亚马逊AWS官方博客
使用 AWS Lake Formation 构建、保护和管理数据湖
Original URL: https://aws.amazon.com/cn/blogs/big-data/building-securing-and-managing-data-lakes-with-aws-lake-formation/
数据湖集中存储了任意量级的多种类数据,并允许数据分析人员和数据科学家等角色运用多种技术分析手段对这些数据进行处理。许多组织正在将其数据转移到数据湖中。在本文中,我们将探索如何使用 AWS Lake Formation 来构建、保护和管理数据湖。
相比之下,基于云的数据湖可让我们对结构化和非结构化数据进行更灵活的分析。IT 人员可以预先聚合、组织、准备和保护任何量级的数据。然后,分析师和数据科学家可以使用他们自己选择的分析工具,根据适当的使用策略来访问这些数据。
建立数据湖面临的挑战
不幸的是,构建、保护和开始管理数据湖的过程复杂且耗时,通常需要几个月的时间才能完成。 即便是在云中构建数据湖都需要完成许多手动且耗时的步骤:
- 设置存储。
- 移动、清理、准备和编目数据。
- 为每个服务配置和实施安全策略。
- 手动授予用户访问权限。
当前,IT 人员和架构师花费太多时间来创建数据湖、配置安全性以及响应数据请求。他们本可以将这些时间用来策划数据资源,或为分析师和数据科学家提供咨询。分析师和数据科学家必须等待整个建立过程完成才能访问所需数据。
下图显示了数据湖的建立过程:

设置存储
数据湖储存海量的数据。在执行其他任何操作之前,必须设置存储空间以保存所有数据。如果使用的是 AWS,可配置 Amazon S3 存储桶和分区。如果要在本地构建数据湖,则需要购买硬件,并设置大型磁盘阵列以存储所有数据。
移动数据
连接本地和云中的不同数据源,然后在 IoT 设备上收集数据。接下来,从那些来源收集并组织相关的数据集,并爬取数据的元数据信息,然后将元数据标签添加到目录中。您可以使用下列服务来传输数据并进行ETL操作:
- AWS Glue
- AWS Database Migration Service (AWS DMS)
- Amazon Kinesis
- Amazon Managed Streaming for Apache Kafka (Amazon MSK)(新)
- AWS Transfer for SFTP 服务(新)
- AWS Snowball
清理和准备数据
接下来,必须仔细对收集的数据进行分区、索引并转换为列格式,以优化性能和成本。您必须进行数据清理、删除重复项并匹配相关记录。
配置和实施策略
客户和监管机构要求组织保护敏感数据。合规涉及创建和应用数据访问、保护和合规性策略。例如,您在表或列级别限制对个人身份信息 (PII) 的访问,对所有数据进行加密,并保留有关谁在访问数据的审计日志。
现在,您可以使用 S3 存储桶上的访问控制列表或第三方加密和访问控制软件来保护数据。您为需要访问数据的每个分析服务创建并维护数据访问、保护和合规策略。例如,如果您正在使用 Amazon Redshift 和 Amazon Athena 对数据湖运行分析,则必须为每个服务设置访问控制规则。
许多客户使用 AWS Glue 数据目录资源策略来配置和控制对其数据的元数据访问。有人则选择使用 Apache Ranger。但是这些方法可能很麻烦并且具有局限性。S3 策略最多能够提供表层级的访问控制。而且,您必须分别维护数据和元数据策略。使用 Apache Ranger,您一次只能配置对一个集群的元数据访问。而且,随着组织内访问数据湖的用户和团队数量的增长,策略可能变得繁多。
轻松查找数据
不同的用户(如分析师和数据科学家)有不同的需求,并且用户可能很难在数据湖中找到并信任相关数据集。为了使用户能够轻松找到相关和受信任的数据,必须在数据湖目录中清楚地标记数据。还需要让用户可以在不需要请求 IT 部门帮助的情况下即可访问和分析这些数据。
如今,所有这些步骤都涉及大量的人工作业。客户需要完成的工作包括:构建数据访问和转换工作流、映射安全性和策略设置,以及配置用于数据移动、存储、编目、安全性、分析和 ML 的工具和服务。要完成所有这些步骤,一个能够充分发挥作用的数据湖可能要花费数月才能部署完成。
客户在 AWS 上使用所有这些服务构建数据湖已经有好几年了。AWS 在 S3 之上运行 10,000 多个数据湖,其中许多将 AWS Glue 用于共享的 AWS Glue 数据目录,并使用 Apache Spark 进行数据处理。
AWS 从数千名在 AWS 上运行分析的客户那里了解到,大多数想要进行分析的客户也希望建立数据湖。只不过许多人都希望这个过程可以更轻松、更快。
AWS Lake Formation(现已正式推出)
在 AWS re:Invent 2018 大会上,AWS 推出了 Lake Formation。这是一项新的托管服务,可帮助您在几天内完成安全的数据湖的构建。如果您未参加,可观看 Andy Jassy 的主题演讲。Lake Formation 具有以下几个优势:
- 识别、提取、清理和转换数据:借助 Lake Formation,您可以更快地移动、存储、编目和清理数据。
- 在多种服务之间实施安全策略:在设置数据源之后,您可以在一处定义安全性、治理和审计策略,并为所有用户和所有应用程序实施这些策略。
- 获得并管理新的见解:借助 Lake Formation,您可以建立数据目录,该目录描述可用的数据集及其相应业务用途。该目录通过帮助用户找到合适的数据集进行分析,从而使他们的工作效率更高。
以下屏幕截图说明了 Lake Formation 及其功能。
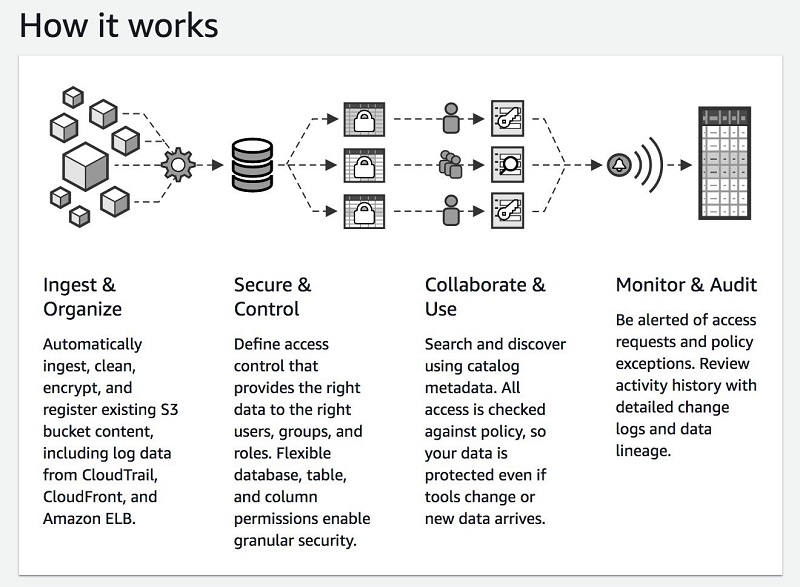
如何创建数据湖
Lake Formation 还优化了 S3 中的数据分区,以提高性能并降低成本。您加载的原始数据可能驻留在太小(需要额外读取)或太大(读取的数据超出需要)的分区中。Lake Formation 根据大小、时间或相关键来组织您的数据,以允许最常用的查询进行快速扫描和分布式并行读取。
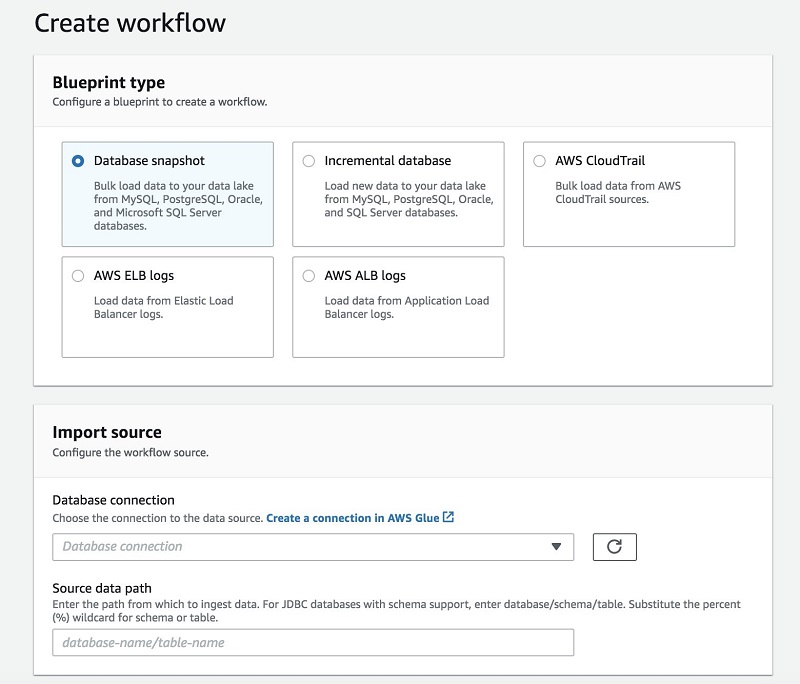
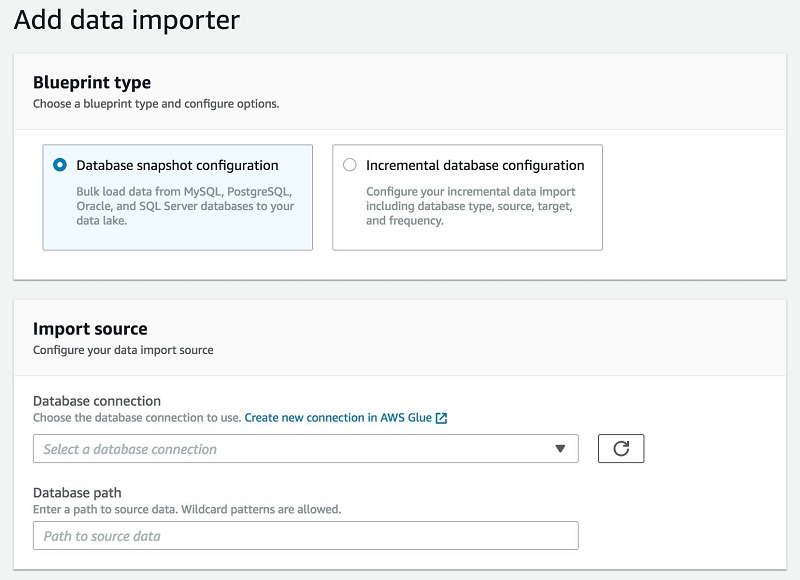
如何加载数据和编目元数据
Lake Formation 在加载和编目数据时使用蓝图这一概念。您可以一次运行蓝图以进行初始加载,也可以将它们设置为增量加载,添加新数据并使其可用。
将 Lake Formation 指向数据源,确定将其加载到数据湖中的位置,并指定加载频率。蓝图能够发现源表架构,自动将数据转换为目标数据格式,根据分区架构对数据进行分区,以及跟踪已处理的数据。所有这些动作都可以自定义。
下图显示了“蓝图工作流程”和“导入”截图:
如何转换和准备数据以进行分析
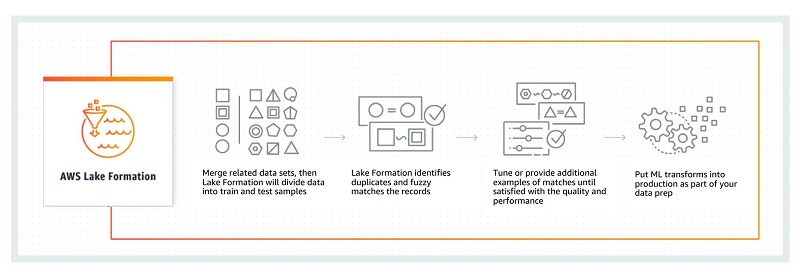
除了支持与 AWS Glue 相同的所有 ETL 功能外,Lake Formation 还引入了新的 Amazon ML Transforms。此功能包含模糊逻辑块算法,该算法可在不到 2.5 小时内对 4 亿多条记录进行重复项删除,这比以前的方法要高效得多。
要使用 Amazon ML Transforms 匹配和删除重复数据,首先要合并相关的数据集。Amazon ML Transforms 将这些集合分为训练和测试样本,然后扫描精确匹配和模糊匹配。您可以提供更多数据和样本以提高准确性,将它们投入生产,以在新数据到达您的数据湖时对其进行处理。分区算法几乎不需要调整。置信水平反映了分组的质量,比以前更为即兴的算法有所改进。下图显示了此匹配和重复数据删除的工作流程。
Amazon.com 目前正在内部针对零售工作负载大规模使用和检验 Amazon ML Transforms。现在,Lake Formation 将这些算法提供给客户,因此您不再需要创建复杂但脆弱的 SQL 语句来处理记录匹配和重复数据删除。Amazon ML Transforms 有助于在分析之前提高数据质量。有关更多信息,请参阅使用 AWS Lake Formation 的 Amazon ML Transforms 对数据进行模糊匹配和重复数据删除。
如何设置访问控制权限
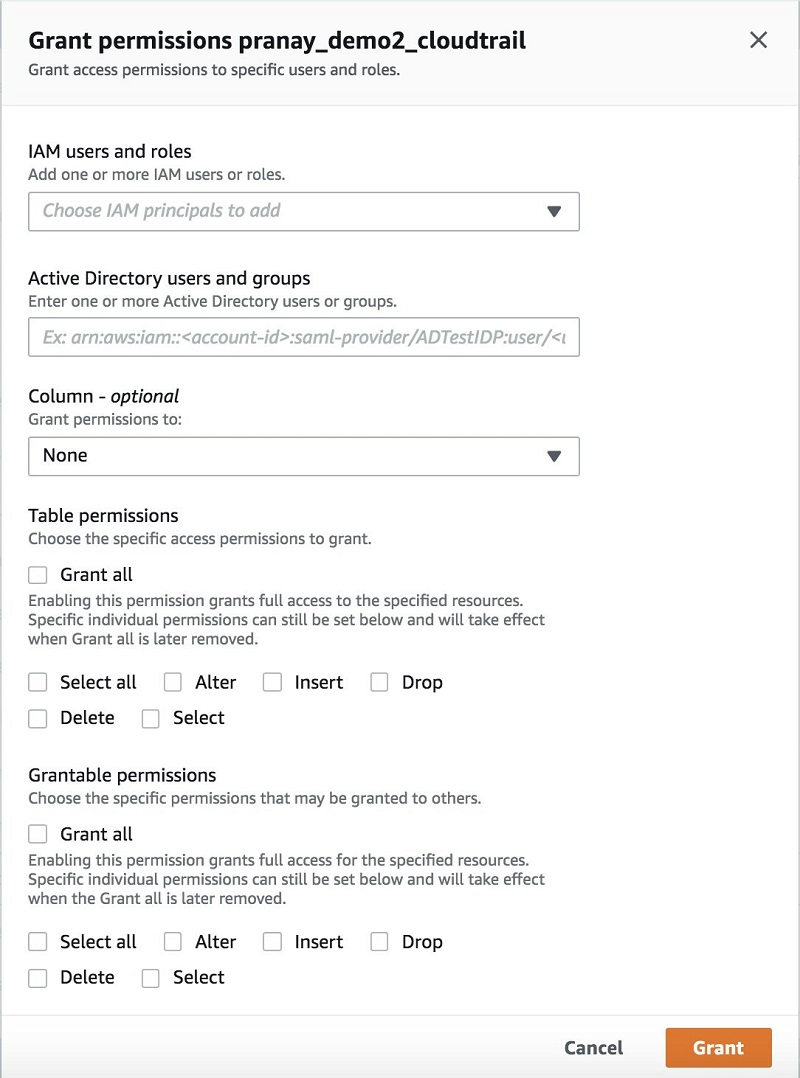
Lake Formation 让您可以在细化的级别,通过简单的“授予和撤消对数据的权限”集,来定义策略并控制数据访问。 您可以使用联合身份验证将权限分配给 IAM 用户、角色、组和 Active Directory 用户。您可以指定目录对象(如表和列)的权限,而不是存储桶和对象的权限。
您可以在一个地方轻松查看和审计授予用户的所有数据策略。通过控制面板搜索和查看授予用户、角色或组的权限;验证授予的权限;并在必要时轻松撤消用户的策略。以下屏幕截图显示了“授予”权限控制台:

如何使数据可用于分析
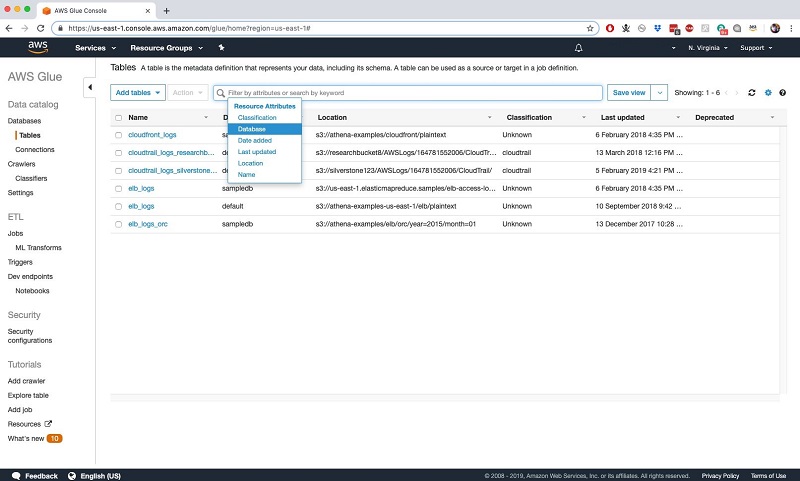
Lake Formation 提供了跨所有元数据的统一、基于文本的搜索,使用户可以自助访问可用于分析的数据集目录。该目录包含发现的元数据(如前所述),并让您可以添加属性(如数据拥有者、管理者和其他特定于业务的属性)作为表属性。
在更细化的级别上,您还可以将数据敏感度级别、列定义和其他属性添加为列属性。您可以通过任何这些属性浏览数据。但是访问受用户权限限制。请参阅以下 AWS Glue 表格选项卡的屏幕截图:
如何监视活动
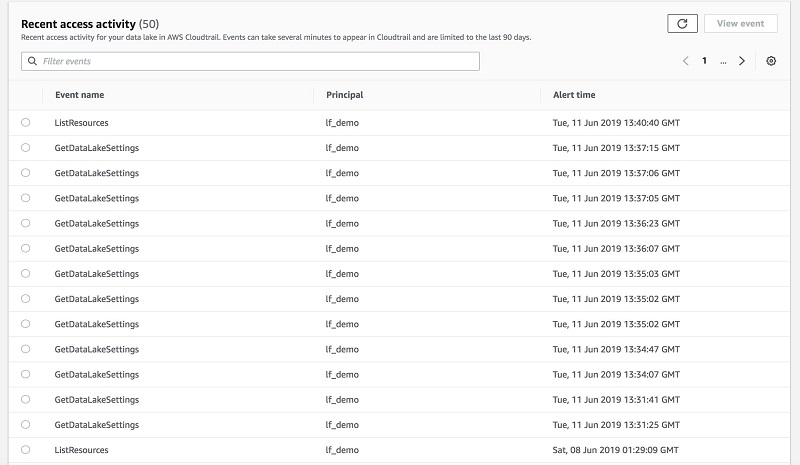
使用 Lake Formation,您还可以在控制面板中查看详细的警报,然后下载审计日志以进行进一步的分析。
Amazon CloudWatch 发布所有数据提取事件和目录通知。这样,您就可以识别可疑行为,证明运营合规。
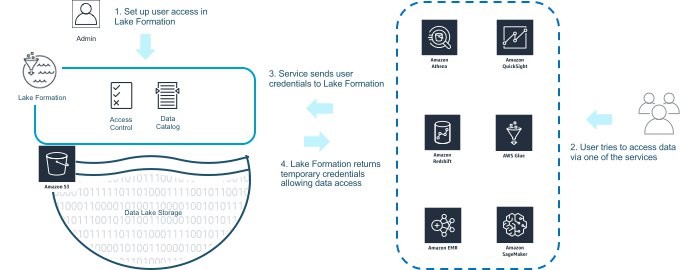
要使用 Lake Formation 监视和控制访问权限,首先如前文所述定义访问策略。想要进行分析的用户可以直接通过 AWS 分析服务(例如,用于适用于 Spark 的 Amazon EMR、Amazon Redshift 或 Athena)访问数据。或者,他们可以使用 Amazon QuickSight 或 Amazon SageMaker 间接访问数据。
以下屏幕截图和图表显示了如何使用 Lake Formation 监视和控制访问。
小结
仅需几步,您就可以在 S3 上设置数据湖并开始提取易于查询的数据。首先,进入 Lake Formation 控制台并添加数据源。Lake Formation 会爬取这些源并将数据移动到新的 S3 数据湖中。
从单个控制面板,您就可以为数据湖设置所有权限。这些权限针对访问数据的每个服务实施,包括分析和 ML 服务(Amazon Redshift、Athena 和适用于 Apache Spark 的 Amazon EMR 工作负载)。Lake Formation 让您免去在多个服务中重新定义策略的麻烦,并且可以始终如一地执行和遵守这些策略。
关于作者
 Nikki Rouda 是 AWS 数据湖和大数据的首席产品营销经理。20 多年来,Nikki 一直帮助 40 多个国家或地区的企业开发和实施解决方案,来应对分析和 IT 基础架构挑战。Nikki 拥有剑桥大学的 MBA 学位和布朗大学的地球物理和数学学士学位。
Nikki Rouda 是 AWS 数据湖和大数据的首席产品营销经理。20 多年来,Nikki 一直帮助 40 多个国家或地区的企业开发和实施解决方案,来应对分析和 IT 基础架构挑战。Nikki 拥有剑桥大学的 MBA 学位和布朗大学的地球物理和数学学士学位。
 Prajakta Damle 是 Amazon Web Services 的首席产品经理。
Prajakta Damle 是 Amazon Web Services 的首席产品经理。