1. 需求背景
公司业务在每个工作日早高峰会迎来客户端并发峰值,此时Lambda 并发扩容速率超出Lambda并发扩展限制 ,产生了Lambda Throttle限流,影响高峰期用户体验。 经与亚马逊云科技中国区域企业级支持团队技术专家深入交流后,获得以下两种解决思路:
优化Lambda执行时间Duration以及函数内访问的第三方接口时间
配置预置并发,优化Lambda冷启动Init阶段的时间
由于第一种解决思路需要对业务代码以及相关调用的服务接口中间件进行长期的优化,要在短期内解决业务高峰期Lambda执行时间长导致并发突增的痛点只能先采用第二种Lambda 预置并发的方案。但Lambda预置并发一旦配置之后将产生额外的成本 且除了高峰期时段外其他时间并不需要预置并发,所以考虑使用AWS提供云原生的应用程序集成工具EventBridge结合Lambda或者利用Application Auto Scaling服务来灵活使用Lambda函数预置并发功能从而降低使用成本。
2. 方案实现
2.1 前置步骤:Lambda 启用版本和别名
预置并发只能配置版本或者别名。我们选用别名,好处是代码调用别名和设置阈值的时候用别名可以不用变动,别名指向最新版本的函数。
目前设置以及别名切换最新版本的操作是在GitLab CI/CD 中执行。
每次发布上传代码,更新函数
创建最新的版本
修改别名的指向版本为最新的
删除超过4个的旧版本
实现代码如下(选取一段):
- |-
for i in ${FUNCTION_NAME};do
aws Lambda update-function-code --function-name $i --zip-file fileb://${UPDATE_ZIP_NAME} --output json | jq -r '.FunctionName'
echo "上传到Lambda: ${i} 成功"
aws Lambda wait function-updated --function-name $i
Lambda_VERSION=$(aws Lambda publish-version --function-name $i --query 'Version' --output text)
# 尝试更新别名,如果失败则创建别名并等待
if ! aws Lambda update-alias --function-name $i --name provisioned --function-version $Lambda_VERSION; then
aws Lambda create-alias --function-name $i --name provisioned --function-version $Lambda_VERSION
else
# 获取所有版本号并删除未被任何别名引用的旧版本
aws Lambda list-versions-by-function --function-name $i \
--query 'Versions[].Version' --output text | \
tr '\t' '\n' | grep -E '^[0-9]+$' | \
# 排除所有被别名引用的版本
grep -v -F -f <(aws Lambda list-aliases --function-name $i --query 'Aliases[].FunctionVersion' --output text | tr '\t' '\n') | \
sort -rn | tail -n +4 | \
xargs -r -I {} aws Lambda delete-function --function-name $i --qualifier {}
fi
done
2.2 配置预置并发的方式
配置预置并发的方式有以下几种:
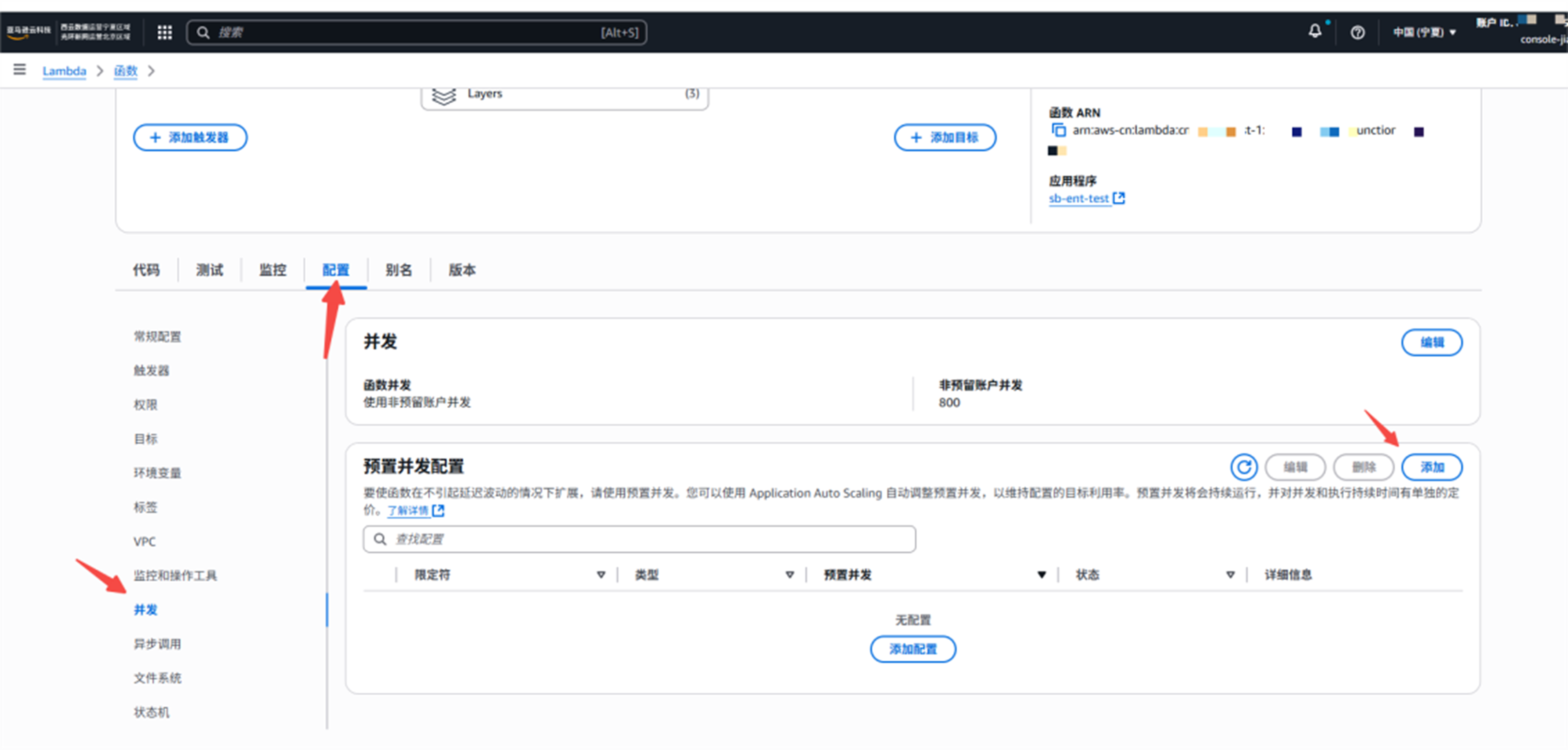
2.2.1 在控制台手动配置
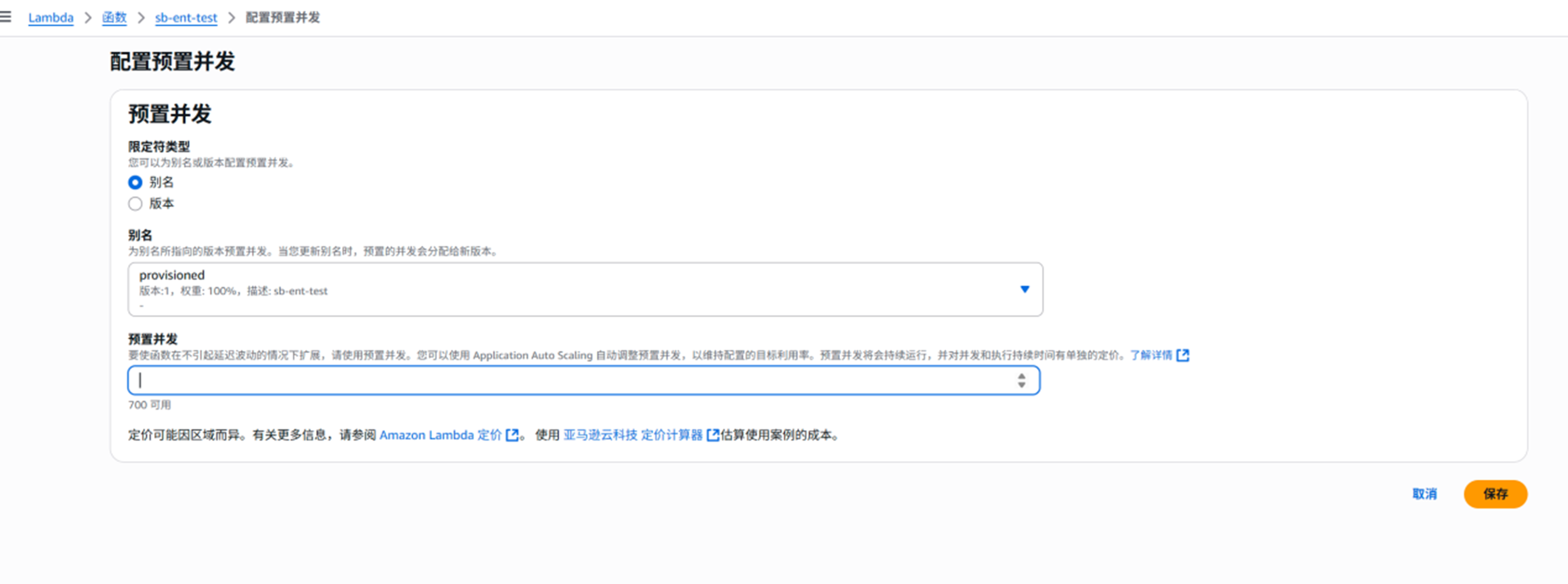
配置–>并发–> 预置并发配置–>添加
选择别名,填写数值,保存
2.2.2 使用 Application Auto Scaling
使用Application Auto Scaling 的方式只能通过 AWS CLI配置,命令如下
# 注册可扩展目标
aws application-autoscaling register-scalable-target \
--service-namespace Lambda \
--scalable-dimension Lambda:function:ProvisionedConcurrency \
--resource-id function:my-function:my-alias \
--min-capacity 10 \
--max-capacity 100
# 创建基于时间的扩展策略
aws application-autoscaling put-scheduled-action \
--service-namespace Lambda \
--scalable-dimension Lambda:function:ProvisionedConcurrency \
--resource-id function:my-function:my-alias \
--scheduled-action-name weekday-morning-scaling \
--schedule "cron(0 9 ? * MON-FRI *)" \
--scalable-target-action MinCapacity=50,MaxCapacity=200
2.2.3 使用 EventBridge + Lambda 自动化
使用 EventBridge的Scheduler(定时)功能触发Lambda ,Lambda通过boto3 API去配置生产环境Lambda函数的预置并发和取消预置并发。
2.2.4 使用AWS CLI编写写自动化脚本
# 为函数别名设置预置并发
aws Lambda put-provisioned-concurrency-config \
--function-name my-Lambda-function \
--qualifier PROD \
--provisioned-concurrent-executions 1000
# 删除预置并发配置(恢复为按需并发)
aws Lambda delete-provisioned-concurrency-config \
--function-name my-Lambda-function \
--qualifier PROD
这里推荐采用使用 EventBridge + Lambda的方式,好处是
Serverless不需要维护底层服务器资源,按需调用且天然实现高可用
EventBridge定时策略变更方便,策略策略灵活
除了Lambda预置并发配置外还可以在代码中接入飞书webhook通知提高可见性
2.3 使用 EventBridge + Lambda定时启动预置并发+飞书通知
2.3.1 创建Lamdba使用的IAM role
创建相应的IAM role 角色策略:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"Lambda:PutProvisionedConcurrencyConfig",
"Lambda:DeleteProvisionedConcurrencyConfig",
"Lambda:GetProvisionedConcurrencyConfig"
],
"Resource": [
"arn:aws-cn:Lambda:*:*:function:*:*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
信任关系:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "Lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
2.3.2 创建Lambda
Lambda 名称:op-test-Lambda-provisioned-pro
运行时: python 3.13
role: 上步创建
vpc:选择vpc,子网,安全组,安全组出栈开放443
ENVIRONMENT: 环境标识(test/pro)
FEISHU_WEBHOOK_URL: 飞书机器人Webhook URL
2.3.3 Lambda代码实现
import boto3
import os
import json
import urllib.request
from datetime import datetime
def send_feishu_message(webhook_url, message, at_all=False):
"""
发送飞书消息通知
Args:
webhook_url (str): 飞书机器人Webhook URL
message (str): 消息内容
at_all (bool): 是否@全体成员
Returns:
str: 消息发送结果
"""
try:
if at_all:
# @全体成员的卡片消息格式
payload = {
"msg_type": "interactive",
"card": {
"config": {
"wide_screen_mode": True
},
"elements": [
{
"tag": "div",
"text": {
"content": message,
"tag": "lark_md"
}
},
{
"tag": "div",
"text": {
"content": "**通知人员:** <at id=all></at>",
"tag": "lark_md"
}
}
]
}
}
else:
# 普通卡片消息格式
payload = {
"msg_type": "interactive",
"card": {
"config": {
"wide_screen_mode": True
},
"elements": [
{
"tag": "div",
"text": {
"content": message,
"tag": "lark_md"
}
}
]
}
}
data = json.dumps(payload).encode('utf-8')
req = urllib.request.Request(
webhook_url,
data=data,
headers={'Content-Type': 'application/json'}
)
response = urllib.request.urlopen(req)
result = response.read().decode('utf-8')
return result
except Exception as e:
print(f"发送飞书消息失败: {str(e)}")
return None
def lambda_handler(event, context):
"""
Lambda函数主入口
Args:
event (dict): 包含触发事件的数据
context (object): Lambda运行时上下文信息
Returns:
dict: 包含状态码和结果信息的响应字典
"""
client = boto3.client('lambda')
print(f"Lambda函数执行开始: {datetime.now()}")
# 获取当前执行时间用于日志记录
execution_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# 获取环境标识和操作类型(必须通过EventBridge触发时传递)
env = os.environ.get('ENVIRONMENT')
action = event.get('action') # 'set' 配置预置并发, 'remove' 取消预置并发
# 函数的别名
alias_name = 'provisioned'
# 从event中获取预置并发数量配置
provisioned_concurrency_config = event.get('provisioned_concurrency', {})
# 获取飞书Webhook URL
feishu_webhook_url = os.environ.get('FEISHU_WEBHOOK_URL')
# 验证是否提供了ENVIRONMENT环境变量
if not env:
error_msg = '未设置ENVIRONMENT环境变量。必须提供"test"、"sim"或"pro"。'
if feishu_webhook_url:
send_feishu_message(feishu_webhook_url, f"❌ **[预置并发错误]**\n**时间:** {execution_time}\n{error_msg}")
return {
'statusCode': 400,
'body': error_msg
}
# 验证ENVIRONMENT环境变量是否有效
valid_environments = ['test', 'sim', 'pro']
if env not in valid_environments:
error_msg = f'无效的ENVIRONMENT环境变量: {env}。必须是"test"、"sim"或"pro"之一。'
if feishu_webhook_url:
send_feishu_message(feishu_webhook_url, f"❌ **[预置并发错误]**\n**时间:** {execution_time}\n{error_msg}")
return {
'statusCode': 400,
'body': error_msg
}
# 验证是否提供了action参数
if action not in ['set', 'remove']:
error_msg = '无效的action参数。必须提供"set"或"remove"。'
if feishu_webhook_url:
send_feishu_message(feishu_webhook_url, f"❌ **[预置并发错误]**\n**时间:** {execution_time}\n{error_msg}")
return {
'statusCode': 400,
'body': error_msg
}
# 当action为set时,验证是否提供了provisioned_concurrency配置
if action == 'set':
if not provisioned_concurrency_config:
error_msg = '当action为"set"时,必须提供provisioned_concurrency配置。'
if feishu_webhook_url:
send_feishu_message(feishu_webhook_url, f"❌ **[预置并发错误]**\n**时间:** {execution_time}\n{error_msg}")
return {
'statusCode': 400,
'body': error_msg
}
# 验证provisioned_concurrency配置中的值是否为有效数字
for key, value in provisioned_concurrency_config.items():
try:
int(value)
except (ValueError, TypeError):
error_msg = f'provisioned_concurrency配置中的{key}值必须为有效数字。'
if feishu_webhook_url:
send_feishu_message(feishu_webhook_url, f"❌ **[预置并发错误]**\n**时间:** {execution_time}\n{error_msg}")
return {
'statusCode': 400,
'body': error_msg
}
# 根据action决定是否配置预置并发
enable_provisioned = (action == 'set')
# 将英文操作类型转换为中文
action_chinese = "配置阈值并发" if action == "set" else "取消阈值并发" if action == "remove" else action
# 存储操作结果
results = []
try:
# 遍历所有需要处理的函数类型
if enable_provisioned:
# 直接从 provisioned_concurrency_config 获取 function_name 和 concurrency 数量
for function_name, concurrency_str in provisioned_concurrency_config.items():
provisioned_concurrency = int(concurrency_str)
response = client.put_provisioned_concurrency_config(
FunctionName=function_name,
Qualifier='provisioned', # 或者也可以从配置中传入 qualifier
ProvisionedConcurrentExecutions=provisioned_concurrency
)
results.append(f"{function_name} 预置并发配置为 {provisioned_concurrency}")
else:
response = client.delete_provisioned_concurrency_config(
FunctionName=function_name,
Qualifier=alias_name
)
results.append(f"{function_name} 取消预置并发配置")
# 发送成功通知
status_icon = "✅" if action == "set" else "❌"
result_message = f"{status_icon} **[预置并发操作完成]**\n**时间:** {execution_time}\n**环境:** {env}\n**操作:** {action_chinese}\n\n" + "\n".join(results)
if feishu_webhook_url:
send_feishu_message(feishu_webhook_url, result_message, at_all=False)
return {
'statusCode': 200,
'body': f'成功处理所有函数 (action: {action_chinese}): ' + '; '.join(results)
}
except Exception as e:
error_message = f"操作失败: {str(e)}"
print(error_message)
# 发送失败通知并@全体成员
fail_message = f"❌ **[预置并发操作失败]**\n**时间:** {execution_time}\n**环境:** {env}\n**操作:** {action_chinese}\n\n**错误详情:** {error_message}"
if feishu_webhook_url:
send_feishu_message(feishu_webhook_url, fail_message, at_all=True)
return {
'statusCode': 500,
'body': error_message
}
2.3.4 配置EventBridge 的 Scheduler
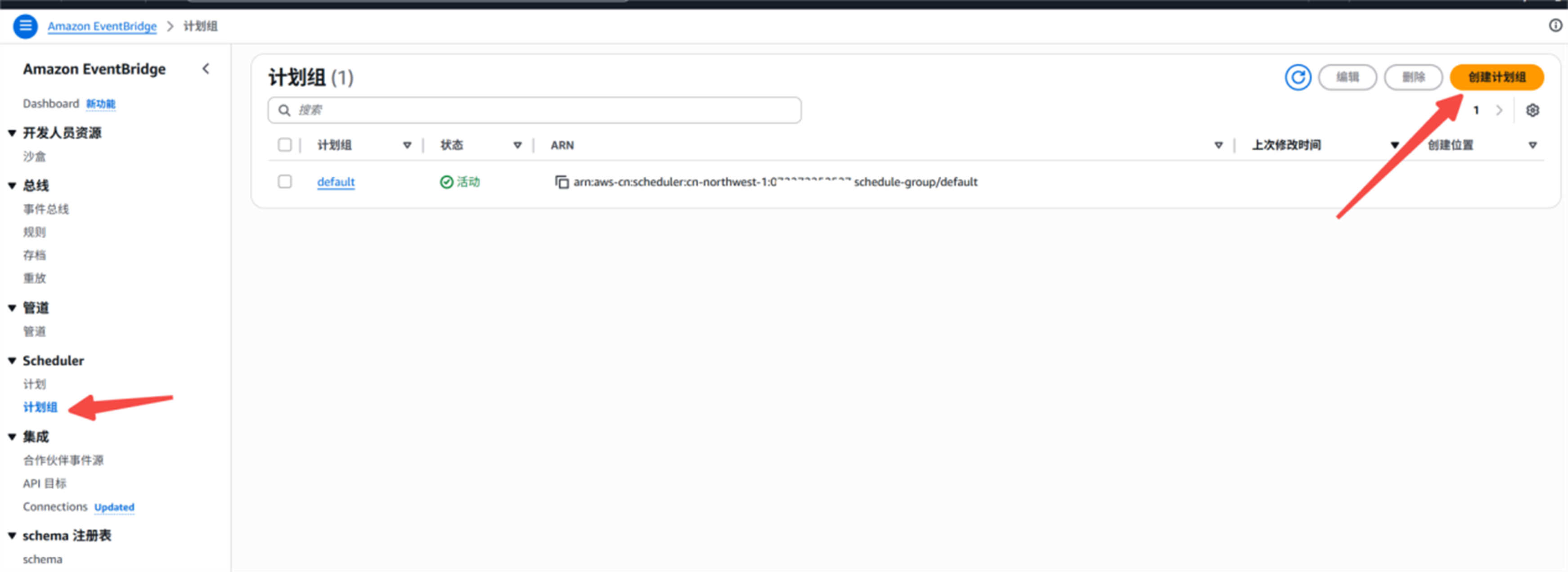
创建计划组
统一管理计划任务
创建给 scheduler 的role
Amazon_EventBridge_Scheduler_op-test-Lambda-provisioned
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"Lambda:InvokeFunction"
],
"Resource": [
"${替换需要配置预置并发的Lambda函数arn}:*",
"${替换需要配置预置并发的Lambda函数arn}"
]
}
]
}
信任关系
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "scheduler.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "${账号id}"
}
}
}
]
}
创建后保存该IAM role的arn
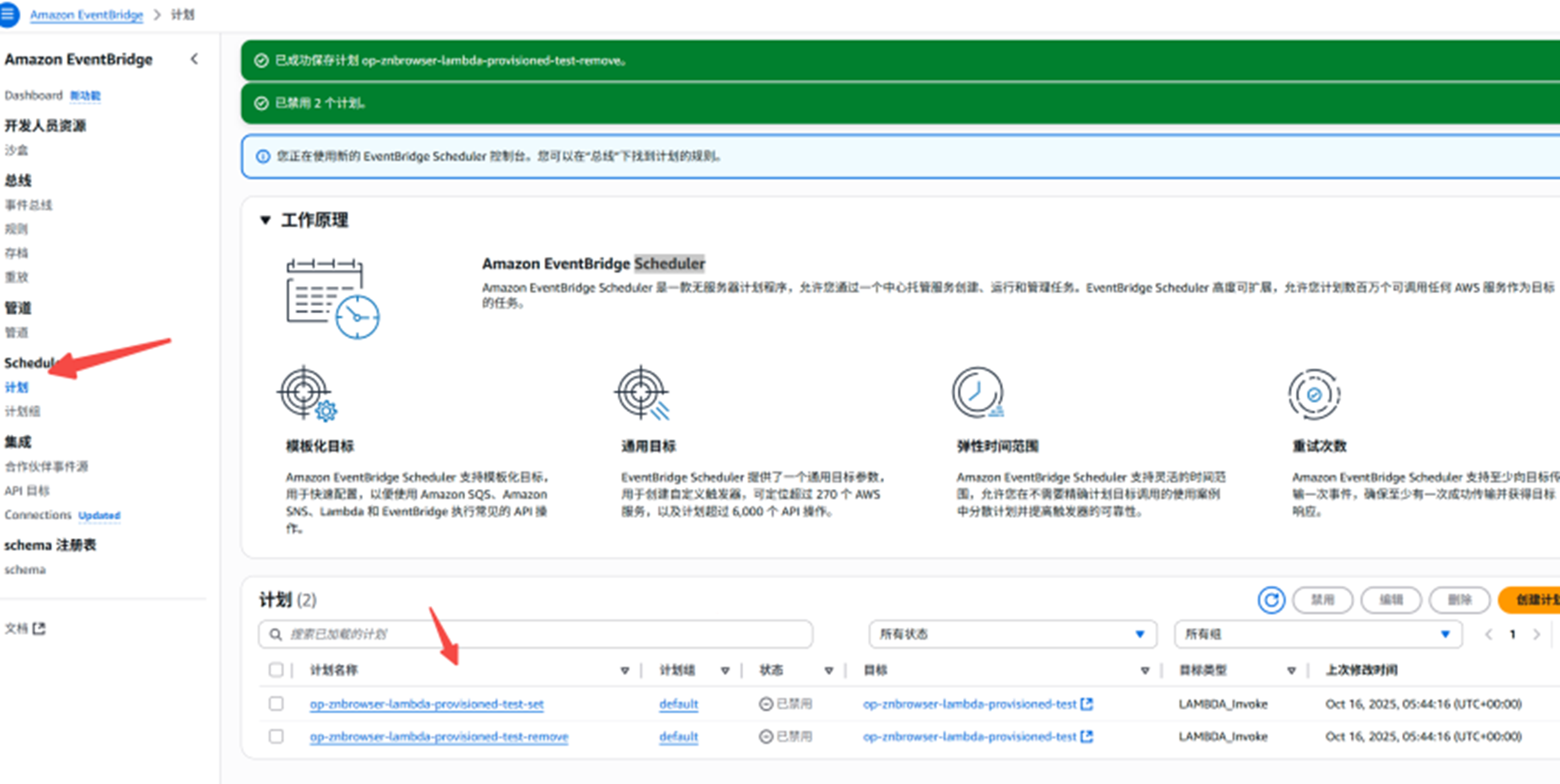
创建配置预置并发的计划
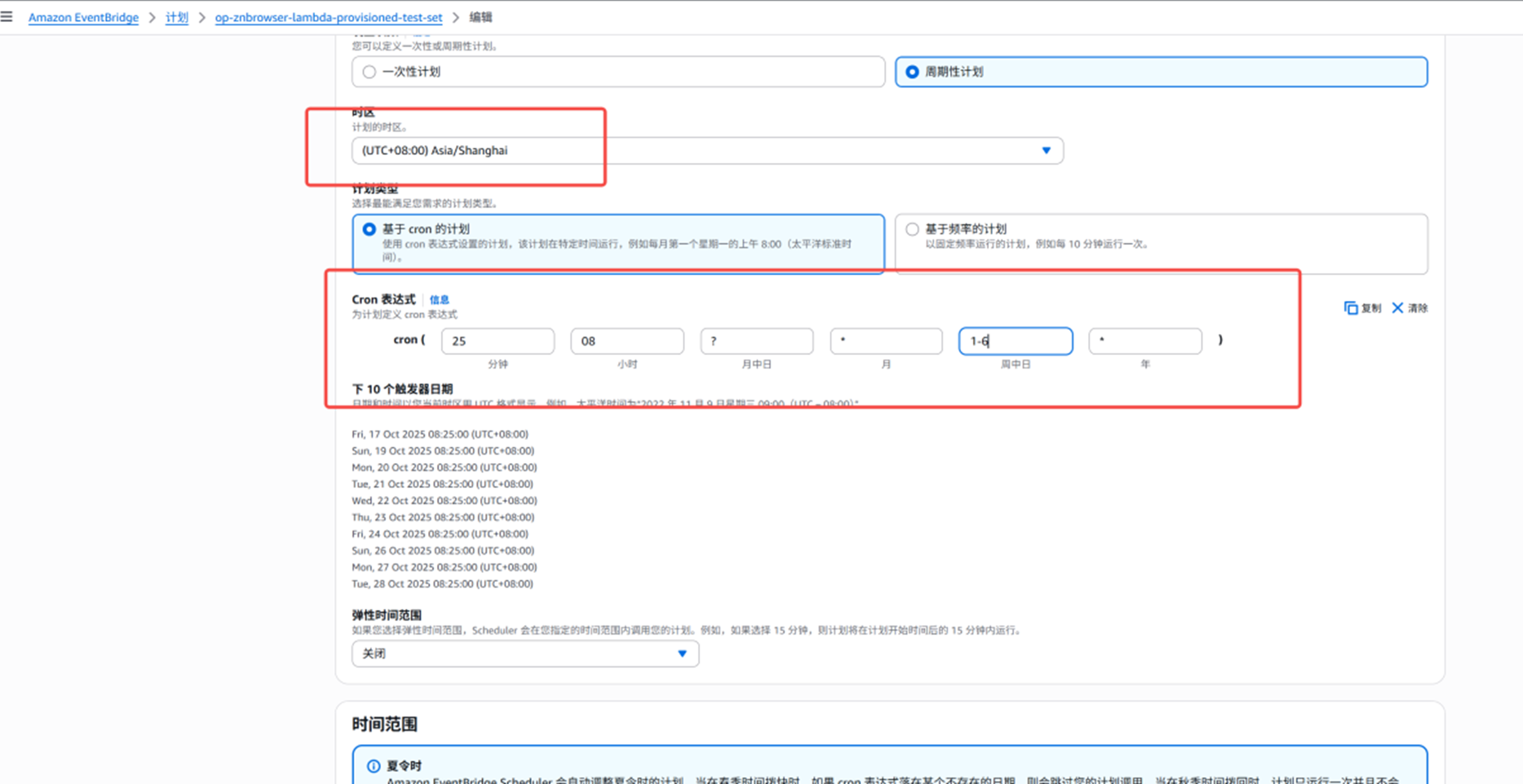
配置在 北京时间 08:25分 Lambda 预置并发的计划,为了给执行环境扩容预留充足的时间,扩容的计划时间要提前5分钟,配置的时候注意时区
cron 25 08 ? * 1-6 *
计划名称:test-Lambda-provisioned-set-08-25
下一步
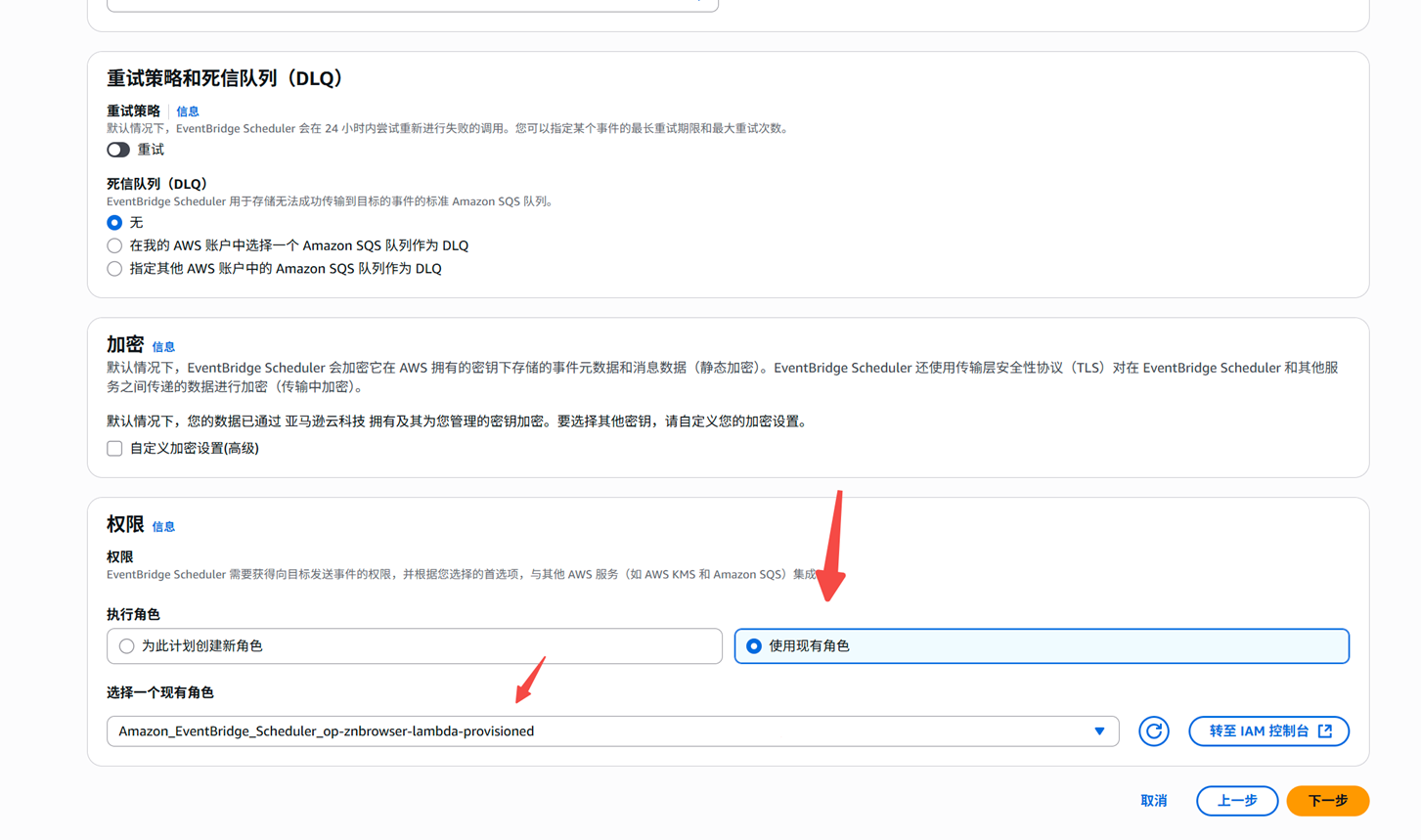
下一步,选择上一步创建的IAM role角色
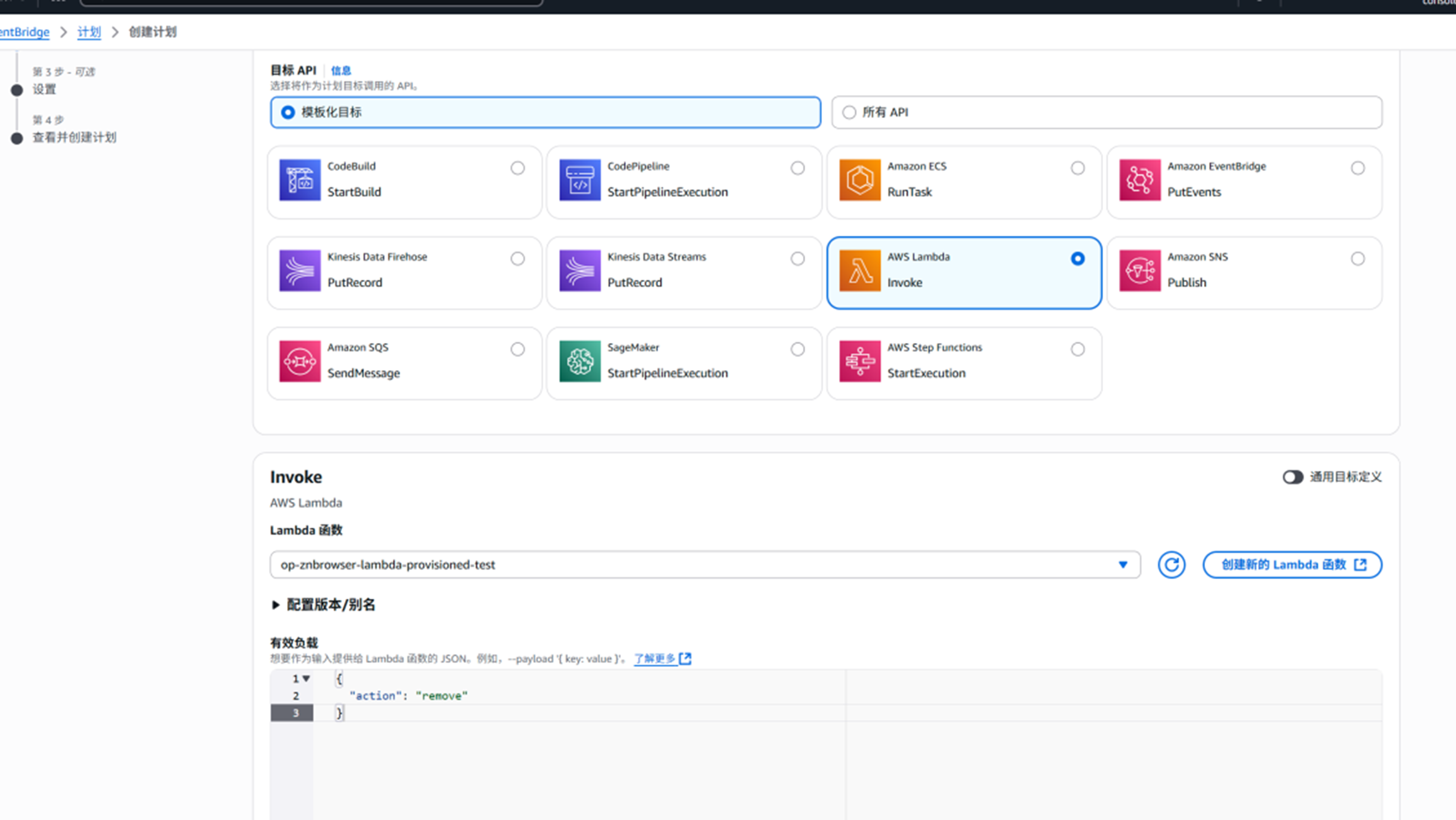
下一步,创建set预置并发计划
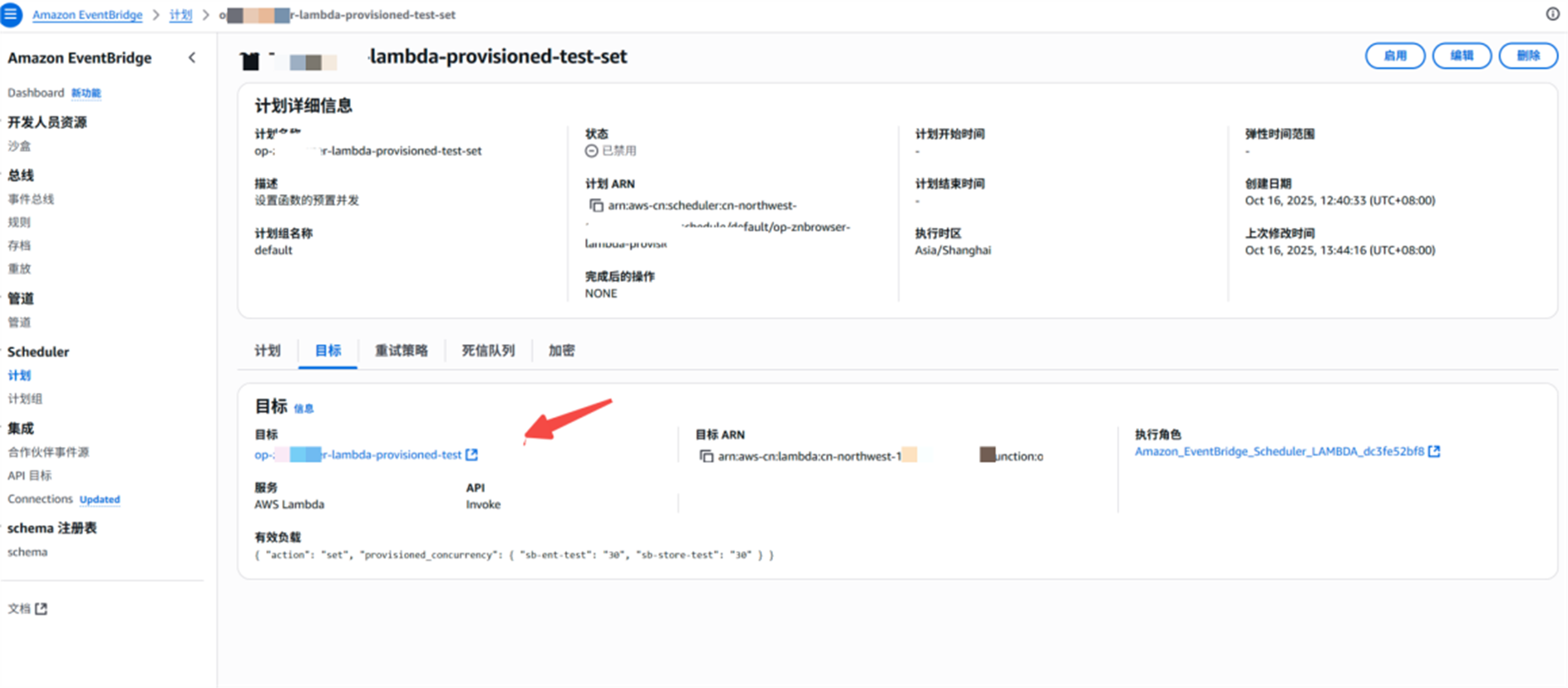
{
"action": "set",
"provisioned_concurrency": {
"test01": "1000",
"test02": "500"
}
}
说明:
Test01: 函数名 后面是并发数值
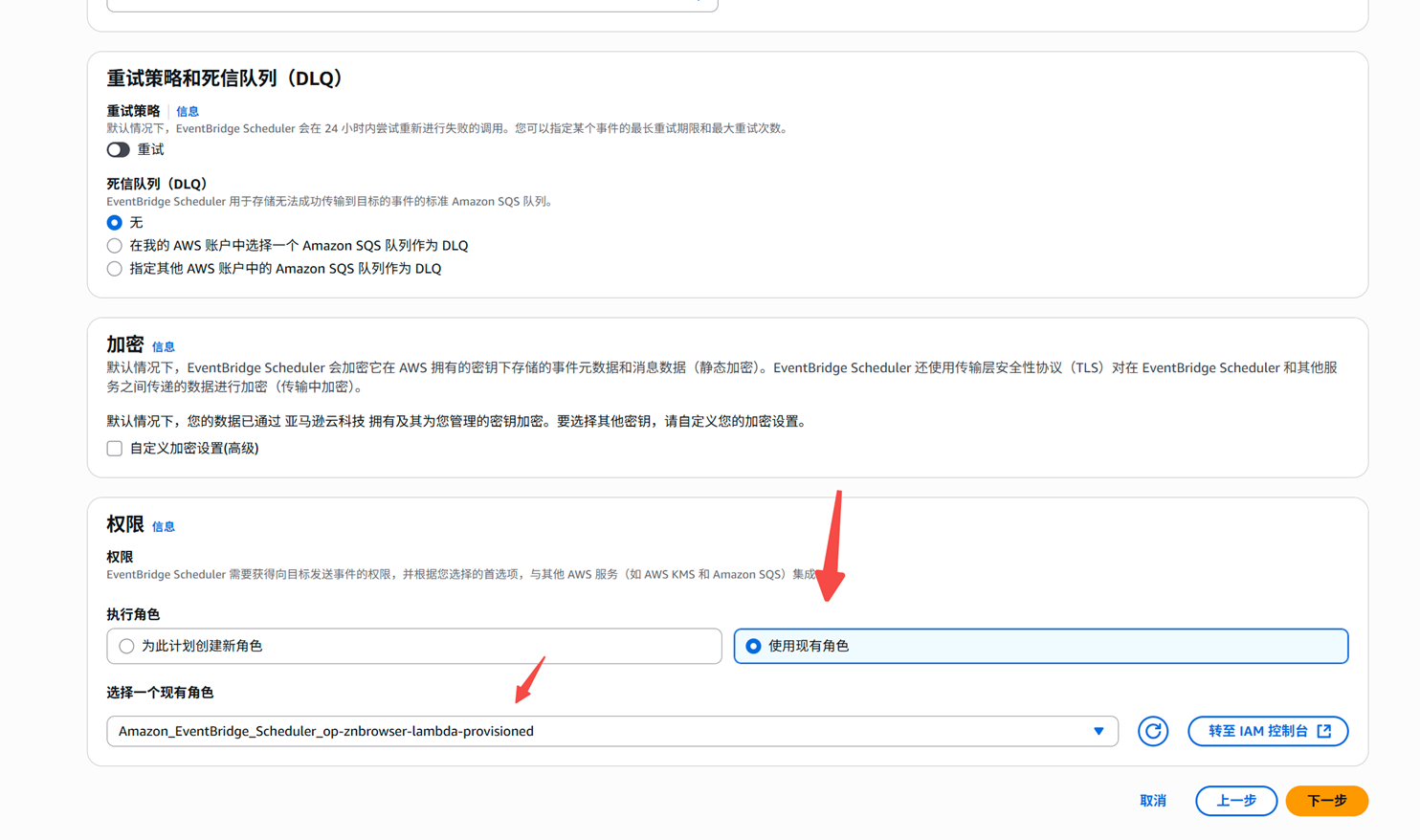
创建取消预置并发的计划
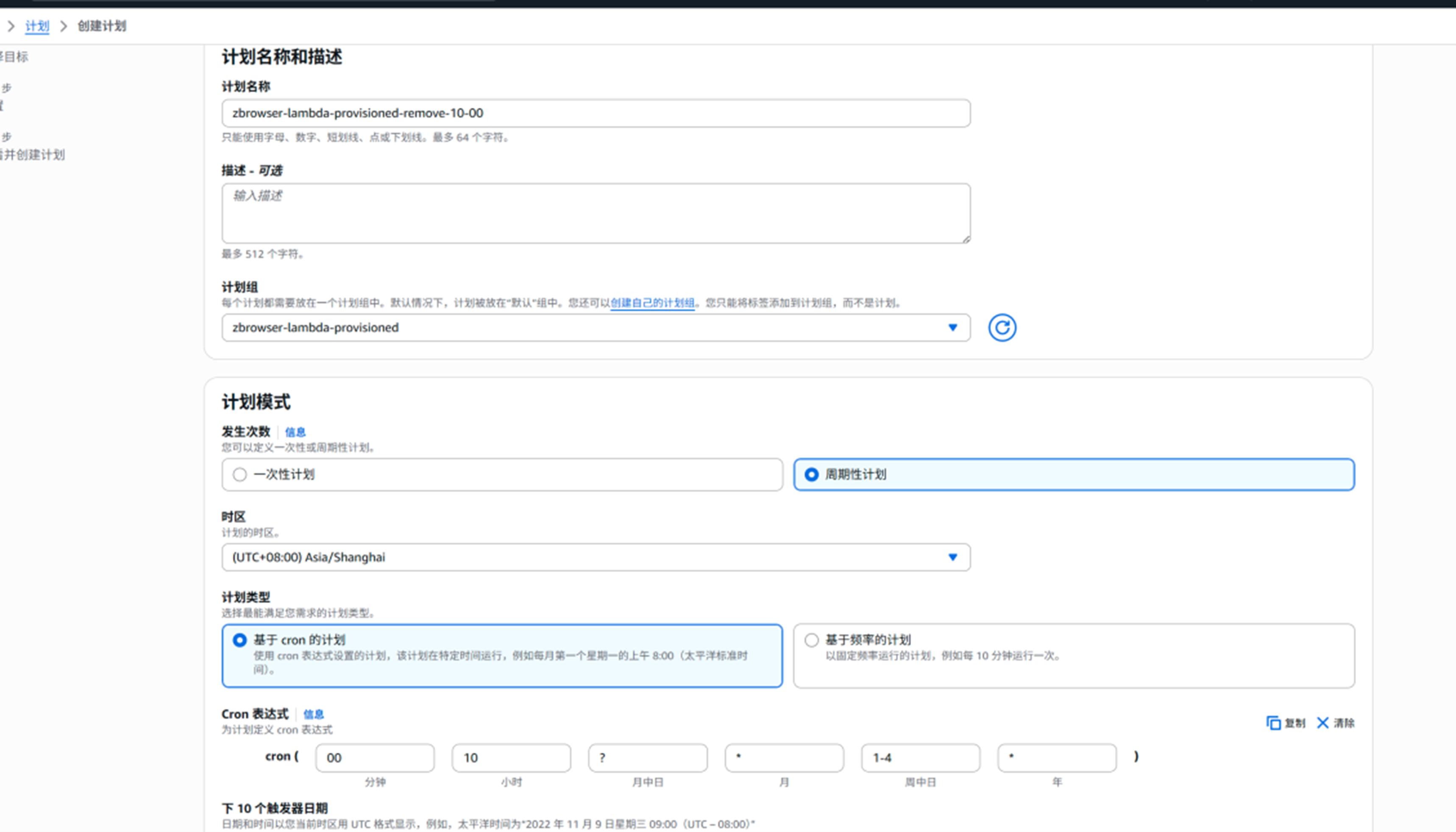
cron 25 10 ? * 1-6 *
计划名称: zbrowser-Lambda-provisioned-remove-10-00
后面是时间
下一步,角色选择上一步创建的role
下一步,创建remove预置并发计划
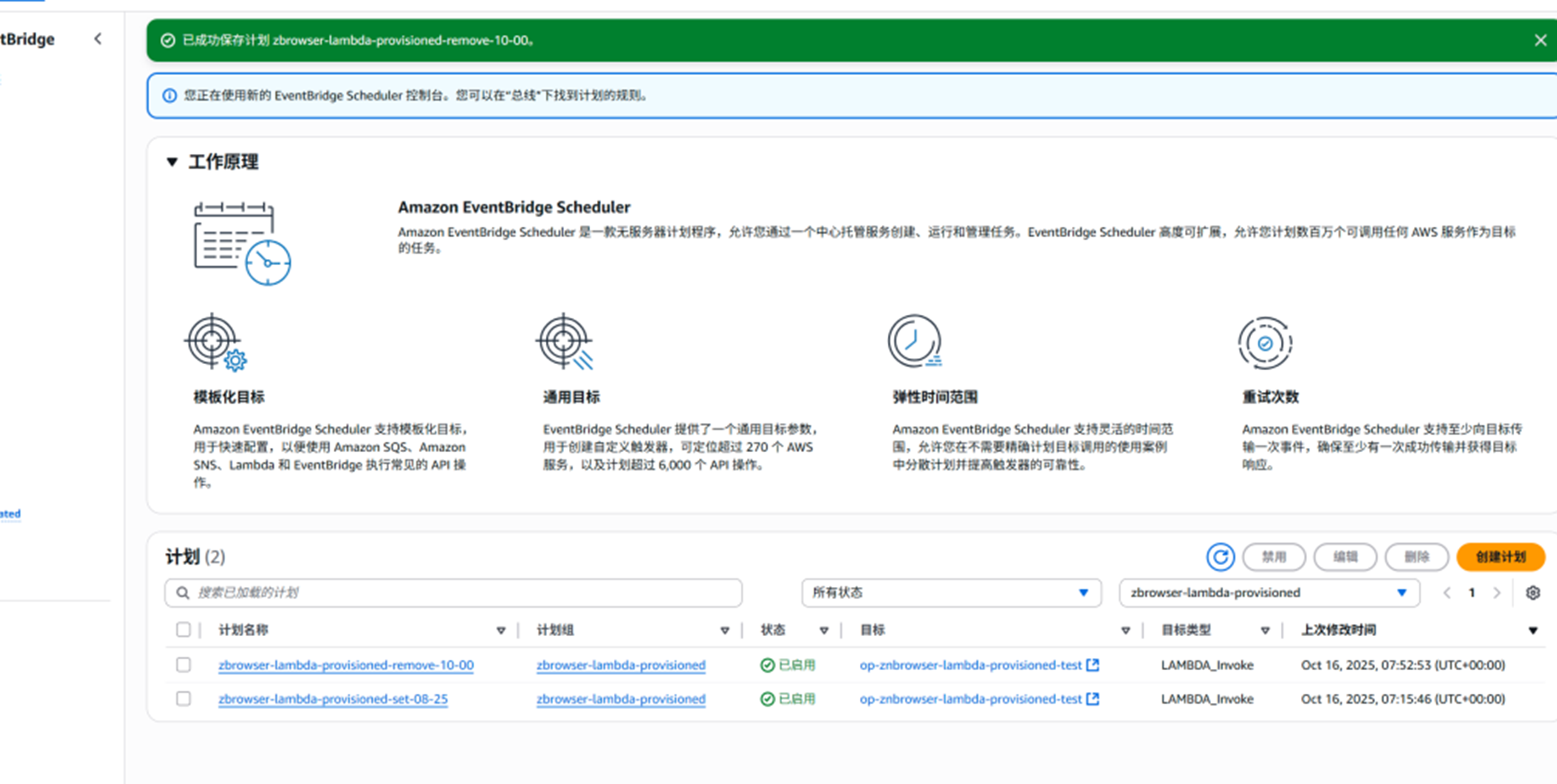
创建完成的计划
3. 实现效果
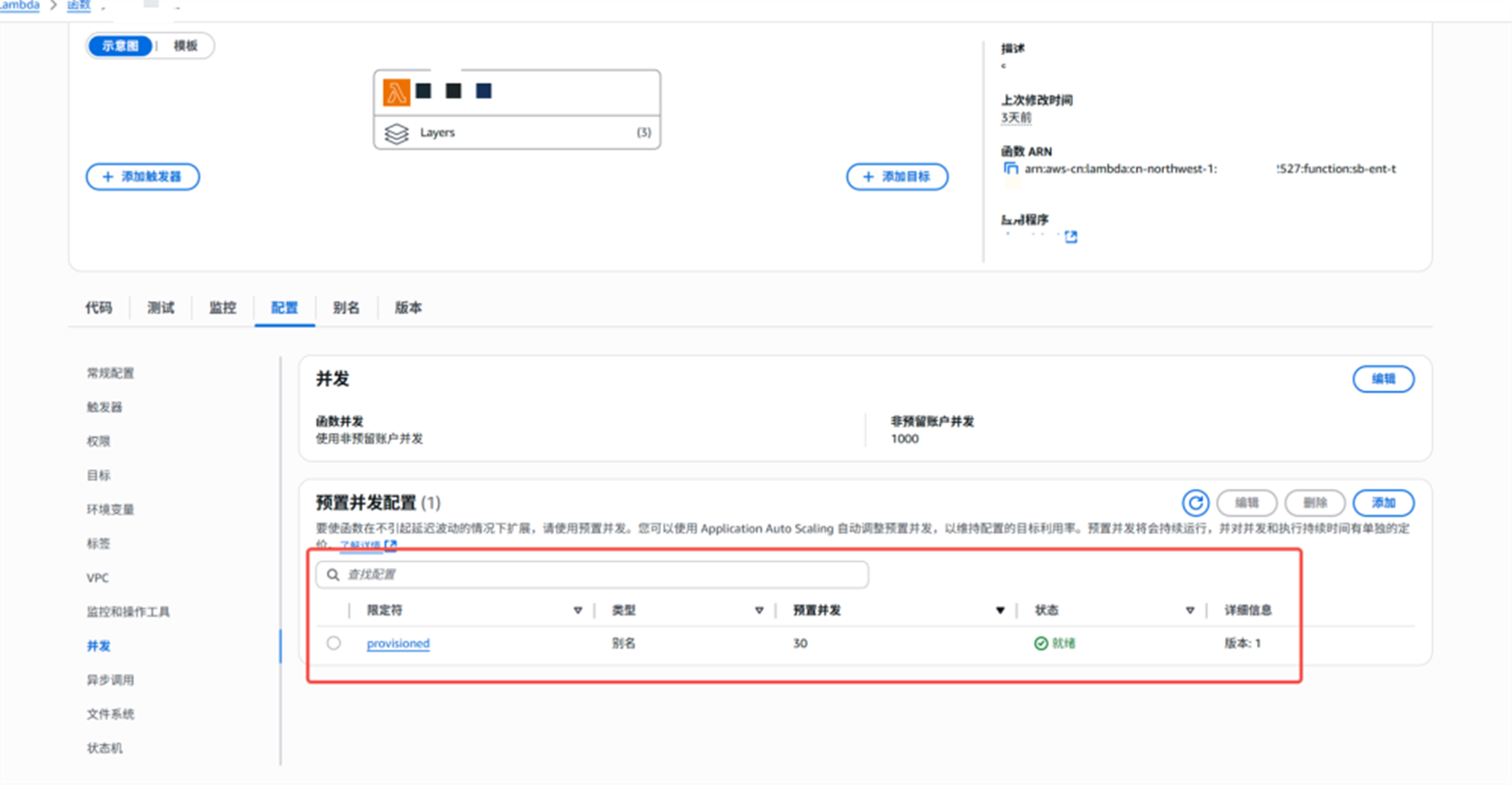
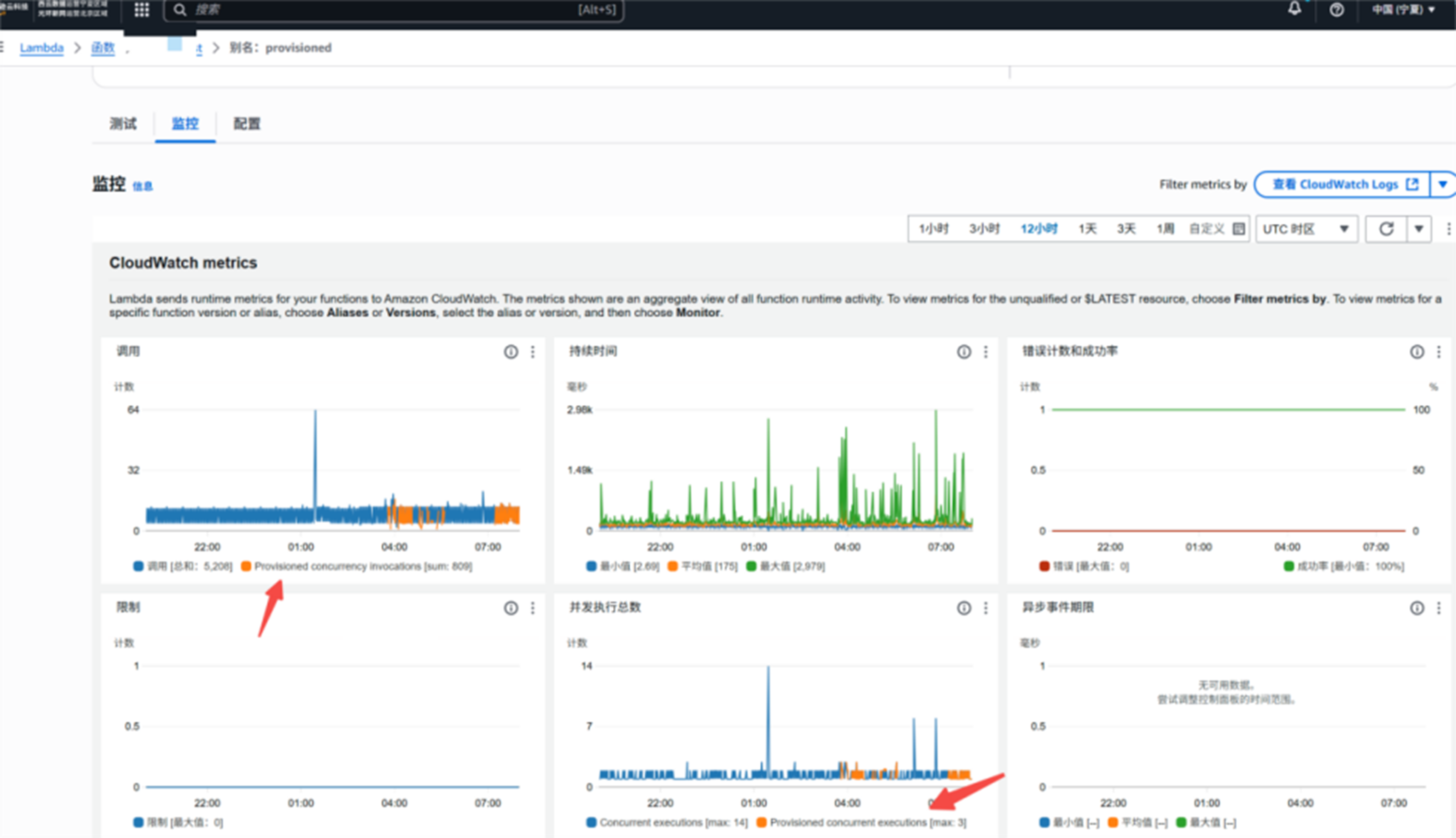
预置并发生效
监控指标:在别名的指标监控里有一个指标
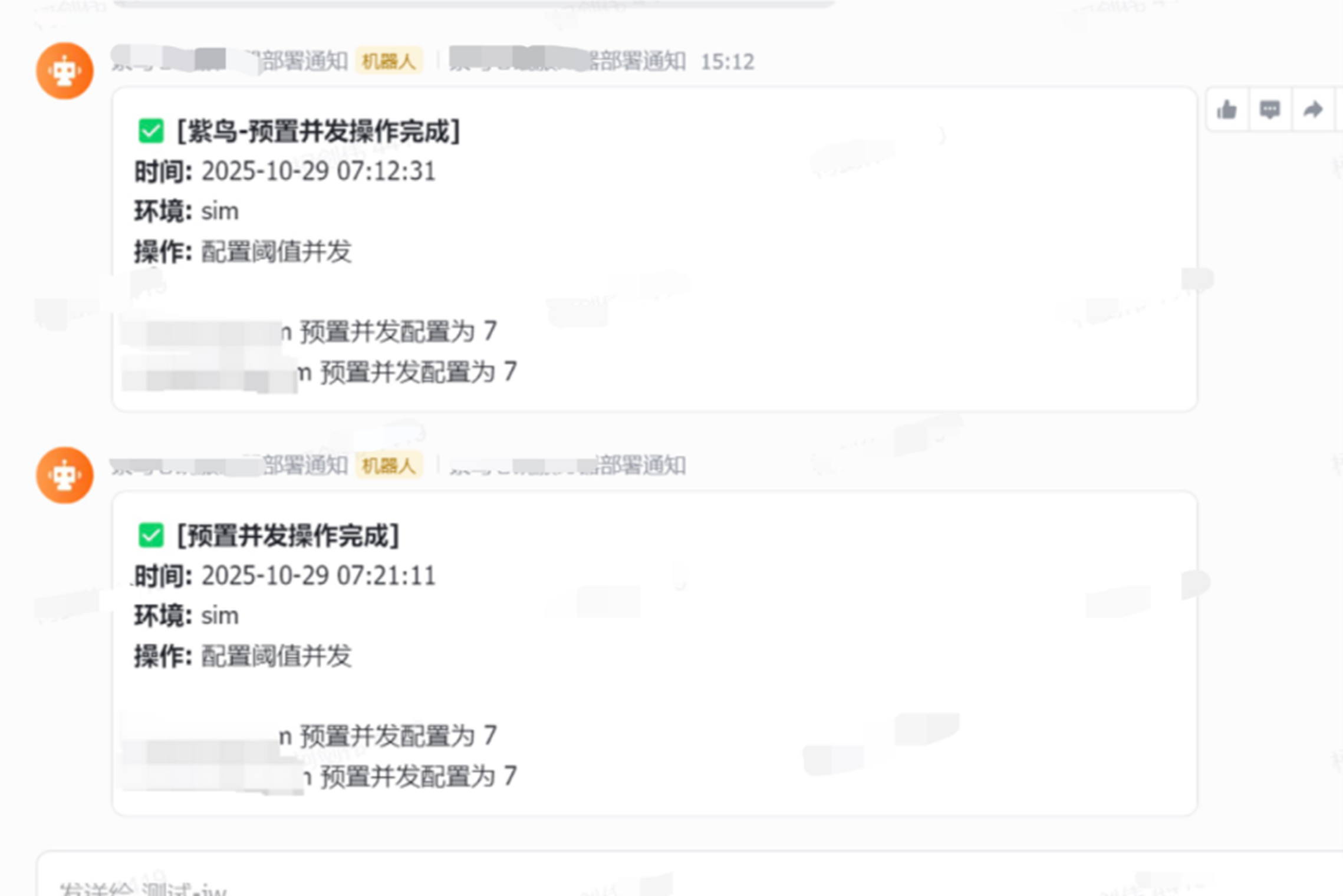
飞书webhook通知:
4. 结语
本方案通过将Lambda预置并发、EventBridge事件驱动调度与按需扩展相结合,本方案在业务高峰期显著提升了生产环境Lambda的并发处理能力与稳定性,同时通过自动化与监控实现成本的可控性。未来将基于实际负载进行自适应调整,进一步优化触发时点与容量配置,以实现更高的资源利用率与业务弹性。
文末,感谢亚马逊云科技中国区域企业支持团队提供的支持跟帮助。
参考链接:
https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/scaling-behavior.html
https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/configuration-concurrency.html
https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/provisioned-concurrency.html#managing-provisioned-concurency
https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/monitoring-metrics-types.html#concurrency-metrics
https://docs.aws.amazon.com/zh_cn/eventbridge/latest/userguide/eb-run-lambda-schedule.html
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
柯剑伟
紫讯科技资深运维专家, 具有8+年运维从业经验,涉及行业包括移动互联网,金融等行业,主要担任SRE、云计算运维工程师、运维架构师等岗位,主要负责企业级IT基础设施的规划、部署、监控和优化工作,专注于构建高可用、高性能的分布式系统架构。
苏锐
西云数据技术客户经理,具有12+年IT及云计算从业经验,涉及行业包括移动互联网、泛娱乐直播、零售、政企等行业,曾担任技术支持经理、SRE、云计算产品架构师等岗位,对流媒体、内容分发、无服务器以及边缘计算领域拥有丰富的行业实践。
AWS 架构师中心:云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用