亚马逊AWS官方博客
Kubernetes 有状态服务跨云迁移到 Amazon EKS
背景
Kubernetes 和云原生技术在过去几年中经历了惊人的增长,企业采用 Kubernetes 的主要原因是它可以快速扩展,提高资源利用率,并且可迁移性优势明显。从本地部署 Kubernetes 向公有云托管 Kubernetes 环境迁移和跨云进行 Kubernetes 迁移的趋势正在加速,因为云上托管的 Kubernetes 服务的维护更加简单,可用性和可靠性更高。
有状态服务迁移的需求
Kubernetes 平台上运行的应用一般是无状态(Stateless)应用为主,但是有状态(Stateful)应用也不少见,各种数据库就是最常见的有状态应用,另外就是一些应用有数据持久化到磁盘的需求。而无状态应用则与有状态应用相对应,常见的无状态应用包括各种页面前端、Httpd、Nginx中间件等。
无状态服务在迁移的过程中一般使用 yaml 文件手工重新部署或利用 CICD 平台进行自动部署,不用过多考虑将原有 Kubernetes 平台上的应用数据恢复到新集群中。但是一些有持久化数据的服务在迁移时要将原有数据也迁移到新集群中,这些服务通常采用 Deployment+PVC 或 StatefulSet 的方式进行部署的,这时选择什么样的迁移方式显得很重要。对于类似数据库这样实时性要求高的,一般建议采用专业工具来进行在线迁移,如:Amazon DMS;如果是对实时性要求没有非常高要求的情况下,可以采用一些开源的数据迁移工具来进行,本文就是针对这种场景,推荐大家使用 Velero 这个工具协助大家迁移有持久化数据的服务。
什么是有状态服务
有状态应用(Stateful Application)通常是指有持久化存储需求的各种应用。有状态在 Kubernetes 中的定义是:StatefulSet 是用来管理有状态应用的工作负载 API 对象。StatefulSet 用来管理某些 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。
为什么有状态服务难迁移
有状态应用在容器平台迁移时面临一个问题:在应用需要数据不丢失的情况下,必须要能做到持久化数据与容器一同进行迁移,否则原有数据将会丢失或无法访问。另外从技术角度讲,在跨平台迁移时因为底层存储驱动大多不一样,导致无法直接将数据迁移到另外的平台。目前,通用迁移方案大多依赖于有状态服务自身提供的备份和恢复机制来实现,然而在迁移操作过程中存在需要人工参与、操作时间过长等问题。
迁移方案
-
- 架构图
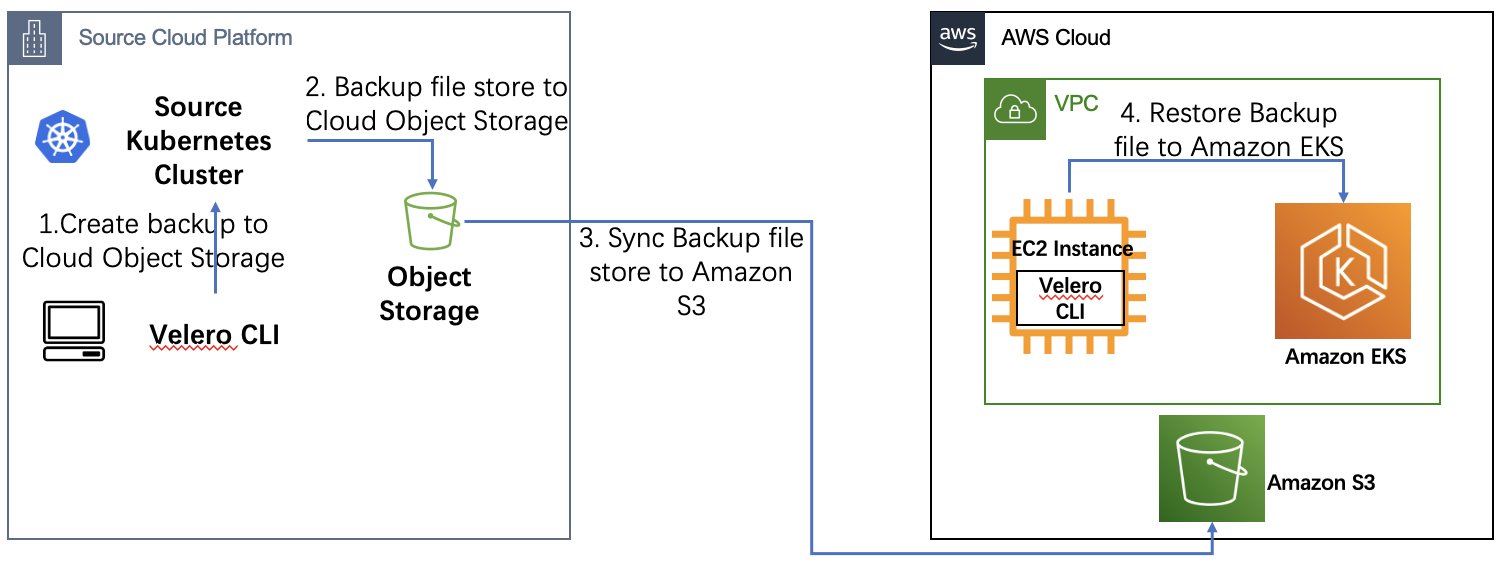 |
- 方案说明
- 在源 Kubernetes 集群所在云虚拟机上安装 Velero CLI
- 在源 Kubernetes 集群上安装并启动 Velero server
- 通过 Velero CLI 创建源 Kubernetes 集群上的有状态应用备份文件并存储到 Cloud Object Storage 中
- 使用命令行工具将 Cloud Object Storage 中的备份文件同步到 Amazon S3
- 在 Amazon EC2 上同样安装 Velero CLI
- 在 Amazon EKS 上安装并启动 Velero server
- 使用 Velero CLI 将 Amazon S3 桶中的备份文件恢复到 Amazon EKS 集群上
- Velero 工具说明
Velero(之前的版本叫做 Heptio Ark),一个开源工具,可以对 Kubernetes 集群进行安全备份和恢复,迁移 Kubernetes 集群资源和持久卷,对于应用部署类型,无论 Deployment 还是 StatefulSet 都可以支持。 在 Kubenetes 集群中部署 Velero,可以实现以下功能:- 备份集群资源,丢失时恢复
- 将集群资源迁移到其他集群
- 将生产集群资源复制到开发和测试集群
关于 Velero 的更多信息,请参见 Velero (https://velero.io/) 官方文档。
下图为 Velero 的工作流程图:
 |
- 迁移原理
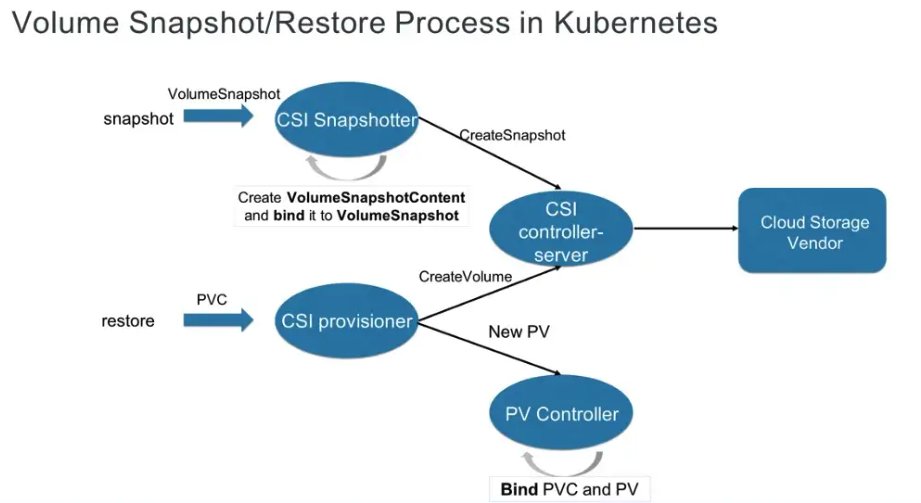
Velero 使用名为 restic 的免费开源备份工具备份和恢复 Kubernetes 卷。Velero 引入了三个CRD(Custom Resource Definitions)和关联的 Controllers。ResticRepository 用来管理 Velero 的 restic 存储库的生命周期,当请求备份时,Velero 会为每个 namespace 创建一个 restic 库,用于存储备份数据。PodVolumeBackup 用于 pod 中卷的静态备份,主 Velero 备份进程在找到带注释的 pod 时会为其创建备份,集群中的每个 node 上都会运行一个备份 controller 用来处理该节点上的 pod 的 PodVolumeBackup。PodVolumeRestore 是用于卷的静态恢复的 controller,Velero 执行 restic restore 命令来恢复 pod volume 数据。在跨云迁移 Kubernetes 集群中的有状态服务时,由于经常使用的 Kubernetes 源集群的 CSI(Cloud Storage Interface)不同于目标集群的 CSI,会导致无法直接使用 Snapshot 来进行备份、恢复,这是在跨云迁移时的一个难题(不同云平台之间的CSI Driver并不相同)。所以使用 Snapshot 并不能完成有状态服务的迁移,在这里我们使用 Velero 的 File System Backup 功能来实现。Velero 不支持容器中 hostpath 的备份,所以请注意 Velero 支持的场景和功能是否满足需求。如果在迁移需求中需要进行增量数据迁移,此时建议使用应用自带的迁移方法,如可使用 Amazon DMS 去满足数据库的全量+增量数据迁移。
下面是备份恢复过程中的相关概念:
-
-
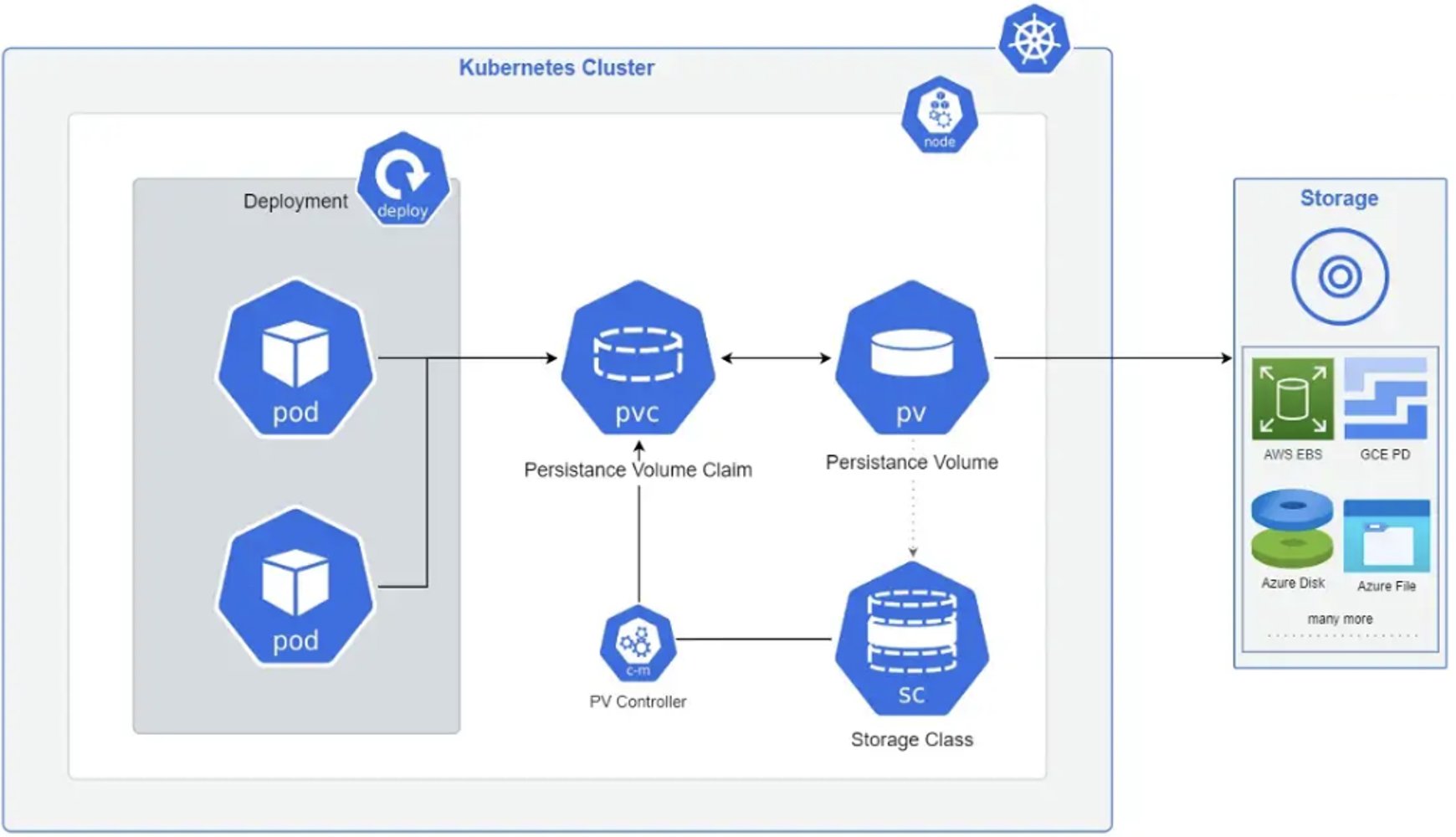
- Kubernetes Volume

Container 中的文件在磁盘上是临时存放的,这给 Container 中运行的较重要的应用程序带来一些问题。 问题之一是当容器崩溃时文件丢失。第二个问题是在同一 Pod 中运行多个容器并共享文件时,如果 kubelet 重新启动容器,但容器会以干净的状态重启,此时无法共享数据。 Kubernetes 卷(Volume) 这一抽象概念能够解决这两个问题。
-
- Snapshot
在 Kubernetes 中,VolumeSnapshot 表示存储系统上卷的快照。
-
-

-
- File System Backup

-
- Velero 支持从卷的文件系统备份和恢复附加到 Pod 的 Kubernetes 卷,称为文件系统备份(简称 FSB)或 Pod 卷备份。

迁移过程 Demo
环境部署
- 前提要求
- 具有某公有云(源)和 AWS(目标)的账号
- 具有源和目标公有云的对象存储服务权限,这里我们使用 GCP Cloud Storage 和 Amazon S3
- 具有两个(源和目标)Kubernetes 集群,版本要求 1.16 以上,在这里我们使用 GCP GKE 和 Amazon EKS 为例
- 两个 Kubernetes 集群都要安装 Velero,后面介绍具体的安装过程
- 在 GCP 环境中部署 Velero CLI 并安装启动 Velero
-
- 创建 GCS Bucket
BUCKET=
gsutil mb gs://$BUCKET/
-
- 为 Velero 创建 Service Account
注意:在 GCP 平台为 Velero 赋权有两种方式:第一种为 Service Account Key;第二种为 Workload Identity。在本文中我们使用第一种方式,如果需要第二种请参考上面的链接中的内容。
#查看当前的配置
gcloud config list
#设置PROJECT_ID
PROJECT_ID=$(gcloud config get-value project)
#创建service account
GSA_NAME=velero
gcloud iam service-accounts create $GSA_NAME \
--display-name "Velero service account"
#查看上面创建的service account
gcloud iam service-accounts list
#设置$SERVICE_ACCOUNT_EMAIL变量
SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list \
--filter="displayName:Velero service account" \
--format 'value(email)')
-
- 为 Velero 创建带有权限的 Role
```bash
ROLE_PERMISSIONS=(
compute.disks.get
compute.disks.create
compute.disks.createSnapshot
compute.snapshots.get
compute.snapshots.create
compute.snapshots.useReadOnly
compute.snapshots.delete
compute.zones.get
storage.objects.create
storage.objects.delete
storage.objects.get
storage.objects.list
)
gcloud iam roles create velero.server \
--project $PROJECT_ID \
--title "Velero Server" \
--permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$SERVICE_ACCOUNT_EMAIL \
--role projects/$PROJECT_ID/roles/velero.server
gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://${BUCKET}
```
-
- 为 Velero 的 Service Account 生成 Key
gcloud iam service-accounts keys create credentials-velero \
--iam-account $SERVICE_ACCOUNT_EMAIL
-
- 下载 Velero CLI
wget https://github.com/vmware-tanzu/velero/releases/download/v1.10.0/velero-v1.10.0-linux-amd64.tar.gz
tar -xvzf velero-v1.10.0-linux-amd64.tar.gz
sudo mv velero /usr/local/bin/
velero help
-
- 安装 Velero
在参考上面 GCP 的安装过程时,注意如下类似的安装命令的变量部分,此命令安装 Velero 以及 GCP 的插件,指定存储位置和指定使用 node-agent 来执行 File System Backup。
velero install --provider gcp --plugins velero/velero-plugin-for-gcp:v1.6.0 --bucket $bucketname --secret-file ./credentials-velero --use-volume-snapshots=false --use-node-agent
安装完后注意检查如下内容,确认是否安装成功:
 |
 |
- 在 AWS 环境中部署 Velero CLI 并安装启动 Velero
参考:GitHub – vmware-tanzu/velero-plugin-for-aws: Plugins to support Velero on AWS
-
- 创建 S3 存储桶
注意:us-east-1 does not support a LocationConstraint. If your region is us-east-1, omit the bucket configuration:
BUCKET=
REGION=
aws s3api create-bucket \
--bucket $BUCKET \
--region $REGION \
--create-bucket-configuration LocationConstraint=$REGION
aws s3api create-bucket \
--bucket $BUCKET \
--region us-east-1
-
- 为 Velero 设置权限
注意:在 AWS 为 Velero 赋权有两种方式:第一种为使用 IAM USER AKSK;第二种为使用 kube2iam。在本文中我们使用第一种方式,如果需要第二种请参考上面的链接中的内容。
创建用户 Velero。也可以使用原有的用户的 AKSK,只需要替换掉 Velero 用户名即可:
aws iam create-user --user-name velero
创建 policy:
cat > velero-policy.json <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeVolumes",
"ec2:DescribeSnapshots",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateSnapshot",
"ec2:DeleteSnapshot"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::${BUCKET}/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::${BUCKET}"
]
}
]
}
EOF
aws iam put-user-policy \
--user-name velero \
--policy-name velero \
--policy-document file://velero-policy.json
为 Velero 用户创建 AKSK:
aws iam create-access-key --user-name velero
上面的命令生成类似如下内容:
{
"AccessKey": {
"UserName": "velero",
"Status": "Active",
"CreateDate": "2017-07-31T22:24:41.576Z",
"SecretAccessKey": ,
"AccessKeyId":
}
}
使用上面的 AKSK 生成 credential 文件 credentials-velero:
$aws configure
[default]
aws_access_key_id=
aws_secret_access_key=
-
- 安装 Velero CLI
#下载安装velero CLI
wget https://github.com/vmware-tanzu/velero/releases/download/v1.10.0/velero-v1.10.0-linux-amd64.tar.gz
tar -xvzf velero-v1.10.0-linux-amd64.tar.gz
sudo mv velero /usr/local/bin/
velero help
-
- 安装 Velero server
在参考上面 AWS 的安装过程时,注意如下类似的安装命令的变量部分。另外,此处的 –secret-file 使用的是上面生成的 credentials 文件:credentials-velero,也可以直接使用之前存 AKSK 的 credential 文件,如:~/.aws/credentials。
velero install --provider aws --plugins velero/velero-plugin-for-aws:v1.6.0 --bucket $bucketname --backup-location-config region=$REGION --snapshot-location-config region=$REGION --secret-file /home/ec2-user/.aws/credentials --use-node-agent restic/restic
安装完后注意检查如下内容:
 |
 |
确认完以上类似内容出现后表示安装成功。
部署 Demo 应用
在 GKE 的源 cluster 上部署 Demo 应用,使用下面的 yaml 文件:
$kubectl apply -f mysql.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: mysql
labels:
app: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-mysql
namespace: mysql
labels:
app: mysql
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
---
apiVersion: apps/v1
kind: Statefulset
metadata:
name: s-mysql
namespace: mysql
labels:
app: mysql
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: Password123!
ports:
- containerPort: 3306
name: port-mysql
volumeMounts:
- name: vol-mysql
mountPath: /var/lib/mysql
volumes:
- name: vol-mysql
persistentVolumeClaim:
claimName: pvc-mysql
验证部署是否成功:
 |
在 pod 中写入要持久化存储的测试数据,执行如下命令:
kubectl exec d-mysql-7c748d6f47-j97bt -it /bin/bash -n mysql
参考下面图中的操作内容进行数据写入测试:进入 pod;登录数据库,数据库登录密码见上面 yaml 文件中的环境变量 MYSQL_ROOT_PASSWORD;创建数据库 test1:
 |
使用 Velero 迁移有状态应用
在源集群上备份有状态应用:
a.在源集群上为包含要备份的卷的每个 pod 运行以下命令:
kubectl -n YOUR_POD_NAMESPACE annotate pod/YOUR_POD_NAME backup.velero.io/backup-volumes=YOUR_VOLUME_NAME_1,YOUR_VOLUME_NAME_2,...
举例:
kubectl -n mysql annotate pod/d-mysql-7c748d6f47-j97bt backup.velero.io/backup-volumes=vol-mysql
b.使用 velero 备份源集群的资源:
velero backup create NAME OPTIONS...
举例:
velero backup create mysql-backup-ann --include-namespaces mysql
c.查看备份结果:
velero backup describe mysql-backup-ann
 |
d.将备份内容传输到 Amazon S3 以用于在目标集群进行恢复(这部分内容要提前把 AWS CLI 的 AKSK 权限设置好,不论是哪家公有云,都可以通过 CLI 的权限进行处理):
gsutil -m rsync -rd gs://velerobucket s3://velero-global-bucket
在 Amazon EKS 集群上恢复有状态应用:
a.查看备份内容是否存在:
velero backup get
 |
b.进行恢复操作:
velero restore create mysql-restore-ann --from-backup mysql-backup-ann
c.查看恢复结果:
velero restore describe mysql-restore-ann
 |
d.进入 pod 查看数据是否恢复,看到有 test1 这个数据库后证明源集群中的数据被恢复到了目标集群中,操作命令请参考下图:
 |
Clean up
kubectl delete namespace/velero clusterrolebinding/velero
kubectl delete crds -l component=velero
kubectl delete ns mysql
结论
通过上面的测试,我们可以发现 Velero 的 File System Backup 功能可以有效的对源 Kubernetes 集群中的有状态服务进行跨云迁移,这解决了很多想将有状态服务迁移到云上或跨云迁移的客户的问题。
注意事项
- 如果 Velero 在集群上启动不了就调整一下资源限制,命令如下:
kubectl patch deployment velero -n velero —patch '{"spec":{"template":{"spec":{"containers":[{"name": "velero", "resources": {"limits":{"cpu": "300m", "memory": "512Mi"}, "requests": {"cpu": "200m", "memory": "128Mi"}}}]}}}}'
kubectl patch daemonset node-agent -n velero —patch '{"spec":{"template":{"spec":{"containers":[{"name": "node-agent", "resources": {"limits":{"cpu": "300m", "memory": "512Mi"}, "requests": {"cpu": "200m", "memory": "512Mi"}}}]}}}}'
kubectl create secret generic -n velero bsl-credentials --from-file=gcp=/home/user1/credentials-velero
velero backup-location create bsl-gcp --provider gcp --bucket $BUCKET --credential=bsl-credentials=gcp
- Velero File System Backup 功能不支持 HostPath
- 低版本的 kubectl 可能会导致 API 调用失败,这时需要升级 AWS CLI 到最新版本,然后执行:
aws eks update-kubeconfig --name ${EKS_CLUSTER_NAME} --region ${REGION}
cat ~/.kube/config
#看到:apiVersion: client.authentication.k8s.io/v1beta1
- Velero File System Backup 只能备份在 yaml 中声明的 mountpath 的路径下的内容,除此以外的内容备份不出来
参考资料
GitHub – vmware-tanzu/velero-plugin-for-aws: Plugins to support Velero on AWS
GitHub – vmware-tanzu/velero-plugin-for-aws: Plugins to support Velero on AWS
aws eks update-kubeconfig invalid apiVersion · Issue #6920 · aws/aws-cli · GitHub
Velero Docs – Velero File System Backup Performance Guide