亚马逊AWS官方博客
使用 Amazon SageMaker Ground Truth 与 Amazon Comprehend 开发 NER 模型
命名实体识别(NER)的核心,在于筛选文本数据以查找名词短语(即命名实体),并使用人、组织或品牌等标签对其进行分类。例如,在“我最近订阅了Amazon Prime”语句中,Amazon Prime就是一项命名实体,可以归类为品牌。但构建准确的内部自定义实体识别器往往非常复杂,需要准备大量手动注释的训练文档,同时选择正确的算法与参数以实现模型训练。
本文探讨了如何通过一条端到端管道,使用Amazon SageMaker Ground Truth 与 Amazon Comprehend构建起一套自定义NER模型。
Amazon SageMaker Ground Truth使您能够高效、准确地标记训练机器学习系统所必需的数据集。Ground Truth提供内置标记工作流,帮助人类标记员逐步完成数据注释任务。此外,Ground Truth还包含多种工具,能够高效准确构建带注释NER数据集以完成机器学习系统训练。
Amazon Comprehend是一项自然语言处理(NLP)服务,使用机器学习查找文本中的洞见与关系。Amazon Comprehend能够处理任何UTF-8格式的文本文件。通过识别文件中的实体、关键短语、语言、情感以及其他常见元素,Comprehend即可成功汇总出分析洞见。要使用这项自定义实体识别采取行动,大家需要准备一套用于模型训练的数据集,保证其中包含一组带有注释的文档或实体列表及其类型标签(例如PERSON,人),外加一组用于容纳各实体的文档。以此为基础,Comprehend即可自动测试算法与参数的最佳与最准确组合,进而完成模型训练。
下图所示,为这套解决方案的基本架构。
整个端到端流程如下所示:
- 将一组文本文件上传至 Amazon Simple Storage Service (Amazon S3)。
- 在Ground Truth中创建一个内部工作组与NER标记作业。
- 该内部工作组负责对所有文本文档进行标记。
- 完成之后,Ground Truth在Amazon S3中创建名为manifest的增强清单。
- 解析增强输出manifest文件,并以CSV格式创建注释与文档文件,而后将其交付至Amazon Comprehed以供处理。我们主要关注用于自动转换增强输出manifest文件的管道,此管道可通过AWS CloudFormation实现一键式部署。此外,我们还将展示如何使用Amazon Comprehend GitHub repo提供的onvertGroundtruthToComprehendERFormat.sh脚本解析该增强输出manifest文件,并以CSV格式创建注释与文档文件。虽然大家在实际使用中往往只需要一种转换方法,但我们强烈建议您尝试这两种方法。
- 在Amazon Comprehend控制台上,启动一项自定义NER训练作业,且使用由AWS Lambda生成的数据集。
为了尽可能缩短本文示例中用于手动注释方面的时间,我们建议您直接使用随附的小型语料库示例。虽然由此训练出的模型可能性能有限,但您可以借此快速体验整个端到端流程,积累到后续使用更大语料库的实践经验,甚至可以使用其他AWS服务替代Lambda函数。
设置流程
大家需要在计算机上安装AWS命令行界面(AWS CLI)。关于具体操作说明,请参阅安装AWS CLI。
接下来需要创建一个CloudFormationn栈,该栈负责创建S3存储桶与转换管道。虽然这条管道可以自动完成转换,但大家也可以直接使用转换脚本,具体操作说明我们将在后文中进行介绍。
设置转换管道
本文提供一套CloudFormation模板,可帮助大家执行多项初始设置工作:
- 创建一个新的S3存储桶。
- 使用Python 3.8运行时创建一项Lambda函数,以及用于实现其他依赖关系的Lambda层。
- 配置S3存储桶,根据接收到的
output.manifest文件自动触发该Lambda函数。
管道源代码托管在GitHub repo当中。要通过模板进行部署,大家需要在新的浏览器窗口或选项卡中登录至us-east-1区域中的AWS账户。
启动以下栈:
完成以下操作步骤:
- 在Amazon S3 URL部分,输入该模板的URL。
- 选择Next。

- 在Stack name部分,输入您的栈名称。
- 在S3 Bucket Name部分,为您的新存储桶输入名称。
- 其他参数直接使用默认值。
- 选择Next。

- 在Configure stack options页面中,选择Next。

- 审查您的栈细节信息。

- 勾选三个复选框,确认由AWS CloudFormation创建其他资源与功能。
- 选择Create stack。


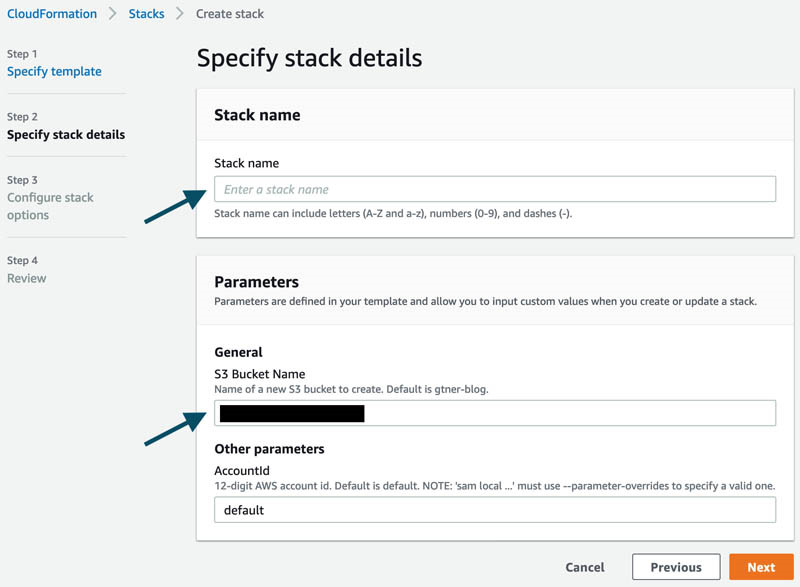

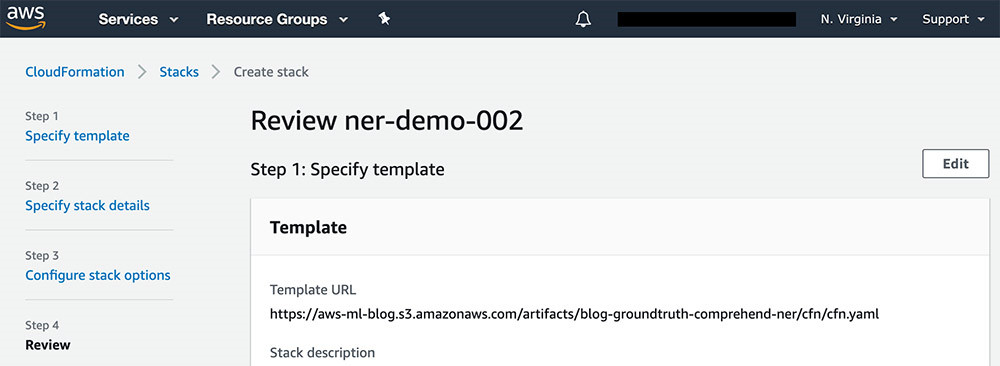

CloudFormation现在开始创建您的栈。在完成之后,大家应看到以下截屏内容。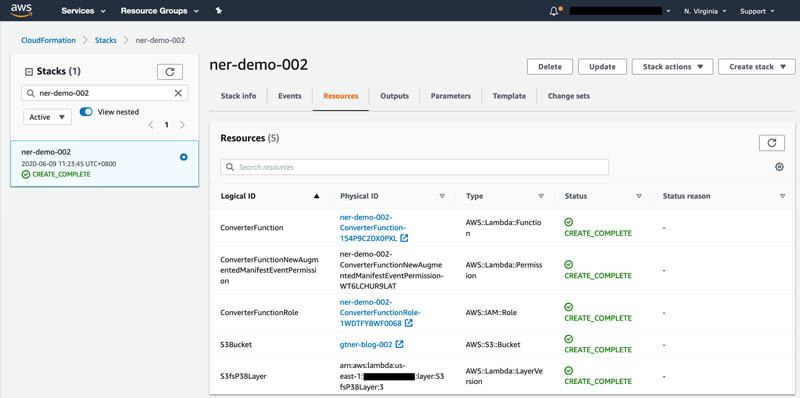
设置转换脚本
要在您的计算机上设置转换脚本,请完成以下操作步骤:
- 在计算机上下载并安装Git。
- 指定您在本地设备上保存该repo的具体位置。我们建议您创建一个专用文件夹,借此轻松使用命令提示符导航至该位置。
- 在浏览器中,导航至Amazon Comprehend GitHub repo。
- 在Contributors部分,选择Clone or download。
- 在Clone with HTTPS部分,选择剪贴板图标以复制repo URL。
要使用SSH密钥克隆该repo,包括由您组织内SSH证书颁发机构颁发的证书,请选择Use SHH并选择剪贴板图、将repo URL复制至剪贴板。
- 在终端内,导航至您之前保存克隆repo的位置。您可以直接输入
$ cd <directory>前往该位置。 - 输入以下代码:
在repo克隆操作完成之后,根据README文件中的步骤使用脚本将Ground Truth NER标记作业与Amazon Comprehend自定义实体识别集成起来。
将未标记样本上传至语料库
运行以下命令,将样本数据文件复制至您的S3存储桶:
这批样本数据可以缩短您的注释时间,由于不追求模型性能最大化,因此无需进行深度优化。
运行NER标记作业
此步骤涉及三项手动操作:
- 创建一个内部工作组。
- 创建一项标记作业。
- 进行数据注释。
您可以在不同作业中重复使用这个内部工作组。
在作业完成之后,它会将结果写出为一个output.manifest文件,并由Lambda函数自动进行内容提取。该函数会将此manifest文件转换为两个文件:.csv格式与.txt格式。假设输出manifest为s3://<your-bucket>/gt/<gt-jobname>/manifests/output/output.manifest,则这两个Amazon Comprehend文件将位于s3://<your-bucket>/gt/<gt-jobname>/manifests/output/comprehend/之下。
创建一个内部工作组
在本用例中,我们将创建一个内部工作组,并使用自己的电子邮件地址作为唯一工作人员。Ground Truth也允许您使用Amazon Mechanical Turk或其他供应商提供的注释人员。
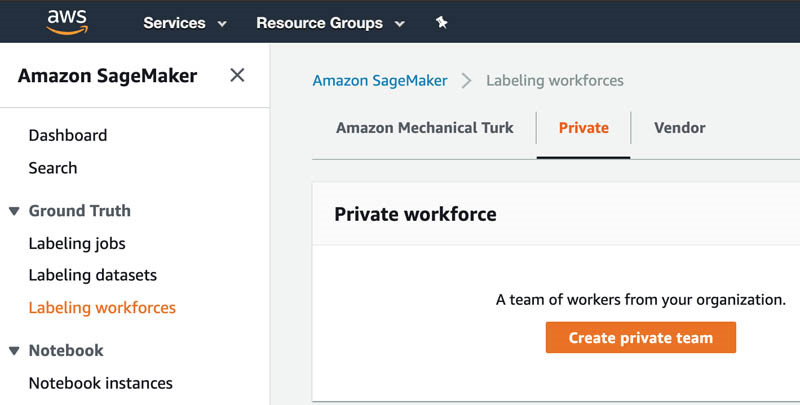
- 在 Amazon SageMaker 控制台的Ground Truth之下,选择Labeling workforces。
- 在Private 选项卡中,选择Create private team。

- 在Team name部分,输入您的工作组名称。

- 在Add workers部分,选择Invite new workers by email。
- 在Email addresses部分,输入您的电子邮件地址。
- 在Organization name部分,输入您的组织名称。
- 在Contact email部分,输入您的电子邮件。
- 选择Create private team。

- 前往新的内部工作组,找到标记门户的URL。
 如果这是您第一次被添加至工作组内,或者设置了Amazon Simple Notification Service (Amazon SNS)通知功能,您还将收到包含URL、用户名以及临时密码的注册电子邮件。
如果这是您第一次被添加至工作组内,或者设置了Amazon Simple Notification Service (Amazon SNS)通知功能,您还将收到包含URL、用户名以及临时密码的注册电子邮件。 - 登录至标记URL。

- 将临时密码更换为新密码。




创建一项标记作业
下一步就是创建NER标记作业。本文将重点介绍其中的各关键步骤。关于更多详细信息,请参阅使用Amazon SageMaker Ground Truth添加数据标记工作流以进行命名实体识别。
为了缩短注释时间,这里请直接使用复制至S3存储桶内的示例语料库作为Ground Truth作业的输入。
- 在Amazon SageMaker控制台的Ground Truth之下,选择Labeling jobs。
- 选择Create labeling job。

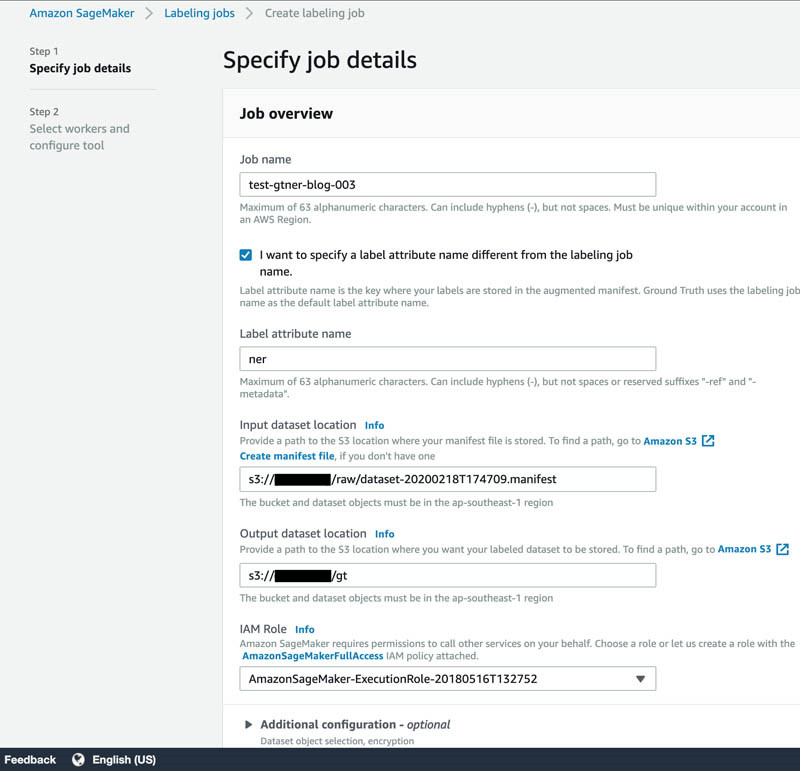
- 在Job name部分,输入一项作业名称。
- 选择 I want to specify a label attribute name different from the labeling job name。
- 在Label attribute name部分,输入ner。
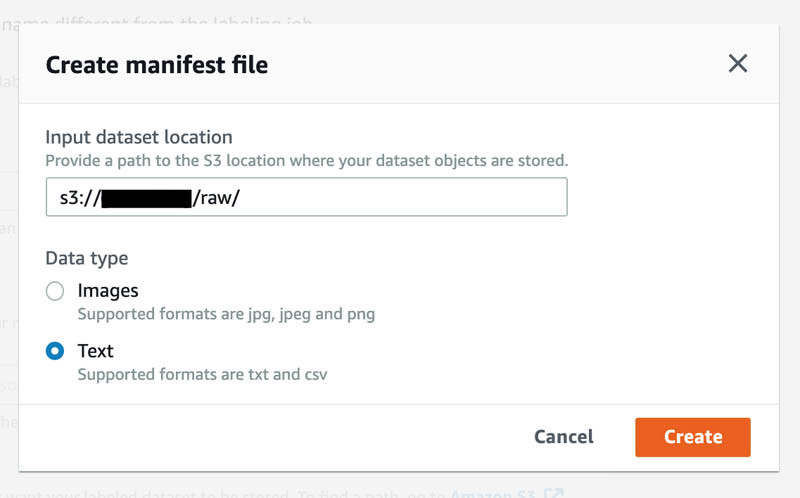
- 选择 Create manifest file。



通过这一步,Ground Truth将自动把您的文本语料库转换为manifest文件。
这时会显示一个弹窗。
- 在Input dataset location部分,输入您的Amazon S3位置。
- 在Data type部分,选择Text。
- 选择Create。

这时我们会看到提示信息,manifest文件已经创建完成。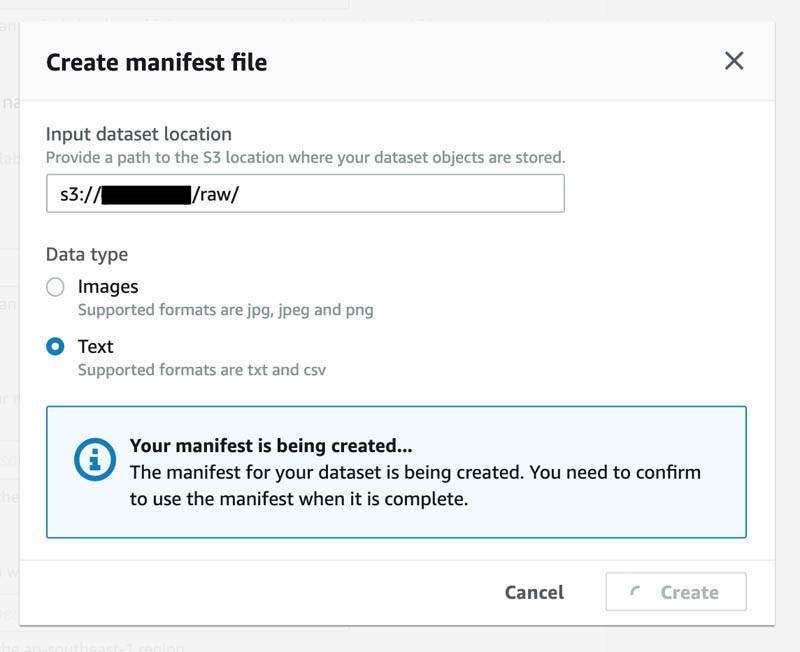
- 在manifest文件创建完成后,选择 Create。


大家也可以自己提供输入manifest。请注意,NER标记作业要求其输入manifest为 {"source": "embedded text"} 格式,而非引用样式中的{"source-ref": "s3://bucket/prefix/file-01.txt"}格式。另外,生成的输入manifest会自动检测到换行符\n,并在各个文档中的每一行生成一条JSON行;如果您自行生成此行,则可在各文档中只保留一个JSON行(但您可能仍需要保留\n换行符以供下游使用)。
- 在IAM role部分,选择CloudFormation模板此前创建的角色。

- 在Task selection部分,选择Named entity recognition。
- 选择Next。

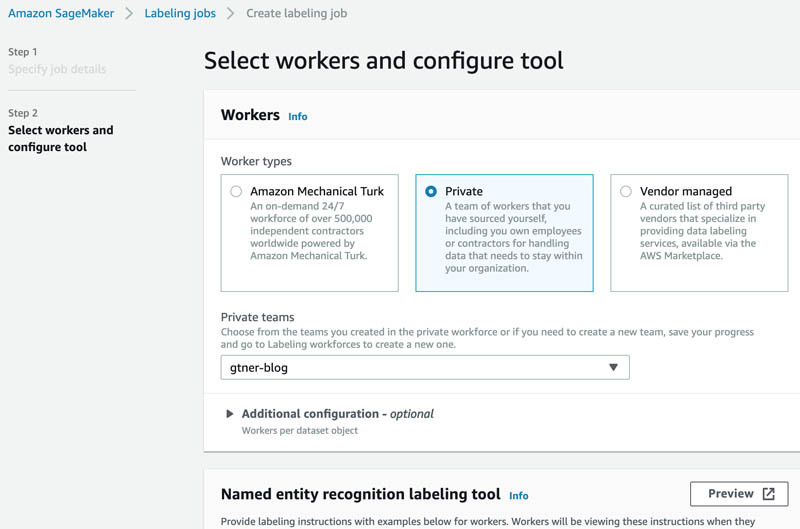
- 在Select workers and configure tool页面中的Worker types部分,选择Private。
- 在Private teams部分,选择您之前创建完成的内部工作组。

- 在Number of workers per dataset object部分,保证工作人员的数量(1)与内部工作组的实际规模相匹配。
- 在文本框中,输入标记操作方法。
- 在Labels下,添加您希望使用的标签。参考以下截屏中为推荐语料库提供的标签。
- 选择Create。



在作业创建完成后,现在我们可以在Labeling jobs页面上跟踪各项标记任务的具体状态。
以下截屏所示,为该作业的详细信息。
标记数据
使用本示例中的推荐语料库,标记流程将在数分钟内完成。
在作业创建完毕后,内部工作组将通过标记门户查看列出的任务,并根据具体分配的工作内容进行数据标记。
以下截屏所示,为工作人员UI。
在全部标记任务完成之后,标记作业状态将显示为Completed。
复核
CloudFormation模板将对示例中的S3存储桶进行配置,在包含manifests/output/output.manifest前缀的新对象传入特定S3存储桶时向Amazon S3提交一项指向Lambda函数put事件。最近,AWS还为标记作业添加了Amazon CloudWatch Events支持功能,您可以将其作为触发转换操作的另一种机制选项。关于更多详细信息,请参阅Amazon SageMaker Ground Truth现已支持多标签图像与文本分类、以及Amazon CloudWatch Events。
该Lambda函数会加载增强manifest文件,并将该文件转换为comprehend/output.csv 与 comprehend/output.txt,且二者皆具有与output.manifest相同的前缀。请参考以下示例中的s3://<your_bucket>/gt/<gt-jobname>/manifests/output/output.manifest 结果:
您可以通过检查Lambda函数添加至output.manifest的标签,在CloudWatch Logs中进一步跟踪Lambda的执行上下文。此项操作可在Amazon S3控制台或者AWS CLI当中实现。
要通过Amazon S3控制台进行跟踪,请完成以下操作步骤:
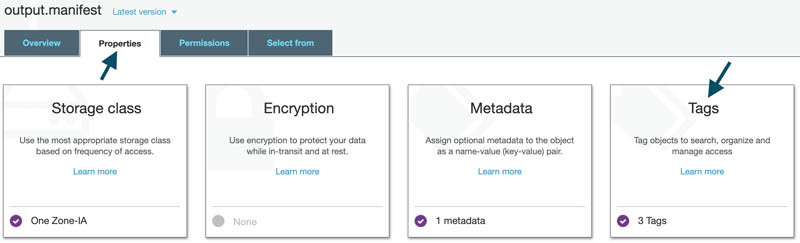
- 在Amazon S3控制台上,导航至该输出结果。
- 选择
output.manifest。
- 在Properties选项卡中,选择Tags。

- 查看由该Lambda函数添加的标签。



要使用AWS CLI,请输入以下代码(其中日志流标签__LATEST_xxx代表CloudWatch日志流[$LATEST]xxx。由于[$]不是Amazon S3标签中的有效字符,因此会被Lambda函数替换掉):
现在,我们可以前向CloudWatch控制台并跟踪实际日志分组、日志流与RequestId,详见以下截屏内容。
在Amazon Comprehend上训练一套自定义NER模型
Amazon Comprehend要求输入语料库遵循各实体的以下最低要求:
- 1000个样本
- 语料库大小为5120字节
- 包含200条注释
这里,我们在Ground Truth中使用的示例语料库无法满足上述最低要求。因此,我们为大家准备了其他预生成的Amazon Comprehend输入。此样本数据将帮助大家快速开始训练自定义模型,但并未针对模型性能做出充分优化。
在您的计算机上,输入以下代码将之前生成的数据上传至存储桶:
您的 s3://<your_bucket>/gt/<gt-jobname>/manifests/output/comprehend/documents/ 文件夹应以两个文件结尾: output.txt 与 output-x112.txt。
您的s3://<your_bucket>/gt/<gt-jobname>/manifests/output/comprehend/annotations/ 文件夹应该包含 output.csv 与 output-x112.csv。
现在,大家可以开始自定义NER模型的训练流程了。
- 在Amazon Comprehend控制台的Customization下,选择 Custom entity recognition。
- 选择Train recognizer。

- 在Recognizer name部分,输入一个名称。
- 在Custom entity type部分,输入您的标签。

请保证自定义实体类型与您在Ground Truth作业中使用的类型相匹配。
- 在Training type部分,选择Using annotations and training docs。
- 为您的注释与训练文档输入Amazon S3位置。

- 在IAM role部分,如果这是您第一次使用Amazon Comprehend,请选择 Create an IAM role。
- 在Permissions to access部分,请选择Input and output (if specified) S3 bucket。
- 在Name suffix部分,输入一个后缀。
- 选择Train。



现在,您可以查看列出的识别器了。

以下截屏所示,为训练完成后的视图,整个过程最多可能需要1个小时。
资源清理
在完成本轮演练之后,请通过以下步骤清理您的资源:
- 清空S3存储桶(或者直接删除该存储桶)。
- 终止CloudFormation栈。
结论
到这里,大家已经了解如何使用Ground Truth以构建NER训练数据集,以及如何将生成的增强manifest文件自动转换为Amazon Comprehend能够直接处理的格式。
与往常一样,AWS欢迎您的反馈意见。请在评论区中与我们交流。