亚马逊AWS官方博客
基于 HAMi 的 GPU 虚拟化实践
 |
1. 引子
在当下的 AI/ML 应用实践中,我们能明显感受到两股趋势的并行发展:
一方面,传统的小模型推理与部署方兴未艾,它们在推荐系统、实时预测、路径优化等业务中依然有着广阔的应用场景,对GPU单卡资源的共享与隔离需求更加精细化,如何实现高效利用成为重点;
另一方面,以大语言模型为代表的大模型部署正在快速兴起,对GPU多卡资源算力弹性的要求越来越高,也对底层虚拟化与调度提出了全新的挑战。
正是基于这两个场景的实际需求,我们开始关注 GPU 虚拟化相关的解决方案,并探索如何在云原生环境下更高效地利用 GPU 资源。本文以实际项目实施过程为主线,通过:
- 详细分析客户对GPU虚拟化的实际需求
- 对Nvidia主流GPU虚拟化方案的原理和挑战分析
- 再结合开源方案 HAMi的原理解析,方案选型过程,以及 基于EKS的部署方式和测试验证
为大家展示基于HAMi的GPU虚拟化项目落地过程的思考与实践。
2. 项目需求综述
项目旨在基于 Kubernetes 构建 GPU 资源申请与管理平台。应用端只需提交统一的 GPU 资源需求(如 GPU 数量与显存大小),平台即可根据需求自动完成资源分配,实现 GPU 算力共享与显存严格隔离,从而提升 GPU 集群的整体利用效率。
典型应用场景主要包括:
- 小模型部署:
资源需求:典型的模型规模对显存需求约 4–5GB,T4 / A10机型单卡即可满足算力需求。每个模型独立部署为一个 Pod。
隔离需求:单卡并行多个模型时,需保证显存隔离,避免 OOM 或性能抖动;同时支持算力共享,避免 GPU 算力空闲浪费。 - 大模型(LLM)部署:
资源需求:典型的模型规模对显存占用较大,且需多张物理 GPU 支撑,希望以与小模型一致的方式,直接声明所需 GPU 数量与显存大小
资源隔离需求:支持多卡部署以及固定显存配额分配,确保大模型运行过程中的资源稳定可控。
基于以上需求我们对Nvidia的主流GPU虚拟化方案进行了分析,发现当前的方案虽然在一定程度上能满足GPU 虚拟化需求,但在多租户大规模生产环境中,依然存在隔离性不足、资源利用率不高、硬件依赖强等问题。
3. Nvidia 主流 GPU 虚拟化方案分析及局限
目前Nvidia 提供的三种主流方案包括MIG (Multi-Instance GPU)、MPS (Multi-Process Service) 和 Time Slicing (时间片调度)。它们各自针对不同的应用场景,解决了部分资源复用与隔离问题,但在实际生产环境下仍存在局限。
- MIG(Multi-Instance GPU)
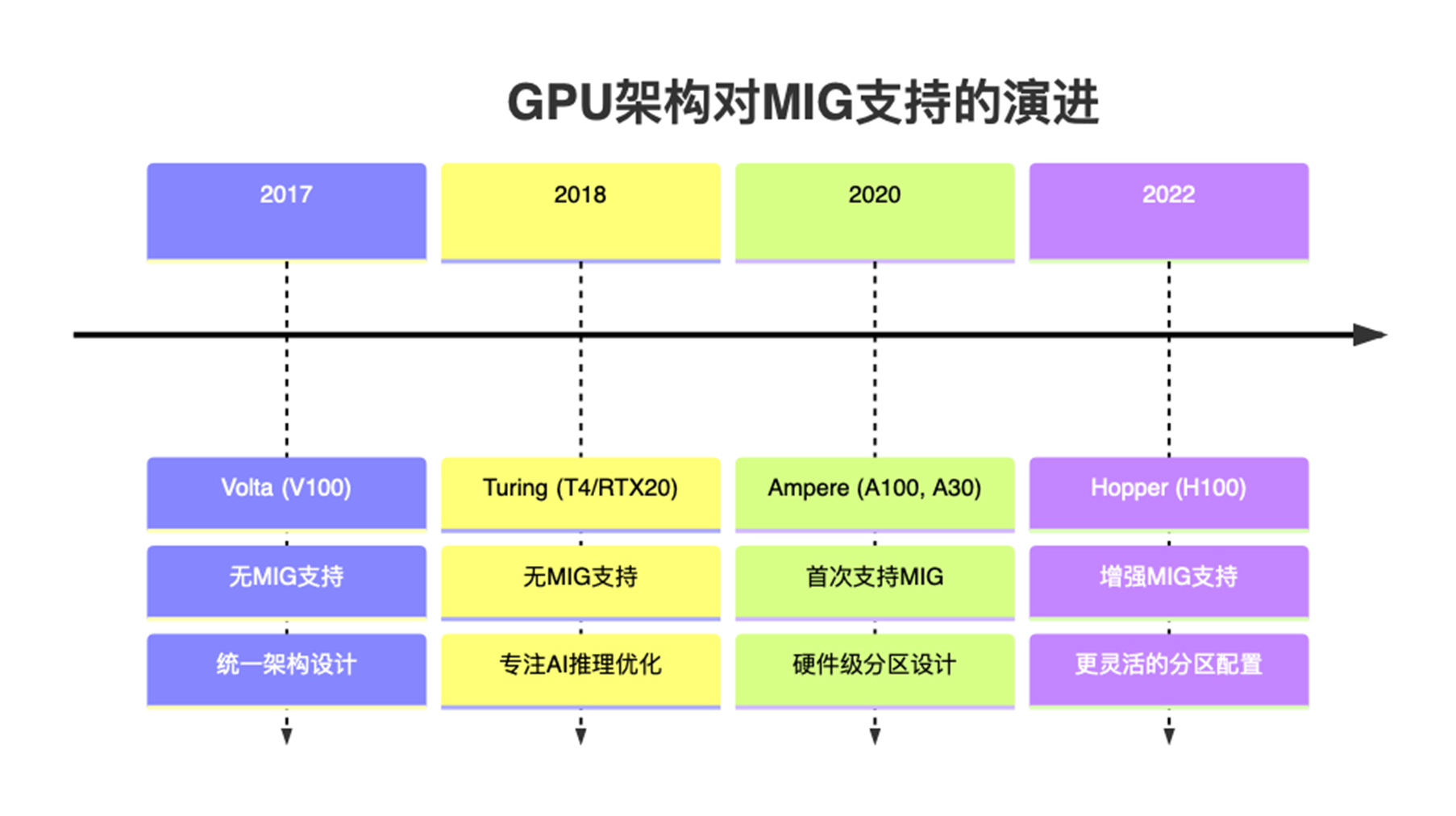 |
MIG 是Nividia对 A100、H100 等新一代GPU 提供的软硬件一体化的GPU/显存隔离技术。硬件层面,可以将SM + L2 Cache + 内存控制器 + IO 通道切割成多个独立MIG单元,每个单元就是一个独立的 GPU 实例,从应用和容器视角看就获得一张小GPU资源;从软件层面,在nvidia driver中增加了MIG driver,实现对支持隔离的硬件的调用,从而实现端到端的GPU虚拟化。
该方案在多租户场景下,虽然能够保证显存和算力的强隔离,但仅支持部分高端 GPU(如 A100/H100),对常见的 T4、A10 不适用。
- MPS(Multi-Process Service)
MPS的核心是在CUDA Runtime和CUDA Driver之上引入了MPS服务层,把多个进程的 CUDA 内核请求合并并下发给 GPU,使得多个 CUDA 进程(或多个容器内的进程)能够共享 GPU 的SM(即算力部分),从而避免了CUDA Context频繁上下文切换,实现GPU利用率的提升。
但对显存分配上,每个进程仍然直接向CUDA Driver独立进行显存申请,不会被 MPS统一调度。因此无法实现显存隔离。所有进程共享同一显存地址空间,任何进程 OOM 都可能导致整个 GPU 崩溃。无法满足当前项目需求
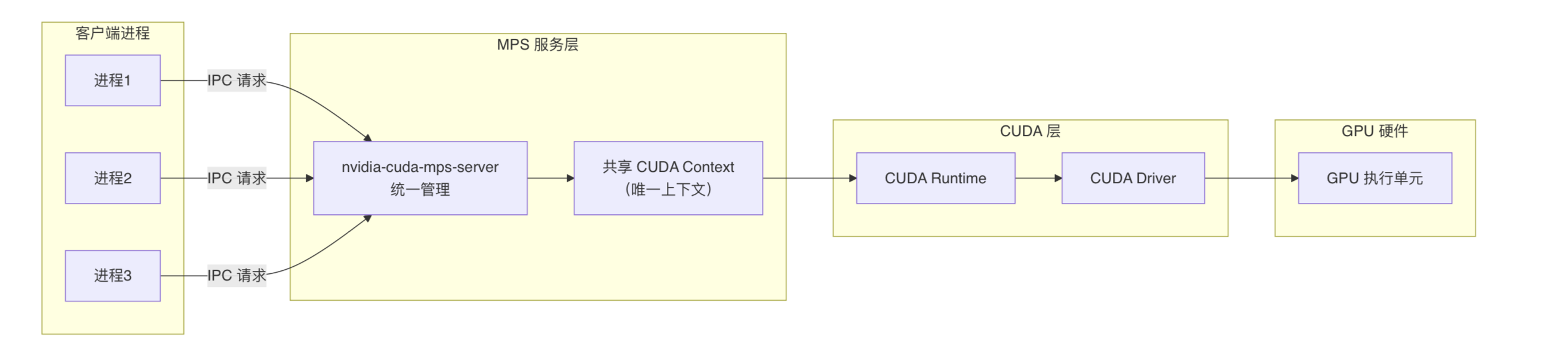 |
- Time Slicing(时间片调度)
Time Slicing 是最基础的 GPU 资源复用方式,通过时间片轮转的方式在多个应用之间共享 GPU。每个应用在分配的时间片内独占 GPU 资源。该方案仅能作为“最低成本的 GPU 复用手段”,适合对延迟不敏感的批处理任务以及需要最小改造、快速共享 GPU 的简单场景。但Time Slicing 即不能在小模型场景提供显存隔离;也不能在大模型场景实现跨卡部署。不符合我们项目的需求。
综上所述,在多租户、大规模、云原生的生产环境中,Nvidia 现有方案存在明显不足,这也是我们转而探索 HAMi方案的原因。
4. HAMi方案原理分析
HAMi是开源的 GPU 虚拟化与调度系统https://project-hami.io/,目标是为 Kubernetes 环境下的深度学习/推理任务提供细粒度、灵活的 GPU 资源管理能力。其思路是:在K8s调度层与GPU driver层能力之间,建立一个智能的中间层,用统一的接口和策略提供给用户。这样,用户提交任务时不需要关心底层细节,只需要声明需要多少 GPU 算力/显存,HAMi 就能动态分配、隔离并调度。
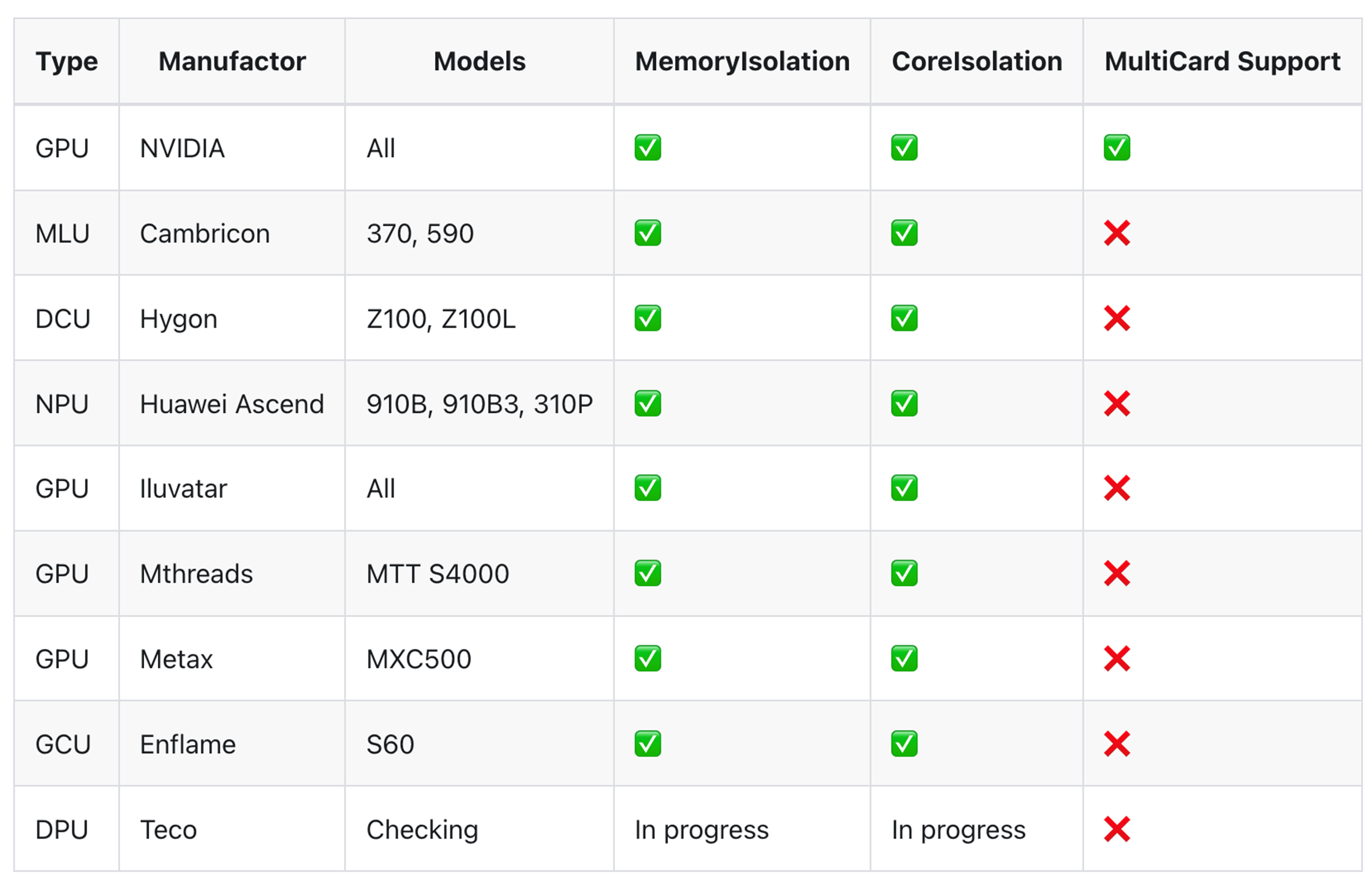
如下表格是HAMi对支持的Device类型及隔离能力的说明https://project-hami.io/docs/userguide/device-supported/。从该表格可以初步评估,HAMi可以满足对Nvidia GPU资源的内存隔离、核心隔离和多卡支持。
 |
在初步判定方案可行后,我们对HAMi的原理进行了分析,以求更深入的理解其虚拟化能力。下图是我们基于Amazon 最新推出的AI IDE Kiro对HAMi的源码https://github.com/Project-HAMi/HAMi进行分析后生成的HAMi架构图。该图从Pod调度以及Pod的持续运行两个阶段分别说明了HAMi是如何进行GPU资源管理的。
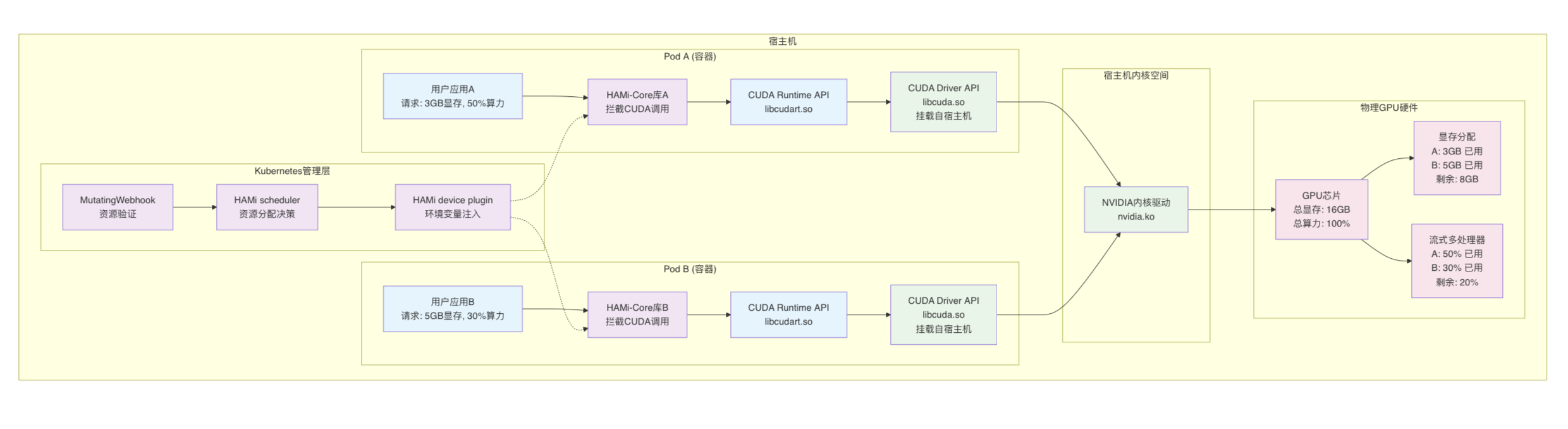 |
4.1 Pod调度阶段
在 Kubernetes 集群中,HAMi 扩展了 Pod 的调度与运行流程。整个过程可以分为以下几个阶段:
1.Pod 提交与 MutatingWebhook 拦截
当用户提交一个带有 GPU 资源请求的 Pod 时,请求首先进入 API Server。此时 MutatingWebhook会拦截 Pod 对象,对其中的 GPU 资源声明进行补全和修正,例如:
- 自动设置 schedulerName=hami-scheduler
- 注入 runtimeClassName=nvidia
- 为容器补齐必要的 GPU 资源字段和环境变量
同时,HAMi还会通过 Pod 的环境变量和容器启动参数注入 LD_PRELOAD,确保在容器启动后,应用程序会自动加载 HAMi Core 的动态库。这样,就为后续的 GPU 调度与运行阶段预埋了“劫持” CUDA API 的钩子。
这样,Pod 被标记为交由 HAMi Scheduler来处理,而不是默认调度器。
2.HAMi Scheduler 调度
Pod 被送入 HAMi Scheduler 的调度逻辑:
- Filter 阶段:解析 Pod 的资源需求,筛选出满足显存、算力等要求的候选节点。
- Score 阶段:对候选节点进行多维度打分,包括资源利用率、碎片化程度、拓扑结构等。
- Bind 阶段:选择最优节点,并将 Pod 绑定到该节点。
这一流程保证了 Pod 能够在合适的 GPU 上运行,并提高集群整体的利用效率。
3.HAMi device plugin与环境变量注入
当 Pod 被分配到节点后,HAMi Device Plugin接管了容器与 GPU 的连接过程。与 NVIDIA 官方插件相比,HAMi device plugin不仅保留了驱动与 API 的兼容性,还新增了以下能力:
- 为容器注入显存、算力、任务优先级等控制参数
- 挂载 HAMi Core 库,实现对 GPU 的虚拟化控制
- 精细化配置 CUDA_MEM_LIMIT、CUDA_CORE_LIMIT 等环境变量,实现资源隔离与共享
最终,Pod 内部的应用感知到的 GPU 是一个受控的虚拟化 GPU,既保证了隔离性,也支持资源共享。
4.2 Pod持续运行阶段
在Pod启动后,HAMi Core通过Linux 的 LD_PRELOAD 机制直接“嵌入”到应用进程中。
LD_PRELOAD 是 Linux 动态链接器的一种功能,允许开发者在运行时指定一个自定义的动态链接库,让它在系统标准库之前被加载。这时程序里调用的函数(比如 malloc、open,或者在 CUDA 应用里调用的 cudaMalloc)就会先经过自定义库的实现,从而实现“函数劫持”(interception)。HAMi Core 正是利用这一点:它通过 LD_PRELOAD 注入一个定制的库到容器应用中,这个库拦截了关键的 CUDA Runtime API(如 cudaMalloc)。
关键工作流程如下:
- 拦截调用:当应用尝试调用 cudaMalloc 申请显存时,请求首先会进入 HAMi Core 的拦截逻辑,而不是直接进入 CUDA runtime API。
- 资源校验:HAMi Core 会读取 Pod 下发的 GPU 配置(例如显存上限),检查本次申请是否超限。
- 严格控制:若超出限制,则直接拒绝分配并返回错误码;若合法,则放行并记录分配情况。
- 持续监管:所有显存分配和释放都会经过这种拦截校验机制,形成一个完整的 Pod 级“资源沙盒”。
对比NVIDIA MPS 仅能在 GPU 核心算力(SM)维度做时间片调度不同,HAMi Core 能进一步在显存维度上做细粒度隔离。这样即便某个应用因为显存泄漏或异常崩溃,也不会像 MPS 下那样拖垮同节点的其他应用。
经过原理分析后,我们开始EKS环境下HAMi的实际部署和测试,对项目需求进行验证。
5. 基于EKS的HAMi部署实践
5.1 HAMi组件安装
参考https://github.com/Project-HAMi/HAMi/blob/master/README_cn.md进行HAMi的安装。
- 首先,通过添加标签 “gpu=on” 来标记需要管理的GPU 节点,以便 HAMi 调度。没有此标签的GPU节点将无法被HAMi进行调度管理。
kubectl label nodes {nodeid} gpu=on
或在创建GPU节点组时打上该标签
- 之后进行HAMi的组件安装和参数设定
在 helm 中添加仓库
helm repo add hami-charts https://project-hami.github.io/HAMi/
使用以下命令进行部署:
helm upgrade -i hami hami-charts/hami -f my-values.yaml -n kube-system
my-value.yaml中配置hami-scheduler-device ConfigMap,以下为基于我们的项目场景进行的配置示例,具体的配置参数说明请参见https://github.com/Project-HAMi/HAMi/blob/master/docs/config.md
- 安装完成后检查HAMi组件,HAMi device plugin和HAMi scheduler已经正常运行。
如果你使用eksctl方式创建集群,EKS在检测到是GPU机型时会自动安装NVIDIA Device Plugin,这时就会同时存在hami-device-plugin 和 nvidia-device-plugin。但这两个plugin只能保留一个,因为hami-device-plugin是对nvidia-device-plugin的扩展。参考:
https://project-hami.io/docs/FAQ/#relationship-and-compatibility-between-hami-device-plugin-volcano-vgpu-device-plugin-and-nvidia-official-device-plugin HAMi Device Plugin and NVIDIA Official Device Plugin: Should not coexist to avoid resource conflicts.
kubectl get pods -n kube-system | grep hami
kube-system hami-device-plugin-64gb4 2/2 Running 0 18s
kube-system hami-device-plugin-rrwcb 2/2 Running 0 18s
kube-system hami-scheduler-5c4d5f76f5-j27w6 2/2 Running 0 18s
5.2 实际场景部署
- 场景一:小模型部署,需要多个task能够显存隔离,但共享GPU算力
- 场景二:大模型部署,希望每个task能够占用多个物理GPU,同时能够进行显存隔离
对这个场景我们起初有个疑问,对具有4个物理GPU卡的机型,当deviceSplitCount=2时,就会虚拟出8张vGPU。这时如果申请GPU资源com/gpu: 2,实际的资源分配会如何呢?是会分配到一张物理GPU卡的两个vGPU?还是会落在两张物理卡上呢?
基于HAMi的FAQhttps://github.com/Project-HAMi/HAMi/issues/646我们找到了HAMi对vCPU的定义:
Significance of vGPU
vGPU represents different task views of the same physical GPU. It is not a separate partition of physical resources. When a task requests com/gpu: 2, it is interpreted as requiring two physical GPUs, not two vGPUs from the same GPU.
因此可以看到,vGPU并不代表对物理GPU的分割,而是从任务视角来定义一个GPU上可以跑几个任务。因此当申请GPU资源com/gpu: 2,会实际分配两张物理GPU卡,这正是我们部署大模型所需要的。
- 对场景二资源分配的实际验证:
- 测试环境:g4dn.12xlarge 4× T4 GPU (16GB/GPU, 总64GB)
- 模拟任务,启动两个task,每个申请4vGPU+4GB显存:
-
- 观察HAMi组件相关日志,观察硬件的注册情况:
- 日志显示了4个物理GPU的对应id,可以提供的vGPU数量/显存数量等。
-
- 观察每个pod的GPU分配情况
输出结果,验证每个pod都分配了4张物理GPU卡
=== Pod 1 GPU分配 ===
GPU-32bd4a3b-4574-1313-b734-938af0bb5125,NVIDIA,4000,0
GPU-e8767757-9f8c-af12-5dc0-6f1e851eca21,NVIDIA,4000,0
GPU-12041b93-e3ec-d354-b8e2-7f4dc39c8fe7,NVIDIA,4000,0
GPU-d1bc9932-e9bd-206a-aecc-63c2eb4dacd1,NVIDIA,4000,0
=== Pod 2 GPU分配 ===
GPU-32bd4a3b-4574-1313-b734-938af0bb5125,NVIDIA,4000,0
GPU-e8767757-9f8c-af12-5dc0-6f1e851eca21,NVIDIA,4000,0
GPU-12041b93-e3ec-d354-b8e2-7f4dc39c8fe7,NVIDIA,4000,0
GPU-d1bc9932-e9bd-206a-aecc-63c2eb4dacd1,NVIDIA,4000,0
进入一个Pod后查看GPU资源占用情况,验证每GPU上申请到4GB显存。
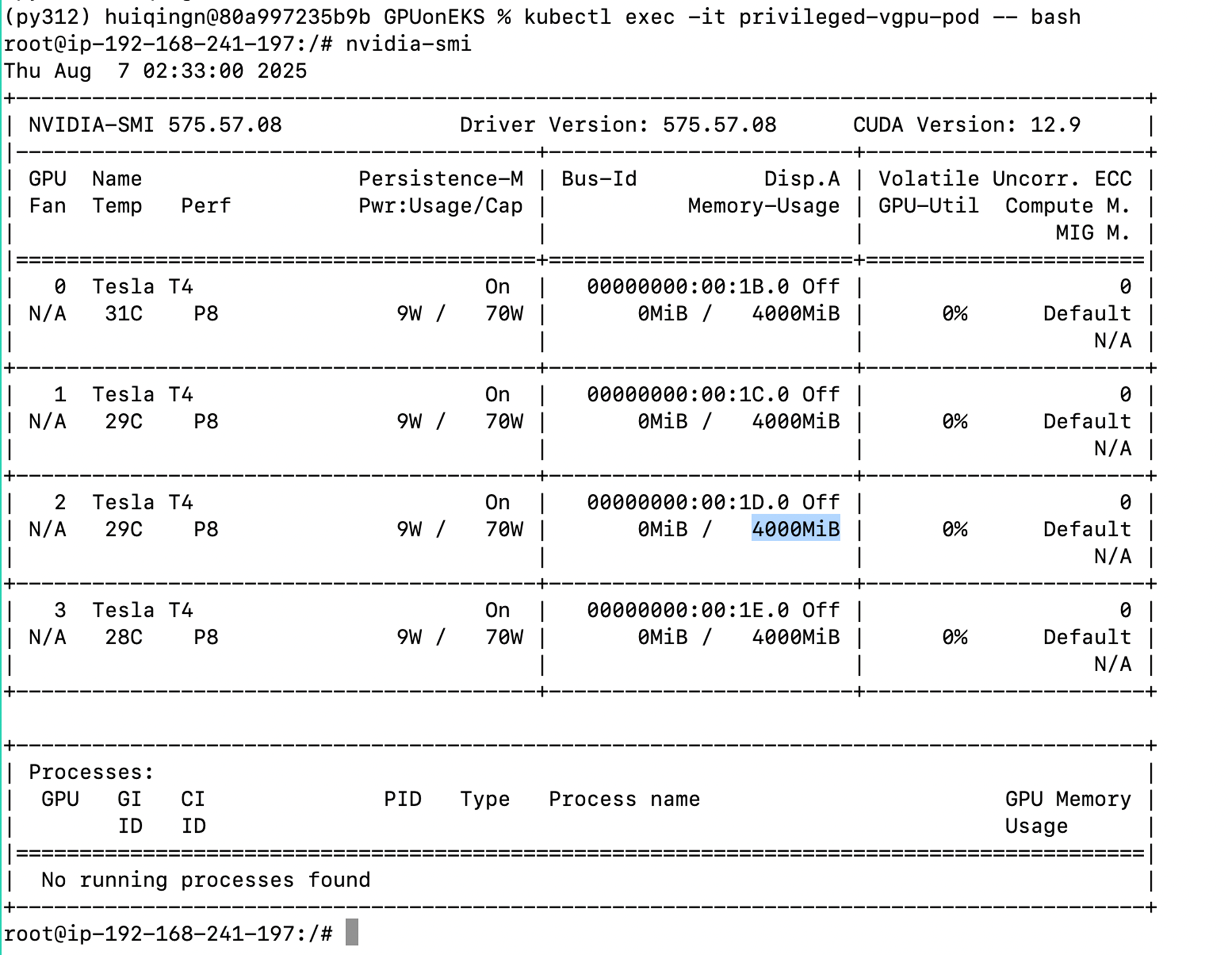 |
6. 典型场景下HAMi测试性能验证
在功能完全满足的情况下我们对性能继续做了测试,以考察HAMi对多任务并行情况下对GPU资源管理过程中对性能的损耗。
- 测试场景如下,对g4dn.xlarge 1× T4 GPU (16GB/GPU),启动HAMi的GPU资源管理
场景一:15G显存分配给一个Pod
场景二:7G显存分配给一个Pod
场景三:同时跑两个pod,每个Pod分别分配7G显存,对计算资源共享。
使用GPU 压力测试脚本,通过执行大规模矩阵乘法运算来持续负载 GPU,并测量其计算吞吐量。
- 压测脚本如下:
- 测试结果
使用设备: Tesla T4
矩阵大小: 8192×8192, 数据类型: torch.float32
目标运行时间: 300 秒 (~5.0 分钟)
| 场景 | 平均算力-Pod1 GFLOPS | 平均算力-Pod2 GFLOPS |
| 1.不使用HAMi的情况下,15G显存分配给一个Pod | 4280.19 | N/A |
| 2.不使用HAMi的情况下,7G显存分配给一个Pod | 4289.40 | N/A |
| 3.使用HAMi的情况下,两个pod分别申请7G显存/GPU共享 | 1751.64 | 1747.41 |
- 测试结果分析:该测试需要的内存不超过1GB,为算力密集性场景。
- 从场景1、2的对比可以看出,对资源分配实现了显存隔离,但算力是可以共享的
- 从场景3可以看出两个pod对算力的使用是抢占式的,且均分。
- 多个Pod并发执行时有算力损耗,大约在18%左右。
7. 总结
综上所述,HAMi 在 Kubernetes 上实现了显存与算力的精细隔离与共享,能够满足小模型和大模型部署的细粒度隔离需求。实测显示,多个 Pod 并发使用 HAMi 时算力虽有下降,但整体 GPU 利用效率显著提升——这是一种在可控开销下提升资源利用率的实用折中方案。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。