亚马逊AWS官方博客
申请试用 Amazon Aurora Limitless Database 预览版
今天,我们宣布推出 Amazon Aurora Limitless Database 预览版。这是一项支持自动横向扩展的新功能,可以每秒处理数百万个写入事务,并且可在单个 Aurora 数据库中管理数千万亿字节(PB 级)的数据。
您可以借助 Amazon Aurora 只读副本增加 Aurora 集群的读取容量,突破单个数据库实例的上限。而借助 Aurora Limitless Database 功能,您还可以扩展数据库的写入吞吐量和存储容量,使其超出单个 Aurora 写入器实例的上限。Limitless Database 使用的计算和存储容量将附加于并且独立于集群中写入器和读取器实例的容量。
通过使用 Limitless Database,您可以专注于构建大型应用程序,无需为了支持工作负载而构建和维护复杂的解决方案,来跨多个数据库实例扩展数据。Aurora Limitless Database 可根据工作负载的需要进行扩展,从而支持目前仍需要多个 Aurora 写入器实例才能满足的写入吞吐量和存储容量。
Amazon Aurora Limitless Database 的架构
Limitless Database 采用双层架构,由多个数据库节点(事务路由器或分片)组成。

分片属于 Aurora PostgreSQL 数据库实例,每个实例会存储数据库数据的一个子集,从而实现并行处理以提高写入吞吐量。事务路由器用于实现数据库的分布式性质,并向数据库客户端呈现统一的数据库映像。
事务路由器负责维护有关数据存储位置的元数据,解析传入的 SQL 命令并将这些命令发送到分片,汇总分片中的数据以将统一的结果返回到客户端,以及管理分布式事务以确保整个分布式数据库的一致性。构成 Limitless Database 架构的所有节点都包含在一个数据库分片组中。该数据库分片组拥有一个单独的端点,以方便访问您的 Limitless Database 资源。
Aurora Limitless Database 入门
要开始使用 Aurora Limitless Database 预览版,建议您立即注册,并且您很快就会受到邀请。此预览版将在版本 15 的新 Aurora PostgreSQL 集群中运行,目前已在 AWS 美国东部(俄亥俄州)、美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(东京)和欧洲地区(爱尔兰)区域开放。
在 Aurora 集群创建工作流中,只需在 Amazon RDS 控制台或 Amazon RDS API 中选择 Limitless Database 兼容版本,然后即可添加数据库分片组并创建新的 Limitless Database 表。您可以选择最大 Aurora 容量单位(ACU)。
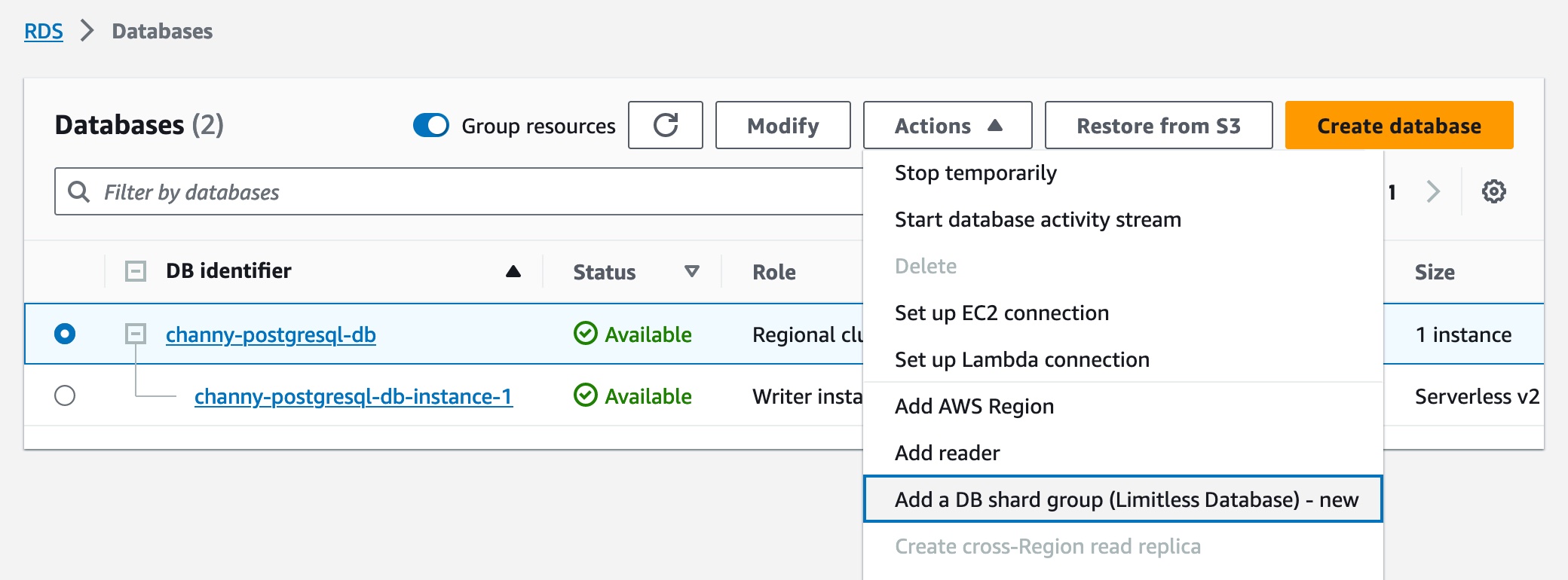
创建数据库分片组后,您可以在数据库页面上查看详细信息,包括其端点。
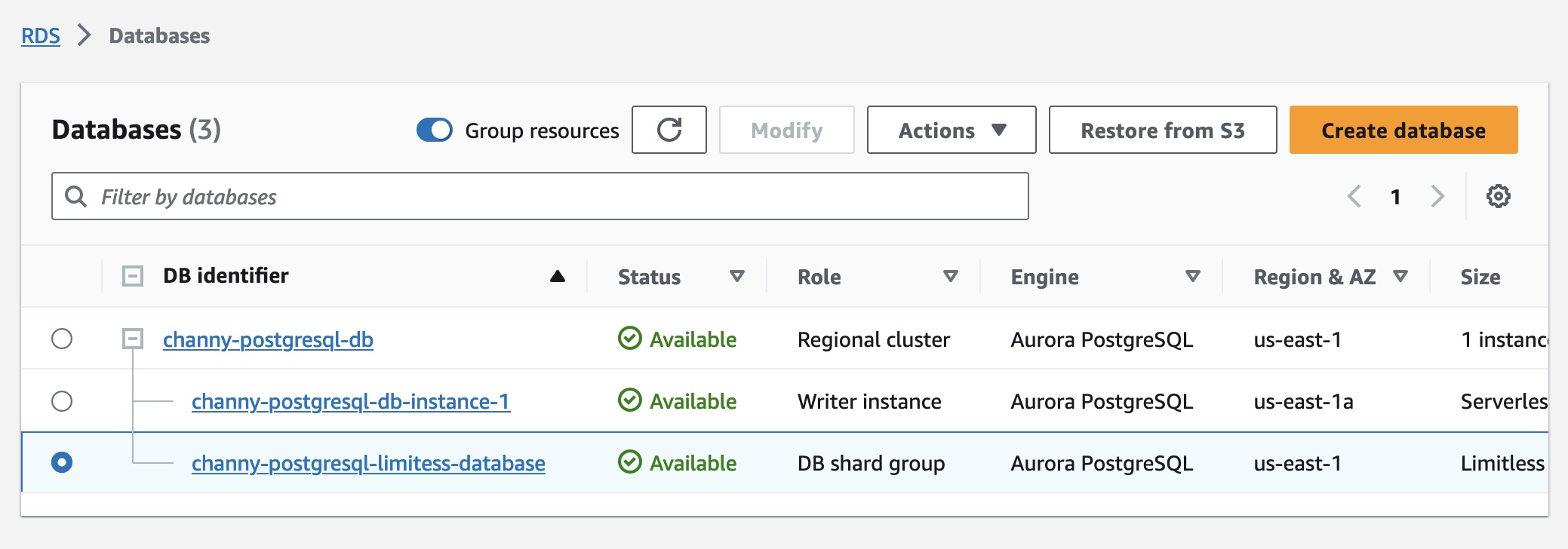
要使用 Aurora Limitless Database,您需要使用 psql 或任何其他支持 PostgreSQL 的连接实用程序,连接到数据库分片组端点,也称为无限端点。
Aurora Limitless Database 使用两种类型的表来包含您的数据:
- 分片表 – 此类表将跨多个分片分布。数据根据表中指定列的值(称为分片键)分布到不同的分片。
- 参考表 – 此类表中的所有数据都将在每个分片上呈现,从而通过消除不必要的数据移动,提高联接查询的运行速度。此类表通常用于不会频繁修改的参考数据,例如产品目录和邮政编码等。
创建分片表或参考表后,您可以将海量的数据加载到 Aurora Limitless Database 中,并使用标准 PostgreSQL 查询来操作这些表中的数据。
申请试用预览版
您可以申请试用 Amazon Aurora Limitless Database 预览版,抢先体验这些强大的功能。
立即注册并试用此新功能,如有反馈请发送给 AWS re:Post for Amazon Aurora 或您通常联系的 AWS Support 联系人。
– Channy