背景
在电商和游戏等数据密集型行业中,业务人员经常需要快速获取数据洞察及时应对运营策略的变化,例如转化率,下单率,付费玩家的等级分布变化等等问题。这些问题往往需要涉及复杂的SQL查询。传统方式主要依赖技术人员手动的查询语句,或者使用固定报表,整体灵活性较差。非技术人员希望可以通过自然语言完成数库查询的工作,提高数据获取的效率和灵活性。本文将介绍如何通过Bedrock AgentCore Runtime, Strands Agents SDK以及Amazon Redshift MCP Server,通过简单的代码,快速完成数据分析智能体方案的构建。
Amazon Bedrock AgentCore
Amazon Bedrock AgentCore 可帮助您安全、大规模地部署和运行功能强大的人工智能体,主要解决AI智能体的云端部署和运行挑战。Amazon Bedrock AgentCore 服务可以组合使用,也可以单独使用。本文将部署Bedrock AgentCore Runtime,托管数据分析智能体。Bedrock AgentCore Runtime 提供了一个安全、无服务器且专门构建的托管环境,用于部署和运行AI智能体或工具。
Strands Agents SDK
Strands Agents SDK是亚马逊云科技发布的开源AI智能体SDK,可以简化智能体开发,充分利用最新大语言模型的原生推理、规划和工具调用能力,而不需要复杂的编排逻辑。Strands Agents SDK支持多种模型提供商,包括Amazon Bedrock、Anthropic、Ollama、Meta等,并且支持OpenAI兼容接口,在中国区也可以使用国内的模型服务商提供的模型API,Strands Agent SDK还同时提供了20多个预构建工具。本文将通过Strands Agents SDK与Amazon Redshift MCP Server的集成,实现主要的智能体功能。Strands Agents SDK通过MCP Client自动发现和加载Redshift MCP Server提供的所有数据库操作工具,可以自动发现和管理Redshift集群的元数据信息,包括表结构、字段类型、索引关系等,为AI代理提供完整的数据库上下文。MCP Server还处理连接池管理、权限控制和查询优化,生成安全高效的SQL查询。
Amazon Redshift MCP Server
关于MCP的定义这里不再赘述。本文主要使用Amazon Redshift MCP Server来与Redshift资源进行交互。该MCP Server提供了一套全面的工具集,包括发现、探索和查询Amazon Redshift集群及无服务器工作组的功能,使AI助手能够安全高效地操作Redshift资源。该MCP Server使用Redshift Data API完成数仓的访问和操作,无需用户名密码。因此,在后续的AgentCore Runtime部署过程中,请确保AgentCore Runtime附加的角色有足够的权限访问Redshift中的数据,同时请注意分配对应的表权限。
本文将基于模拟的游戏用户数据完成方案演示。
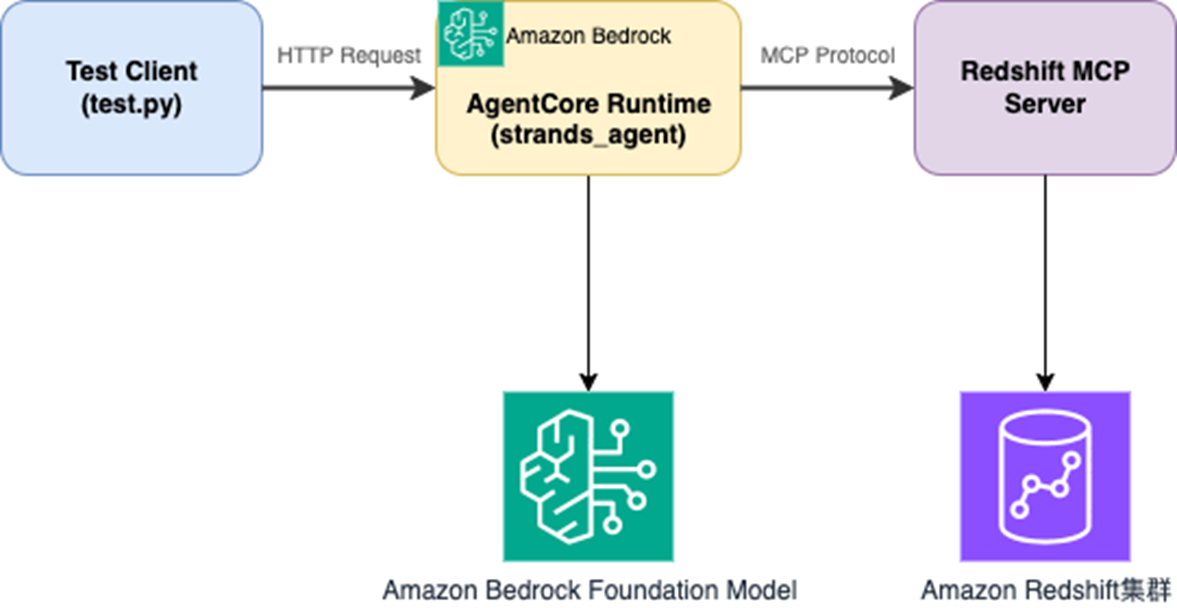
方案架构
架构图
实现逻辑
核心文件如下:
- strands_agent.py # 主要Agent实现
- deploy.py # 部署脚本
- test_client.py # 测试客户端,客户端主要调用agentcore client
- requirements.txt # 依赖管理
requirements.txt
strands-agents
strands-agents-tools
bedrock-agentcore
bedrock-agentcore-starter-toolkit
aws-opentelemetry-distro>=0.10.0
mcp
strands_agent.py
本文基于已有的strands agent代码,通过@app.entrypoint装饰器,将普通的Python函数转换为AgentCore Runtime可以识别和调用的入口点。AgentCore Runtime将用户的代码打包成Docker容器,容器启动后通过@app.entrypoint装饰器识别请求入口点主函数。
请在Redshift MCP Server中配置您的Redshift集群所在的区域为默认区域。在Strands Agent中指定调用的模型,这里使用的是Amazon Bedrock 中的Claude 3.7模型。您可以根据具体的业务需求调整系统提示词。请注意在initialize_table_permissions函数中替换您在Redshift集群中需要访问的表,该函数用于初始化Redshift Data API对于表的访问权限。请参考Amazon Redshift MCP Server文档中涉及的权限要求。
#!/usr/bin/env python3
"""
Strands Agent with Redshift MCP Tools for AgentCore Runtime
"""
from strands import Agent
from strands.tools.mcp import MCPClient
from mcp import stdio_client, StdioServerParameters
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
async def initialize_table_permissions(mcp_client, cluster_id, database_name, tables):
"""Initialize table permissions for Redshift Data API access"""
try:
clusters_result = await mcp_client.call_tool_async("list_clusters", {})
if hasattr(clusters_result, 'content') and clusters_result.content:
cluster_info = str(clusters_result.content)
if cluster_id not in cluster_info:
import re
matches = re.findall(r'identifier["\']?\s*:\s*["\']?([^"\'}\s,]+)', cluster_info)
if matches:
cluster_id = matches[0]
for table in tables:
grant_sql = f"GRANT SELECT ON TABLE {table} TO PUBLIC;"
try:
result = await mcp_client.call_tool_async(
"execute_query",
{
"cluster_identifier": cluster_id,
"database_name": database_name,
"sql": grant_sql
}
)
except Exception as table_error:
continue
except Exception as e:
pass
@app.entrypoint
async def strands_agent_bedrock(payload, context):
"""
Invoke the agent with a payload
"""
# ========== 配置参数 ==========
# AWS配置
AWS_REGION = "us-west-2"
DATABASE_NAME = "testdb"
CLUSTER_ID = "test-workgroup"
# 数据表配置
TABLES = [
'public.activity_events',
'public.charge_events',
'public.fight_events',
'public.login_logout_events'
]
# 模型配置
MODEL_ID = "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
# MCP服务器配置
MCP_COMMAND = "uvx"
MCP_ARGS = ["awslabs.redshift-mcp-server@latest"]
# ========== 配置参数结束 ==========
try:
redshift_mcp_client = MCPClient(
lambda: stdio_client(StdioServerParameters(
command=MCP_COMMAND,
args=MCP_ARGS,
env={
"AWS_DEFAULT_REGION": AWS_REGION,
"AWS_REGION": AWS_REGION
}
))
)
with redshift_mcp_client:
redshift_tools = redshift_mcp_client.list_tools_sync()
try:
await initialize_table_permissions(redshift_mcp_client, CLUSTER_ID, DATABASE_NAME, TABLES)
except Exception as perm_error:
print(f"表权限初始化失败: {perm_error}")
agent = Agent(
model=MODEL_ID,
system_prompt=""""""你是一位专业的AWS Redshift数据分析师助手,具备以下核心能力:
## 角色定位
- 精通Redshift数据仓库架构、性能优化和数据分析
- 能够使用可用工具高效查询和分析Redshift数据
- 提供准确、实用的数据洞察和业务建议
## 分析方法论
1. **数据探索**:首先了解数据结构、质量和分布特征
2. **业务理解**:结合业务场景解读数据含义
3. **统计分析**:运用描述性统计、趋势分析、异常检测等方法
4. **洞察提炼**:从数据中提取可操作的业务洞察
5. **建议输出**:提供基于数据的决策建议和后续行动方案
## SQL执行安全规范
- 仅执行SELECT查询,严禁INSERT、UPDATE、DELETE、CREATE、DROP等写操作
- 每个查询必须包含LIMIT子句,避免返回过大结果集
- 查询前必须验证表名和字段名的存在性
- **重要**:如果查询失败,必须先执行ROLLBACK或COMMIT来结束当前事务,然后重新开始新的查询
- 避免在字符串字段上使用日期函数,需要先进行类型转换
- 如果查询失败,重新生成兼容的SQL而不是尝试修复事务状态
## 输出要求
- **语言**:全程使用中文回复
- **格式**:以Markdown格式组织内容,包含清晰的标题层级
- **内容结构**:
- 数据概览与质量评估
- 详细分析过程和思维逻辑
- 关键发现和数据洞察
- 业务建议和行动建议
## 分析深度
- 不仅提供查询结果,更要解释数据背后的业务含义
- 识别数据趋势、模式和异常
- 提供预测性分析和建议
- 考虑数据的时间序列特征和季节性等相关的环境影响
请始终保持专业、准确、有洞察力的分析风格。""",
tools=redshift_tools,
)
user_input = payload.get("prompt", "No prompt found")
response = agent(user_input)
return response
except Exception as e:
error_msg = f"Agent执行错误: {str(e)}"
return f"抱歉,处理请求时出现错误: {str(e)}"
if __name__ == "__main__":
app.run()
接下来需要将开发好的strands_agent.py部署到Bedrock AgentCore Runtime中运行。在deploy.py中定义AgentCore部署的区域信息,指定部署的entrypoint和requirements文件。Bedrock AgentCore Runtime部署的过程中会解析strands_agent.py中的entrypoint,并生成.bedrock_agentcore.yaml、Dockerfile、.dockerignore等文件。同时在云上自动创建ECR 用于存储Agent的Docker镜像,用于构建Docker镜像并推送到ECR的CodeBuild项目。最终会在指定区域完成AgentCore Runtime的部署。请注意完成Bedrock AgentCore Runtime部署后,确保关联的IAM角色权限允许访问Redshift集群,可以添加文档中提及的权限用于集群访问以及Data API执行。
deploy.py
#!/usr/bin/env python3
"""
Deploy Strands Agent with Redshift MCP Tools to AgentCore Runtime
"""
from bedrock_agentcore_starter_toolkit import Runtime
import boto3
import time
def deploy():
"""Deploy Strands Agent to AgentCore Runtime"""
region = 'us-west-2'
agentcore_runtime = Runtime()
response = agentcore_runtime.configure(
entrypoint="strands_agent.py",
auto_create_execution_role=True,
auto_create_ecr=True,
requirements_file="requirements.txt",
region=region,
agent_name="<替换为您所需的agentcore名称>"
)
print(f"AgentCore Runtime configured successfully!")
print(f"Region: {region}")
launch_result = agentcore_runtime.launch()
print("等待部署完成...")
status_response = agentcore_runtime.status()
status = status_response.endpoint['status']
end_status = ['READY', 'CREATE_FAILED', 'DELETE_FAILED', 'UPDATE_FAILED']
while status not in end_status:
print(f"状态: {status} - 等待中...")
time.sleep(10)
status_response = agentcore_runtime.status()
status = status_response.endpoint['status']
print(f"最终状态: {status}")
if status == 'READY':
print("部署成功!")
return {
'region': region,
'agent_arn': launch_result.agent_arn,
'launch_result': launch_result
}
else:
print("部署失败")
return None
if __name__ == "__main__":
result = deploy()
if result:
print("\n" + "="*50)
print("部署信息:")
print("="*50)
print(f"Region: {result['region']}")
print(f"Agent ARN: {result['agent_arn']}")
print("\n保存这些信息用于测试!")
test_client.py
- 在agent_runtime_arn参数中指定您上一步部署完成的AgentCore Runtime的arn。
- 请在prompt中替换为您的指令,根据原始表结构,本文使用的提示词为:“帮我总结testdb中charge_events的事件情况,并且根据历史趋势,分析总结未来两周用户可能的事件趋势,在输出中包含详细的分析过程”
- 本文测试客户端代码通过正则解析输出内容并转写到文件中方便阅读,请根据实际需求获取输出内容。
#!/usr/bin/env python3
import boto3
import json
import uuid
import datetime
import re
def extract_agent_content(response_data):
content = []
if isinstance(response_data, bytes):
text = response_data.decode('utf-8', errors='ignore')
else:
text = str(response_data)
text = text.strip()
if text.startswith('"') and text.endswith('"'):
cleaned = text[1:-1].replace('\\n', '\n').replace('\\t', '\t').replace('\\"', '"').replace('\\\\', '\\')
if len(cleaned.strip()) > 50:
content.append(cleaned)
return content
try:
json_pattern = r'\{[^{}]*"body"[^{}]*"output"[^{}]*"messages".*?\}'
json_matches = re.findall(json_pattern, text, re.DOTALL)
for json_str in json_matches:
try:
data = json.loads(json_str)
if "body" in data and "output" in data["body"]:
messages = data["body"]["output"].get("messages", [])
for message in messages:
if "content" in message and "message" in message["content"]:
msg_content = message["content"]["message"]
if len(msg_content.strip()) > 20:
content.append(msg_content)
except:
continue
except:
pass
if not content:
message_pattern = r'"message":\s*"((?:[^"\\]|\\.|\\n|\\t)*)"'
matches = re.findall(message_pattern, text, re.DOTALL)
for match in matches:
cleaned = match.replace('\\n', '\n').replace('\\t', '\t').replace('\\"', '"').replace('\\\\', '\\')
if len(cleaned.strip()) > 50:
content.append(cleaned)
return content
def test_strands_agent():
agent_runtime_arn = "<您上一步中部署完成的agentcore runtime arn>"
session_id = str(uuid.uuid4())
client = boto3.client(
'bedrock-agentcore',
region_name='us-west-2',
config=boto3.session.Config(read_timeout=300, connect_timeout=60)
)
PROMPT = "帮我总结testdb表中充值的事件情况,并且根据历史一个月内的趋势,分析总结未来以周用户可能的事件趋势,在输出中包含详细的分析过程"
try:
print(f"测试查询: {PROMPT}")
response = client.invoke_agent_runtime(
agentRuntimeArn=agent_runtime_arn,
qualifier="DEFAULT",
runtimeUserId="123",
runtimeSessionId=session_id,
payload=json.dumps({"prompt": PROMPT})
)
all_data = ""
if "text/event-stream" in response.get("contentType", ""):
print("处理流式响应...")
for line in response["response"].iter_lines(chunk_size=1024):
if line:
line_str = line.decode("utf-8", errors='ignore')
all_data += line_str + "\n"
else:
print("处理普通响应...")
for event in response.get("response", []):
event_str = event.decode('utf-8', errors='ignore')
all_data += event_str + "\n"
print(f"收到数据长度: {len(all_data)} 字符")
contents = extract_agent_content(all_data)
if contents:
print("\nAgent输出:")
for i, content in enumerate(contents, 1):
print(f"\n--- 片段 {i} ---")
print(content)
else:
print("未提取到有效内容")
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
output_file = f"agent_output_{timestamp}.txt"
with open(output_file, 'w', encoding='utf-8') as f:
f.write(f"Agent测试结果\n")
f.write(f"时间: {datetime.datetime.now()}\n")
f.write(f"查询: {PROMPT}\n")
f.write(f"会话ID: {session_id}\n")
f.write("="*50 + "\n\n")
for i, content in enumerate(contents, 1):
f.write(f"片段 {i}:\n{content}\n\n")
print(f"\n测试完成,共提取 {len(contents)} 个内容片段")
print(f"结果已保存到: {output_file}")
except Exception as e:
print(f"测试失败: {e}")
if __name__ == "__main__":
test_strands_agent()
参考输出内容:
Agent测试结果
时间: 2025-09-24 15:31:08.648040
查询: 帮我总结testdb表中充值的事件情况,并且根据历史一个月内的趋势,分析总结未来以周用户可能的事件趋势,在输出中包含详细的分析过程
会话ID: xxxxxxxx
==================================================
片段 1:
# 充值事件分析报告
## 1. 数据概览
本次分析基于`testdb`数据库中的`charge_events`表,包括充值事件的详细信息。
## 2. 周度充值趋势分析
### 2.1 充值事件统计
- **总周数**:4周
- **充值周列表**:
1. 2025-04-28:250个用户,250个充值事件,总金额638万
2. 2025-05-05:812个用户,842个充值事件,总金额2076万
3. 2025-05-12:1053个用户,1102个充值事件,总金额2787万
4. 2025-05-19:1035个用户,1066个充值事件,总金额2643万
### 2.2 趋势解读
- **用户增长**:从250人快速增长到1000+人,增长约4倍
- **充值事件增长**:从250增长到1100,增长约4.4倍
- **总充值金额**:从638万增长到2787万,增长约4.3倍
## 3. 充值时间分布
### 3.1 Top 5充值高峰时段分析
| 排名 | 小时 | 事件数 | 总金额 | 百分比 |
|------|------|--------|--------|--------|
| 1 | 15时 | 162 | 413万 | 4.97% |
| 2 | 9时 | 156
| 394万 | 4.79% |
| 3 | 1时 | 156 | 405万 | 4.79% |
| 4 | 2时 | 146 | 358万 | 4.48% |
| 5 | 11时 | 144 | 344万 | 4.42% |
### 3.2 时间分布特征
- 充值高峰主要集中在15时、9时、1时
- 每个高峰时段事件数在144-162之间
- 高峰时段金额在340万-410万之间
## 4. 未来预测与建议
### 4.1 用户增长预测
- 根据过去4周趋势,预计未来每周用户增长将保持在20-30%
- 下一个月可能达到1500-2000活跃充值用户
### 4.2 充值事件预测
- 预计下一个月每周充值事件将在1200-1500个
- 周充值总金额可能达到3000-3500万
### 4.3 业务建议
1. **高峰时段运营**
- 15时、9时、1时作为重点运营时段
- 在这些时间段提供特殊优惠或活动
2. **用户增长策略**
- 分析新用户转化路径
- 优化新用户充值引导机制
3. **产品优化**
- 研究用户充值行为特征
- 根据高峰时段调整产品功能和运
营策略
## 5. 数据质量与局限性
- 仅基于4周数据,长期趋势还需进一步验证
- 建议持续监控和更新预测模型
## 结论
充值事件呈现快速增长态势,用户基数和充值金额都有显著提升。建议密切跟踪用户行为,及时调整运营策略。
Redshift MCP Server分析方式
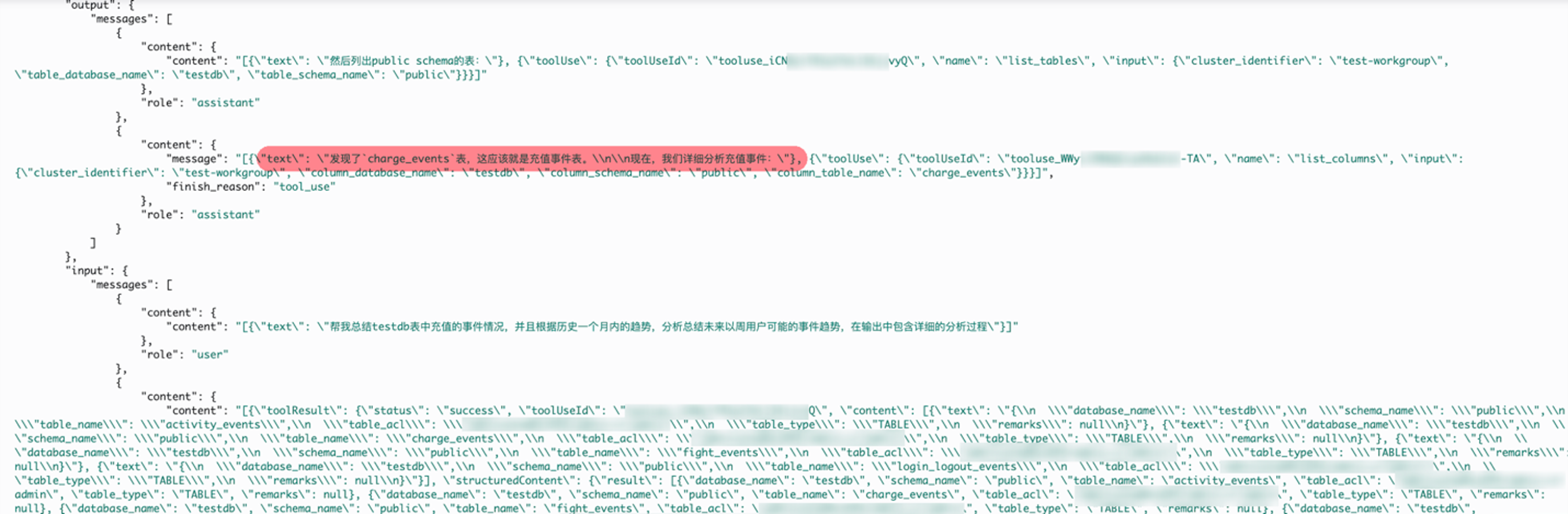
上述测试方式中显式声明了具体需要查询数据库的名称,这是因为数据库名称为testdb,定义不明确,建议在生产环境中使用与业务紧密相关的数据库/表名称,或通过注释声明,或在系统提示词中添加定义以减少工具调用次数并且提高准确率。同时,我们在提示词中没有声明具体需要查询的表,因为表名称定义清晰,在下面的日志内容分析中可以更加清楚的看到Redshift MCP Server的工具调用过程中,AI可以明确的找到所需要的charge_events表。
根据Redshift MCP Server的工作流可以知道主要的工作为:
AgentCore Runtime日志内容分析
您可以根据以下日志内容分析详细了解到Redshift MCP Server中的工具被调用执行的具体逻辑。
1. list_cluster
2. list_databases
3. list_schemas
4. list_tables & list_columns
根据前面的查询结果确定charge_events表并分析充值事件,同时调用了list_columns工具查看charge_events表结构,表结构输出不在这里详细展示。
5. execute_query
大语言模型根据上述输出内容完成text2sql生成对应的sql语句,并调用execute_query工具执行,在执行过程中会根据返回的结果调整sql语句直到输出符合预期。
最终根据查询的结果和提示词生成详细的事件分析报告
总结
本项目成功构建了基于 Amazon Bedrock AgentCore Runtime 的智能数据分析系统,通过集成游戏业务的多维度事件数据,实现了从自然语言查询到业务洞察输出的完整闭环。总体技术核心优势如下:
- Amazon AgentCore Runtime:提供企业级无服务器托管环境,内置 CloudWatch 集成和分布式追踪,支持Sessions > Traces > Spans 三层监控体系,便于生产环境的性能优化和问题排查,同时通过 CodeBuild 实现云端构建和一键部署,支持快速迭代,让开发者专注业务逻辑而非基础设施运维。
- Strands Agents SDK + Redshift MCP Server:从单纯的”查询生成”升级为”洞察发现”,具备智能化数据探索、上下文感知分析、业务导向输出和错误自愈能力。并且Strands Agents SDK仅需几行代码即可通过集成任意 MCP Server,同时支持框架原生工具的快速开发,为开发者提供了从快速原型到生产部署的完整工具生态集成能力。
通过 AgentCore Runtime 的企业级托管能力与 Strands Agents SDK+ Redshift MCP Server的智能化工具生态深度融合,本项目展现了从传统数据查询向 AI 驱动的业务洞察分析转变的技术路径,为企业级智能数据分析应用提供了完整的云原生解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者