前言
Amazon Aurora 是专为云构建的一种兼容 MySQL 和 PostgreSQL 的关系数据库,它既具有传统企业数据库的性能和可用性,又具有开源数据库的精简性和成本效益。Amazon Aurora 的速度可达标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍。Amazon Aurora 由 Amazon Relational Database Service (RDS) 完全托管,Amazon RDS 可以自动执行各种耗时的管理任务。Amazon Aurora 采用分布式、有容错能力并且可以自我修复的存储系统,这一系统可以使每个数据库实例最高扩展到 256TB。它可实现高性能和高可用性,支持多达 15 个低延迟读取副本、时间点恢复、持续备份到 Amazon S3,以及跨三个可用区(AZ)复制。
MySQL 查询优化器作为数据库执行的核心组件,其生成高效执行计划的能力在很大程度上依赖于存储引擎所提供的统计信息质量。在数据管理过程中,像 InnoDB 和 MyISAM 这样的存储引擎会动态维护关键统计数据,包括表行数、列基数(即不同值的数量)以及索引分布等。这些信息对优化器的决策逻辑有着直接的影响。
在处理 WHERE 子句时,优化器会借助列基数来估算谓词选择性,进而决定是采用索引扫描还是全表扫描;而在多表连接的场景中,优化器会基于统计信息来评估不同连接顺序的成本,优先选择数据量小、过滤效率高的执行路径。
统计信息的准确性对执行计划的质量起着决定性作用。如果存储引擎提供的统计数据存在偏差,优化器就有可能做出错误的决策。在实际的业务场景中,我们常常会发现优化器预估的筛选条件比例与真实数据之间存在显著差异,这种偏差会导致生成次优的查询计划,最终表现为查询性能的严重下降。
以下是 MySQL 示例数据库中针对不同 WHERE 条件的筛选比例预估结果:
mysql> explain select count(*) from employees where birth_date > '1955-01-01';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299423 | 33.33 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
mysql> explain select count(*) from employees where birth_date = '1955-01-01';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299423 | 10.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
以下是实际符合筛选条件的比例。对比可见,优化器对筛选条件的预估比例与实际数据存在显著偏差:
mysql> SELECT SUM(birth_date > '1955-01-01') AS filtered, COUNT(*) AS total, CONCAT(ROUND(SUM(birth_date > '1955-01-01') / COUNT(*) * 100, 2), '%') AS ratio FROM employees;
+----------+--------+--------+
| filtered | total | ratio |
+----------+--------+--------+
| 232658 | 300024 | 77.55% |
+----------+--------+--------+
1 row in set (0.10 sec)
mysql> SELECT SUM(birth_date = '1955-01-01') AS filtered, COUNT(*) AS total, CONCAT(ROUND(SUM(birth_date = '1955-01-01') / COUNT(*) * 100, 2), '%') AS ratio FROM employees;
+----------+--------+-------+
| filtered | total | ratio |
+----------+--------+-------+
| 72 | 300024 | 0.02% |
+----------+--------+-------+
1 row in set (0.10 sec)
在本篇博客中,我们将深入探讨 Aurora MySQL 环境下如何借助直方图,为查询优化器提供更精准的数据分布预估,并通过 TPC-DS 基准测试中的查询,直观展示其对查询性能的优化提升效果。
MySQL中的直方图
直方图原理
直方图(Histogram)在数据库优化领域用于描述数据分布的关键工具。它通过将列数据划分为若干连续区间(Bucket),统计每个区间内数据的出现频率,从而直观呈现数据的分布特征。相较于仅记录总行数、列基数等基础统计信息,直方图能精准捕捉数据的非均匀分布特性。例如,在分析电商订单金额时,基础统计信息可能掩盖低价订单占比极高的分布规律,而直方图可清晰展现数据集中趋势,帮助优化器更准确地预估查询谓词的选择性,避免因错误估算数据规模而生成低效的执行计划。
直方图存在多种类型,MySQL 选择支持两种不同类型:等宽直方图(singleton)和等高直方图(equi-height)。所有直方图类型的共同点是将数据集划分为一组 “桶”。 等宽直方图针对低基数列,为每个唯一值创建一个桶,直接记录该值的出现频率;等高直方图则适用于高基数列,将数据划分为数据量大致相等的区间桶,每个桶包含相近数量的记录。MySQL 会自动将值划分到各个桶中,并且能够根据列的基数、数据分布等特征,自动决定创建何种类型的直方图。这种自动划分和类型选择机制,使得直方图能更精准地反映数据分布情况,为优化器提供更可靠的统计信息,从而助力生成更高效的查询执行计划。
创建直方图
使用带有UPDATE HISTOGRAM子句的ANALYZE TABLE语句可为指定表的列生成直方图统计信息,并将其存储在数据字典中。可选的WITH N BUCKETS子句用于指定直方图的桶数量,其中 N 必须是 1 到 1024 之间的整数;若省略该子句,桶数量默认为 100。而带有DROP HISTOGRAM子句的ANALYZE TABLE语句则用于从数据字典中删除指定表列的直方图统计信息。
例如,为employees表的birth_date列创建直方图:
mysql> analyze table employees update histogram on birth_date with 32 buckets;
+---------------------+-----------+----------+-------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+---------------------+-----------+----------+-------------------------------------------------------+
| employees.employees | histogram | status | Histogram statistics created for column 'birth_date'. |
+---------------------+-----------+----------+-------------------------------------------------------+
1 row in set (1.21 sec)
直方图的存储
在 MySQL 中,直方图统计信息以 JSON 对象格式存储于数据字典,这种存储方式兼具灵活性与可读性。借助数据库内置的 JSON 函数,用户能够便捷地从直方图中提取所需信息。用户可直接从INFORMATION_SCHEMA.COLUMN_STATISTICS 视图查询直方图内容,该视图提供了访问列统计信息的标准化接口。通过查询该视图,不仅能了解直方图的类型、桶的数量,还能获取每个桶的具体数据范围和对应的频率分布,为分析数据分布特征、优化查询执行计划提供了直观且高效的途径。下面我们查询刚才创建的直方图的详细信息:
mysql> select JSON_PRETTY(HISTOGRAM) from INFORMATION_SCHEMA.COLUMN_STATISTICS where schema_name='employees' and table_name='employees' and column_name='birth_date';
……
{
"buckets": [
[
"1952-02-01",
"1952-06-26",
0.031076362944748605,
147
],
[
"1952-06-27",
"1952-11-23",
0.06230895678517573,
150
],
[
"1952-11-24",
"1953-04-21",
0.0936094771019848,
149
],
[
"1953-04-22",
"1953-09-16",
0.12484207094241194,
148
],
[
"1953-09-17",
"1954-02-14",
0.1560135309540953,
151
]
……
[
"1964-09-07",
"1965-02-01",
1.0,
148
]
],
"data-type": "date",
"null-values": 0.0,
"collation-id": 8,
"last-updated": "2025-06-20 03:03:24.331824",
"sampling-rate": 0.4911407057220447,
"histogram-type": "equi-height",
"number-of-buckets-specified": 32
}
可以看到MySQL在数据字典中存储了列的数据类型、更新时间、直方图的类型、桶的数量以及每个桶的范围和对应的数值占比。
直方图的效果
在示例数据表的birth_date字段创建直方图后,通过EXPLAIN工具对比分析优化器对两个查询条件的筛选度预估。可以看到,直方图创建后,优化器对符合条件的行数预估准确性显著提升。相较于创建前的显著偏差,新预估结果与实际数据分布的吻合度大幅提高。针对该列的数据分布特征调整直方图的桶数量,可进一步调整预估精度。
mysql> explain select count(*) from employees where birth_date > '1955-01-01';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299423 | 77.67 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
mysql> explain select count(*) from employees where birth_date = '1955-01-01';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299423 | 0.10 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
查询优化实践
Amazon Aurora 是专为云构建的一种兼容 MySQL 和 PostgreSQL 的关系数据库,它既具有传统企业数据库的性能和可用性,又具有开源数据库的精简性和成本效益。Amazon Aurora 的速度可达标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍。Amazon Aurora 由 Amazon Relational Database Service (RDS) 完全托管,Amazon RDS 可以自动执行各种耗时的管理任务。Amazon Aurora 采用分布式、有容错能力并且可以自我修复的存储系统,这一系统可以使每个数据库实例最高扩展到 256TB。它可实现高性能和高可用性,支持多达 15 个低延迟读取副本、时间点恢复、持续备份到 Amazon S3,以及跨三个可用区(AZ)复制。
我们此次使用Aurora MySQL 3.05.02 版本的 r7g.large 实例类型上,采用 scale factor 为 1 的 TPC-DS 数据集(整体数据库规模 1GB)进行测试。集群采用默认的参数组,该实例类型默认可用的buffer pool空间约8GB,此次测试中所有数据集驻留在 buffer pool 中。下面将通过 TPC-DS 中的两个查询,直观展示直方图对查询执行计划的优化影响。
Query 90
该查询为统计针对特定条件的客户上午与下午的销售的商品数量的比。
mysql> SELECT
CAST(amc AS DECIMAL(15,4))/CAST(pmc AS DECIMAL(15,4)) am_pm_ratio
-> CAST(amc AS DECIMAL(15,4))/CAST(pmc AS DECIMAL(15,4)) am_pm_ratio
-> FROM (
-> SELECT
-> COUNT(*) amc
-> FROM
-> web_sales,
-> household_demographics,
-> time_dim,
-> web_page
-> WHERE
-> ws_sold_time_sk = time_dim.t_time_sk
-> AND ws_ship_hdemo_sk = household_demographics.hd_demo_sk
-> AND ws_web_page_sk = web_page.wp_web_page_sk
-> AND time_dim.t_hour BETWEEN 9 AND 9+1
-> AND household_demographics.hd_dep_count = 2
-> AND web_page.wp_char_count BETWEEN 5000 AND 5200
-> ) at, (
-> SELECT
-> COUNT(*) pmc
time_dim,
web_page
WHERE
ws_sold_time_sk = time_dim.t_time_sk
AND ws_ship_hdemo_sk = household_demographics.hd_demo_sk
AND ws_web_page_sk = web_page.wp_web_page_sk
AND time_dim.t_hour BETWEEN 15 AND 15+1
AND household_demographics.hd_dep_count = 2
AND web_page.wp_char_count BETWEEN 5000 AND 5200
) pt
ORDER BY
am_pm_ratio
LIMIT 100; -> FROM
-> web_sales,
-> household_demographics,
-> time_dim,
-> web_page
-> WHERE
-> ws_sold_time_sk = time_dim.t_time_sk
-> AND ws_ship_hdemo_sk = household_demographics.hd_demo_sk
-> AND ws_web_page_sk = web_page.wp_web_page_sk
-> AND time_dim.t_hour BETWEEN 15 AND 15+1
-> AND household_demographics.hd_dep_count = 2
-> AND web_page.wp_char_count BETWEEN 5000 AND 5200
-> ) pt
-> ORDER BY
-> am_pm_ratio
-> LIMIT 100;
+-------------+
| am_pm_ratio |
+-------------+
| 1.27619048 |
+-------------+
1 row in set (2.30 sec)
可以看到查询时间为2.3s。我们为web_page的wp_char_count字段创建直方图。
mysql> ANALYZE TABLE web_page UPDATE HISTOGRAM ON wp_char_count WITH 16 buckets;
+----------------+-----------+----------+----------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------------+-----------+----------+----------------------------------------------------------+
| tpcds.web_page | histogram | status | Histogram statistics created for column 'wp_char_count'. |
+----------------+-----------+----------+----------------------------------------------------------+
1 row in set (0.00 sec)
重新执行该查询。
mysql> SELECT ……
+-------------+
| am_pm_ratio |
+-------------+
| 1.27619048 |
+-------------+
1 row in set (0.63 sec)
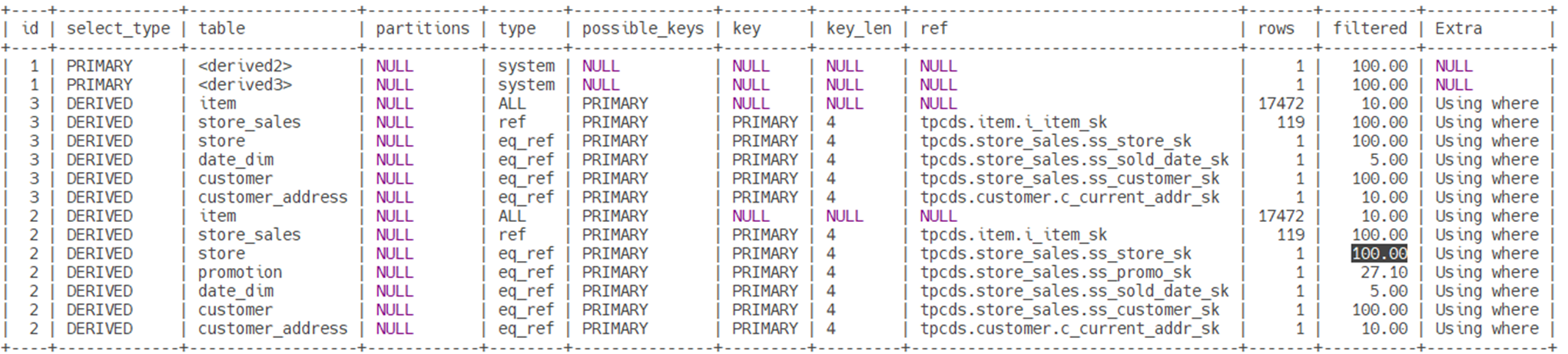
可以看到执行时间缩短至0.63。我们对比一下,创建直方图前后的执行计划。
在创建直方图后,web_page的筛选比例从11.11%到1.74%。我们通过表中实际的符合筛选条件的行的比例。
mysql> SELECT (SELECT COUNT(*) FROM web_page WHERE web_page.wp_char_count BETWEEN 5000 AND 5200)/(SELECT COUNT(*) FROM web_page) AS ratio;
+--------+
| ratio |
+--------+
| 0.0167 |
+--------+
通过结果可以看到创建直方图之后预估的比例与实际数据更接近。优化器根据更准确的统计信息,调整了join的顺序,提升了查询的效率。
Query 61
该查询特定时区特定品类的商品在给定月份中有促销和无促销商品销售比例。
mysql> SELECT
-> promotions,
total,
CAST(promotions AS DECIMAL(15,4)) / CAST(total AS DECIMAL(15,4)) * 100
FROM
(SELECT
-> total,
-> CAST(promotions AS DECIMAL(15,4)) / CAST(total AS DECIMAL(15,4)) * 100
date_dim,
customer,
customer_address,
-> FROM
-> (SELECT
WHERE
ss_sold_date_sk = d_date_sk
-> SUM(ss_ext_sales_price) promotions
-> FROM
AND ss_promo_sk = p_promo_sk
AND ss_customer_sk = c_customer_sk
-> store_sales,
AND ca_address_sk = c_current_addr_sk
AND ss_item_sk = i_item_sk
-> store,
AND ca_gmt_offset = -5
AND i_category = 'Sports'
-> promotion,
AND (p_channel_dmail = 'Y' OR p_channel_email = 'Y' OR p_channel_tv = 'Y')
AND s_gmt_offset = -5
-> date_dim,
AND d_year = 2002
-> customer,
AND d_moy = 11) promotional_sales,
(SELECT
SUM(ss_ext_sales_price) total
-> customer_address,
FROM
store_sales,
store,
-> item
date_dim,
-> WHERE
-> ss_sold_date_sk = d_date_sk
customer_address,
-> AND ss_store_sk = s_store_sk
ss_sold_date_sk = d_date_sk
AND ss_store_sk = s_store_sk
-> AND ss_promo_sk = p_promo_sk
AND ca_address_sk = c_current_addr_sk
AND ss_item_sk = i_item_sk
-> AND ss_customer_sk = c_customer_sk
-> AND ca_address_sk = c_current_addr_sk
AND s_gmt_offset = -5
-> AND ss_item_sk = i_item_sk
ORDER BY
promotions,
-> AND ca_gmt_offset = -5
-> AND i_category = 'Sports'
-> AND (p_channel_dmail = 'Y' OR p_channel_email = 'Y' OR p_channel_tv = 'Y')
-> AND s_gmt_offset = -5
-> AND d_year = 2002
-> AND d_moy = 11) promotional_sales,
-> (SELECT
-> SUM(ss_ext_sales_price) total
-> FROM
-> store_sales,
-> store,
-> date_dim,
-> customer,
-> customer_address,
-> item
-> WHERE
-> ss_sold_date_sk = d_date_sk
-> AND ss_store_sk = s_store_sk
-> AND ss_customer_sk = c_customer_sk
-> AND ca_address_sk = c_current_addr_sk
-> AND ss_item_sk = i_item_sk
-> AND ca_gmt_offset = -5
-> AND i_category = 'Sports'
-> AND s_gmt_offset = -5
-> AND d_year = 2002
-> AND d_moy = 11) all_sales
-> ORDER BY
-> promotions,
-> total
-> LIMIT 100;
+------------+------------+------------------------------------------------------------------------+
| promotions | total | CAST(promotions AS DECIMAL(15,4)) / CAST(total AS DECIMAL(15,4)) * 100 |
+------------+------------+------------------------------------------------------------------------+
| 3086783.26 | 6039385.41 | 51.11088381 |
+------------+------------+------------------------------------------------------------------------+
1 row in set (4.36 sec)
对store表内的时区字段增加直方图。
mysql> ANALYZE TABLE store UPDATE HISTOGRAM ON s_gmt_offset WITH 8 BUCKETS;
+-------------+-----------+----------+---------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+-------------+-----------+----------+---------------------------------------------------------+
| tpcds.store | histogram | status | Histogram statistics created for column 's_gmt_offset'. |
+-------------+-----------+----------+---------------------------------------------------------+
重新执行该查询,可以看到执行时间从4.36s降低到2.37s。
mysql> SELECT ……
+------------+------------+------------------------------------------------------------------------+
| promotions | total | CAST(promotions AS DECIMAL(15,4)) / CAST(total AS DECIMAL(15,4)) * 100 |
+------------+------------+------------------------------------------------------------------------+
| 3086783.26 | 6039385.41 | 51.11088381 |
+------------+------------+------------------------------------------------------------------------+
1 row in set (2.37 sec)
我们对比一下,创建直方图前后的执行计划。
store表的预估筛选比例从10%变为100%,这是因为测试数据内的store表内的时区全部符合筛选条件。根据统计信息,优化器调整了jion的顺序,对store表的访问方式也从表扫描调整为索引查找。新的查询计划效率更高,执行时间更短。
通过以上查询示例可以发现,Aurora MySQL的直方图特性(与社区版一致)通过统计列值分布信息,帮助优化器更精准评估数据选择性,从而生成更优的执行计划。尤其在处理低选择性列、范围查询或数据倾斜时,直方图能避免全表扫描或低效索引选择,显著提升复杂查询性能。
注意事项
在 Aurora MySQL 中使用直方图优化查询,需确保参数optimizer_switch中的condition_fanout_filter选项已开启。该选项在 Aurora 默认参数组中通常为启用状态(值为on)。若需关闭直方图功能,可使用ANALYZE TABLE table_name DROP HISTOGRAM ON column_name在表级别关闭或者通过修改参数组禁用condition_fanout_filter在集群级别关闭。
参数histogram_generation_max_mem_size控制生成直方图时的最大内存使用量,默认为20000000 字节(约 19MB)。数据库在创建或更新直方图时,会将表数据页读入内存并排序。对于超大型表,可通过调整该参数控制采样数据量。实际采样率与表的最大行长度相关,可通过查询INFORMATION_SCHEMA.COLUMN_STATISTICS视图的HISTOGRAM->’$.sampling-rate’获取具体数值。议根据实例内存配置和采样精度需求调整该参数,提升直方图生成效率。
与索引不同,直方图不会随数据变更自动更新,无需实时维护的特性避免了写入操作的额外开销。在大量数据插入、删除或更新操作后,需手动执行ANALYZE TABLE table_name UPDATE HISTOGRAM ON column_name。
直方图功能是 MySQL 8.0及后续版本引入的特性,在 Aurora MySQL 环境中,该功能对应支持于 Aurora MySQL 版本 3 及 Aurora Serverless v2。需要注意的是,当前 Aurora MySQL 版本 2 已进入扩展支持阶段,除常规的数据库集群运行费用外,还会按每 VPC 小时额外收取扩展支持费用。建议用户及时升级至 Aurora MySQL 版本 3,不仅能使用直方图等最新数据库特性,还能避免产生扩展支持费用。
参考资料:
Histogram statistics in MySQL
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |