,将在实验环节,向您展示它的全貌。
Amazon Redshift
 |
Amazon Redshift 是一种完全托管的 PB 级云中数据仓库服务,使整个组织的用户能够利用各种数据并获得业务洞察力。同时应用实时分析和机器学习(ML)术。无需专业的数据仓库管理经验即可实现从接收、存储和访问数据分析、可视化和预测各种形式的数据。在本实验中,它将作为数据存储和 OLAP 的核心,借助物化视图和极高的查询性能,实现增量的 ETL 和以及大屏应用端秒级刷新需求。
Redshift Streaming Ingestion(流式摄取)允许您直接连接到流引擎 Kinesis Data Stream 或 Amazon Managed Streaming for Apache Kafka,实现快速流数据摄入,而不需要在 Amazon S3 中暂存数据并将其加载到集群相关的延迟和复杂性。您现在可以使用 SQL 连接到数据流并从中访问数据,并通过直接在数据流之上创建物化视图来简化数据管道。物化视图还可以将 SQL 转换作为 ELT(提取、加载和转换)管道的一部分。流式摄取支持高达30万/秒的数据摄入(2KB size/row),小于10秒的延迟,同时支持高并发实时查询如大宽表、多表关联、复杂聚合等各种 SQL 查询。
Amazon Managed Grafana
 |
Grafana 是一个开源的数据可视化和运营仪表板解决方案,由数十万组织和数百万用户使用。Grafana 丰富的可视化程序库和对多个数据源的广泛支持使客户可以在单个控制台中轻松地查询、可视化各种操作数据并发出警报,包括指标、日志和跟踪。Amazon 托管 Grafana 提供与开源项目兼容的完全托管 Grafana 工作区,并与开源项目的母公司 Grafana Labs 合作开发。在本实验中,Grafana 作为可视化终端,完成数据最终展现,支持秒级自动刷新,极大的提升大屏体验。
方案步骤
1. 创建 Service 资源
创建 Kinesis Data Generator (KDG),Kinesis,Redshift,Grafana 等资源
使用 Amazon Kinesis Data Streams,按照以下步骤创建一个名为 blog_kds 的流。对于 Capacity mode(容量模式),选择 On-demand(按需)。有关更多信息,请参阅通过亚马逊云科技管理控制台创建流。
2. 编写 KDG 端数据模版并生成数据
具体配置 KDG 步骤, https://awslabs.github.io/amazon-kinesis-data-generator/web/help.html
首先进入 KDG 页面,https://awslabs.github.io/amazon-kinesis-data-generator/web/producer.html
并选择上一步所在 region 的 Kinesis 资源
 |
编写 Record template
测试数据具体模板
粘贴以上模板,然后选择对应的区域和 Kinesis Data Stream 名字。本篇博客主要是模拟 IoT 数据,具体生成数据的写法可以参考:https://fakerjs.dev/api/datatype.html。 KDG 扩展了 faker.js, 一个开源的数据生成器。
 |
点击 Test template check 可以查看生成的数据
 |
检查数据样式后,点击 send data 正式写入数据,这里我们选择每秒发送100条数据。
 |
3. 在 KDS console 上检查数据情况
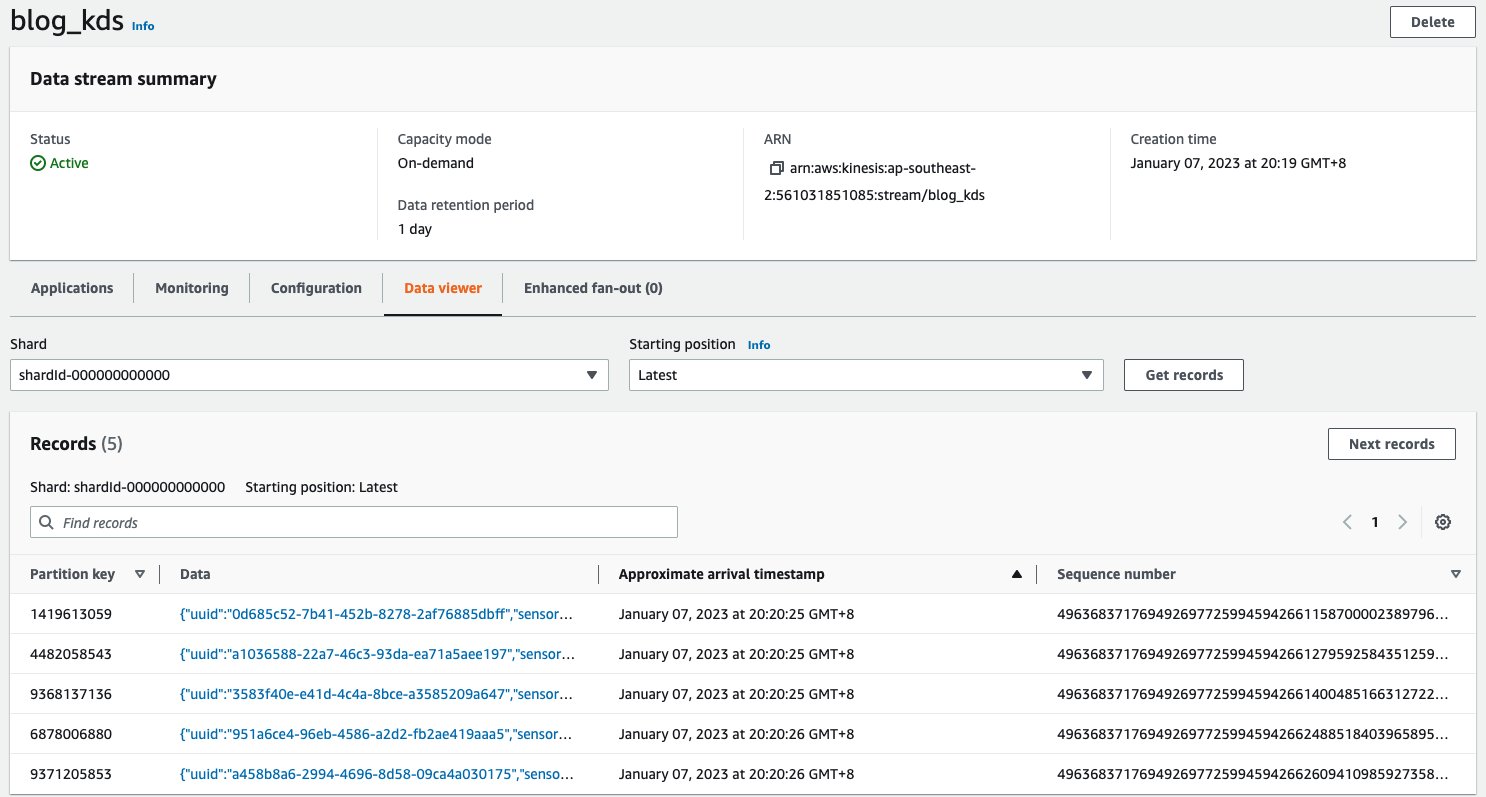 |
4. 在 Redshift 中构建 Kinesis 物化视图
4.1 字段信息
Redshift 从 KDS 中读取数据,会有如下几个字段信息。
| Metadata column | Description | |
| 1 | approximate_arrival_timestamp | The approximate time that the record was inserted into the Kinesis stream |
| 2 | partition_key | The key used by Kinesis to assign the record to a shard |
| 3 | shard_id | The unique identifier of the shard within the stream from which the record was retrieved |
| 4 | sequence_number | The unique identifier of the record from the Kinesis shard |
| 5 | refresh_time | The time the refresh started |
| 6 | kinesis_data | The record from the Kinesis stream |
4.2 Redshift Ingestion
使用信任策略创建 IAM 角色,该策略允许您的 Amazon RedShift 群集承担该角色。有关如何配置 IAM 角色的信任策略的信息,请参阅授权 Amazon RedShift 代表您访问其他亚马逊云科技服务。创建角色后,该角色应具有以下 IAM 策略,该策略提供与 Amazon Kinesis 数据流通信的权限。
4.3 为Redshift 创建 KDS schema 和 kds 物化视图
创建外部 Schema 以将 Kinesis 中的数据映射到某个 Redshift 对象。
而在下面的具体化视图定义中,具体化视图具有在 Redshift 中定义的 Schema。具体化视图按照来自流的 UUID 值分配,并按 approximatearrivaltimestamp 值存储。
检查 kds 物化视图的状态
 |
状态 0 表示物化视图将完全刷新,状态 1 表示物化视图将以增量方式刷新。
该物化视图为自动刷新,观察 starttime 可知,数据刷新间隔在 5s 内。
 |
查询刷新后的具体化视图以获取使用情况统计信息。
现在可以通过查询物化视图实现具体分析, 以下只是举例。
5. Grafana 对接
具体如何配置 Amazon Grafana, 可以参考:https://aws.amazon.com/blogs/big-data/query-and-visualize-amazon-redshift-operational-metrics-using-the-amazon-redshift-plugin-for-grafana/
配置 IAM Identity Center 和 Amazon Grafana Admin 权限
 |
 |
通过 IAM Identity Center(亚马逊云科技SSO)登录 Grafana
 |
选择 Data Sources
 |
Amazon Grafana 支持各种类型的的数据源,具体可以参考:
https://docs.aws.amazon.com/zh_cn/grafana/latest/userguide/AMG-data-sources-builtin.html
https://docs.aws.amazon.com/zh_cn/grafana/latest/userguide/AMG-data-sources-enterprise.html
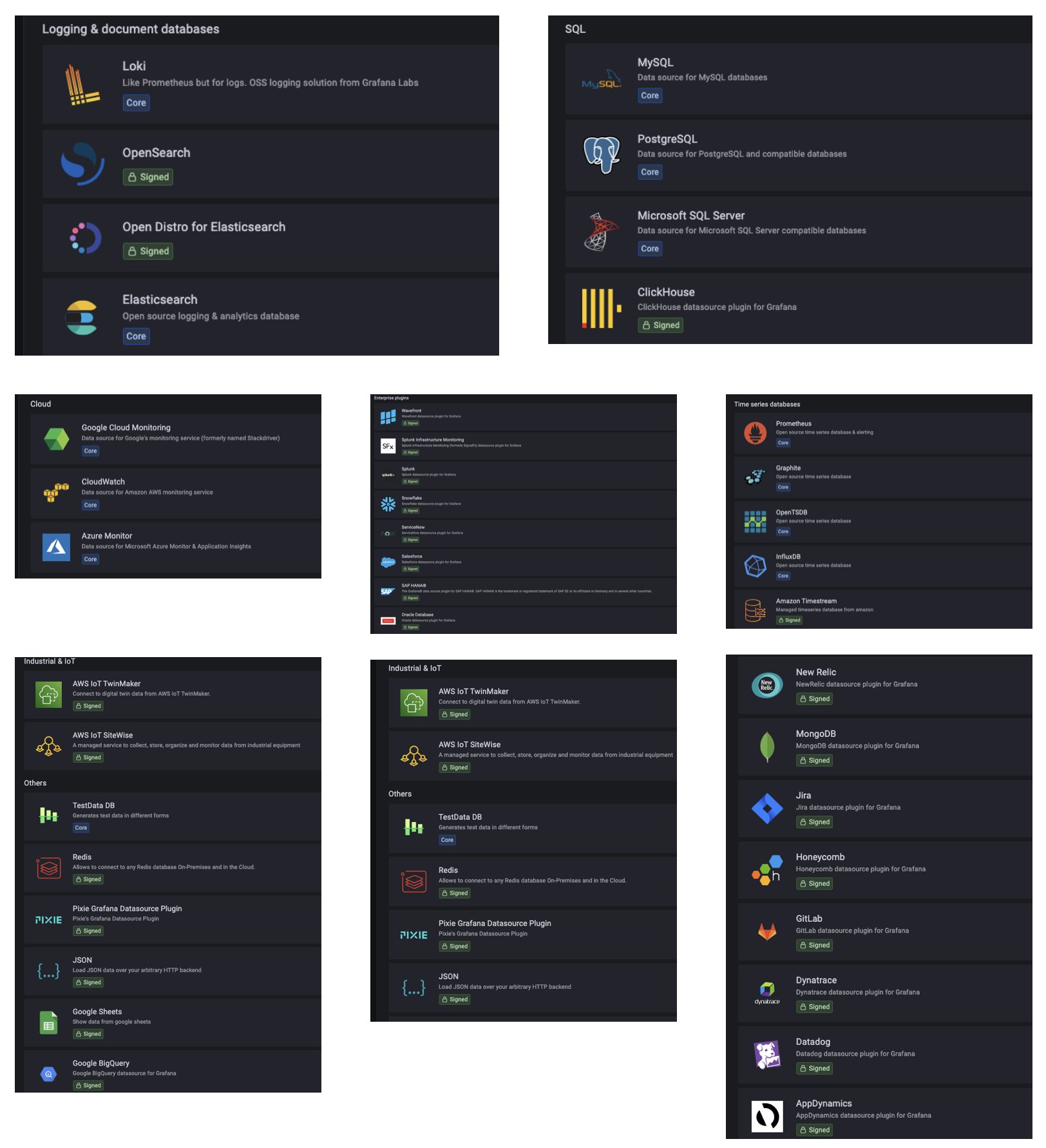 |
点击选择 Redshift
 |
配置 Redshift 数据源, 我们可以在不同账号设定数据源,本篇博客我们采用连接和 Grafana 在一个账号下不同区域的数据源,但 Grafana 也支持连接其它账号设置数据源,并且 Grafana 可以通过 assume role 的方式访问其它账号的 Redshift 集群,这样既安全,同时也可以在一个组织下共享一个 Grafana 资源。
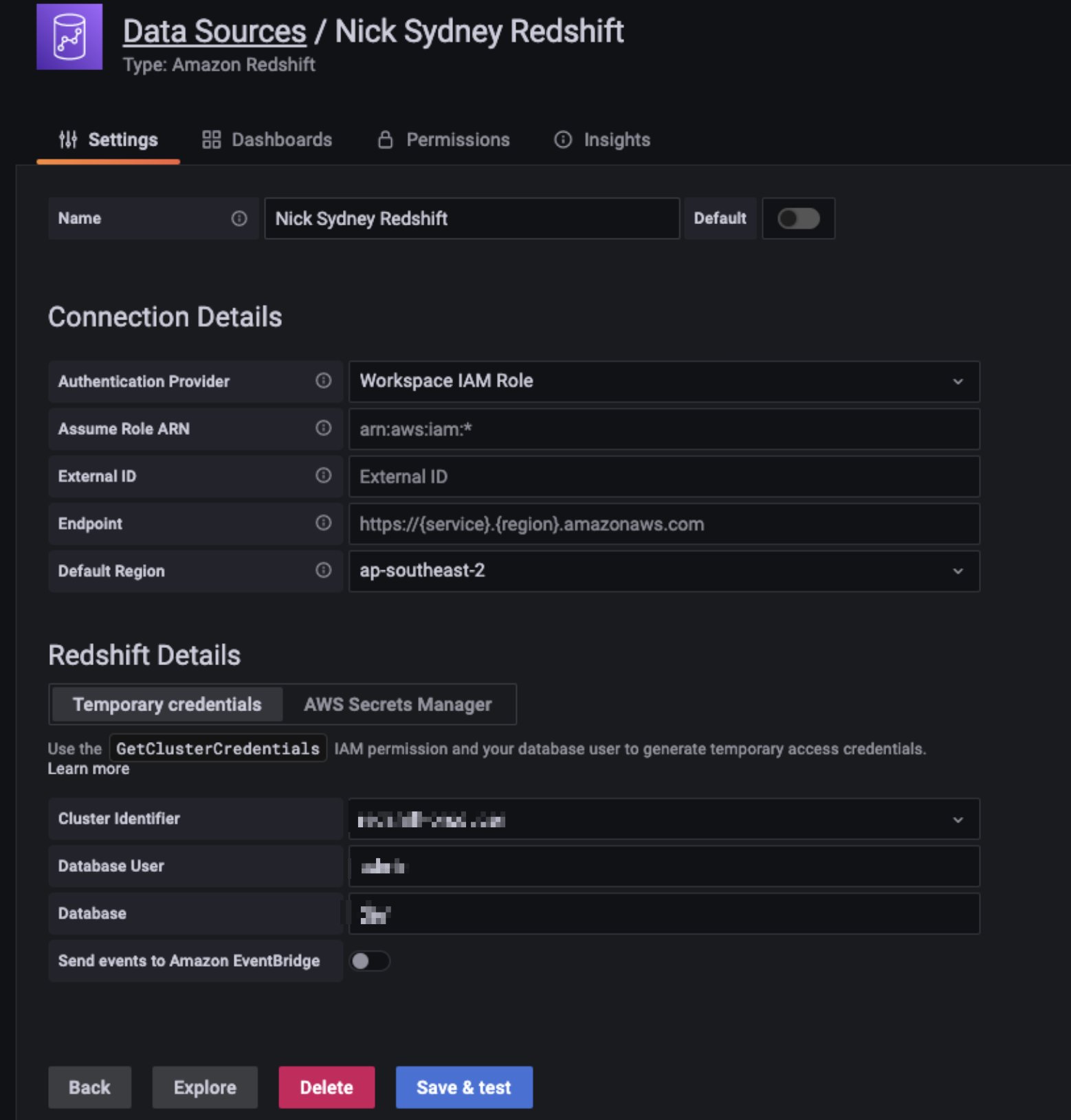 |
可以看到通过 assume role 的方式,安全的连接在其它区域和其他账号下的 Redshift。
 |
Grafana 非常人性化,可以用默认定制化的功能生成 Dashboard。
 |
同时也提供 Explore 的功能,相当于一个 Query 编辑器,可以方便的开发,测试和发布成报表。
 |
最后,我们生成一个模拟的 Dashboard。
 |
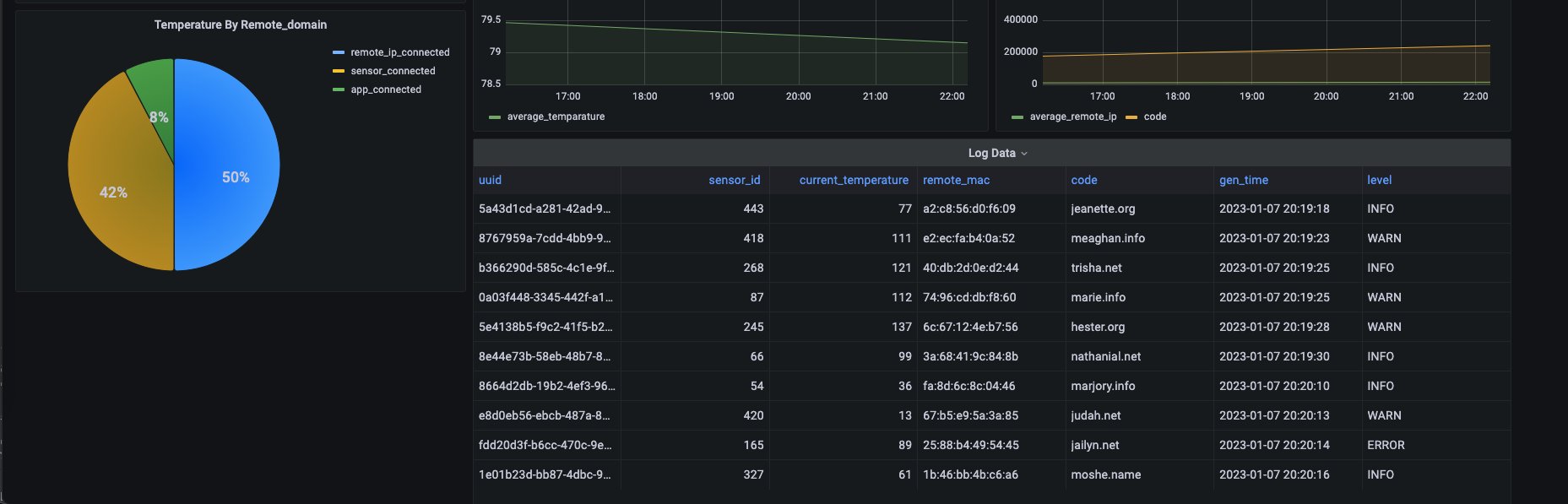 |
我们在 dashboard 设置每5秒自动刷新一次,这个可以按照实际情况来选择。
 |
结论
使用 Redshift 的流式数据摄入功能可以让你对数据进行实时处理和分析。这对于建立实时大屏应用来说非常有意义,因为它可以帮助你快速响应数据变化,并提供实时可视化信息。
为了验证使用 Redshift 流式数据摄入功能和 Grafana 构建实时大屏应用的可行性,我们可以构建一个模拟数据的pipeline。在这个 pipeline 中,我们可以使用 Redshift 的流式数据摄入功能来实时接收流式数据,并将其存储在 Redshift 中。然后,我们可以使用 Grafana 来查询 Redshift 中的数据,并构建实时大屏应用来显示这些数据。
在这个模拟数据 pipeline 中,我们可以使用各种数据源(如传感器数据、财务数据等)来模拟流式数据,并使用 Redshift 流式数据摄入功能将其摄入 Redshift。然后,我们可以使用 Grafana 构建可视化界面,并使用 Redshift 中的数据来更新这些可视化界面,从而实时显示数据变化。
另外,使用 Redshift 流式数据摄入功能和 Grafana 构建实时大屏应用还有一些其他优势:
- 可扩展性:Redshift 是一个高性能数据仓库,可以处理大量数据。因此,使用 Redshift 流式数据摄入功能和 Grafana 构建实时大屏应用可以帮助你应对数据规模的增长。
- 数据完整性:Redshift 提供了丰富的数据完整性保障机制,包括数据备份、恢复和数据完整性校验等。因此,使用 Redshift 流式数据摄入功能和 Grafana 构建实时大屏应用可以帮助你保证数据的完整性。
- 数据可视化:Grafana 是一个强大的可视化工具,可以帮助你构建丰富的可视化界面,秒级别自动刷新,并提供各种图表、仪表盘等可视化元素。因此,使用 Redshift 流式数据摄入功能和 Grafana 构建实时大屏应用可以帮助你更好地展示数据,并使用可视化工具来帮助你理解数据。
参考资料
https://awslabs.github.io/amazon-kinesis-data-generator/web/producer.html