亚马逊AWS官方博客
从X86到AWS Graviton4:合合信息图像识别应用的性能突破之旅
摘要
本文分享了合合信息将其图像识别应用从x86架构迁移到AWS Graviton ARM架构完整实践过程。通过精心的规划和实施,该项目不仅实现了3倍的性能提升,还在业务量翻倍的情况下将实例数量减少了61%,每台实例处理能力提升至之前的491%,整体成本下降为之前的30.1% 显著优化了总拥有成本(TCO)。
一、项目背景:计算密集型应用的成本挑战
1.1系统现状
合合信息为全球数亿用户及众多行业的企业客户提供服务,专注于多模态大模型文本智能技术,高质量数据建设等核心技术,这些都是典型的计算密集型应用。随着业务量的快速增长,原有的 C5 实例集群在应对高峰期请求时,面临着三大挑战:
- 高计算需求:图像识别算法需要大量CPU资源进行特征提取和模型推理
- 性能扩展瓶颈:在业务高峰期,需要启动大量的 C5 实例才能满足海量的并发请求,这不仅导致了资源管理的复杂性增加,也带来了潜在的性能抖动。
- 成本压力:庞大的实例数量直接导致了高昂的计算成本,如何在保证服务质量的前提下,有效控制成本,是合合信息持续关注的重点。
1.2迁移前的架构
- 实例配置:近百台EC2 C5实例组成的业务集群
- 处理能力:集群每秒计处理500 MB图片处理请求
- 平均负载:每台实例需要大量CPU资源处理56 MB/s的图像信息,峰值CPU使用率达到90%
- 主要痛点:实例数量多、管理复杂、成本高昂
二、前期规划:技术与商业价值的双重考量
2025年亚马逊云科技Graviton4实例在中国区发布,对比原X86架构的虚拟机提供了更高性价比。在性能的提升同时还能实现成本优化,无疑将为企业带来更大的价值。合合信息对这几款实例的成本效益进行分析:
- 测试目标:对比 x86 架构与不同代际 Graviton 处理器的 CPU 性能。
- 测试区域:cn-northwest-1 (中国 – 宁夏区域)
- 测试工具:本次测试采用质数计算作为基准测试工具,该测试在计算密集型任务上具有很高的代表性,等效于 sysbench cpu –cpu-max-prime=20000 –threads=4 命令。
- 测试环境:所有实例均使用 Amazon Linux 2 操作系统,并统一配置4个线程,以充分利用所有 vCPU 资源。
2.1 Graviton 与x86的性能对比
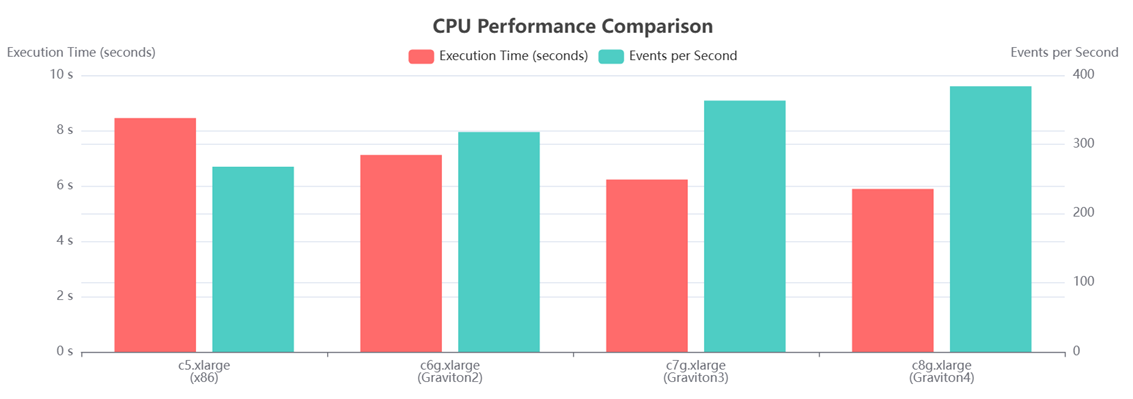 |
| 实例类型 | CPU架构 | 执行时间 (秒) | 每秒事件数 | 性能比较(相较于 c5.xlarge) | |
| 1 | c5.xlarge | X86 | 8.45 | 267.7 | Baseline (100%) |
| 2 | c6g.xlarge | Graviton2 | 7.12 | 317.7 | +18.7% faster |
| 3 | c7g.xlarge | Graviton3 | 6.23 | 363.1 | +35.6% faster |
| 4 | c8g.xlarge | Graviton4 | 5.89 | 384 | +43.5% faster |
从上图的“成本比较”可以看出,所有C6g、C7g、C8g Graviton 实例的性能都高于C5 X86实例。
2.2 性能价格比 (Performance/Price Ratio)
为了更全面地衡量实例的价值,我们引入“性能价格比”这一指标(每秒事物数/按需价格),即每花费一元人民币所能获得的性能。
| 实例类型 | 按需价格 (CNY/小时) | 成本节约 (相较于 c5.xlarge) | 每秒事件数 | 性能价格比 | 性能价格比提升 | |
| 1 | c5.xlarge | CNY 0.986 | 基准 | 267.7 | 271.4 | – |
| 2 | c6g.xlarge | CNY 0.783 | 20.60% | 317.7 | 405.6 | 49.40% |
| 3 | c7g.xlarge | CNY 0.783 | 20.60% | 363.1 | 463.7 | 70.80% |
| 4 | c8g.xlarge | CNY 0.783 | 20.60% | 384 | 490.3 | 80.60% |
从上表性价比的比较中可以看出:
- C8g 的价值最大化:xlarge 展现了最高的性能价格比,其性价比高出 C5.xlarge 80.6%,这意味着用户每花费一分钱,都能从 C8g 实例上获得最多的计算性能。
- Graviton 实例的普遍成本优势:对比X86实例所有 Graviton 实例均提供了约 20% 的成本节约,同时性能却远超 x86 实例。这使得迁移到 Graviton 成为一项极具吸引力的成本优化策略。
2.3 测试结果总结:
- Graviton4 性能领跑:xlarge (Graviton4) 实例以 5.89 秒的执行时间拔得头筹,相较于基准的 C5.xlarge (x86) 实例,性能提升了 43.5%。这充分证明了 Graviton4 处理器在纯计算能力上的巨大优势。每一代 Graviton 处理器都带来了显著的性能提升。C6g 相较于 C5 提升 18.7%,C7g 提升 35.6%,而 C8g 则达到了 43.5% 的提升,显示了 AWS 在自研芯片上持续且成功的投入。
- C8g 的价值最大化:在测试中xlarge 都展现了最高的性价比,其性价比高出 C5.xlarge 80.6%;这意味着每花费一分钱都能从 C8g 实例上获得最多的计算性能。
- 在使用sysbench进行初步后,通过真实业务场景继续进行了相关功能与性能测试,得出对EC2虚拟机更有价值的参数数据。
三、中期实施:代码适配与问题攻坚
3.1实施过程
被迁移程序主要通过Lua/C语言实现,应用从x86迁移到ARM64架构需要对原C语言库进行重新编译和优化,整个过程包括以下八项目工作:
1)准备 Graviton 环境
- 启动 Graviton EC2 实例(如xlarge)
- 安装编译工具链和 Lua 环境
2)扫描 C 库依赖
- 列出所有 Lua应用调用所有C库模块
- 识别需要重新编译的C扩展模块
- 检查是否使用X86特定SIMD 指令(SSE/AVX)
3)编译选项优化
- 更新 Makefile,添加 Arm64 优化参数
- 编译时启用-02或-03优化级别
4)重新编译 C 库
5)更新容器镜像(Dockerfile)
6)更新CI/CD 多架构支持
7)测试和性能评估
8)生产环境灰度发布
3.2 问题解决
在项目实施中整体比较顺利,但在测试过程中遇到以下两个问题,迁移团队进行分析与解决:
问题1:字符集兼容性问题
- 问题说明:
迁移到 Graviton 后测试过程中发现在x86下的部分代码输出出现了乱码问题:经过分析其原因是X86 通常是 UTF-16BE(Big Endian)格式,而现代 ARM(包括 Graviton)通常是UTF-16LE格式,存在字节序(Endianness)差异:
-
- UTF-16BE(Big Endian):高位字节在前,例如:字符 “A” (U+0041) 存储为 00 41
- UTF-16LE(Little Endian):低位字节在前,例如:字符 “A” (U+0041) 存储为 41 00
X86 和 ARM 架构的字节序差异导致 UTF-16 数据解析错误。
- 解决策略:
确认原因后,通过在 Lua 代码中明确指定字符编码转换 set_iconv $d $s from=utf-16be to=utf-8,确保正确处理 Big Endian 格式的 UTF-16 数据,问题得到解决。
问题2:迁移后发生Coredump问题
- 问题说明:
迁移到 Graviton 后测试发现在x86下的部分可以运行的代码在Graviton中出现Coredump问题:分析原因发现原有程序在x86下运行有时会出现可以忽略的报错,而Graviton环境无法忽略产生Coredump。
深入研究后其触发是因为,ARM 架构对内存访问的对齐要求比 x86 更严格。x86 处理器允许未对齐的内存访问(如从奇数地址读取 4 字节整数),仅产生性能损失。而 ARM 遇到未对齐访问会触发 SIGBUS 信号导致程序崩溃。此外,ARM 对某些未定义行为(如空指针解引用、数组越界)的检测更敏感,在 x86 上可运行的代码,在 Graviton 上会直接出现 Coredump。
- 解决策略:
确认原因后针对该问题使用短期+长期的综合方案解决:
-
- 短期:在 C 代码中添加signal_handler信号处理,使用捕获信号防止崩溃,同时通过/proc/cpu/alignment 内核参数放宽内存对齐检查解决。
- 长期:在后续将检查 C 代码中的内存对齐问题进行最终解决。
四、后期部署:稳妥的灰度上线策略
测试完成后,为了确保切换过程中的业务稳定性和连续性,设计了三阶段的灰度发布方案。通过渐进式的策略有助于控制风险,发布过程的真实流量也分步验证了新架构的稳定性和性能表现。同时为保障灰度发布过程的万无一失,也建立了完善的监控与风险应对机制:
- 监控关键指标:实时追踪应用响应时间、错误率、系统资源利用率(CPU、内存)以及成本变化趋势。
- 风险控制措施:配置了基于关键指标的实时告警系统,并部署了自动回滚机制。一旦监控到异常,系统能够迅速将流量切回 x86 集群,确保问题得到快速遏制。
阶段一:小流量验证 (5% 流量)
- 部署 5 台 C8g 实例集群,切换少量线上生产流量。
- 核心任务:监控关键性能指标(应用响应时间、错误率、资源利用率),验证核心功能的完整性与正确性。
阶段二:扩大验证 (30% 流量)
- 生产集群逐步扩展至 15 台 C8g 实例。
- 核心任务:在新旧集群间进行性能数据对比分析,并收集小范围用户反馈,确保体验一致。
阶段三:全量切换 (100% 流量)
- 根据核心业务与性能数据,将所有 30+ 台 C8g 实例部署上线,此时已经可以承载原近百台的C5集群的业务流量。
- 平滑地将全部流量切换至新集群,并正式下线原有的 C5 实例。
- 核心任务:进入持续监控和长期优化阶段。
五、成果总结:超预期的性能突破
实际性能提升结果:满足同样的业务需求,升级前近百台C5虚拟机集群可处理500MB/秒的请求,峰值5.56MB/秒/台,升级后仅用30+台C8g 虚拟机集群就可处理1.15GB/秒的请求, 峰值32.86MB/秒/台 。
集群节点数容量变化:
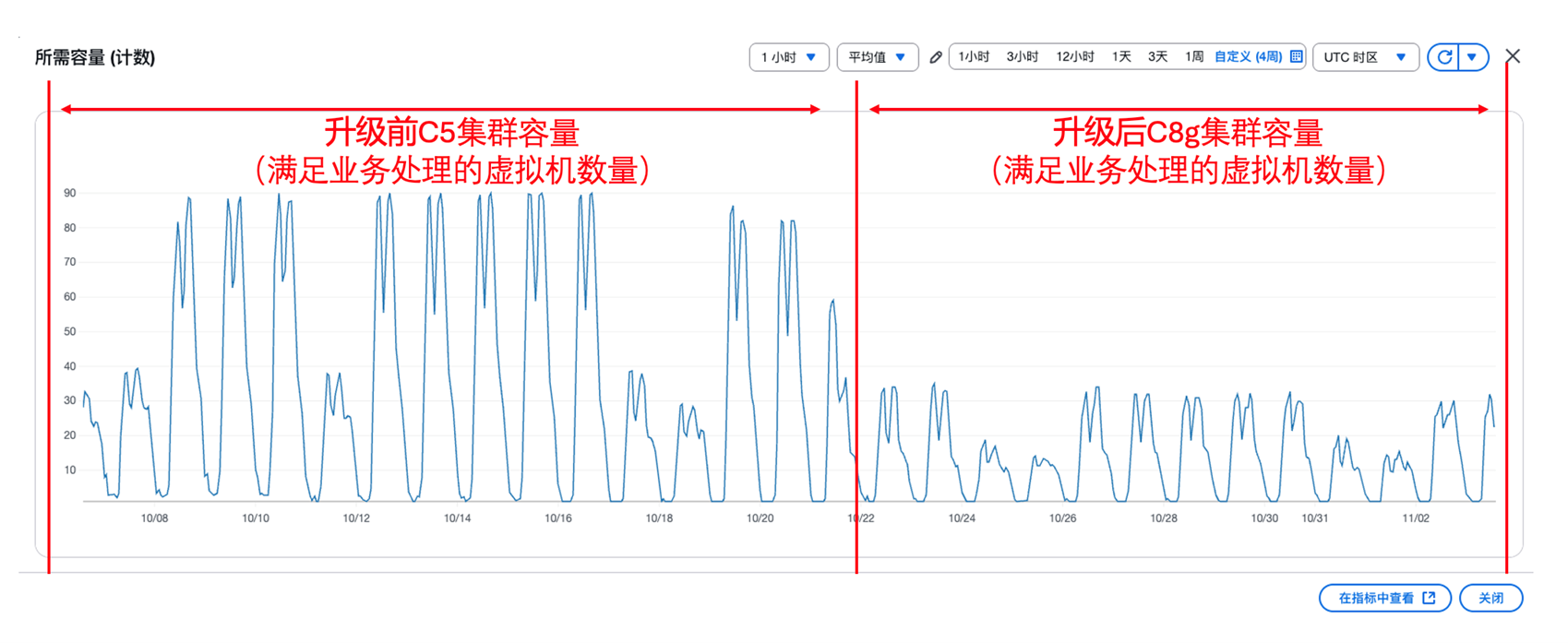 |
集群网络承载容量变化:
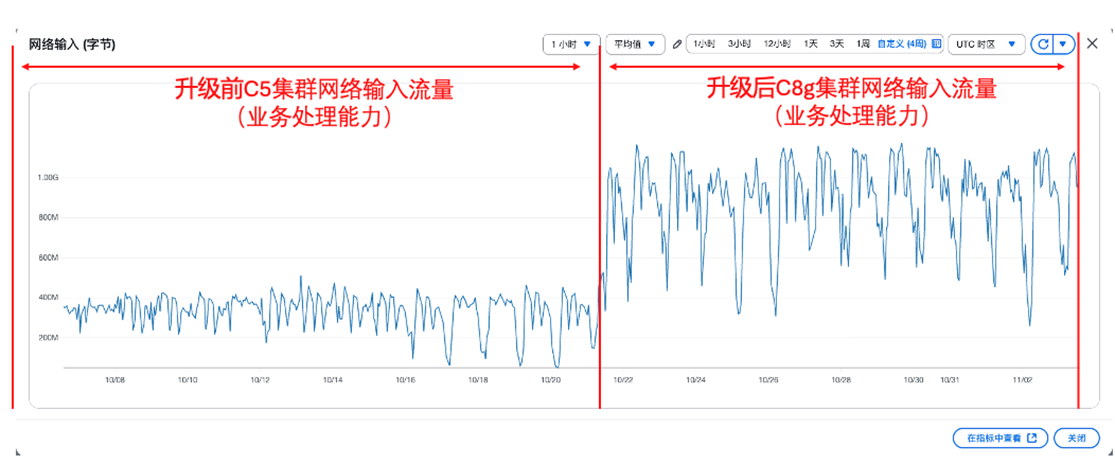 |
从 X86 到 AWS Graviton 的迁移,不仅是一次技术架构的升级,更是一次驱动业务向前发展的战略决策。通过精心的规划、严谨的实施和持续的优化,我们最终实现了 3 倍的性能提升、61% 的实例缩减和 491% 的单实例效率增长,同时显著优化了总体拥有成本。
这个案例有力地证明,合合信息拥抱像 AWS Graviton 这样的新兴 ARM 架构不仅在技术上完全可行,更能为企业带来超乎想象的商业回报,为数字化转型注入强劲的创新动力。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
