浏览本文需要约10分钟,建议按照章节分段阅读。
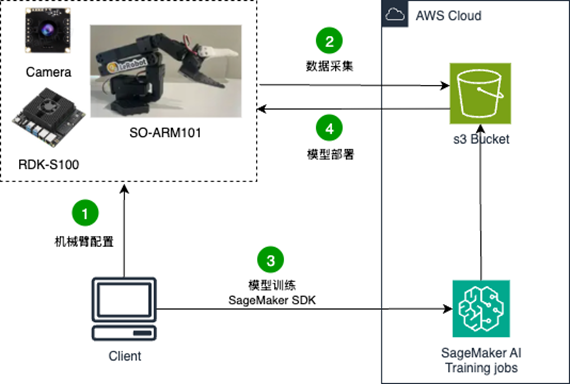
随着具身智能大模型的浪潮席卷学术界与工业界,越来越多的开发者希望以更低门槛参与真实机器人系统的训练与部署。在这一背景下,开源的LeRobot机械臂以其低成本、易获取的优势,成为体验与研究具身智能的理想平台。
机器人开发板采用业界广泛使用的RDK-S100,凭借128 Tops的高算力与完善的生态系统,为本地推理与实时控制提供了坚实的硬件基础。但是训练算力资源,往往是普通开发者最为紧缺却又至关重要的环节。
Amazon SageMaker AI作为一项完全托管的机器学习服务,提供了从数据准备、模型训练到部署推理的一站式解决方案。其弹性伸缩的训练环境、多框架兼容能力以及快速上线特性,使开发者无需管理底层基础设施,能够更专注于算法创新。
借助以上组合,开发者能以低成本实践具身智能从训练到部署的完整闭环。接下来,将从机械臂配置开始,到数据采集,进行模型训练,最后部署在开发板上,完整走通整个流程。
1. 整体架构
2. 物料准备
| 物料名称 |
物料型号 |
产品描述 |
| 机械臂 |
SO-ARM101 |
SO-ARM101 LeRobot开源大模型机械臂 |
| 高清免驱摄像头 |
亚博智能USB摄像头 |
亚博智能USB摄像头1080P,AI视觉识别120帧数,支持树莓派,Jetson和RDK系列主板 |
| 开发板 |
RDK-S100 |
地瓜机器人RDKS100开发者套件6xCortex-A78AE 80TOPS算力 |
3. 本地开发环境准备
首先完成LeRobot开发环境的安装,默认使用Miniconda作为环境管理的工具,先运行以下命令创建一个Python3.10的虚拟环境。
conda create -y -n lerobot python=3.10
接着便可以在Bash中运行以下命令来配置LeRobot所需要的依赖(使用的lerobot源码是我修改之后的,仅添加了本地ServerClient,其他部分与官方源码一致)。
# step:0 安装编译依赖
sudo apt-get install cmake build-essential python3-dev pkg-config libavformat-dev libavcodec-dev libavdevice-dev libavutil-dev libswscale-dev libswresample-dev libavfilter-dev pkg-config
# step:1 激活环境
conda activate lerobot
# step:2 安装ffmpeg
conda install ffmpeg -c conda-forge
# 以下两种方式任选其一:
# step:3.1 安装方式一:从源码安装lerobot
git clone https://github.com/xiongqi123123/LeRobot-VLA.git
cd LeRobot-VLA/lerobot
pip install -e .
# step:3.2 安装方式二:从PyPI安装
pip install lerobot
# 要安装附加功能,请使用以下之一
pip install 'lerobot[all]' # All available features
pip install 'lerobot[aloha,pusht]' # Specific features (Aloha & Pusht)
pip install 'lerobot[feetech]' # Feetech motor support
4. 机械臂和摄像头配置
4.1 机械臂安装
官方安装教程:SO-101-Hugging Face 机器学习平台
由于SO-ARM101机械臂默认不提供机械臂上的相机安装位置,因此在原始的机械臂夹爪部分自行设计添加了一个相机固定的位置(安装孔位与夹爪上的螺丝孔位对齐),相机是亚博智能高清免驱摄像头,固定的底座及支架的打印文件如下:摄像头底座,摄像头支架。
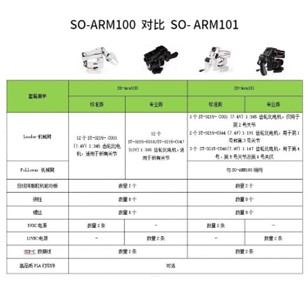
拿到机械臂配件,首先将Follower和Leader臂的物料进行区分,要注意的是Follower机械臂使用的是12个ST-3215-C001(7.4V)1:345齿轮比的电机,而Leader臂不同关节使用的电机型号有所不同,电机型号区分如下图及下表:
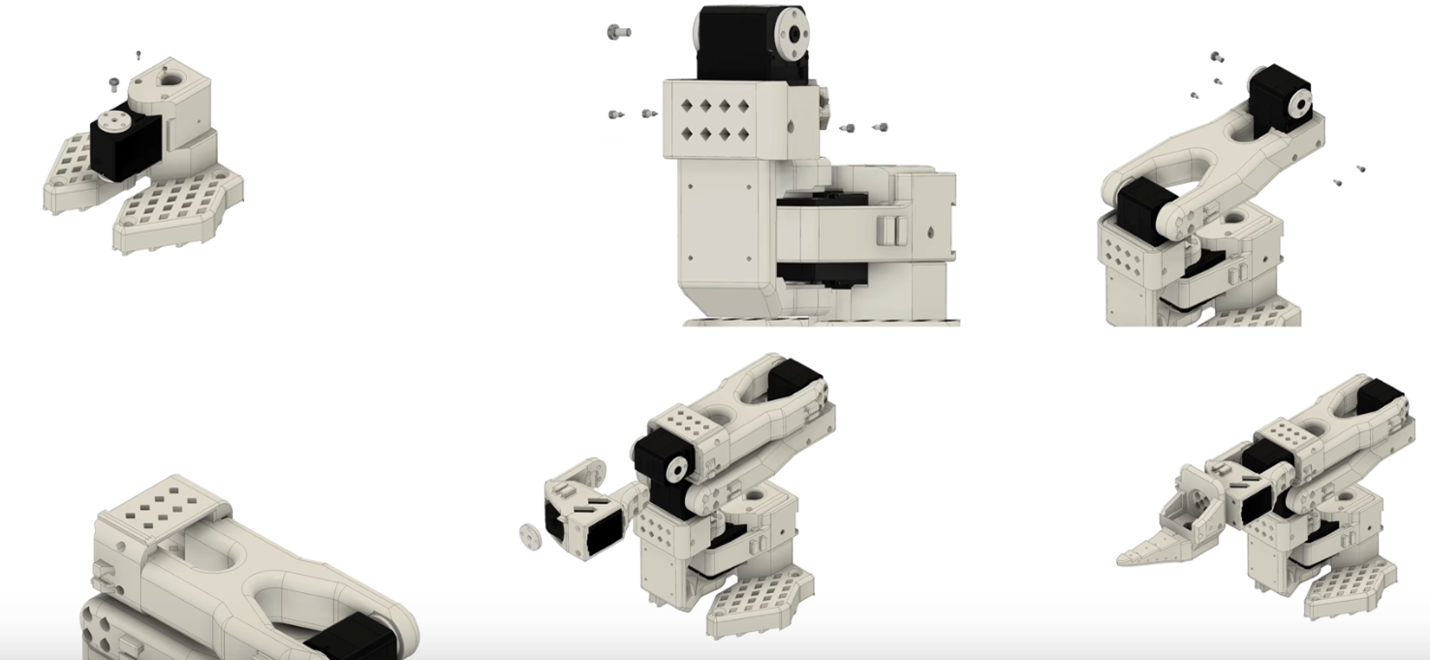
接下来便可以按照官方提供的如下3D演示动画安装Follower和Leader了,下面是关节一到关节五以及夹爪的安装实例,除了夹爪之外,前面五个关节的安装方法均一致,仅需注意Leader臂的电机型号:
4.2 机械臂电机配置
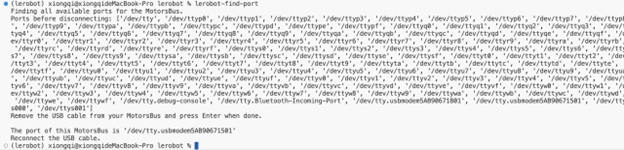
在完成机械臂的安装后,可以开始对机械臂两个臂的电机进行配置并设置其对应的ID了,新版的LeRobot提供了CLI命令可以直接运行对应的命令。首先将两个机械臂的串口线全部接上电脑并运行如下命令,接着按照提示拔出其中一个串口线按下回车即可知道拔出的串口号是多少(实际就是记录插上的所有串口,然后再和拔出后的进行对比就可以知道哪个串口少了…),示例输出如下图:
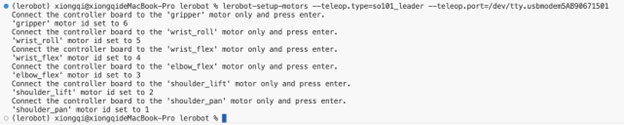
由于LeRobot使用的是总线舵机,每个电机都通过总线上的唯一 ID 进行识别,而全新电机通常带有一个默认 ID 为 ’1’,所以为了让电机和控制器之间正常通信,需要为每个电机设置一个唯一的且不同的 ID,在确定了自己的两个机械臂分别对应的串口后便可以一个臂一个臂一个电机一个电机的进行配置,在新版的LeRobot库不需要重复多次运行电机配置命令,只需要运行以下命令并依次将不同的舵机线插到控制板按回车即可,具体可以参考这个视频。
lerobot-setup-motors \
--robot.type=so101_follower \
--robot.port=/dev/tty.usbmodem585A0076841 # <- paste here the port found at previous step
4.3 主从机械臂校准
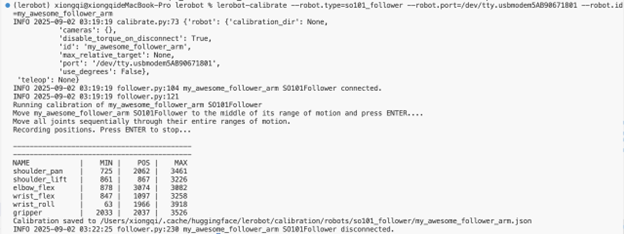
在完成机械臂电机的配置之后,可以对机械臂进行校准。这部分主要是为了确保主动机臂和从动机臂在处于相同物理位置时具有相同的位置值,也就是可以操控Leader来控制Follower臂进行数据采集,旧版的LeRobot需要在运行命令之后将所有臂摆成三个不同的姿势来校准,如果校准的姿势有细微的区别,就会影响两个机械臂之间的映射。新版的LeRobot采用了新的控制方式,只需要在所有舵机处于机械臂运动的中值时开启校准然后依次扭动舵机使系统自动记录舵机当前可运动的最大最小值即可自动完成校准,具体命令如下,及参考视频链接。
lerobot-calibrate \
--robot.type=so101_follower \
--robot.port=/dev/tty.usbmodem58760431551 \ # <- The port of your robot
--robot.id=my_awesome_follower_arm # <- Give the robot a unique name
4.4 摄像头配置
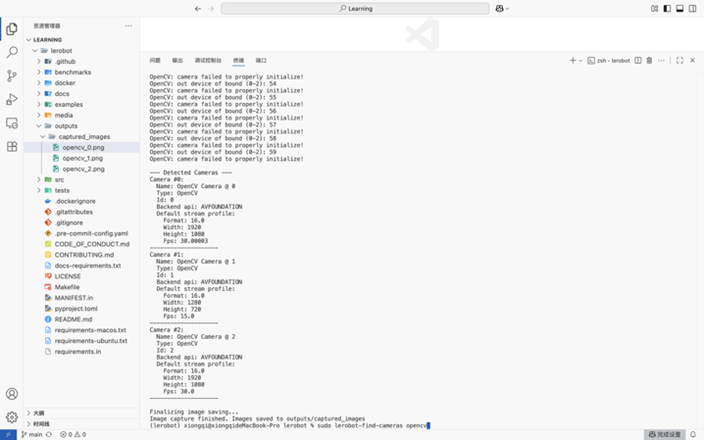
LeRobot 提供多种视频捕捉选项,包括手机摄像头、内置笔记本电脑摄像头、外部网络摄像头等,可以随意选择使用的摄像头以及摄像头的放置位置。首先可以运行以下的命令来查找并测试当前设备连接的摄像头ID及参数:
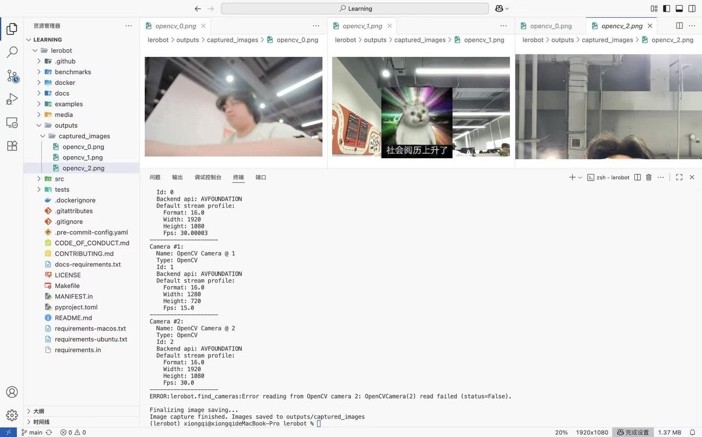
lerobot-find-cameras opencv
启用命令后,会显示出三个摄像头设备(免驱外部摄像头、Macbook摄像头、iPhone连续互通摄像头),拍摄的图片会按照摄像头的ID保存在outputs文件夹中,可以通过这个文件夹里面摄像头拍摄的图片来判断当前位置是否有问题,但是要注意不要将两个同款的摄像头连接在一个USB-HUB上,这样在采集数据的时候会出现摄像头识别问题。
4.5 机械臂测试
在完成了机械臂的校准配置之后,可以使用以下命令来对机械臂进行测试看两个机械臂的校准是否有问题,在命令行输入以下命令之后便可以操作Leader臂来测试Follower臂是否正常的跟随运动了:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/tty.usbmodem5AB90671801 \
--robot.id=my_awesome_follower_arm \
--teleop.type=so101_leader \
--teleop.port=/dev/tty.usbmodem5AB90671501 \
--teleop.id=my_awesome_leader_arm \
如果已经配置好摄像头,可以使用以下命令来同步测试带摄像头的遥操是否正常:
lerobot-teleoperate \
--robot.type=so101_follower \
--robot.port=/dev/tty.usbmodem5AB90671801 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ arm: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}, front: {type: opencv, index_or_path: 2, width: 1920, height: 1080, fps: 30}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/tty.usbmodem5AB90671501 \
--teleop.id=my_awesome_leader_arm \
--display_data=true
5. 数据集采集
完成了上述配置之后,可以开始采集数据集。由于目前使用的是单臂,因此仅采集两个视角的图像,即上方和夹爪视角:
然后是任务方面,围绕笔和笔筒,定义了一个比较常见的任务,使用机械臂来对桌面上杂乱摆放的马克笔进行整理,将其放置到笔筒中,使用到的物品资产如下:
运行以下命令即可开始数据采集,其中的num_episodes用于设置一次采集的数据条数,single_task则用于设置当前任务使用的语言instructions,在将push_to_hub参数设置为False后便会将数据集保存至本地而不会将采集的数据上传至huggingface,episode_time_s参数用于设置每段数据的视频采集时长,reset_time_s则是两段采集之间的复原时间,这些参数按需设置即可:
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/tty.usbmodem5AB90671801 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ arm: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}, front: {type: opencv, index_or_path: 2, width: 1920, height: 1080, fps: 30}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/tty.usbmodem5AB90671501 \
--teleop.id=my_awesome_leader_arm \
--display_data=true \
--dataset.repo_id=skyxz/blackmarker_scence1 \
--dataset.num_episodes=5 \
--dataset.single_task="Grab the black marker and put it in the bin" \
--dataset.push_to_hub=False \
--dataset.episode_time_s=15 \
--dataset.reset_time_s=5
数采过程中要注意慢慢平滑的操作,不可过于快速的完成一个任务。采集之后的数据将保存在~/.cache/huggingface/lerobot/{repo_id}下面,可以打开这个目录来查看每条数据的采集效果,在这里采集红黑两种颜色笔的数据,每个笔采集50条,其中每个笔有10条数据位置大致一定,20条数据笔的摆放位置随机,20条数据桌面有少量其他物品干扰,采集过程参考这个视频。
6. 训练任务配置
SageMaker Training Job 是全托管、按需付费的云服务,可以快速启动和简化机器学习训练。相比较裸机,它不仅能执行模型训练,还集成了模型管理和并行超参数调优等高级功能,开发者可以专注于机器学习本身。
作为 SageMaker AI 用户,可以自带训练数据集,将其保存到 Amazon S3。也可以选择使用 SageMaker AI 内置算法进行模型训练,或者自带训练脚本,使用机器学习框架构建的模型进行训练。
6.1 创建IAM User并获取AK/SK
接下来的操作将基于SageMaker的SDK,使用Python的boto3以及SageMaker Training Job完成所有任务。在此之前需要在本地安装AWS CLI和获取IAM账户的AK和SK,本地安装AWS CLI步骤请参考手册;IAM账户的创建和获取AK/SK请参考手册,账户策略可以访问s3桶, ServiceQuotas,SageMaker和创建IAM Role,遵循权限最小化原则。
通过aws configure在本地设置AK/SK和使用区域,本文的训练任务使用韩国首尔(ap-northeast-2)资源。
aws configure
AWS Access Key ID [None]: ***********
AWS Secret Access Key [None]: **********************
Default region name [None]: ap-northeast-2
Default output format [None]:
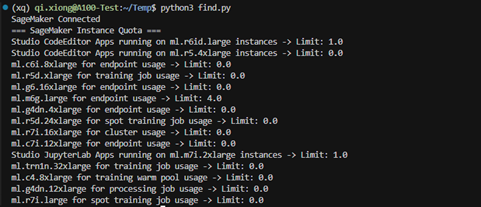
使用以下代码来测试IAM账户权限是否可用,同时获取当前账号下可使用的训练资源配额,出现以下输出即代表与SageMaker的连接是正常的:
pip3 install boto3 sagemaker
import boto3
boto_sess = boto3.Session(
region_name="region"
)
sm = boto_sess.client('sagemaker')
resp = sm.list_training_jobs(MaxResults=1)
print("SageMaker Connected")
service_quotas = boto_sess.client('service-quotas')
quotas = service_quotas.list_service_quotas(ServiceCode='sagemaker')
print("=== SageMaker Instance Quota ===")
for q in quotas['Quotas']:
if 'ml.' in q['QuotaName']:
print(f"{q['QuotaName']} -> Limit: {q['Value']}")
6.2 创建IAM Role
AWS的SageMaker进行训练需要用到Role的概念,这个Role(角色)是一种临时授权机制,由于在训练的时候数据集一般储存在AWS的s3bucket中,使用角色可以赋予SageMaker访问其他 AWS 服务(如 S3、CloudWatch)的权限,当SageMaker运行训练任务时,它会以这个角色的身份去读取数据集、写入模型输出等操作。
首先需要在IAM中创建一个SageMaker执行角色(Execution Role),并授予创建的这个角色AmazonS3FullAccess以及 AmazonSageMakerFullAccess 等必要策略,使用SDK来创建这样的一个角色:
import boto3
import json
boto_sess = boto3.Session(
region_name="Region"
)
iam = boto_sess.client("iam")
role_name = "SkyXZ-Test-Role"
trust_policy = {
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "sagemaker.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}
try:
role = iam.create_role(
RoleName=role_name,
AssumeRolePolicyDocument=json.dumps(trust_policy),
Description="SageMaker execution role"
)
except iam.exceptions.EntityAlreadyExistsException:
role = iam.get_role(RoleName=role_name)
policies = [
"arn:aws:iam::aws:policy/AmazonSageMakerFullAccess",
"arn:aws:iam::aws:policy/AmazonS3FullAccess"
]
for p in policies:
iam.attach_role_policy(RoleName=role_name, PolicyArn=p)
print(f"Role Created: {role['Role']['Arn']}")
使用以下代码来查看当前账号下创建的所有Role:
import boto3
boto_sess = boto3.Session(
region_name="Region"
)
iam = boto_sess.client('iam')
paginator = iam.get_paginator('list_roles')
for page in paginator.paginate():
for role in page['Roles']:
print(f"Role Name: {role['RoleName']}")
print(f" ARN: {role['Arn']}")
print(f" Create Date: {role['CreateDate']}")
print("-" * 60)
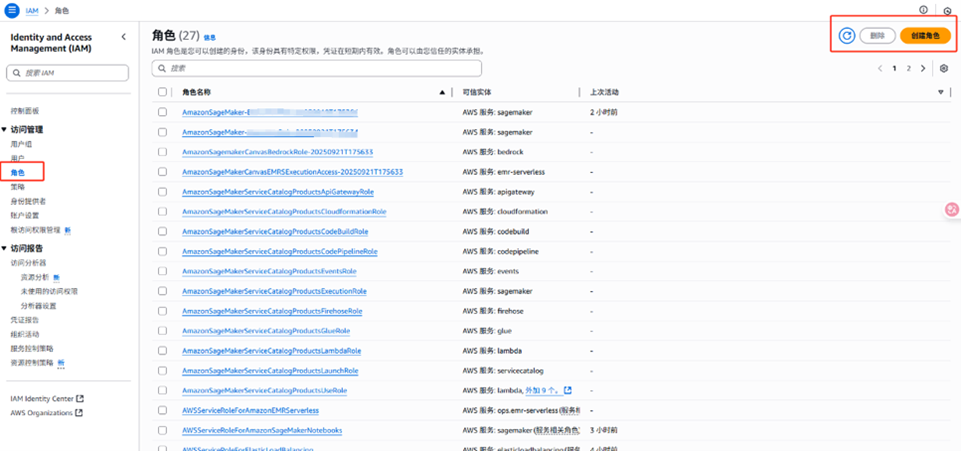
除了使用SDK的方式,也可以使用网页端可视化的配置Role。进入AWS的控制台依旧进入服务中的IAM页面,然后找到左边列表访问管理里的角色,即可在右上角创建一个新的Role。
6.3 创建S3Bucket并上传数据集
s3bucket是AWS提供的一个通用存储服务,用于存放训练数据、模型文件以及其他资源。使用SageMaker训练模型的时候,可以将本地的数据集上传到s3bucket以便SageMaker训练作业可以直接从云端读取数据,用以下代码来创建一个s3bucket存储桶:
import boto3
import os
boto_sess = boto3.Session(
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = 'skyxz-test-bucket-2025'
s3.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={'LocationConstraint': 'Region'}
)
print(f"S3 Bucket {bucket_name} Created")
用以下代码查看当前账号下创建的所有s3bucket以及所在的区域和对应桶的大小:
import boto3
boto_sess = boto3.Session(
region_name="Region"
)
s3 = boto_sess.client('s3')
s3_res = boto_sess.resource('s3')
for bucket in s3.list_buckets()['Buckets']:
name = bucket['Name']
region = s3.get_bucket_location(Bucket=name).get('LocationConstraint')
size_mb = sum(obj.size for obj in s3_res.Bucket(name).objects.all()) / (1024*1024)
print(f"{name} | Region: {region} | Size: {size_mb:.2f} MB")
创建了一个s3bucket之后,可以使用如下的代码将本地或者服务器的数据集上传至刚才新创建的存储桶:
import boto3, os
boto_sess = boto3.Session(
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = 'your-bucket'
local_dir = './my_local_dataset'
s3_prefix = 'lerobot-data/'
for root, dirs, files in os.walk(local_dir):
for file in files:
local_path = os.path.join(root, file)
relative_path = os.path.relpath(local_path, local_dir)
s3_key = os.path.join(s3_prefix, relative_path).replace("\\", "/")
s3.upload_file(local_path, bucket_name, s3_key)
print(f"Success: {local_path} → s3://{bucket_name}/{s3_key}")
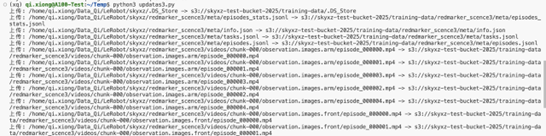
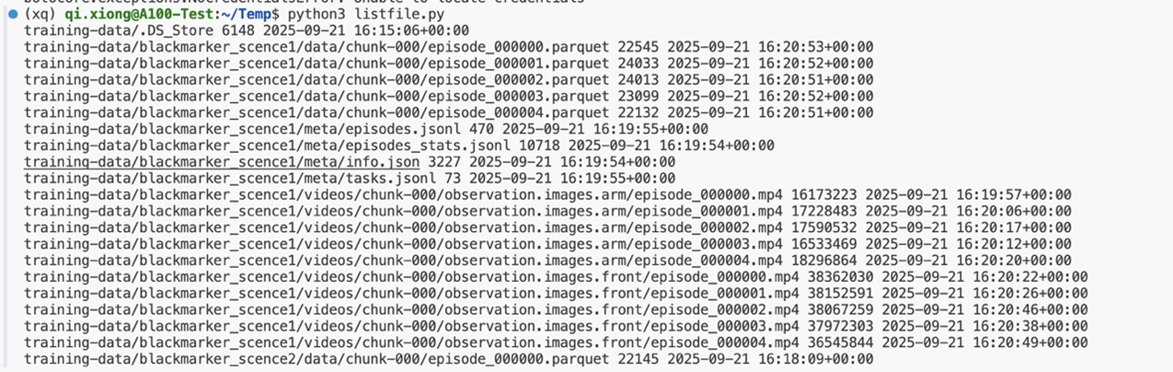
上传完成后,可以使用 boto3 的 list_objects_v2 方法,来遍历指定桶里的文件,使用如下的代码来列出s3bucket中所有文件进行检查:
import boto3
boto_sess = boto3.Session(
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = "skyxz-test-bucket-2025"
s3_prefix = "training-data"
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=s3_prefix)
if "Contents" in response:
for obj in response["Contents"]:
print(obj["Key"], obj["Size"], obj["LastModified"])
else:
print("No Found Files")
如果要删除桶中的某个文件,可以使用 boto3 的 delete_object 方法,具体方法及代码如下:
import boto3
boto_sess = boto3.Session(
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = "skyxz-test-bucket-2025"
key_to_delete = "training-data/example.txt"
s3.delete_object(Bucket=bucket_name, Key=key_to_delete)
print(f"{key_to_delete} have been {bucket_name} deleted")
如果不需要这个桶了,可以用 boto3 的 delete_bucket 方法删除桶本身。但由于S3 不允许删除非空桶,因此在删除之前需要把桶内的文件全部删除清空,以下代码会先清空桶里的所有文件,然后删除这个桶:
import boto3
boto_sess = boto3.Session(
region_name="Region"
)
s3 = boto_sess.client('s3')
bucket_name = "skyxz-test-bucket-2025"
objects = s3.list_objects_v2(Bucket=bucket_name)
if 'Contents' in objects:
for obj in objects['Contents']:
s3.delete_object(Bucket=bucket_name, Key=obj['Key'])
s3.delete_bucket(Bucket=bucket_name)
print(f"{bucket_name} have been deleted")
当然也可以使用可视化的界面,来创建s3bucket存储数据集。在AWS控制台的左上角的所有服务中,选择s3即可进入存储桶服务,点击右边的创建并根据引导一步一步设置即可。
7. 训练过程
LeRobot中已经集成ACTPolicy,在配置好LeRobot环境之后可以直接使用如下代码开始训练,其中参数{dataset.root}为指定的数据集路径、{policy.type} 为使用的策略类型、{output_dir} 为训练模型保存的路径、{job_name} 为任务名称和{policy.repo_id}
lerobot-train \
--dataset.repo_id=${HF_USER}/so101-test-0903 \
--policy.type=act \
--output_dir=outputs/train/act_so100_test \
--job_name=act_so100_test \
--policy.device=cuda \
--wandb.enable=false \
--policy.repo_id=${HF_USER}/my_policy
7.1 使用SageMaker GPU按需实例
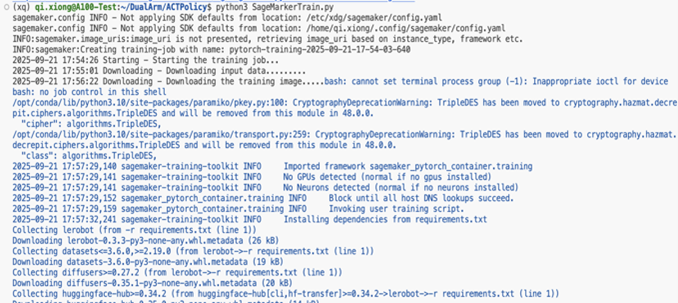
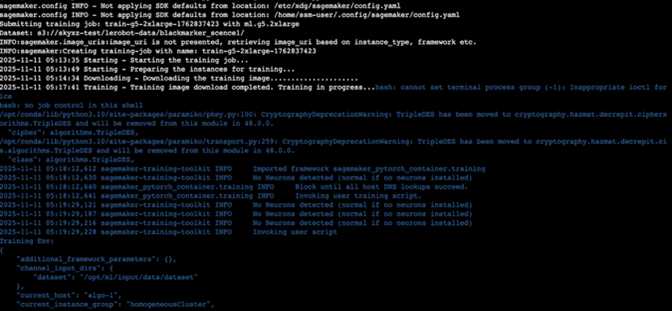
由于使用lerobot-train指令在没配置HuggingFace仓库时,默认会加载的本地数据集路径为~/.cache/huggingface/lerobot,需要使用{dataset.root} 来指定到本地的数据集路径。接着在lerobot目录同级创建一个SageMakerTrain.py作为SageMaker的启动文件,但由于使用lerobot-train命令进行训练,需要在lerobot目录内有一个train.py脚本,两个文件如下:
SageMakerTrain.py
from sagemaker.pytorch import PyTorch
from sagemaker.inputs import TrainingInput
import boto3, sagemaker
# === 数据集路径 ===
dataset_input = TrainingInput(
"s3://your-bucket-name/",
distribution="FullyReplicated"
)
# === 创建 boto3 会话 ===
boto_sess = boto3.Session(
region_name="Region"
)
# === SageMaker 会话 ===
sess = sagemaker.Session(boto_session=boto_sess)
# === PyTorch 训练任务 ===
estimator = PyTorch(
entry_point="lerobot/train.py",
source_dir="/your-source-dir/",
dependencies=["lerobot/requirements.txt"],
role="your-role-arn",
instance_count=1,
instance_type="ml.g5.2xlarge",
framework_version="2.1",
py_version="py310",
sagemaker_session=sess,
)
# === 发起训练 ===
estimator.fit({"dataset": dataset_input})
train.py
import subprocess
import sys
cmd = [
'lerobot-train',
'--dataset.repo_id=/opt/ml/input/data/dataset/',
'--dataset.video_backend=pyav',
'--policy.type=act',
'--output_dir=outputs/train/act_so100_test',
'--job_name=act_so100_test',
'--wandb.enable=false',
'--policy.push_to_hub=false',
'--policy.device=cuda',
'--batch_size=2',
'--steps=100000'
]
print(f"Running: {' '.join(cmd)}")
subprocess.run(cmd, check=True)
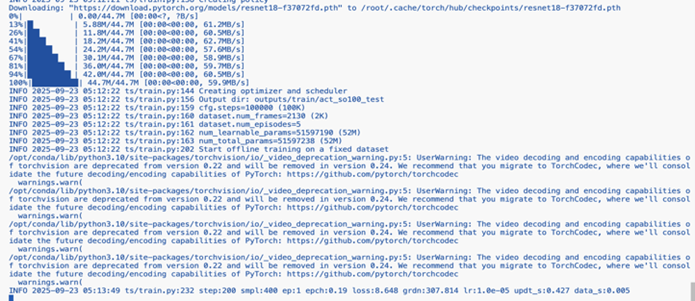
看到如下输出即代表训练正常启动:
训练完成的模型文件,会储存在所用的s3bucket里面。如下方所示,可以直接在网页上下载模型的训练结果,也可以使用如下的代码从桶中拉取下来。
import boto3, os
boto_sess = boto3.Session(
region_name="Region"
)
bucket = ""
prefix = ""
local_dir = "./output"
s3 = boto_sess.client("s3")
resp = s3.list_objects_v2(Bucket=bucket, Prefix=prefix)
for obj in resp.get("Contents", []):
key = obj["Key"]
if key.endswith("/"):
continue
local_path = os.path.join(local_dir, os.path.relpath(key, prefix))
os.makedirs(os.path.dirname(local_path), exist_ok=True)
s3.download_file(bucket, key, local_path)
print(f"Downloaded: {key} -> {local_path}")
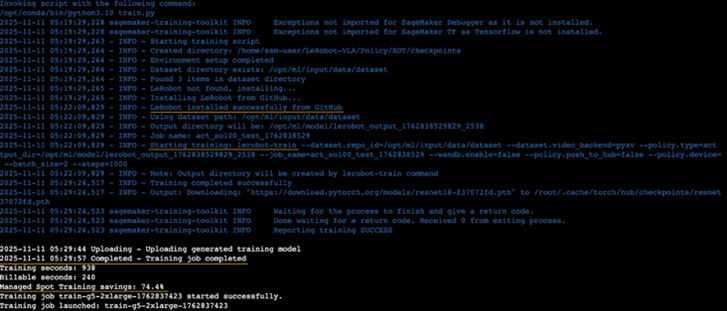
7.2 使用SageMaker GPU Spot实例
在训练像LeRobot ACT这样的模型,Amazon SageMaker的Spot GPU实例通常是一个非常合适且高性价比的选择,尤其适合那些能够容忍中断、并且希望大幅控制成本的训练任务,按需GPU和Spot GPU对比如下:
| 对比维度 |
按需GPU实例 (On-Demand) |
Spot GPU实例 (Spot Instances) |
| 核心概念 |
按使用时长付费,稳定可靠的计算资源 |
利用AWS空闲容量的折扣实例,价格远低于按需实例 |
| 价格与成本 |
价格固定,费用较高 |
价格极低,通常可比按需实例节省60%-90% 的成本 |
| 适用场景 |
生产环境、关键任务、无法容忍中断的长时间训练或推理 |
容错性高的任务:如模型实验、调试、数据处理 |
同上述GPU按需场景下的使用,两个文件如下链接:SageMakerTrain.py和train.py。
看到如下输出即代表训练正常启动,从图示中可以看到该训练任务成本节省了74.4%。
8. 在开发板上部署模型并推理
在完成了模型的训练之后,使用LeRobot+RDKS-100进行实机测试,在RDK-S100上配置板端推理的所需环境,在板端依旧使用MiniConda作为包管理工具,创建所需的Python3.10的环境。
# 创建conda环境
conda create -y -n lerobot python=3.10
# 激活虚拟环境
conda activate lerobot
接着在板端安装好LeRobot的仓库,ACT的板端运行代码和导出量化工具均保存在LeRobot-VLA/RDKS_ModelRun/ACT下面,这里面集成了RDK-S100官方提供的rdk_LeRobot_tools脚本可以帮助大家快速完成模型的板端量化与编译。
# step:1 Clone官方LeRobot仓库
git clone https://github.com/xiongqi123123/LeRobot-VLA.git
# step:2 安装所需依赖
conda install ffmpeg=7.1.1 -c conda-forge # 若使用conda环境
cd lerobot && pip install -e ".[feetech]"
8.1 CPU部署
CPU部署比较快速,RDKS_ModelRun/ACT下面提供了可以直接运行的脚本,仅需要根据个人的配置修改这个脚本中的一些参数即可。需要修改的一些参数位置如下:
...16-25
NUM_EPISODES = 10 <---
FPS = 30 <---
EPISODE_TIME_SEC = 60 <---
TASK_DESCRIPTION = "My task description" <---
# Create the robot configuration
camera_config = {"front": OpenCVCameraConfig(index_or_path=0, width=640, height=480, fps=FPS)} <---
robot_config = SO100FollowerConfig(
port="/dev/tty.usbmodem5AA90178121", id="my_red_robot_arm", cameras=camera_config <---
)
# Initialize the policy --31--
policy = ACTPolicy.from_pretrained("train\act_so100_testpretrained_model") <--此处修改为模型地址
修改完参数之后可以直接运行推理代码:
# 需要修改脚本中对应模型权重目录
python RDKS_ModelRun/ACT/cpu_act_infer.py
8.2 BPU部署
BPU部署相对比较复杂,但是模型的运行性能会有大幅提升,总体的流程是:模型导出->模型量化->模型编译>板端部署HBM模型。首先将ACT Policy导出为ONNX模型的形式,训练出来的模型文件夹格式一般如下:
./pretrained_model/
├── config.json
├── model.safetensors
└── train_config.json
ACT的工具包中也集成了RDK-S100提供的一键导出ONNX模型,并在运行过程中生成校准数据的脚本,具体的脚本路径在RDKS_ModelRun/ACT/export_bpu_actpolicy.py。这个脚本有以下的参数可以配置,其中的type参数用于配置生成模型运行在板端的类型,RDK-S100为nash-e,RDK-X5为bayes-e,其余的参数仅需根据自己的需要,配置导出路径即可:
parser.add_argument('--act-path', type=str, default='outputs/train/act_so100_test/checkpoints/001000/pretrained_model', help='Path to LeRobot ACT Policy model.')
"""
# example: --act-path pretrained_model
./pretrained_model/
├── config.json
├── model.safetensors
└── train_config.json
"""
parser.add_argument('--export-path', type=str, default='marcelo_test1', help='Path to save LeRobot ACT Policy model.')
parser.add_argument('--cal-num', type=int, default=400, help='Num of images to generate')
parser.add_argument('--onnx-sim', type=bool, default=True, help='Simplify onnx or not.')
parser.add_argument('--type', type=str, default="nash-e", help='Optional: nash-e, nash-m, nash-p, bayes-e, bayes')
parser.add_argument('--combine-jobs', type=int, default=6, help='combie jobs for OpenExplore.')
opt = parser.parse_args([])
在完成了参数配置后,使用如下命令来运行这个脚本。由于代码中调用了LeRobot的一些参数服务器,这里的一些参数配置与训练时基本一致,一般需要修改的参数是–dataset.repo_id或–dataset.root(优先级高)来指定所使用的数据集,–policy.repo_id来指定policy仓库(优先级小于–act-path)
python RDKS_ModelRun/ACT/export_bpu_actpolicy.py \
--dataset.repo_id=${HF_USER}/so100-test-0903 \
--dataset.root=...... \
--policy.type=act \
--policy.device=cpu \
--policy.policy=111 \
--wandb.enable=false
出现以下日志代表脚本运行成功,模型以及校准数据有正确生成:
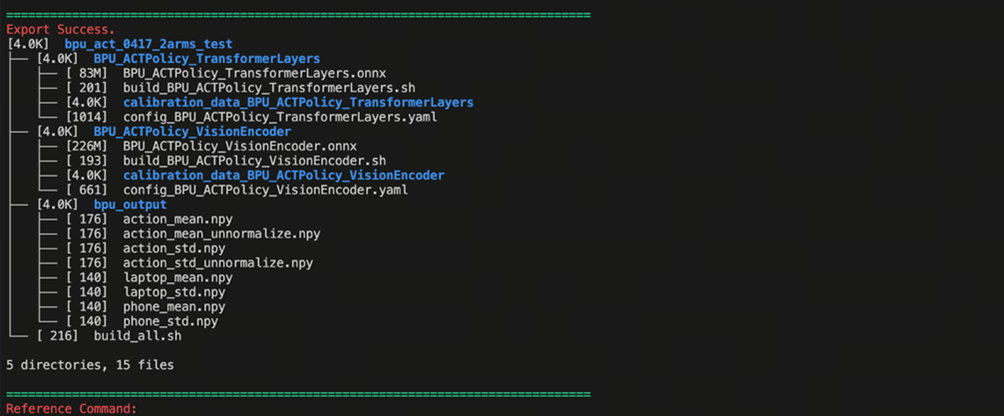
在完成了ACT模型的导出之后,即获得了BPU编译的工作目录,结构如下图所示,官方提供的代码将ACT Policy的视觉编码器部分和4+1层的Transformers层分别导出为ONNX,同时基于训练时的数据集,取了50组校准数据进行保存,并同步生成了编译的脚本和编译的yaml文件夹,还将图像和action输入的前后处理参数保存为npy文件,放在最终BPU模型生成的产出文件夹中:
├── BPU_ACTPolicy_TransformerLayers
│ ├── BPU_ACTPolicy_TransformerLayers.onnx
│ ├── build_BPU_ACTPolicy_TransformerLayers.sh
│ ├── calibration_data_BPU_ACTPolicy_TransformerLayers
│ ├── config_BPU_ACTPolicy_TransformerLayers.yaml
├── BPU_ACTPolicy_VisionEncoder
│ ├── BPU_ACTPolicy_VisionEncoder.onnx
│ ├── build_BPU_ACTPolicy_VisionEncoder.sh
│ ├── calibration_data_BPU_ACTPolicy_VisionEncoder
│ ├── config_BPU_ACTPolicy_VisionEncoder.yaml
├── bpu_output_act_0417_2arms
│ ├── action_mean.npy
│ ├── action_mean_unnormalize.npy
│ ├── action_std.npy
│ ├── action_std_unnormalize.npy
│ ├── laptop_mean.npy
│ ├── laptop_std.npy
│ ├── phone_mean.npy
│ └── phone_std.npy
└── build_all.sh
接着便可以使用RDK-S100官方交付的工具链,标准环境Docker来对模型进行编译,具体操作的命令如下,仅需要将导出生成的文件夹路径替换 {path/to/your/folder} 即可:
# 下载并挂载RDKS100官方Docker工具链交付物
#CPU Docker镜像
wget -c ftp://oeftp@sdk.d-robotics.cc/oe_v3.2.0/ai_toolchain_ubuntu_22_s100_cpu_v3.2.0.tar --ftp-password=Oeftp~123$%
#GPU Docker镜像
wget -c ftp://oeftp@sdk.d-robotics.cc/oe_v3.2.0/ai_toolchain_ubuntu_22_s100_gpu_v3.2.0.tar --ftp-password=Oeftp~123$%
# 导入镜像
docker load < ai_toolchain_ubuntu_22_s100_gpu_v3.2.0.tar
# 挂载镜像执行自动编译
[sudo] docker run [--gpus all] -it -v <BPU_Work_Space>:/open_explorer REPOSITORY:TAG
# Example:
docker run -it --rm --gpus device=6 --shm-size=32g \
-v {path/to/your/folder}:/open_explorer \
ai_toolchain_ubuntu_22_s100_gpu:v3.2.0
# 运行编译
bash build_all.sh
在Docker内部运行了build_all.sh脚本,完成了模型量化与编译的步骤之后,便会得到bpu_output文件夹,这个文件夹里面会有如下的内容:
$ tree bpu_output
.
├── BPU_ACTPolicy_TransformerLayers.hbm
├── BPU_ACTPolicy_VisionEncoder.hbm
├── action_mean.npy
├── action_mean_unnormalize.npy
├── action_std.npy
├── action_std_unnormalize.npy
├── laptop_mean.npy
├── laptop_std.npy
├── phone_mean.npy
└── phone_std.npy
将这整个文件夹全部复制进RDK-S100开发板板端,并将修改工具包中bpu_act_infer.py文件里的模型路径(PS: 这里的模型路径是整个bpu_output文件夹),接着运行如下的命令即可开始使用BPU推理,演示视频浏览链接。
python RDKS_ModelRun/ACT/bpu_act_infer.py
9. 总结
本文旨在引导开发者走通一个从机械臂配置开始,经过数据采集,云端模型训练,最终部署到开发板上运行的端到端闭环流程。所有代码已传至GitHub,欢迎探讨和指正。
10. 参考资料
[1] 如何组装旗舰机器人 SO-101
[2] D-Robotics RDK用户手册
[3] Amazon SageMaker Python SDK
[4] Run training on Amazon SageMaker
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |