亚马逊AWS官方博客
基于 MinerU 和 AWS Serverless 构建企业级 RAG 文档处理平台-平台搭建-聊天助手部署与 Prompt 工程
本文是 RAG 系统构建系列的第二篇,重点介绍智能问答系统的实践部署。第一篇文章《基于 MinerU和 AWS Serverless 构建企业级 RAG 文档处理平台-文档处理平台搭建》介绍了文档处理平台的架构设计。
前言:从文档处理到智能问答
在上一篇文章中,我们构建了一个高性能的文档处理平台,通过 MinerU + AWS Serverless + CloudFront 的深度整合,获得了高质量的处理结果,示例如下:
MinerU 处理后的文档结构
MinerU 处理完成后,会在 S3 的 processed/ 目录下生成以下结构:
关键特性:
- Job ID 目录:每次处理任务生成唯一的 UUID 作为顶层目录
- 文档名称目录:保留原始文档名称,便于识别
- auto 子目录:存放所有自动生成的处理结果
- 图片哈希命名:使用 SHA256 哈希的前 16 位十六进制字符命名,避免重复和冲突
- CloudFront URL:Lambda 自动将相对路径替换为 CloudFront 全球加速 URL
现在的问题是:如何将这些处理好的文档快速接入RAG系统,并确保用户在问答时能够看到原始图片?
本文将聚焦于工程化实践,介绍三个关键环节:
核心实践内容
实践一:MinerU 文档快速导入 Dify
- 直接导入 Markdown 文档到 Dify,构建知识库
- 配置最佳分块策略(chunk_size、overlap)
- 验证导入效果和检索准确率
实践二:Prompt 工程 – 图片显示的关键技巧
- 如何在 Prompt 中指示模型保留图片链接
- 处理不同类型内容(表格、图片、公式)的最佳实践
- 避免图片链接被转换为文字描述
实践三:多模态 RAG 的示例
- 从用户提问到返回带图片的答案
- 实际案例:技术文档问答、财务报表分析
- 常见问题和解决方案
通过本文的实践指导,您将能够快速将 MinerU 处理的文档接入 Dify,并实现带图片展示的智能问答系统。
实践一:MinerU 文档快速导入 Dify
为什么选择 Dify?
Dify 是一个开源的 LLM 应用开发平台,提供可视化的 RAG 工作流构建能力。相比从零编码,使用 Dify 可以将开发周期从 2-3 个月缩短至 1-2 周。Dify在aws的部署方法参考AWS Blog: 基于 Amazon EKS 部署高可用 Dify 或 使用Docker Compose部署。
核心优势:
- 可视化工作流设计:拖拽式界面,无需编写向量数据库集成代码,业务人员也能快速上手
- 多模型支持:支持 Amazon Bedrock托管模型、OpenAI、Claude、Gemini、Deepseek、硅基流动托管模型等主流模型接入方式。
- 智能知识库管理:自动处理文档分块、向量化、检索优化,内置多种分块策略。
- 企业级功能:用户管理、API 接口、使用统计、成本控制、审计日志。
- 插件生态:丰富的第三方集成,支持自定义工具开发。
选择 Dify 的关键因素:
- 快速验证 MVP
- 2-3 天即可搭建可用的原型系统
- 快速验证业务价值,降低试错成本
- 支持快速迭代和调整
- 成本可控
- 可自主部署,数据完全可控
- 按需扩展,避免过度投入
- 多模态优势
- 与 MinerU 完美配合,保留图片、表格、公式
- 支持复杂文档的完整展示
- 提供优秀的用户体验
- 中文友好
- 对中文文档处理效果优秀
- 活跃的中文社区,问题响应快
- 丰富的中文文档和教程
- 可扩展性强
- 支持自定义 Prompt 和工作流
- 可集成自定义工具和 API
- 支持二次开发和深度定制
导入 MinerU 处理的文档
步骤 1:准备文档
从 S3 下载 MinerU 处理后的 Markdown 文件:
步骤 2:创建知识库
在 Dify 控制台进行详细配置:
- 登录 Dify 管理界面
- 访问 Dify 部署地址(如:https://your-dify.com)
- 使用管理员账号登录
 |
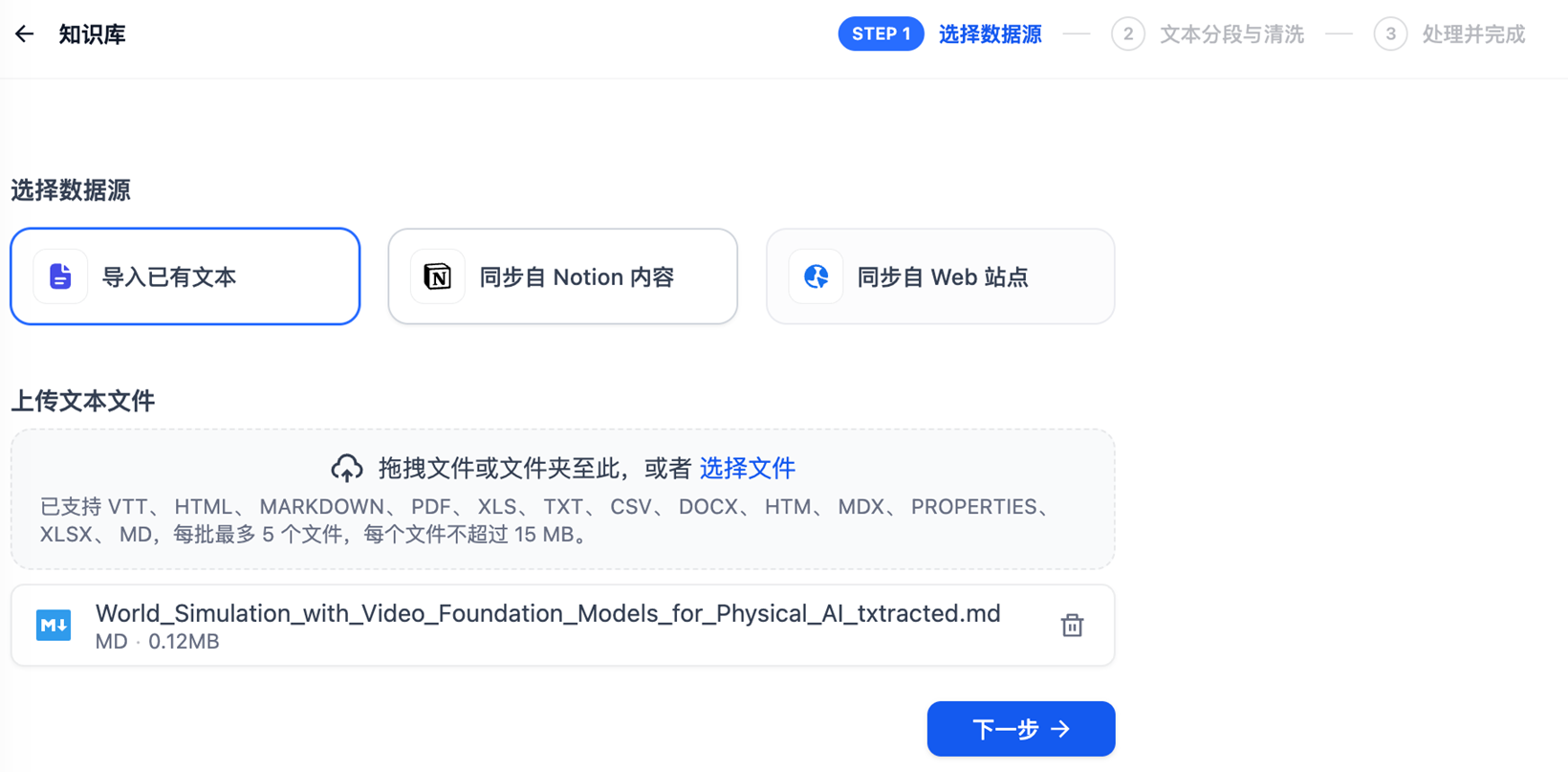
- 创建知识库并上传markdown文档
- 进入「知识库」→「创建知识库」
- 知识库名称:如「技术文档库-2024Q4」
- 描述:详细说明知识库内容和用途
- 可见性:根据需要选择「私有」或「团队共享」
- 支持的格式:Markdown、TXT、HTML、PDF(我们选择 MinerU 处理后的 Markdown)
- 支持单个或批量上传
- 建议每次上传 10-20 个文档,避免超时
- 上传后会自动开始处理,可以在「处理状态」中查看进度
 |
3:配置分块、检索策略及Embeding大模型
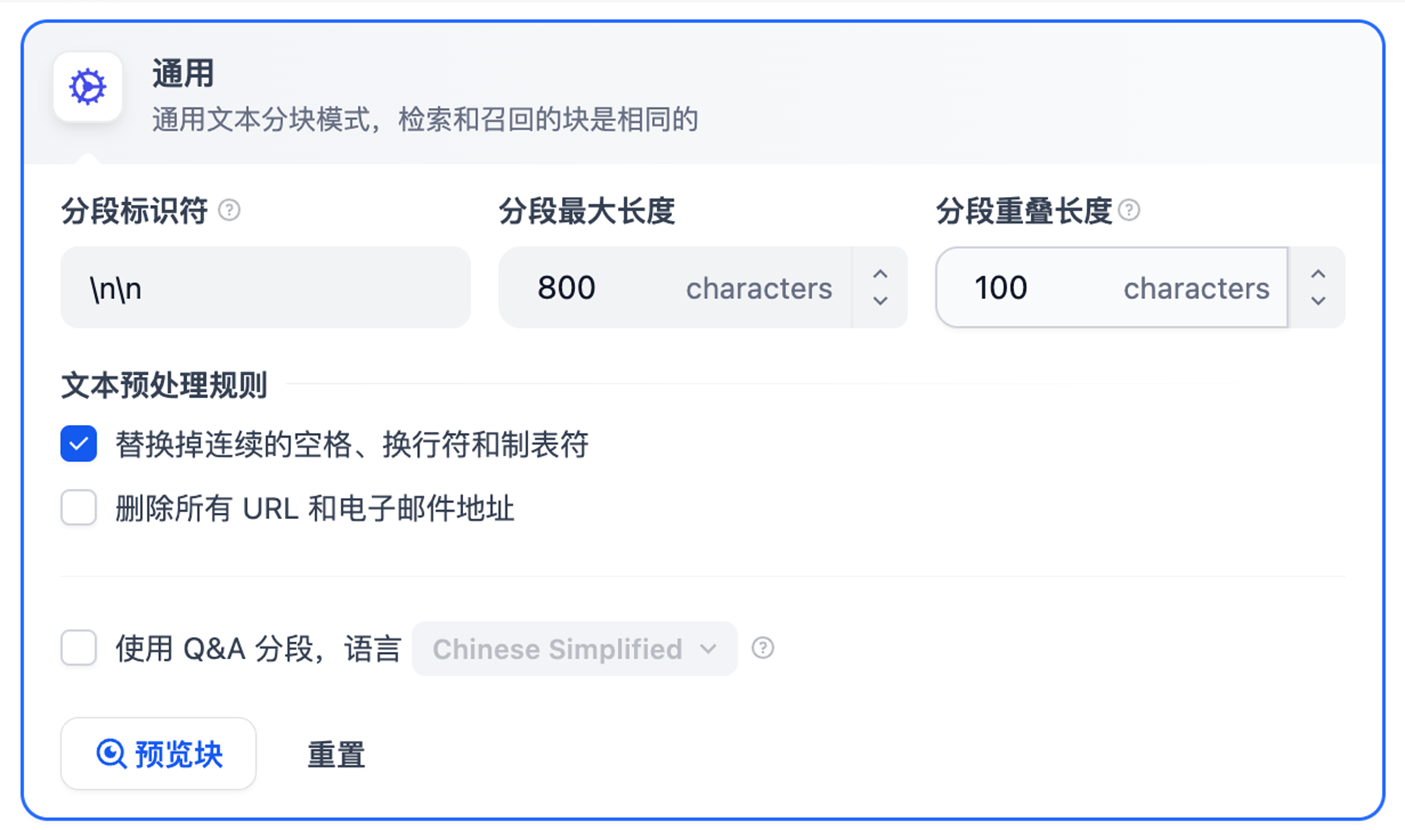
参数详解与最佳实践:
- chunk_size: 800
- 为什么选择 800?
- MinerU 输出的段落通常较长,包含完整的表格和图片上下文
- 经过测试,800 字符能很好地保留完整的表格(通常 500-1000 字符)
- 太小(如 256)会导致表格被截断,图片上下文丢失
- 太大(如 1500)会导致检索精度下降,噪音增加
- 不同文档类型的建议:
技术文档(含大量代码):600-800 财务报表(含大量表格):800-1000 法律合同(长段落):1000-1200 简短问答(FAQ):300-500
- chunk_overlap: 100
- 为什么需要重叠?
- 确保重要信息不会在分块边界丢失
- 特别重要:图片说明文字通常在图片前后,重叠能保证完整性
- 12.5% 的重叠率(100/800)符合学术界的最佳实践
- 重叠率建议:
标准文档:10-15%(80-120 字符) 技术文档:15-20%(120-160 字符) 法律文档:20-25%(160-200 字符)
 |
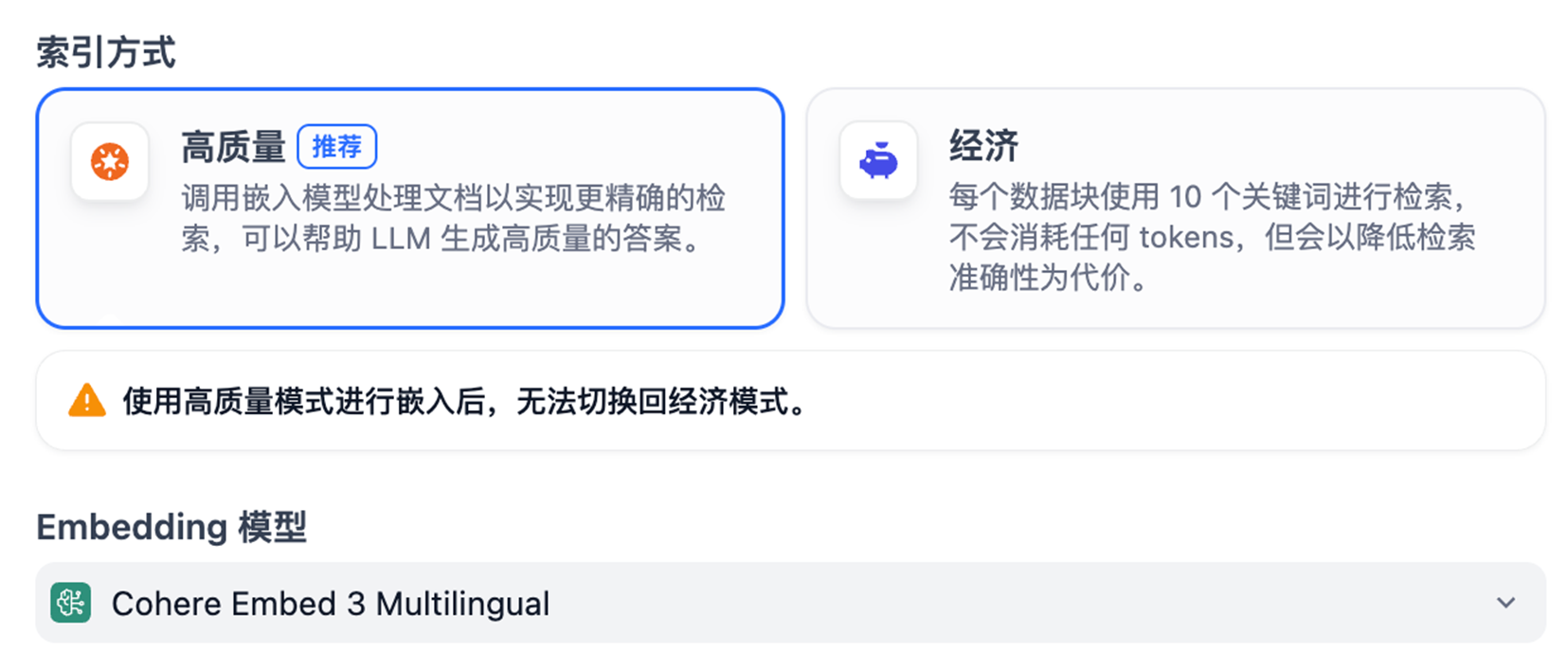
- indexing_technique: high_quality
- 混合检索的优势:
- 同时使用关键词检索(BM25)和向量检索(Embedding)。
- 全文检索:精确匹配专业术语、产品名称。
- 向量检索:语义理解,处理同义词和相关概念。
- 混合检索,准确率提升 30-50%。
- 索引模式:
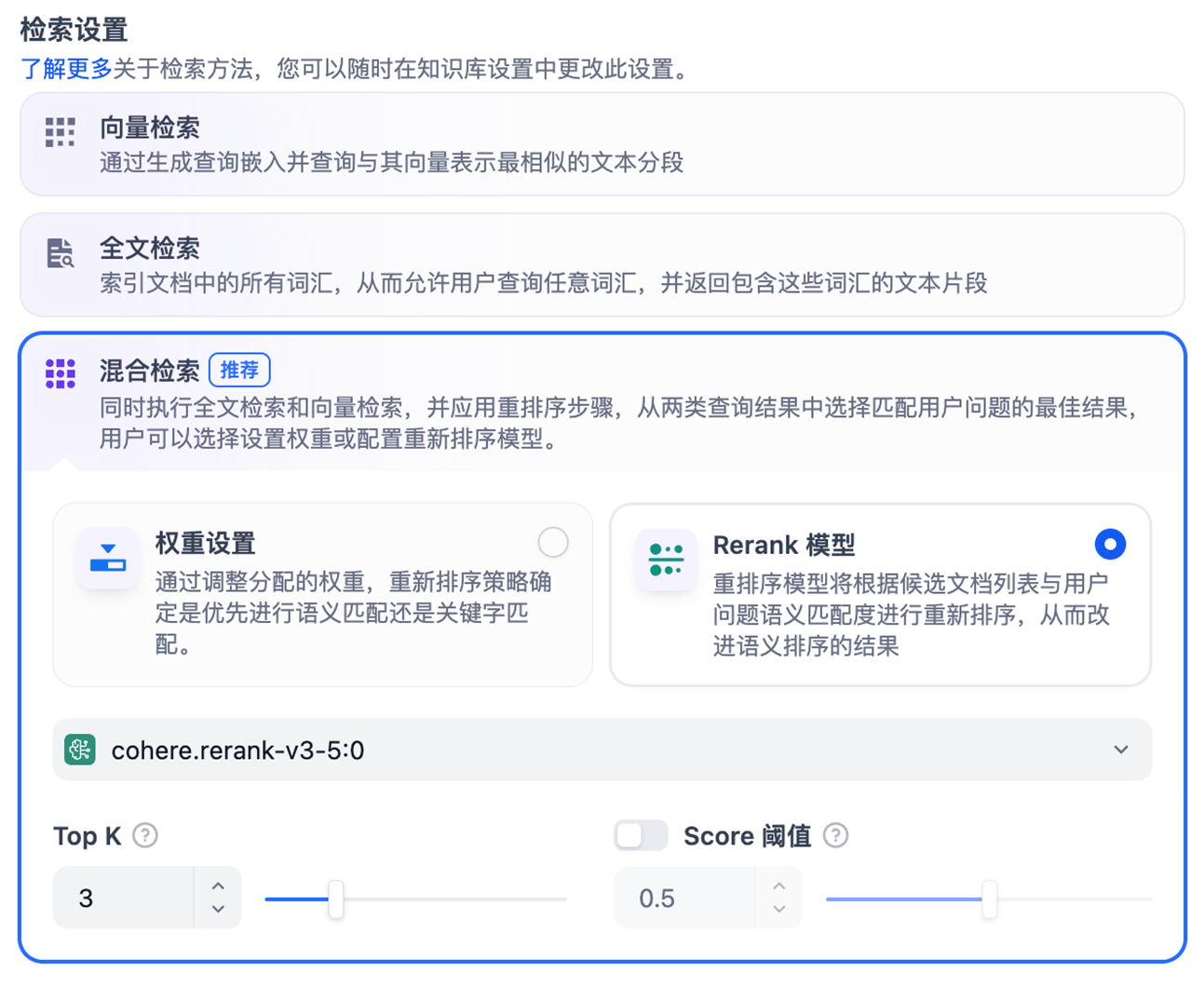 |
经济模式:仅关键词检索,成本低,速度快,准确率一般
高质量模式:混合检索,成本略高,准确率显著提升。
大模型选择:Amazon Bedrock提供了包含Titan、Cohere的多种Embeding及Rerank大模型,完全可以满足RAG需求。
 |
- preprocessing_rules
- remove_urls_emails: false(关键配置)
- 必须设置为 false,否则图片 URL 会被删除。
- 这是最常见的配置错误,导致图片无法显示。
- remove_extra_spaces: true
- 清理多余空格,提升检索效果。
- 不影响图片 URL 和表格格式。
- remove_stopwords: false
- 保留停用词(如”的”、”是”、”在”)。
- 对于技术文档,停用词可能包含重要信息。
步骤 4:导入效果
转换完成后,会显示该文档已启用。
 |
实践二:构建简单知识库智能体
Dify提供了高效的智能体构建方法,包含工作流、聊天助手等多种应用。
 |
本文通过创建聊天助手,快速验证生成的知识库效果。
实践三:Prompt 工程 – 图片、公式、表格显示的关键技巧
端到端流程
在 RAG 系统中,即使知识库中包含图片 URL,大模型也可能:
- 忽略图片链接:只返回文字描述
- 使用错误格式:返回纯文本 URL 而非 Markdown 图片格式
- 使用自己的图片:大模型使用训练数据中的图片,而非检索到的实际图片
解决方案:精确的 Prompt 指令
Prompt 模板:
注意,请将模型输出内容严格按照以下格式输出,使用中文:
## 输出要求
- 如果知识库输出的内容包含图片 URL,请使用以下格式输出:

- 如果输出的内容不包含图片 URL,请直接输出文字内容。
## 重要说明
– 输出的 URL 直接使用 {{#context#}} 中的图片地址(jpeg、png 等图片格式)
– URL 必须为 http 或 https 开头,如果不是,则没有 URL
– 如果有多张图片,则都按照  的格式分别进行显示
– **不能使用大模型自己存储的图片地址**
– **必须使用检索到的实际图片 URL**
## 用户问题
{{query}}
## 检索到的文档内容
{{#context#}}
## 回答
请基于上述文档内容回答问题,并严格按照输出要求显示图片。
Prompt 设计要点:
- 明确输出格式:开头就强调”严格按照以下格式输出”,提高模型遵循度
- URL 来源限制:明确指出只能使用 {{#context#}} 中的图片地址,防止模型幻觉
- 协议验证:要求 URL 必须是 http/https,过滤无效链接
- 多图处理:明确说明多张图片都要显示,避免遗漏
- 禁止行为:明确禁止使用模型自己的图片地址
增强版 Prompt
如果需要更强的控制力和更好的输出质量,可以使用以下增强版 Prompt:
系统 Prompt:
实际效果对比
未使用恰当 Prompt:
 |
可以进行知识库检索,但只能输出文本信息。
使用恰当Prompt:
 |
可以进行更加丰富的多模态内容显示。
Prompt 优化技巧与最佳实践
技巧 1:使用明确的格式指令
✅ 好的写法:
“必须使用以下格式输出:”
❌ 不好的写法:
“如果有图片,请显示出来”
技巧 2:强调 URL 来源
✅ 好的写法:
“输出的 URL 直接使用 {{#context#}} 中的图片地址”
“不能使用大模型自己存储的图片地址”
❌ 不好的写法:
“显示相关图片”(模型可能使用训练数据中的图片)
技巧 3:处理多图场景
✅ 好的写法:
“如果有多张图片,则都按照  的格式分别进行显示”
❌ 不好的写法:
“显示图片”(可能只显示第一张)
技巧 4:协议验证
✅ 好的写法:
“URL 必须为 http 或 https 开头,如果不是,则没有 URL”
原因:过滤掉相对路径和无效链接
技巧 5:使用中文输出
✅ 好的写法:
“注意,请将模型输出内容严格按照以下格式输出,使用中文”
原因:明确语言要求,提高用户体验
总结
本文聚焦于工程化实践,介绍了如何将MinerU处理的文档快速接入Dify,并实现带图片展示的智能问答系统。
关键成果
通过正确的 Prompt 工程,实现了:
- 用户体验提升:用户可以直接看到原始图表,而非文字描述
- 多模态支持:同时展示文字、表格、图片、公式
结合第一篇文章的文档处理平台,您现在拥有了一个完整的企业级 RAG 系统解决方案:
- Blog1:MinerU + Serverless + CloudFront(文档处理 + 图片加速)
- Blog2:Dify + Prompt 工程(知识库 + 图片显示)
从文档处理到智能问答,实现了高准确率、快速响应和优秀的用户体验。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
