亚马逊AWS官方博客
在 AWS 上构建事件驱动的弹性 Kubernetes 应用:结合 EKS + KEDA 的架构升级与实践
关于加勒比熊猫
加勒比熊猫成立于 2019 年,是一家专注海外知识分享以及休闲游戏市场,集产品研发,运营和发行于一体的企业。自成立以来,公司一直专注创作高品质知识分享工具类App和休闲类游戏,并持续探索全球市场潜力。截至目前,公司自研产品海外累计下载量已突破1.5亿,其中不仅有多款游戏获得Apple App Store 及Google Play全球推荐,同时多种不同类型的知识分享及阅读产品,在多个重点市场位居应用榜单前列。
挑战:传统伸缩策略不足以满足业务需求
对于一家面向全球市场的软件研发与发行企业而言,应用的伸缩能力并不仅仅是基础设施层面的技术选型问题,而是直接关系到业务稳定性、用户体验与整体成本结构的核心能力。一方面,海外市场用户分布广泛,不同时区的流量高峰差异显著,应用需要具备应对突发流量和周期性波动的能力;另一方面,工具类 App 与休闲游戏在运行形态上往往伴随着异步任务、消息驱动处理和长时间运行的后台逻辑,这些负载特征并不总是与资源使用率线性相关。在这样的业务背景下,如何根据真实业务负载实现快速、精准且低成本的弹性伸缩,成为加勒比熊猫在云原生架构演进过程中必须解决的关键问题。
在传统 Kubernetes 中,Horizontal Pod Autoscaler(HPA) 主要依据 CPU / Memory 指标来调整 Pod 副本数量。对于某些业务场景,比如在线推理服务、消息驱动任务、长时请求处理等,CPU / Memory 并不能准确反映业务负载压力,因此导致:
- 扩容不及时或不足
- 资源浪费或成本骤升
- 难以快速响应突发请求量
创新:构建自定义指标服务实现精细化伸缩
为此,需要一种更贴近业务层面的自动伸缩能力。加勒比熊猫构建了一个基于 Flask 的自定义指标服务应用,作为KEDA外部Scaler的数据源。通过获取当前 Pod 数量,同时基于 waittime (队列的等待时间)的分级扩容策略实现对较长等待时间时可以有更积极的扩容策略,基于 tasklen (进行中任务的数量,当waittime==0时生效)的智能维持策略可以避免因任务量短暂下降后立刻缩容,从而满足高度定制化,更加精准地控制扩缩容的需求。
在上线运行数个月的时间里观察到:”Pod 数量从原来跑空的360个,平均每天缩减到36个。在保证业务 SLA 的前提下,整体计算资源成本显著下降。”这意味着在低峰期或无负载时,系统能够将 Pod 数量大幅缩减,从而极大地减少了不必要的资源浪费。在业务高峰期,系统又能迅速扩容以应对流量冲击。极大地增强了系统弹性,同时自动化的扩缩容机制减少了人工干预的需要,使得运维团队可以更专注于业务逻辑和系统优化,而非手动调整资源。
—— 加勒比熊猫技术合伙人 李凌
解决方案概览:事件驱动伸缩与业务对齐
KEDA 是一个开源的 Kubernetes 控制器,可以根据外部事件源自动调整工作负载副本数量。它不是替代 Kubernetes HPA,而是与 HPA 协同工作,通过提供外部指标让 HPA 做出扩缩容决策:
- 事件驱动:支持数十种事件源,如 AWS SQS、Kafka、Prometheus、HTTP/Cron 等
- Scale to Zero:在无事件触发时,将副本缩容至 0
- 无侵入:无需修改原有 Deployment,可通过自定义资源 ScaledObject 或 ScaledJob 实现扩缩容配置
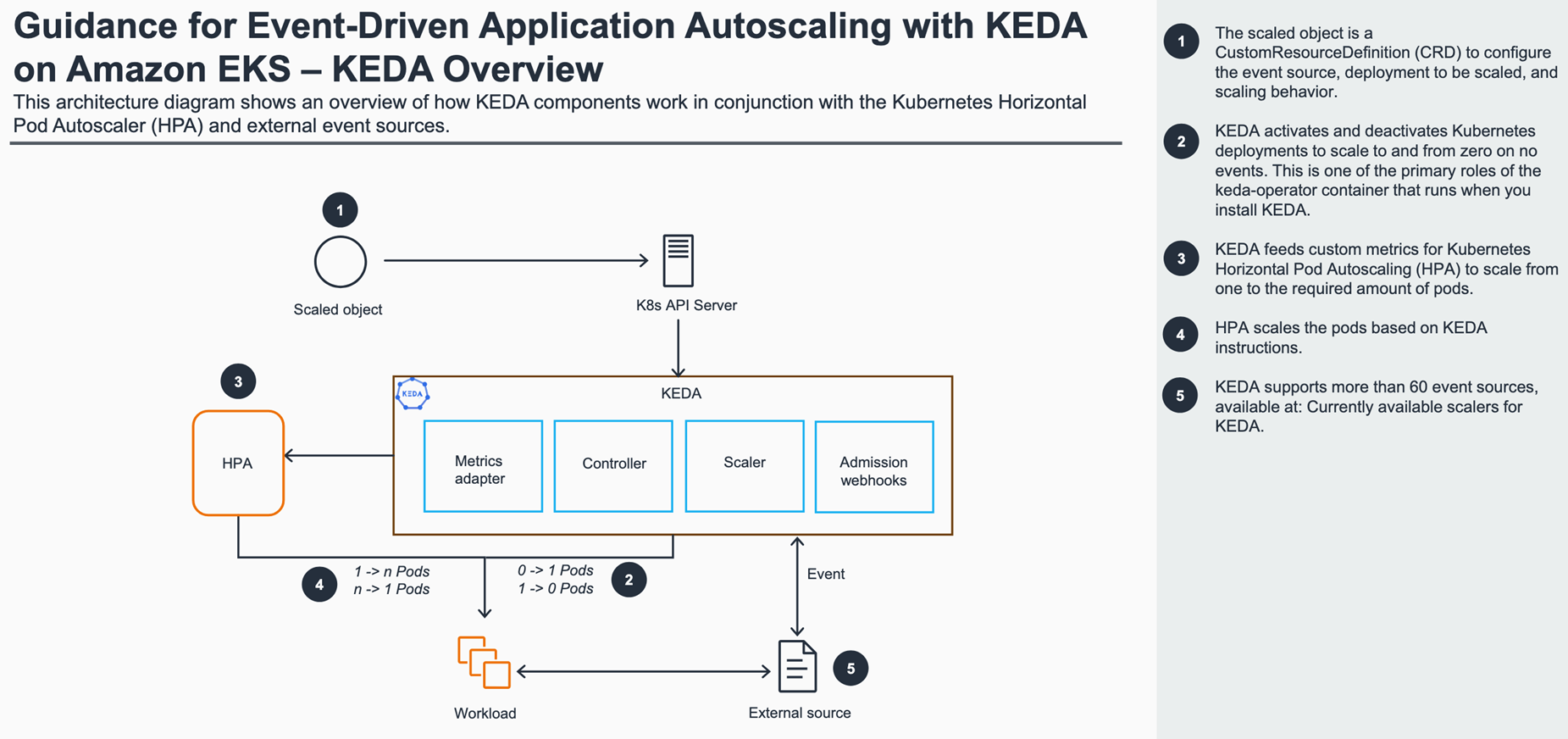 |
这种方式既保留了 Kubernetes 原生弹性,又增强了扩缩容策略的适应性。通过将 KEDA 与 Amazon EKS 结合,可以让 Pod 的扩缩容由“资源指标驱动”转变为“业务事件驱动”。这样,当业务队列长度、请求数、消息积压等指标发生变化时,应用能够更快速、精确地响应。
该方案的核心组件包括:
- Amazon EKS:托管 Kubernetes 控制平面和节点组运行环境;
- KEDA:扩展 Kubernetes 伸缩能力,提供基于业务事件的扩缩容触发;
- Kubernetes HPA:作为底层调度执行扩缩容;
- Cluster Autoscaler / Karpenter(可选):驱动节点层自动伸缩;
- 外部事件源:如 SQS 队列、HTTP 请求计数、Kafka 消息流等。
架构图与运行流程
典型事件驱动自动伸缩架构如下:
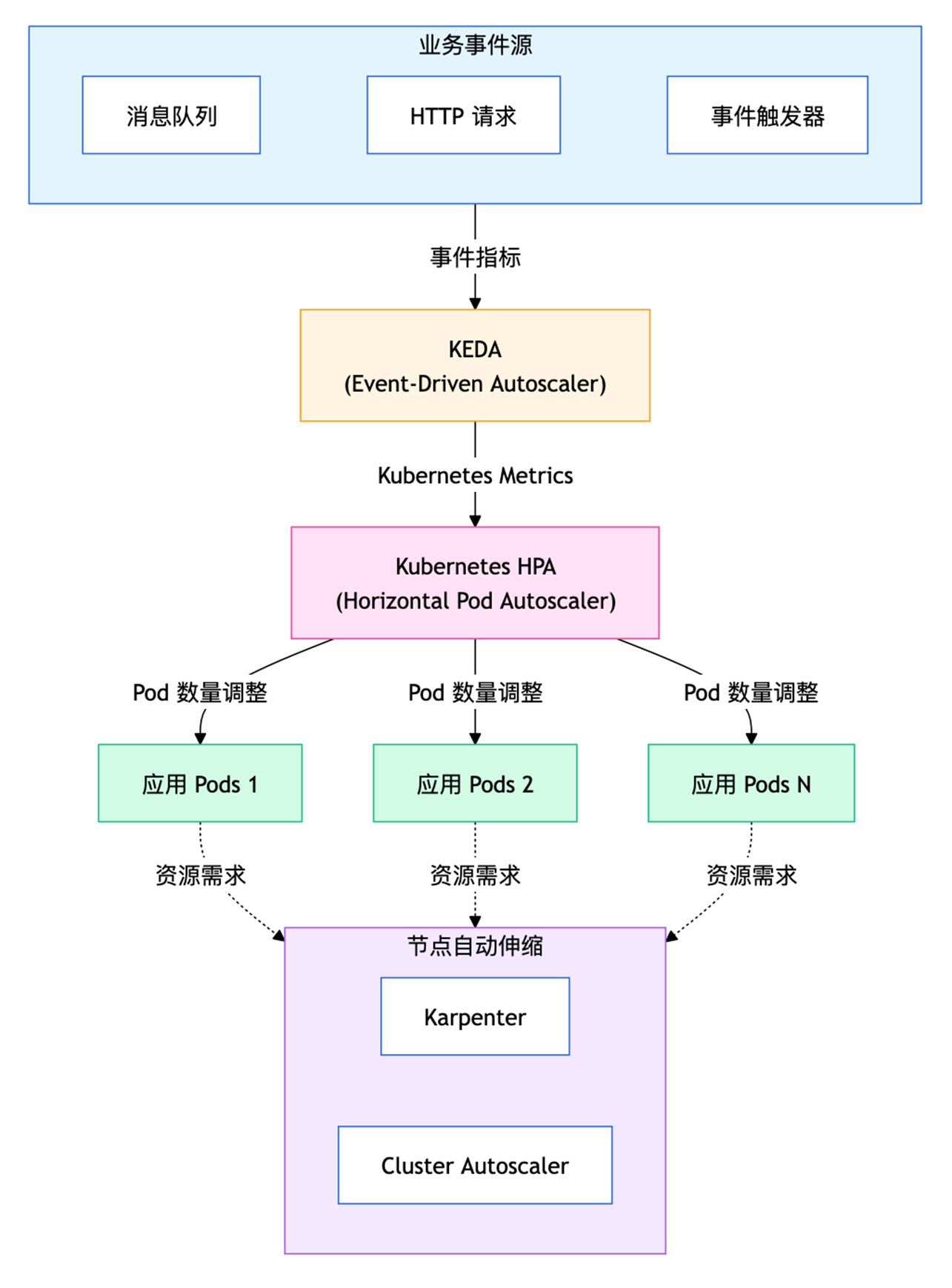 |
运行流程:
- 业务事件产生(如消息入队、请求突增);
- KEDA 根据设定的 Trigger 监测当前负载;
- KEDA 将事件指标提供给 Kubernetes HPA;
- HPA 调整应用 Pod 副本数;
- (如必要)节点层自动伸缩组件触发节点扩容;
- 系统稳定后根据事件下降自动收缩。
实现步骤
- 安装 KEDA
在 Amazon EKS 中推荐使用 Helm 安装 KEDA:
以上命令将 KEDA 部署到 keda 命名空间中,并自动安装必要组件。
- 定义 ScaledObject
ScaledObject 是 KEDA 的核心扩缩容配置,用于定义扩缩容目标及触发条件。例如,下面是一个基于 AWS SQS 队列长度的扩缩容示例(用户也可以根据实际业务情况自定义指标服务,实现精细化伸缩):
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: sqs-scaledobject
spec:
scaleTargetRef:
name: worker-deployment
minReplicaCount: 0
maxReplicaCount: 10
triggers:
- type: aws-sqs-queue
metadata:
queueURL: https://sqs.ap-southeast-1.amazonaws.com/123456789012/my-queue
queueLength: "5"
awsRegion: ap-southeast-1
解释:
- scaleTargetRef 指定应用对应的 Deployment
- minReplicaCount 和 maxReplicaCount 控制扩缩容范围
- queueLength 定义当队列长度达到 5 条及以上 时触发扩容
这样的策略允许系统根据实际业务负载自动扩缩,支持 Scale to Zero,实现资源按需调度。
最佳实践
- 在同一个 ScaledObject 中可以组合多个触发器
- KEDA 支持在同一个 ScaledObject 或 ScaledJob 中配置多个触发器。
- 这种做法可以让系统基于多个业务指标同时驱动伸缩行为,例如队列等待时间、任务数等不同维度的业务指标。当任一触发器达到阈值时,伸缩机制会被激活,从而让扩缩容响应更全面、更贴合业务需求。
- 避免 ScaledObject 与传统 HPA 直接竞争
- 同一工作负载同时使用传统 Kubernetes HPA 和 KEDA ScaledObject 进行伸缩配置,因为这会导致两个控制器互相竞争伸缩决策,可能出现不一致行为。
- 如果希望兼顾资源指标(如 CPU/Memory)和事件指标伸缩,可以考虑优先使用 KEDA 内置的相关触发器,而不是将 HPA 单独配置为另一套伸缩逻辑。
总结
本文介绍了加勒比熊猫通过在 Amazon EKS 上引入 KEDA 并与 Kubernetes HPA 协同使用,可以实现事件驱动的弹性扩缩容策略,在负载突发或空闲期间实现更高的资源利用效率。这种方式特别适合消息驱动、异步任务处理等场景,既保持 Kubernetes 原生机制的可观测和可控性,又显著提升业务响应能力。
参考链接
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
