亚马逊AWS官方博客
新一代国产 NewSQL 昆仑数据库的云上探索和压测表现
对于大多数开发者或者IT界从业者来说,对传统的关系型数据库管理系统(RDBMS)都不会太陌生,我们所熟知的开源界的 MySQL,PostgreSQL,商用版的 Oracle,DB2 等都属于这个范畴,再比如公有云上的比如亚马逊云科技自研的 Aurora,也属于这个范畴。RDBMS 的架构发展已经有几十年的历史了,而随着现代化应用的发展,数据库除了要满足 ACID(原子性、一致性、隔离性和持久性)之外,还要有 TPS 高,QPS 高,扩展性好,甚至既要支持 OLTP,还想要支持 OLAP 的需求。真的是既要,又要,还要!传统的 RDBMS 显然不能直接满足这些需求,因此我们又发展出了非常多的数据库中间件和分库分表的方法来解决业务数据量不断变大,同时性能要求又越来越高的问题。这个时候 NewSQL 横空出世,似乎带来了一些曙光。
NewSQL 可以简单归纳为是一种新型的 DBMS,同时具有 NoSQL 的扩展性和性能,也具有 SQL 数据库的 ACID 能力,能支持事务数据。NewSQL 一般会将数据以分片或者分区的方式切割成若干的小块,在查询和处理的适合会针对多个分区进行操作,然后汇总成一个统一的结果。通过一定的同步机制来保证数据的持久性和整个集群的高可用性。可以通过灵活地添加计算节点和存储节点来扩展,同时容错性也比较高,如果个别节点出现故障,一般不影响整个数据库的使用。
作为 NewSQL 的一个代表,昆仑分布式数据库(KunlunBase)是一款国产的关系型数据库,可处理 TB 和 PB 级别海量数据, 并且具有高性能,高可扩展性,高可用性和具有完备容灾能力。
本文会分为两个部分:
- 第一部分会阐述昆仑数据库在云上的编译、测试和自动化流程。通过这一部分的内容,我们可以了解到泽拓科技如何灵活利用云端资源来做测试、开发的。这种模式也可以轻易复制到其他开源软件公司,比如做 HTAP 的,做 API 网关的,做 DB 的等等。
- 第二部分会针对昆仑数据库本身,在 OLTP 和 OLAP 场景下分析一些压测数据。这部分比较适合对数据库和数据分析比较感兴趣的工程师和架构师们。
昆仑数据库整体架构图
从如下的架构图可以看出来,昆仑 DB 整个系统主要由3个组件组成,分别是计算节点、存储节点和元数据集群。
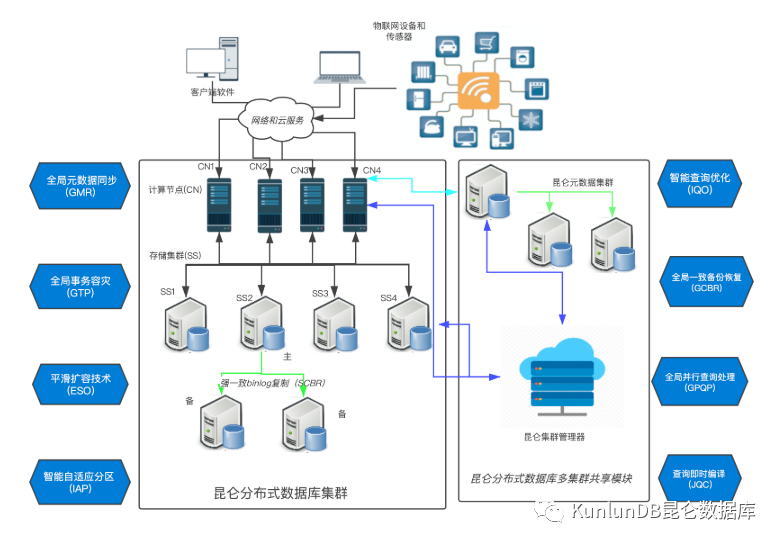
计算节点(KunlunServer)
计算节点由 PostgreSQL 11.5 开发,可以实现自动的 DDL 同步和复制以及分布式事务、分布式查询的功能。我们可以根据工作负载来增减计算节点,每一个计算节点都相对独立,可以单独处理用户连接和读写请求。在执行一个 SQL 的时候,计算节点首先会解析这个 SQL 语句,然后通过与后端存储 shard 做交互来进行分布式查询,最后合并所有后端返回的结果,形成最终的查询结果来返回给客户端。
存储节点(KunlunStorage)
每一个存储 shard 存储着一部分用户表或者表分区,彼此之间的数据没有交集。每一个存储 shard 又是一个 MySQL binlog 的复制集群,通过标准的 MySQL MGR single master 模式或者传统的 row based binlog 复制的抢同步机制来实现高可用性。一个 shard 的主节点接受来自计算节点的读写请求,执行请求并返回结果给计算节点。昆仑数据库还有一个备机读功能,这个类似于我们常见的只读副本,可以用来接受和处理来自计算节点的只读请求。和计算节点一样,用户可以根据需要随时增加和减少存储 shard,
元数据集群(Meta Cluster)
元数据集群是一个 MySQL binlog 复制集群,存储着整个昆仑数据库集群的愿数据。
运维监控平台(Xpanel)
KunlunBase 的运维管理模块,可以对整个集群环境进行管理和监控。Xpanel 可以监控集群各个节点的操作系统及各关键组件的重要信息,包括操作系统资源,操作系统错误日志,计算&存储引擎的关键日志错误信息等。

(Part I)昆仑数据库开源产品云上测试
和多数初创公司一样,在成立之初到融资之前,泽拓科技也面临资金不足,场地狭小等因素,无法建立公司自己的数据中心,没有稳定的硬件和存储资源来对开发中的产品进行完整的测试和验证。
受到其他创业公司的启发,此时,泽拓科技将目光放到亚马逊云科技的公有云上。通过亚马逊云,泽拓不需要购买机器,网络布线,安装机器,安装系统等复杂的人工操作,就能快速按需式获得满足规格要求的资源,而后完成产品的测试验证,并在验证完毕后,及时释放资源。 亚马逊云提供的这种按需式资源购买和释放,和按使用量付费的方式,使得泽拓不需要很大的人力和资金成本就能快速测试产品,修复产品问题,完善产品功能,大大加快了产品初期的迭代速度。
随着各大公有云平台逐渐成熟,企业将业务部署到成熟的公有云平台已经成为潮流,这就要求企业的数据核心-数据库系统也能够在各大公有云平台上高效稳定可靠运行。昆仑数据库开发之初就将云优先作为产品战略之一。 除了一开始在公有云上以按需式方式购买硬件来进行产品测试验证外,在融资构建了自己的数据中心后,我们仍然将云上测试验证放在优先的位置。比如,优先考虑公有云上的部署方式, 优先考虑使用公有云的相关服务而不是自我搭建,优先修复公有云上测试发现的问题等。 鉴于公有云平台的服务具有极大相似性,以及亚马逊云科技是全球最为成熟可靠的公有云平台,我们目前的在公有云平台上的工作,都是在亚马逊云上展开的。
在测试整个云上的数据库集群的时候,我们三个元数据节点使用 m5.xlarge, 计算节点使用的是三台 c5.4xlarge, 而存储节点使用的是 i3.4xlarge。其中 i3.4xlarge 底层的 NVMe SSD 能够提供最高825,000的随机读取 IOPS 和360,000写入 IOPS,非常适合对 TPS/QPS 要求很高的事务场景,内网带宽最高也去到了 10Gbps 的水平,某些实例类型还能达到100Gbps。
昆仑数据库在亚马逊云上主要包含以下日常活动:
- 开源版在 EC2 上的编译及测试
- 企业版在 EC2 上的测试
- 企业版在 EKS 上的测试
与普通物理机器不同的是, 亚马逊云科技对运行于其上的服务提供了极其灵活的控制方式。无论是对计算,存储,网络还是其他服务,泽拓科技就是这种灵活控制方式的受益者。借助于这种灵活的控制方式,我们能够按需的自动申请资源,自动进行资源配置,完成相关测试,而后释放资源,最大程度的节约成本。
除了使用各种语言 API 调用外,亚马逊云科技还提供了一套命令行工具包,来允许客户对自己名下的各种资源进行各种操作, 我们当前就是使用这一套工具包来操作云上资源,以达到按需使用的目的。
开源代码在 EC2 上编译测试
在 EC2 上编译的主要目的是为了确保我们发布的开源代码能够在亚马逊云科技上的主流 Linux 平台上正常工作,这是我们最早在云上进行的活动。 当时亚马逊云科技上的主流 Linux 平台主要有:
- Amazon Linux 2
- Red Hat Enterprise Linux 8.3
- SUSE Linux Enterprise Server 15 SP2
- Ubuntu Server 20.04 LTS
我们使用亚马逊云科技提供的 EC2 控制台,使用这几种 Linux 的官方 AMI,迅速创建了四台安装有这四种系统的 EC2 机器。 借助于云上提供的密钥对,安全组等服务,这四台机器一创建好,其中的安全访问就自动设置好了。 这比自己购买机器,安装系统,设置网络和访问方便多了。我们只需要安装昆仑数据库必须的依赖库就够了。
实际使用中,在每个平台上做编译时,自动化脚本都执行以下流程:
- 调用aws ec2 start-instances –instance-ids <ec2-id> 启动机器
- 在机器上执行编译,汇报结果
- 调用aws ec2 stop-instances –instance-ids <ec2-id> 关闭机器
在每个平台编译完成之后,自动化脚本还将启动这些机器,构建完整集群并完成一些基础测试后,关闭机器。正是亚马逊云科技提供的工具包,让我们能够根据需要启动和关闭机器,在节约费用的同时,持续保证了我们的产品能够支持这些主流的 Linux 平台。
企业版在 EC2 上的测试
除了开源版,我们还提供了企业版,为了不让客户受到 Linux 平台和版本的影响(比如需要用户选择需要下载的 Linux 发行版及具体版本), 我们的企业版目前统一在 Centos7 上进行编译。
与开源版不同的是,我们在亚马逊云科技上对企业版提供了更完整的验证。 开源版构建的集群始终使用四台配置好的机器, 所有节点都部署在这四台机器上。一台机器上,可能元数据节点,数据节点,和计算节点都部署于其上, 这并不符合产品化的部署方式。
在产品化的部署方式中, 为了保证系统的高可用性,元数据节点、计算节点和存储节点一般都是分开部署于不同的机器上。不同类型的节点负载不同, 所以这些机器也可以具有不同的配置。另外,用户实际需要部署集群时,尤其是集群规模比较大情况下,如果需要自己一台台创建机器,并且安装依赖库,这工作量就比较大,而且容易遗漏。 为了均衡利用计算节点,还需要自己安装负载均衡软件,设置该软件的对外访问方式,以及保证负载均衡软本身的高可用。
针对以上情况,亚马逊云科技提供了比较好的资源控制入口:
- 对于依赖库,亚马逊云科技提供了自定义镜像的功能,用户只需要安装好一台机器的依赖库,据此产生自己的镜像,而后使用该镜像创建好的 EC2 实例,依赖库都是安装好的。
- 亚马逊云科技工具集允许用户传递参数来设置新创建实例的镜像,磁盘空间,实例类型,安全组,密钥等。
- 亚马逊云科技工具集可以创建负载均衡服务(ELB),提供对所有计算节点的平衡访问。而AWS提供的ELB服务本身就是高可用的。
我们提供了一套基于亚马逊云科技的脚本,来辅助用户创建集群,用户只需要提供一个包含以下内容的 JSON 文件:
这里面包含了实例镜像 id、密钥 id、安全组 id、vpc-id(ELB 需要)、元数据节点的 EC2 实例类型、计算节点的 EC2 实例类型、计算节点数量、计算节点的用户名和密码、负载均衡服务(ELB)的监听端口、存储节点的 EC2 实例类型和存储分片数。
我们的工具将根据用户提供 JSON 文件, 按以下步骤创建出集群:
- 调用aws ec2 run-instances,按 JSON 文件中指定元数据 EC2 实例类型,以及镜像,密钥,安全组等创建出相应的 EC2 实例,而后在这些 EC2 实例上,安装元数据节点。
- 调用aws ec2 run-instances,按 JSON 文件中指定存储节点 EC2 实例类型,以及镜像,密钥,安全组等创建出相应的 EC2 实例,而后在这些 EC2 实例上,安装存储节点
- 调用aws ec2 run-instances,按 JSON 文件中指定计算节点 EC2 实例类型,以及镜像,密钥,安全组等创建出相应的 EC2 实例,而后在这些 EC2 实例上安装好计算节点
- 构建完整集群,完成集群的初始化配置
- 调用aws elbv2 create-load-balancer 根据配置文件中的 ELB 相关项,创建出一个 ELB 服务实例,用于接受客户端请求。
我们在亚马逊云科技上的企业版测试,将自动产生一个具有随机分片数(2-10之间)的 JSON 文件,而后调用上述工具,创建出一个完整集群,通过 ELB 入口运行我们的完整测试集,收集必要的结果信息,而后销毁这个集群, 相应的 EC2 实例,以及 ELB 服务实例。 正是借助于 AWS 提供的这些资源访问入口,我们能够以最小的代价持续保证企业版在 AWS 上能够正常工作。
企业版在 EKS 上的测试
Kubernetes 已经成为容器编排领域事实上的标准,越来越多的应用以容器的方式,运行于Kubernetes 中。为了以更加统一的方式管理 IT 系统,作为数据核心的数据库系统也要求能够运行于 Kubernetes 中。
昆仑数据库也在 Kubernetes 部署方面作为了必要的尝试。我们构建了相关的 Docker 镜像,在自己的数据中心内部建立一个 Kubernetes 平台,而后在 Kubernetes 平台中部署了多套昆仑数据库集群,运行地很好。
之后,我们将 Kubernetes 部署向亚马逊云科技中推进。 当把 EC2 实例当成和我们机房内部的物理机器一样看待时, Kubernetes 集群搭建以及部署都很顺畅,和我们机房内部部署基本没有区别,但是没法使用亚马逊云上的相关服务,尤其是负载均衡器 ELB 和块存储 EBS。
由于 Kubernetes 主流代码和各云厂商 CloudPrivoider开 发不同步的原因,用户想要在 EC2 实例中自建的 Kubernetes 中访问其他云服务变得越来越困难。不仅配置项多(比如 EC2 标签,访问权限等),还容易出错,以及难以找到出错原因。在此情况下,越来越多的厂商开始使用云厂商提供的 Kubernetes 服务来运行应用, 因为云厂商提供的 Kubernetes 服务把这些复杂配置都处理好了。
昆仑数据库在 EC2 实例上自建的 Kubernetes 集群中访问 ELB/EBS 也遇到了难题。经过考虑,也决定转向亚马逊云科技提供的 Kubernetes 服务 – EKS(Elastic Kubernetes Service)。使用 EKS 主要有以下好处:
- 免去配置访问云服务的复杂性
- 可以使用定制的容器镜像而不必是公有镜像,提供更好的安全性
- 可以直接从 EBS 获取存储空间
昆仑数据库提供了一套脚本工具,方便客户(以及我们自己)在 EKS 上创建昆仑数据库集群,用户只需要提供一个具有以下内容的 JSON 配置文件:
其中包括了 ELB 端口号、存储镜像地址、计算镜像地址、集群管理镜像地址、存储节点分片数及每个分片的数据量上限、计算节点数量及用户名密码和元数据节点资源限制/存储节点资源限制/计算节点资源限制 (可选)。
我们提供的脚本工具,将根据该json配置文件, 产生并安装 Kubernetes 下的各种 yaml 文件:
- Namespace 的yaml
- PersistentVolume 和 PersistentVolumeClaim 的 yaml
- 存放昆仑数据库配置的 configmap 的 yaml
- 元数据节点和数据分片节点的 yaml
- 包含 ELB 配置的计算节点的 yaml
- 集群管理节点的 yaml
而后,脚本工具将初始化出集群。
我们在 EKS 上的测试,将使用上述的脚本工具和亚马逊云科技提供的 EKS 工具,整体过程为:
- 调用eksctl create nodegroup 创建能被 EKS 使用的 EC2 节点
- 调用脚本工具创建数据库集群,运行完整的测试用例
- 调用eksctl delete nodegroup 删除相应的 EC2 节点
通过该过程,我们既实现了在 EKS 的测试,又保证了资源仅在使用时才申请,从而保证了最小使用成本。
总之,亚马逊云科技对资源使用提供了细粒度的控制方式,我们基于这种控制方式,形成了一套工具脚本, 以便能够在AWS上快速构建出满足需要的昆仑数据库集群。我们日常的自动化测试同时使用了亚马逊云科技和我们自己提供的工具,来完成在公有云上的产品测试。 在持续验证产品功能,保证和亚马逊云科技服务能集成的同时,还保证了最小的使用成本。
除了以上描述的方法之外,作为类似的自动化脚本,亚马逊云科技还提供了基础架构即代码的工具 CloudFormation 和 CDK (Cloud Development Kit)来给客户将整个亚马逊云上的基础架构资源和配置整合成代码的形式,这样我们不管在创建资源、更改资源、销毁资源都更方便了,也更加可以做代码化的流程管理,版本控制等等。不管是做开源数据库、开源网关还是其他开源软件的客户,都可以通过这类方法在云上快速构建自己的测试或者生产环境,然后在不需要的时候快速销毁相应资源,减少相应的成本支出。
(Part II)昆仑数据库在 OLTP 和 OLAP 上的压测表现
相信大家对于数据库的压测效果还是非常感兴趣的,我们也不负大家所望,花了很多精力来给大家呈现昆仑数据库在不同场景和不同的并发情况下它的压测效果。
本次压力测试主要会做两个部分,一个是 OLTP 场景,一个是 OLAP 场景。在 OLTP 场景中我们会用sysbench 来执行4中操作:updatenonindex/update_index,在 OLAP 场景中我们会执行 point select/simple range select/sum range select/order by range select/distinct range select 操作。
为了节省大家时间,我们可以先看看每个场景的配置情况和压测结果,如果对测试细节感兴趣可以再往下继续阅读。
OLTP 基本配置情况
- 本测试使用 MGR 复制模式和 RBR 复制模式两种方法构建集群,其中昆仑数据库的 Fullsync 机制就是基于 RBR(Row Based Replication)binlog 复制模式,实现了主备复制的强同步的。更多细节内容在本篇文章中不展开讲解,如果有兴趣的话可以查阅这个链接。
- 测试客户端采用1台9xlarge 来运行 sysbench, 通过 AWS Network Load Balancer 做分流,将请求发向3个计算节点。
- 集群配置
- rbr/mgr: 元数据集群使用3台xlarge, 计算节点使用3台 c5.4xlarge, 存储节点使用3台 i3.4xlarge, 包含3个 shards, 每个 shard 都是三副本,每台i3上具有一个 shard 的 primary 和另外两个 shards 的 replicas.
- norep: 元数据集群使用1台xlarge, 计算节点使用3台 c5.4xlarge, 存储节点使用3台 i3.4xlarge, 包含3个 shards, 每个 shard 都是单副本,每台i3上具有一个 shard。
- 数据:总共为18个表,每个表1000万记录,总数据量为36G。数据在 shard 间均匀分布,每个 shard 含有6个表,12G
- 缓存命中率 :每个数据节点 innodbbufferpoolsize 为20G,meta node 的innodbbufferpoolsize 为1G,缓存命中100%
- 测试情况: 每台 sysbench 客户端测试线程为 150/300/600/900/1200/1500,每个线程下每个操作运行时间为10分钟
OLTP 测试结论
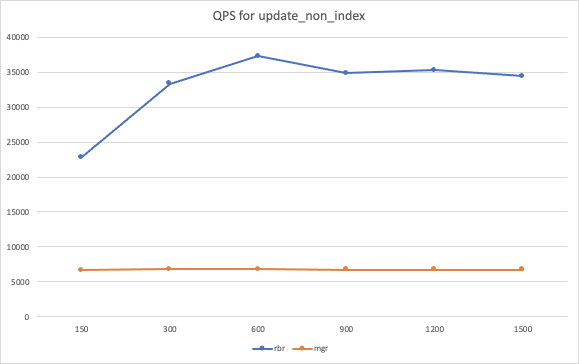
- rbr 模式对比 mgr 复制模式,从测试结果看性能提升显著。
- 对于 updatenonindex: rbr 性能约为 mgr 的5倍
- 对于 update_index: rbr 性能约为 mgr 的5倍
Sysbench 测试命令:
Sysbench 测试命令:

OLAP 基本配置情况
OLAP测试根据资源利用的情况,调整了机型的配置,以衡量不同配置下集群的整体表现, 这里主要使用2种配置。
- 配置1:计算节点使用3台4xlarge, 存储节点使用3台 c5d.9xlarge
- 配置2:计算节点使用3台9xlarge, 存储节点使用3台 c5d.9xlarge
OLAP 测试结论
- 通过使用 CloudWatch 分析 EC2 的资源利用情况,能够更好的发现性能瓶颈,以便调整配置获得更好的性能价格比。
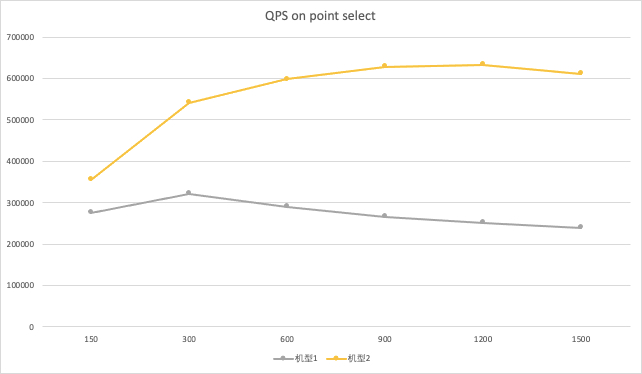
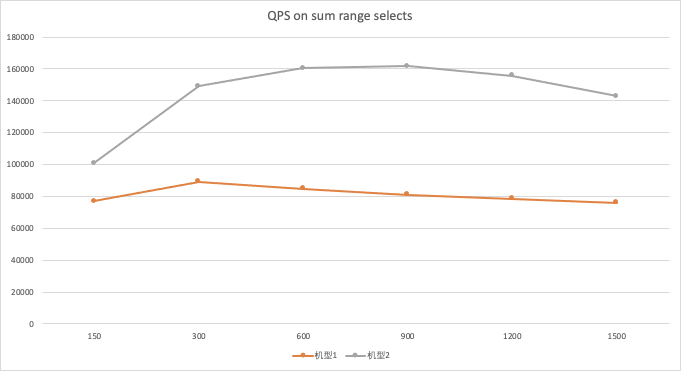
- 配置2能够更好发挥集群各部分的整体性能,也具有更高的性能价格比(qps/price)
- 在超高线程下,集群性能有下降,但比较稳定
- 由于存储节点基于 MySQL 开发, 具有完整的 SQL 解析执行功能, 存储节点比其他竞品的存储节点具有更强大的功能,但也要求更高的 CPU,在复杂查询下性能也更出色。
- 除 point select 外的其他聚集类查询对网络要求较高,在亚马逊云上更容易展现出高性能。
OLAP测试命令和结果
测试命令:
测试命令:

测试命令:

测试命令:

测试命令:
更多关于每个场景下的TPS和P95延迟测试报告,因为篇幅原因在这里就不一一给大家展示了,如果有兴趣的话可以查看昆仑数据库的相关测试链接。
总结
通过利用亚马逊云科技上丰富的 API 和自动化脚本,我们可以很灵活、快速地创建云上的开源软件集群,进行测试和模拟(不同的硬件架构和操作系统),然后在测试完毕之后迅速自动关闭整个集群和资源,帮初创企业节约云上的成本。亚马逊云科技也提供丰富的 EC2 的资源以及托管的 K8S 平台 EKS,帮助开源软件通过虚拟机和容器方式运行。在基础设施方面,内网带宽高达 100Gbps 和 IOPS 高达百万级别的存储可以支持大部分应用的场景,包括 API 网关,数据库,OLTP,OLAP 等。并且也提供丰富的 IaC 工具,比如 CloudFormation,Terraform 来对整个云上的资源做更多更定制化的编排,管理甚至是 CI/CD 的自动化流水线。
本文大家可以当做一个开胃菜,我们会在下一篇文章给大家介绍昆仑数据库和 MySQL 等开源关系型数据库在各方面的压测表现,以及昆仑数据库在基于ARM架构上的重新编译和性能情况。
参考文档
http://www.zettadb.com/KunlunDB-Instruction-manual
https://aws.amazon.com/cn/blogs/china/aurora-test/