亚马逊AWS官方博客
基于 MinerU 和 AWS Serverless 构建企业级 RAG 文档处理平台-文档处理平台搭建
本文是 RAG系统构建系列的第一篇,重点介绍文档处理平台的架构设计。第二篇文章《基于 MinerU 和 AWS Serverless 构建企业级 RAG 文档处理平台-平台搭建-聊天助手部署与 Prompt 工程》将介绍如何将本平台与 Dify 集成,构建完整的智能问答系统。
前言:RAG 系统面临的核心挑战
随着大语言模型技术的快速发展,检索增强生成(RAG)已成为企业级 AI 应用的核心技术之一。然而,行业实践表明,有相当高比例的企业 RAG 系统在生产环境中未能达到预期效果。正如埃森哲在《2025年AI扩展指南》中指出的,尽管超过 80% 的企业都进行过 AI 实验,但能成功将其扩展到核心业务的企业不足 30%。深入分析发现,RAG 系统问题的根源往往不在于大模型本身的生成能力,而在于上游文档处理环节的质量有待提升。
多模态大模型直接处理文档的局限性
当前企业级文档处理领域呈现出多元化的技术路径。通用多模态大语言模型(MLLM)方案虽然部署简单、交互灵活,但在企业级应用中面临以下核心挑战:
- 准确性与一致性问题
在真实企业文档中,复杂表格、跨页结构、合并单元格、嵌套列表等格式较为常见。当前主流 MLLM 在此类任务上的准确率通常为 60%~75%,低于企业级应用对关键信息提取的精度要求(通常需 ≥95%)。
此外,由于生成式模型固有的随机性(temperature > 0),同一文档多次上传可能得到不同解析结果。尽管主流模型(如 GPT-4o 支持 512MB、Gemini 2.0 支持 50MB 的文件上传)的上下文窗口已扩展至 128K~200K tokens,但在处理超长文档时,模型对中间部分信息的注意力权重可能显著衰减,导致”Lost in the Middle”问题。研究表明,当文档长度超过 8K tokens 时,模型对中段信息的召回率可能下降 40% 以上。
- 成本与规模化挑战
以商用 API(如 GPT-4o、Gemini)为例,其文档处理成本约为 $0.015–$0.05 每页。对于需处理百万级页数的企业级应用(如档案数字化、审计资料解析),总成本可达数十万美元,远超企业预算。高频调用的成本问题严重制约了大规模部署的经济性。
- 数据安全与合规风险
使用第三方 API 处理企业文档意味着数据需上传到外部服务器,这在金融、医疗、法律等对数据安全有严格要求的行业中存在合规风险。GDPR、HIPAA 等法规要求企业对敏感数据保持完全控制权,而第三方 API 方案难以满足这一要求。同时,输出结果的不确定性也阻碍了流程自动化和审计追溯。
解决方案:MinerU + AWS Serverless 的三大核心优势
本文将介绍如何基于 MinerU 专业文档解析引擎 和 AWS Serverless 架构 构建一个高性能的企业级文档处理平台。这个方案通过三个核心技术组件的深度整合,能够较好地解决传统方案的痛点。
优势一:MinerU 专业解析引擎 – 准确性与性能的良好平衡
为什么选择 MinerU?
MinerU 作为新一代 AI 驱动的文档解析引擎,专门针对企业级 RAG 应用的需求而设计。与多模态大模型的通用处理能力相比,MinerU 在以下方面具有显著优势:
核心技术特性
MinerU 2.5 采用两阶段推理架构(布局分析 + 内容识别),仅 1.2B 参数即实现业界领先的解析能力:
- 文档结构理解
- 智能过滤页眉页脚、页码、水印等干扰元素
- 保留标题层级、段落、列表等语义结构
- 支持单栏/多栏/复杂排版的阅读顺序重建
- 多模态内容提取
- 表格解析:转换为 HTML/Markdown(F1: 94.8%)
- 公式识别:转换为 LaTeX 格式(准确率: 92.5%)
- 图片提取:自动提取图表、示意图等视觉内容
- 工程化优势
- 确定性输出:避免生成式模型随机性,支持可审计流程
- GPU 加速:32 页文档处理时间约 1.7 分钟
- 跨平台部署:支持 CPU/GPU、Windows/Linux/macOS
性能对比
根据 OmniDocBench 权威基准测试(涵盖 10 万+ 样本的多场景文档解析基准),MinerU 2.5 版本(1.2B 参数)在核心任务上全面超越大模型和专业工具:
| 工具/模型 | 参数规模 | 布局分析(F1) | 表格解析(F1) | 公式识别(准确率) | 文本识别(CER) |
| MinerU 2.5 | 1.2B | 96.2% | 94.8% | 92.5% | 1.8% |
| GPT-4o | 约1.5T | 93.5% | 91.2% | 89.7% | 2.1% |
| Gemini 2.5 Pro | 约1.8T | 92.8% | 90.5% | 88.9% | 2.3% |
| PP-StructureV3 | – | 90.1% | 88.3% | 82.6% | 3.5% |
| dots.ocr | – | 89.5% | 87.6% | 81.2% | 3.8% |
关键优势:
- 参数效率: MinerU 参数规模仅为 GPT-4o 的 1/1000,却实现更高准确率
- 处理速度: 1.7 分钟/32页(GPU 加速),比大模型快 5-10 倍
- 批量处理: 无限制,适合企业级大规模文档处理
- 文件大小: 无限制,支持超大文档处理
- 长文档一致性: 优秀,避免”中间丢失”问题
- 成本优势: 本地部署无 API 调用费用,大规模处理成本更低
典型应用场景
- 财务报表:资产负债表结构化提取,保留会计科目层级关系
- 学术论文:公式转 LaTeX、表格转 HTML、图表独立提取
- 技术文档:多栏排版处理、代码块识别、架构图提取
- 合同审核:扫描件 OCR、条款结构化、关键信息定位
相比多模态 LLM 将表格转为线性文本描述,MinerU 保留完整结构信息,更适合企业级应用。
优势二:AWS Serverless 架构 – 弹性扩展与成本优化
为什么选择 Serverless?
传统的文档处理系统往往面临资源利用率低、运维成本高、扩展性差等问题。AWS Serverless 架构通过事件驱动和按需计费的模式,能够较好地解决这些痛点。
核心架构组件
- Amazon ECS + Auto Scaling – 智能容器编排
- 弹性扩缩容:根据队列深度自动调整实例数量(0-10 个)
- 按需启动:无任务时缩容至 0,节省 100% 计算成本
- GPU 加速:使用 g4dn.xlarge 实例,配备 NVIDIA T4 GPU
- Amazon SQS + DynamoDB – 任务管理
- 消息队列:确保任务不丢失,支持重试和死信队列
- 状态跟踪:毫秒级延迟的实时任务状态查询
- 解耦架构:Lambda 触发器和 ECS 处理器完全解耦
- AWS Lambda – 事件驱动触发
- S3 事件触发:文件上传自动触发处理流程
- 零运维成本:无需管理服务器,自动扩展
- 按调用计费:仅为实际执行时间付费
成本优化效果
| 场景 | 传统方案 | Serverless 方案成本节约 |
| 低频使用(10 文档/天) | MATHINLINE142/月(按需) | 89% |
| 中频使用(100 文档/天) | MATHINLINE2120/月 | 68% |
| 高频使用(1000 文档/天) | MATHINLINE3393/月(动态) | 48% |
弹性扩展能力
优势三:私有化部署 – 数据安全与成本优化
为什么选择私有化部署?
对于处理敏感文档的企业场景,私有化部署提供了更好的数据控制和成本优化方案。
核心架构特点
- 完全私有部署
- 所有资源部署在用户自己的 AWS 账号中
- 文档数据不离开用户的云环境
- 用户拥有完整的数据控制权和访问权限
- 多层安全保障
- 传输加密:S3 和 CloudFront 支持 HTTPS/TLS 加密
- 存储加密:S3 服务端加密(SSE-S3 或 SSE-KMS)
- 访问控制:IAM 角色和策略精细化权限管理
- 网络隔离:VPC 私有网络,可配置 VPC Endpoint
- 合规性支持
- 支持 GDPR、HIPAA、SOC 2 等合规要求
- 支持数据本地化(选择特定 AWS 区域部署)
- 完整的审计日志(CloudTrail + CloudWatch)
- 数据生命周期管理(S3 生命周期策略)
- 对比第三方 API 方案
| 维度 | 本方案(私有化部署) | API方案 |
| 数据控制 | 数据不出用户环境 | 需上传到第三方服务器 |
| 合规性 | 完全可控,支持审计 | 依赖第三方合规声明 |
| 成本 | 无 API 费用,按需付费 | 按 Token 计费,成本高 |
| 可用性 | 自主控制,无依赖 | 依赖第三方服务稳定性 |
适用场景
本方案特别适合以下场景:
- 汽车制造:技术规范、维修手册、设计图纸、质量检测报告等技术文档
- 金融行业:财务报表、客户资料、交易记录等敏感数据处理
- 医疗健康:病历、检查报告等受 HIPAA 监管的数据
- 法律服务:合同、案件材料等需要保密的文档
- 通用场景:希望降低长期运营成本的大规模文档处理需求
优势四:多模态 RAG 支持 – 图文并茂的智能问答
为什么多模态 RAG 很重要?
在企业级 RAG 应用中,纯文本检索往往无法满足实际业务需求。复杂表格、公式、图表等视觉信息在转换为文本时会丢失关键的结构和语义。本系统通过 CloudFront + Lambda 自动化架构,实现了完整的多模态 RAG 能力,让 AI Agent 能够同时理解和呈现文字与图片信息。
多模态 RAG 的核心价值
- 完整的信息呈现
- 图表完整性:财务趋势图、架构图等保留视觉语义,避免文本转换失真
- 专业图形:化学结构式、电路图、地图等专业内容保证准确性
- 混合策略:表格用 HTML(便于检索),图表用图片(保留视觉),实现最佳平衡
- 增强的 AI 理解能力
- 多模态检索:同时检索文本和图片内容,提高召回率
- 视觉问答:结合 Aamazon Bedrock中的Claude、Nova、Deepseek等多模态模型,基于图片深度分析
- 上下文关联:AI Agent 能够关联文字描述和对应图表,提供更准确的答案
- 更好的用户体验
- 快速决策:金融分析师直接查看趋势图,医生查看影像报告
- 图文并茂:Agent 回答时同时展示文字解释和原始图片
- 可追溯性:用户可查看信息原始来源,增强系统可信度
技术实现架构
- 自动化处理:Lambda 自动替换图片路径为 CloudFront URL
- 全球加速:CloudFront CDN 确保图片访问 < 100ms
- 安全可控:OAI 访问控制、WAF 集成、HTTPS 加密传输
- 无缝集成:Markdown 中的图片链接可直接被 RAG 系统使用
系统架构设计
AWS Serverless 架构全景
本系统采用完全 Serverless 的架构设计,通过 AWS 托管服务实现高可用、弹性扩展和成本优化:
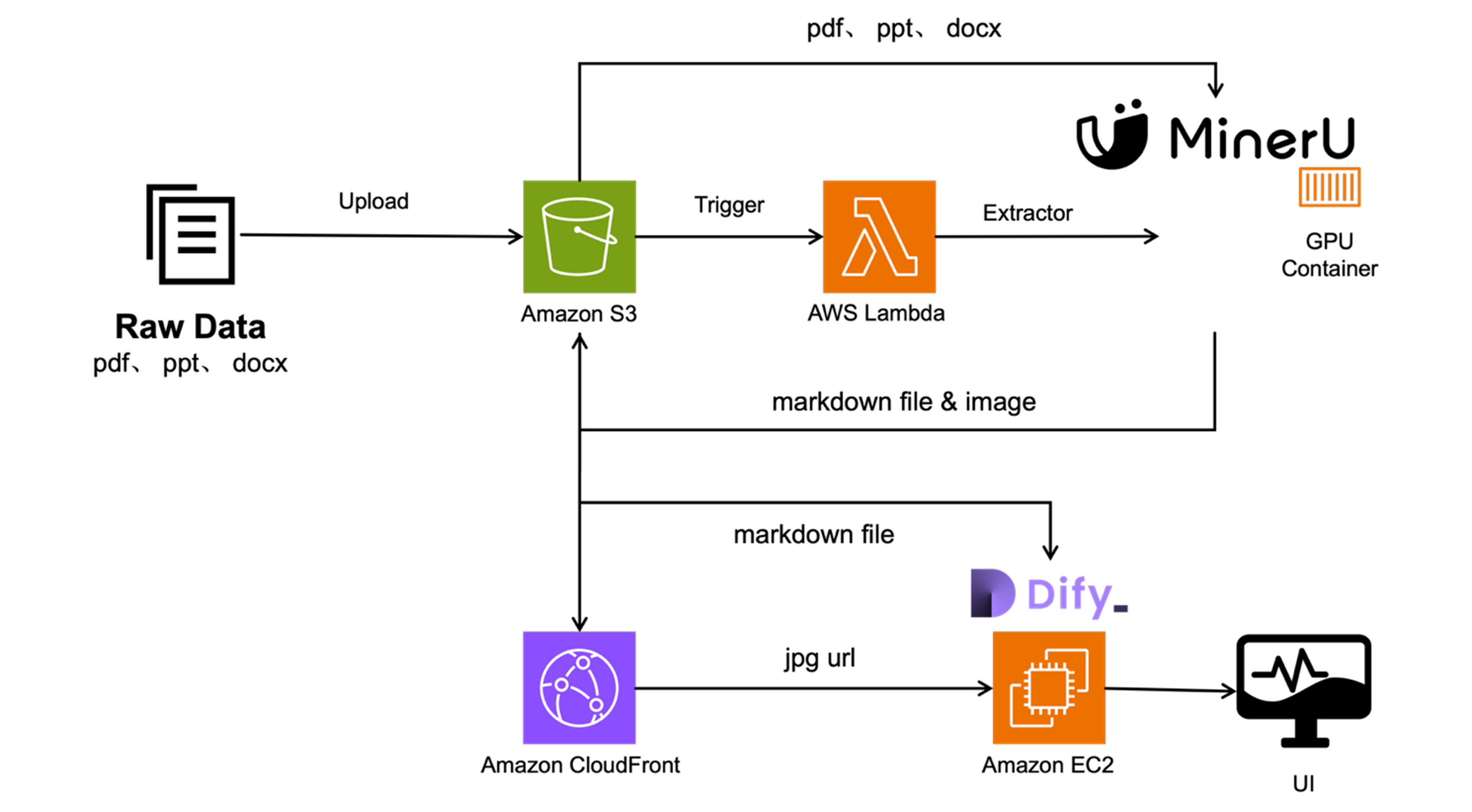 |
核心服务与业务流程
完整处理流程:
- 文件上传触发 → 用户上传 PDF 到 S3
input/,自动触发 Lambda 1 - 任务创建 → Lambda 1 生成 Job ID,在 DynamoDB 创建任务记录(状态:pending),发送 SQS 消息
- 弹性计算 → ECS 容器从 SQS 轮询任务,Auto Scaling 根据队列深度自动扩缩容(0-10 实例)
- 文档处理 → MinerU GPU 容器(g4dn.xlarge + NVIDIA T4)智能解析:
- 表格 → HTML/Markdown
- 图表 → 独立图片文件
- 公式 → LaTeX
- 文本 → 保留结构
- 结果上传 → 处理结果上传到 S3
processed/{job-id}/,更新 DynamoDB 状态为 completed - 路径替换 → Lambda 2 检测
.md文件创建,自动替换图片相对路径为 CloudFront URL - CDN 加速 → CloudFront 全球边缘节点分发图片,访问延迟 < 100ms
- RAG 集成 → 系统检索到的内容包含结构化表格(HTML)、可访问图片(CloudFront URL)、LaTeX 公式
关键技术特性:
- 可靠性保证:SQS 死信队列捕获失败任务(最多重试 3 次),可见性超时 3600 秒防止重复处理
- 弹性扩展:队列消息 > 10 时扩容,< 2 时缩容,无任务时缩至 0,成本节省最高 89%
- 状态管理:DynamoDB 记录任务完整生命周期(pending → processing → completed/failed)和处理元数据
- 监控告警:CloudWatch 聚合日志,监控队列深度、处理时间、错误率,异常时自动通知
部署与使用
快速部署
系统提供一键部署脚本,支持跨账号、跨区域部署:
按顺序部署包含:
- 基础设施堆栈:VPC、ECS 集群、Auto Scaling 组
- 数据服务堆栈:S3 Bucket、DynamoDB 表、CloudFront Distribution
- 触发服务堆栈:Lambda 1(任务创建)、Lambda 2(MD 后处理)
- 计算服务堆栈:ECS 任务定义、容器配置
 |
使用示例
上传文档到创建的S3中的input文件夹:
Option1-aws cli上传:
aws s3 cp document.pdf s3://mineru-ecs-production-data-{account-id}/input/
Option2-aws console上传:
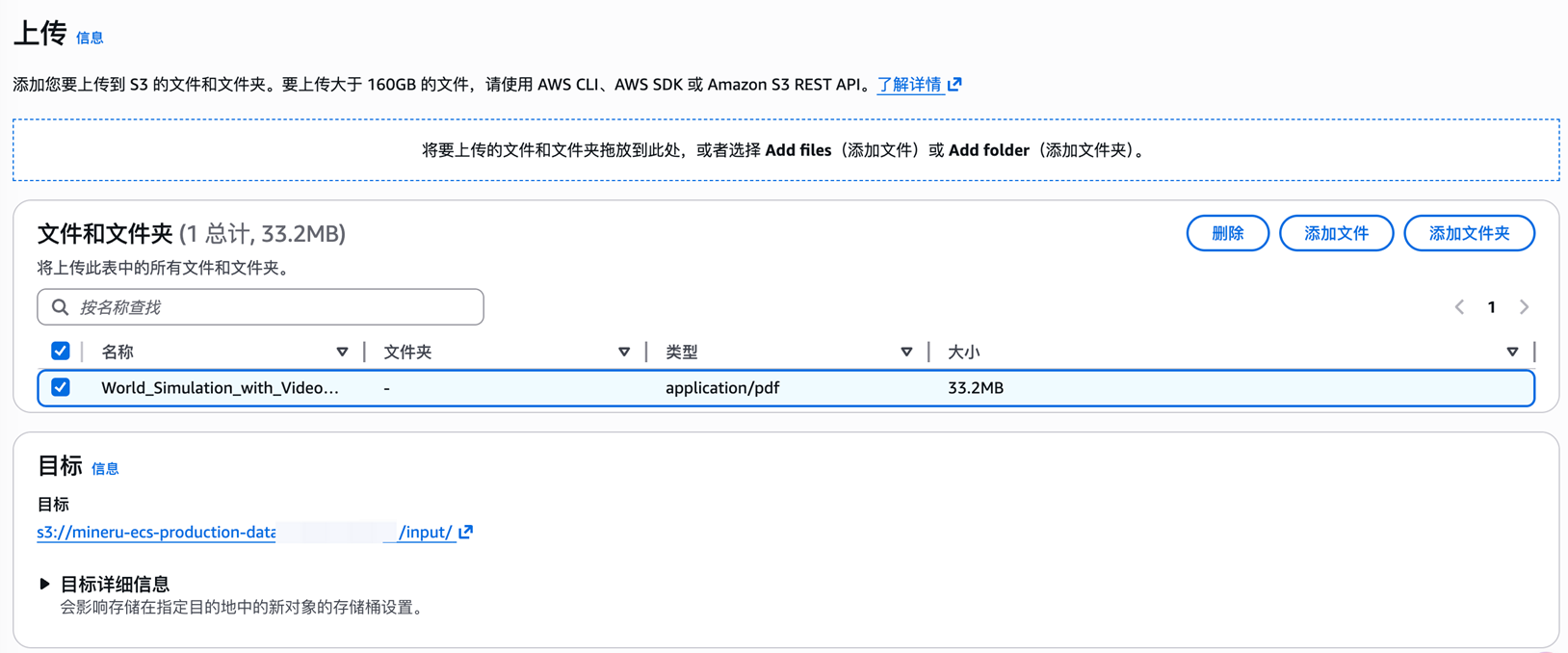 |
监控处理状态:
Option1-aws cli:
aws dynamodb scan \
--table-name mineru-ecs-production-processing-jobs \
--limit 5
Option2-aws console:
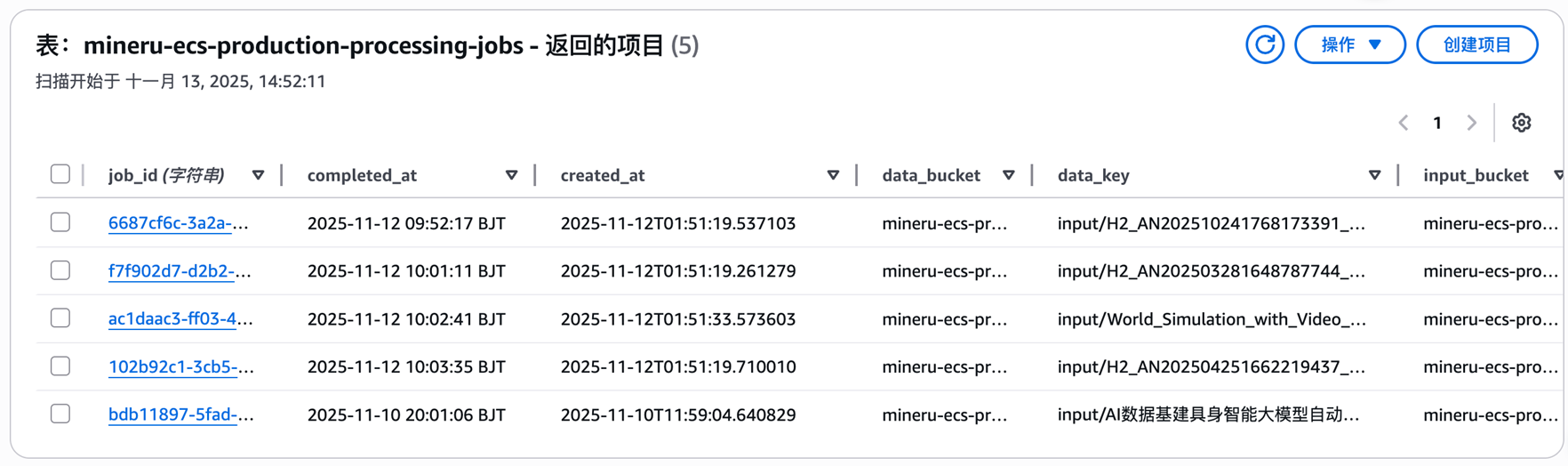 |
DynamoDB中的表 mineru-ecs-production-processing-jobs 会显示每个任务的启动时间、结束时间及任务执行情况。
下载结果:
aws s3 sync \
s3://mineru-ecs-production-data-{account-id}/processed/{job-id}/ \
./results/
也可以在results文件夹下手动下载生成的md文件。
文档架构如下:
验证处理结果:
 |
如上图为生成文件结构示例,生成结果存储在对应的s3/output/job-id文件夹,包含md文件,pdf过程文件,提取的图片文件存储在image文件夹。由于配置了cloudfront cdn服务,图片可以通过互联网访问,也可以在cloudfront限制仅允许您应用的服务器访问。
本文使用World Simulation with Video Foundation Models for Physical AI的pdf文档作为案例,读者客户查看实际转换效果。
原始文档名称:World Simulation with Video Foundation Models for Physical AI
下载地址:https://arxiv.org/pdf/2511.00062
说明:此文档中图片存储位置为github文件夹,目的是方便展示,使用本方案后实际图片存储位置在aws s3, 使用cloudfront进行分发,写入md文档中的位置为cloudfront的网址。
删除部署
# 完整清理所有资源(自动执行所有步骤)
./deploy-cross-account.sh delete-all
# 带 AWS Profile 的删除
./deploy-cross-account.sh –profile prod-account delete-all
# 删除特定环境
./deploy-cross-account.sh -e production delete-all
脚本会自动执行:
- ✓ 清空 S3 存储桶
- ✓ 删除 CloudFormation 堆栈(按相反顺序)
- ✓ 清理 ECR 镜像仓库
- ✓ 删除 CloudWatch 日志组
- ✓ 验证清理结果
注意事项:
- 删除操作不可逆,请确保已备份重要数据
- 推荐使用脚本删除,自动处理依赖关系
- S3 存储桶必须先清空才能删除
- 堆栈需要按相反顺序删除(先删除依赖资源)
总结
本文介绍的 MinerU + AWS Serverless + CloudFront 解决方案,通过专业文档解析引擎(表格解析 94.8%、公式识别 92.5%)、弹性 Serverless 架构(成本节省最高 89%)和全球 CDN 加速(图片访问 < 100ms),为企业级 RAG 应用提供了从文档处理到多模态展示的完整能力。
该方案适用于金融财报分析、学术论文解析、企业合同管理、医疗病历处理、公司内部文档处理等场景,在文档处理环节相比人工录入提升 50 倍效率,同时保证确定性输出和合规审计能力
第二篇文章《基于 MinerU 和 AWS Serverless 构建企业级 RAG 文档处理平台-平台搭建-聊天助手部署与 Prompt 工程》将介绍如何将本平台与 Dify 集成,构建完整的智能问答系统。
参考文献
- Accenture – The Front-runners’ Guide to Scaling AI
埃森哲关于企业 AI 扩展的权威研究报告,指出仅 8% 的企业成功扩展 AI 应用
https://www.accenture.com/us-en/insights/data-ai/front-runners-guide-scaling-ai - Accenture – How to Scale AI and Realize Value Across the Enterprise
企业级 AI 规模化部署的实践指南
https://www.accenture.com/us-en/insights/consulting/how-to-scale-ai-for-value - MinerU:开源多模态文档解析工具,高效提取 PDF 中表格、公式与复杂布局内容
https://www.aipuzi.cn/ai-news/mineru.html
- OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
CVPR 2025 收录的文档解析基准测试,包含 1355 页、9 种文档类型、超过 10 万个精细标注
论文地址:https://arxiv.org/html/2412.07626v1
项目主页:https://www.2077ai.com/dataset/dataset-omnidocbench - Lost in the Middle: How Language Models Use Long Contexts
Stanford 大学关于长上下文语言模型性能衰减的研究,发表于 TACL 2024
论文地址:https://arxiv.org/abs/2307.03172
ACL Anthology:https://aclanthology.org/2024.tacl-1.9/ - OpenAI – File Uploads FAQ
GPT-4o 文件上传限制:512MB/文件,2M tokens/文件
https://help.openai.com/en/articles/8555545-file-uploads-faq
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
