实时 ASR 的业务场景与需求
在近几年,自动语音识别(ASR,Automatic Speech Recognition)经历了两条主线的发展:一条是模型本身,从传统声学/语言模型到端到端的 Transformer、再到多模态大模型;另一条是推理硬件,从早期的通用 GPU 到今天专门针对推理优化的低功耗、高带宽芯片。两条曲线叠加的结果是:在一块主流数据中心 GPU 上,已经可以稳定支撑多路语音流的低延迟识别,这也让“实时 ASR”从概念变成了可以大规模落地的能力。
应用层,围绕实时 ASR 已经形成了几类典型需求:
-
交互类:语音助手、智能客服、车载语音、人机对话机器人,更看重 单句响应延迟 和连续对话体验。
-
内容呈现类:直播/短视频字幕、会议同声传译、在线课程,要求识别结果能紧跟画面,整体 端到端延迟控制在 1–2 秒以内。
-
实时分析类:呼叫中心质检、金融风控、内容安全审核,需要在通话进行中完成“识别 + 关键词/情绪/意图”判断,对 持续吞吐和稳定性 要求更高。
这些场景的共同点是:不再满足于“通话结束后再离线转写”,而是希望在说话的同时就拿到可用的转写结果,甚至直接得到机器的分析结论。这正是轻量化、低延迟 ASR 模型和新一代推理 GPU 发挥价值的地方。
技术平台选型:GPU 实例与 SageMaker AI
要把上述这些实时 ASR 需求落到生产环境,关键有两点:一是选什么样的 GPU 做推理核心,二是选什么样的平台来托管和运维这些推理服务。
在硬件层面,近几代数据中心 GPU(例如面向NVIDIA推理优化的 T 系列、L 系列)在算力、显存带宽和能效比上不断提升,使得一张卡既能支撑多路语音流实时转写,又能同时承载后续的文本理解、检索和风控模型。 对于企业来说,更现实的问题不再是“算力够不够”,而是“如何在成本可控的前提下,把这些 GPU 的利用率真正压满”,比如在同一块卡上同时跑 ASR 和大语言模型、在忙闲时段自动调整实例数量等。
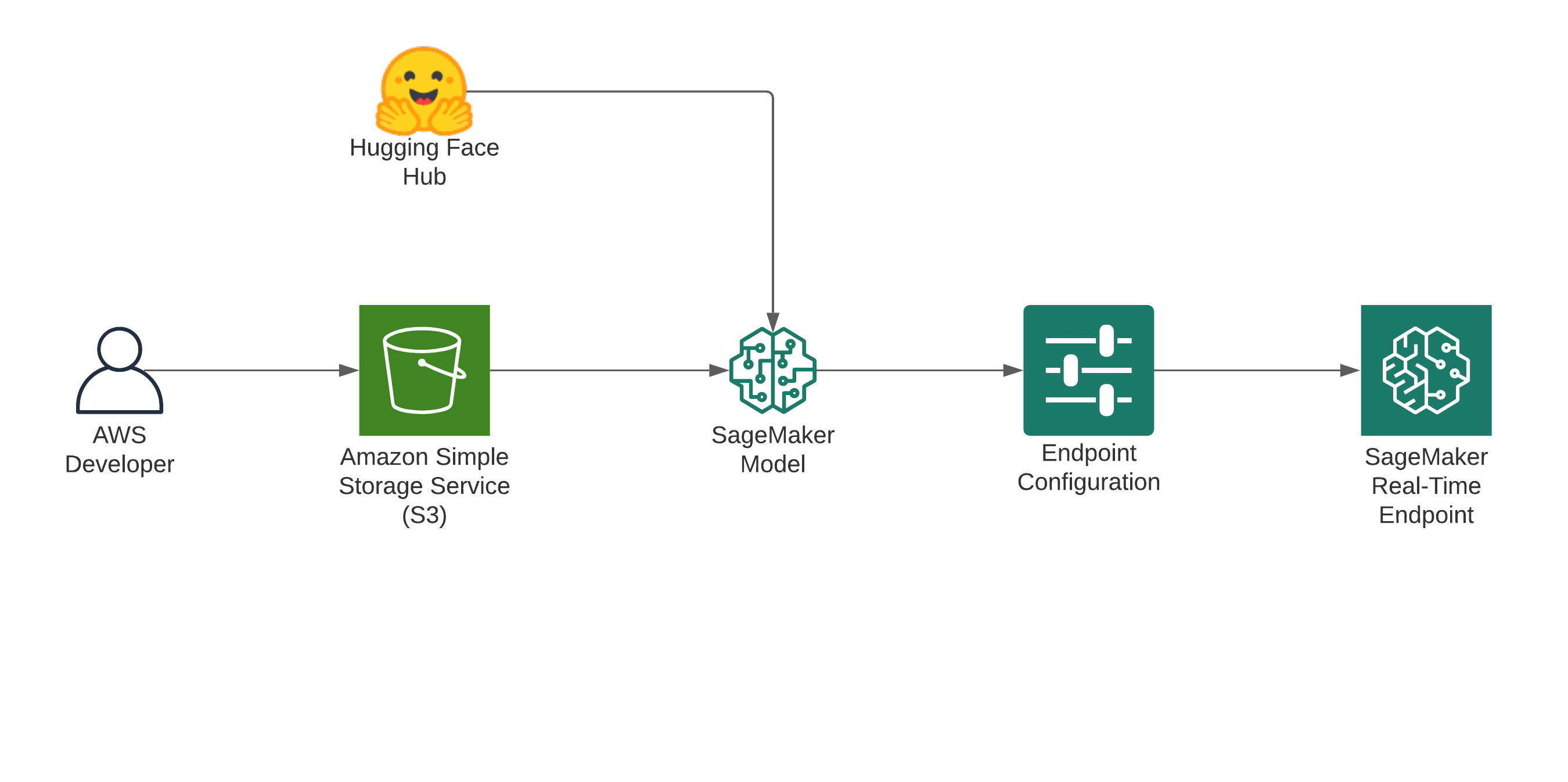
在平台层面,Amazon SageMaker AI 提供了一个面向企业的托管推理底座:一方面可以直接调度搭载 NVIDIA GPU 的实例(如使用 L4、L40S 的实例族)来承载实时 ASR 工作负载,另一方面通过 Real-time Inference 端点 把模型以标准 HTTPS API 的形式暴露出去,并内置健康检查、监控、自动扩缩容、多模型端点等能力。 对比“自己在裸 EC2 上拉 Docker”,SageMaker 的优势在于:让团队可以把主要精力放在模型与业务逻辑上,而不是把时间耗在容器编排、日志聚合、告警和灰度发布这些基础设施上。
在这篇文章后续的内容中,会以 “NVIDIA GPU 实例 + SageMaker Real-time 端点” 作为统一的平台组合,分别部署并测试 Whisper Turbo、Voxtral Mini 和 NVIDIA Parakeet 三类实时 ASR 模型,比较它们在同一技术栈下的延迟、吞吐和适用场景。
部署步骤与测试结论
Whisper Large-v3 Turbo
模型 openai/whisper-large-v3-turbo 0.8b
OpenAI 的 Whisper Large-v3 Turbo(约 0.8B 参数) 是在 Large-v3 基础上做结构剪枝和加速优化的一代实时友好模型,重点优势是:在保持接近原版 Large-v3 识别精度的前提下,大幅减少解码层数和计算量,使推理速度提升到原版的数倍,更适合直播字幕、在线会议、语音助手等低延迟场景;同时参数规模和显存占用显著下降,方便在单卡 GPU 上以更高并发运行,整体实现“中高精度 + 明显更快 + 资源占用更小”的平衡。
在亚马逊云科技平台上,可以使用SageMaker的jumpstart 实现一键部署。也可以参考以下脚本指定模型及实例参数部署。
import json
import boto3
from sagemaker.jumpstart.model import JumpStartModel
from sagemaker.jumpstart.utils import get_jumpstart_content_bucket
model_id, model_version = "huggingface-asr-whisper-large-v3-turbo", "*"
model = JumpStartModel(model_id=model_id, model_version=model_version)
model.deploy(
initial_instance_count=1,
instance_type="ml.g6e.12xlarge",
)
-
进入SageMaker AI 的RSstuido
-
在Models 界面搜索Whisper Large-v3 Turbo 模型
-
点击部署,选择实例类型
-
测试总结
Payload 示例:
def invoke_whisper_turbo(self, endpoint: str, audio_data: dict) -> tuple[float, Optional[str]]:
"""调用 Whisper Turbo 端点 (JumpStart 格式,使用 hex 编码)"""
payload = {
"audio_input": audio_data["hex"]
}
start = time.time()
try:
resp = self.sm_runtime.invoke_endpoint(
EndpointName=endpoint,
ContentType="application/json",
Body=json.dumps(payload)
)
result = json.loads(resp["Body"].read().decode("utf-8"))
latency = time.time() - start
text = result.get("text", result.get("transcription", ""))
return latency, text
except Exception as e:
return time.time() - start, None
Single-request latency
| Audio duration |
Mean (ms) |
P50 (ms) |
P95 (ms) |
P99 (ms) |
QPS |
| 15s |
483 |
482 |
488 |
489 |
2.07 |
| 30s |
491 |
492 |
497 |
498 |
2.03 |
| 60s |
515 |
515 |
523 |
527 |
1.94 |
Throughput (QPS) under concurrency
| Audio duration |
C=1 |
C=5 |
C=10 |
C=20 |
| 15s |
2.08 |
2.14 |
2.14 |
2.14 |
| 30s |
2.04 |
2.13 |
2.12 |
2.12 |
| 60s |
1.97 |
2.11 |
2.11 |
2.11 |
Average latency (ms) under concurrency
| Audio duration |
C=1 |
C=5 |
C=10 |
C=20 |
| 15s |
481 |
2238 |
4246 |
7562 |
| 30s |
490 |
2251 |
4284 |
7614 |
| 60s |
509 |
2273 |
4307 |
7652 |
Voxtral Mini
mistralai/Voxtral-Mini-3B-2507
mistralai/Voxtral-Mini-3B-2507 是一款约 30 亿参数的多模态语音模型,既能完成高质量的语音转文字,又能在同一次推理中执行摘要、问答和内容理解等任务,因此非常适合作为“转录 + 语义理解一体化”的在线服务内核。 相比传统纯 ASR 模型,它在保持接近主流强力 ASR(如 Whisper 大模型)识别准确率的同时,提供更长上下文和多任务能力,支持对长语音(播客、会议、电话录音等)做端到端的理解与生成,从而简化“ASR → LLM”的多段流水线。
本文使用自定义部署镜像,通过SageMaker AI 部署实时推理端点。
- 自定义镜像Dockerfile 参考Github
# Custom vLLM Container for Voxtral Model Deployment on SageMaker
FROM --platform=linux/amd64 vllm/vllm-openai:latest
# Set environment variables for SageMaker
ENV MODEL_CACHE_DIR=/opt/ml/model
ENV TRANSFORMERS_CACHE=/tmp/transformers_cache
ENV HF_HOME=/tmp/hf_home
ENV VLLM_WORKER_MULTIPROC_METHOD=spawn
# Install audio processing dependencies
RUN pip install --no-cache-dir \
"mistral_common>=1.8.1" \
librosa>=0.10.2 \
soundfile>=0.12.1 \
pydub>=0.25.1
- 指定模型和参数
# Model configuration for BYOC deployment (as per official requirements)
engine=Python
#option.model_id=mistralai/Voxtral-Small-24B-2507
option.model_id=mistralai/Voxtral-Mini-3B-2507
option.tensor_parallel_degree=1
option.rolling_batch=vllm
option.dtype=bfloat16
# vLLM specific settings for Voxtral (as per official HF documentation)
option.tokenizer_mode=mistral
option.config_format=mistral
option.load_format=mistral
option.trust_remote_code=true
option.download_dir=/tmp/model_cache
# Memory and performance optimization (for L4 GPU)
option.gpu_memory_utilization=0.92
# 1.5分钟音频约需 ~8k tokens,降低可提升性能
option.max_model_len=16384
option.pipeline_parallel_size=1
option.block_size=16
option.swap_space=4
option.cpu_offload_gb=0
- 执行部署
import boto3
import sagemaker
from sagemaker.model import Model
# Initialize SageMaker session
region = "us-east-1"
boto_session = boto3.Session(region_name=region)
sagemaker_session = sagemaker.Session(boto_session=boto_session)
role = sagemaker.get_execution_role()
bucket = ""
# Upload model artifacts to S3
byoc_config_uri = sagemaker_session.upload_data(
path="./code",
bucket=bucket,
key_prefix="voxtral-vllm-byoc/code"
)
# Configure custom container image
account_id = boto3.client('sts').get_caller_identity()['Account']
image_uri = f"{account_id}.dkr.ecr.{region}.amazonaws.com/voxtral-vllm-byoc:latest"
# Create SageMaker model
voxtral_model = Model(
image_uri=image_uri,
sagemaker_session=sagemaker_session,
model_data={
"S3DataSource": {
"S3Uri": f"{byoc_config_uri}/",
"S3DataType": "S3Prefix",
"CompressionType": "None"
}
},
role=role,
env={
'MODEL_CACHE_DIR': '/opt/ml/model',
'TRANSFORMERS_CACHE': '/tmp/transformers_cache',
'SAGEMAKER_BIND_TO_PORT': '8080'
}
)
# Deploy to endpoint
predictor = voxtral_model.deploy(
initial_instance_count=1,
instance_type="ml.g6e.12xlarge", # For Voxtral-Small
container_startup_health_check_timeout=1200,
wait=True
)
- 测试总结
Payload 示例:
def invoke_voxtral(self, endpoint: str, audio_data: dict) -> tuple[float, Optional[str]]:
"""调用 Voxtral 端点 (Mini 和 Small 格式相同)"""
payload = {
"transcription": {
"audio": {"data": audio_data["base64"]},
"language": "en",
"temperature": 0.0
}
}
start = time.time()
try:
resp = self.sm_runtime.invoke_endpoint(
EndpointName=endpoint,
ContentType="application/json",
Body=json.dumps(payload)
)
result = json.loads(resp["Body"].read().decode("utf-8"))
latency = time.time() - start
# Voxtral 返回格式: result['transcription']['text']
text = result.get("transcription", {}).get("text", "")
return latency, text
except Exception as e:
return time.time() - start, None
Single-request latency
| Audio duration |
Mean (ms) |
P50 (ms) |
P95 (ms) |
P99 (ms) |
QPS |
| 15s |
656 |
656 |
658 |
658 |
1.52 |
| 30s |
1055 |
1052 |
1058 |
1104 |
0.95 |
| 60s |
1598 |
1597 |
1600 |
1607 |
0.63 |
Throughput (QPS) under concurrency
| Audio duration |
C=1 |
C=5 |
C=10 |
C=20 |
| 15s |
1.52 |
1.55 |
1.55 |
1.56 |
| 30s |
0.95 |
0.96 |
0.96 |
0.96 |
| 60s |
0.63 |
0.64 |
0.64 |
0.63 |
Average latency (ms) under concurrency
| Audio duration |
C=1 |
C=5 |
C=10 |
C=20 |
| 15s |
657 |
3116 |
6004 |
11012 |
| 30s |
1055 |
5013 |
9670 |
17842 |
| 60s |
1596 |
7555 |
14624 |
27057 |
NVIDIA Parakeet
nvidia/parakeet-tdt-0.6b-v2 是 NVIDIA 推出的轻量级 ASR 模型,参数规模约 6 亿,主打超高吞吐与低延迟,适合在单卡 GPU 上服务多路语音流。它采用端到端 Transformer‑Transducer/CTC 风格架构,对长语音与流式场景(电话录音、会议音频、在线语音流)做了针对性优化,在保持商业可用识别准确率的同时,把推理时间压缩到远低于实时的量级,因此非常适合作为实时或近实时语音转录服务的“工业级引擎”。
本文使用自定义部署镜像,通过SageMaker AI 部署实时推理端点。
- 镜像Dockerfile 参考 Github repo
# Parakeet ASR - SageMaker 自定义容器
# 基于 NVIDIA NeMo 官方镜像 (需要 CUDA 12.x, g6e 支持)
FROM nvcr.io/nvidia/nemo:24.07
# 环境变量
ENV PYTHONUNBUFFERED=1
ENV PYTHONDONTWRITEBYTECODE=1
ENV HF_HOME=/tmp/hf_cache
ENV TORCH_HOME=/tmp/torch_cache
ENV NEMO_CACHE_DIR=/tmp/nemo_cache
# 安装 Web 服务依赖
RUN pip install --no-cache-dir \
flask>=3.0.0 \
gunicorn>=21.0.0 \
boto3>=1.35.0 \
requests>=2.31.0 \
soundfile>=0.12.1
# 创建目录
RUN mkdir -p /opt/ml/model /opt/ml/code /tmp/hf_cache /tmp/torch_cache /tmp/nemo_cache
# 复制推理代码
COPY serve.py /opt/ml/code/serve.py
# 工作目录
WORKDIR /opt/ml/code
# 暴露端口
EXPOSE 8080
# 健康检查
HEALTHCHECK --interval=30s --timeout=10s --start-period=300s --retries=3 \
CMD curl -f http://localhost:8080/ping || exit 1
# 启动服务
ENTRYPOINT ["python", "/opt/ml/code/serve.py"]
- 推理代码参考
# 启动时加载模型
logger.info("Starting Parakeet ASR server...")
load_model()
# 启动 Flask 服务
port = int(os.environ.get("SAGEMAKER_BIND_TO_PORT", 8080))
logger.info(f"Starting server on port {port}")
# 生产环境用 gunicorn
if os.environ.get("USE_GUNICORN", "false").lower() == "true":
import gunicorn.app.base
class StandaloneApplication(gunicorn.app.base.BaseApplication):
def __init__(self, app, options=None):
self.options = options or {}
self.application = app
super().__init__()
def load_config(self):
for key, value in self.options.items():
self.cfg.set(key.lower(), value)
def load(self):
return self.application
options = {
"bind": f"0.0.0.0:{port}",
"workers": 1,
"timeout": 300,
"keepalive": 60,
}
StandaloneApplication(app, options).run()
- 执行部署
# 1. 创建模型
print("\nStep 1: 创建 SageMaker Model...")
sm.create_model(
ModelName=model_name,
PrimaryContainer={
"Image": IMAGE_URI,
"Mode": "SingleModel",
"Environment": {
"SAGEMAKER_BIND_TO_PORT": "8080",
}
},
ExecutionRoleArn=ROLE,
)
print(f"✓ Model created: {model_name}")
# 2. 创建端点配置
print("\nStep 2: 创建 Endpoint Config...")
sm.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[{
"VariantName": "primary",
"ModelName": model_name,
"InstanceType": INSTANCE_TYPE,
"InitialInstanceCount": 1,
"ContainerStartupHealthCheckTimeoutInSeconds": 600, # 10分钟启动超时
}]
)
print(f"✓ Endpoint config created: {endpoint_config_name}")
# 3. 创建端点
print("\nStep 3: 创建 Endpoint...")
print("这需要 5-10 分钟,请耐心等待...")
sm.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)
- 测试总结
Payload 示例:
def invoke_parakeet(self, endpoint: str, audio_data: dict) -> tuple[float, Optional[str]]:
"""调用 Parakeet 端点"""
payload = {
"audio": {"data": audio_data["base64"]},
"timestamps": False
}
start = time.time()
try:
resp = self.sm_runtime.invoke_endpoint(
EndpointName=endpoint,
ContentType="application/json",
Body=json.dumps(payload)
)
result = json.loads(resp["Body"].read().decode("utf-8"))
latency = time.time() - start
return latency, result.get("text", "")
except Exception as e:
return time.time() - start, None
Single-request latency
| Audio duration |
Mean (ms) |
P50 (ms) |
P95 (ms) |
P99 (ms) |
QPS |
| 15s |
74 |
74 |
77 |
77 |
13.45 |
| 30s |
84 |
84 |
88 |
89 |
11.83 |
| 60s |
133 |
134 |
139 |
141 |
7.51 |
Throughput (QPS) under concurrency
| Audio duration |
C=1 |
C=5 |
C=10 |
C=20 |
| 15s |
13.84 |
8.54 |
3.88 |
2.52 |
| 30s |
11.86 |
3.95 |
2.04 |
2.44 |
| 60s |
7.6 |
4.98 |
1.61 |
1.57 |
Average latency (ms) under concurrency
| Audio duration |
C=1 |
C=5 |
C=10 |
C=20 |
| 15s |
72 |
241 |
447 |
931 |
| 30s |
84 |
244 |
465 |
965 |
| 60s |
132 |
363 |
595 |
1078 |
总结
本文选取 Whisper Large‑v3 Turbo、Voxtral Mini 与 NVIDIA Parakeet 三个代表性小参数模型,在统一的 NVIDIA GPU + SageMaker Real‑time 端点 技术栈上完成了可复现的部署与基准测试:包括 JumpStart 一键部署、BYOC 自定义镜像、端点调用 payload 示范,以及对不同音频长度和并发条件下的延迟与吞吐进行量化对比。 推荐选型建议:Parakeet 适合作为高吞吐转写引擎,Whisper Turbo 适合多语种、体验优先的实时字幕场景,Voxtral Mini 则更适合需要“转录 + 摘要/问答”一体化处理的语音理解型应用,为企业在不同业务场景下平衡延迟、精度和算力成本提供了直接可用的参考坐标。
面向生产环境,推荐将NVIDIA 推理 GPU L4/L40S 等 (亚马逊云科技 G6、G6e 等实例类型) 与 SageMaker 实时端点 结合使用:以 L4 承载单一 ASR 服务,以 L40S 承载“ASR+LLM”等复合工作负载;在平台层使用 SageMaker 的多模型端点和自动扩缩容,统一托管 ASR 与文本模型,并依据 QPS 与 GPU 利用率动态调整实例数,配合监控和实时指标探测,实现在保证端到端延迟和稳定性的前提下持续优化资源利用率和整体 TCO。
参考
- https://huggingface.co/nvidia/parakeet-tdt-0.6b-v2
- https://huggingface.co/mistralai/Voxtral-Mini-3B-2507
- https://huggingface.co/openai/whisper-large-v3-turbo
- https://aws.amazon.com/blogs/machine-learning/deploy-mistral-ais-voxtral-on-amazon-sagemaker-ai/
- https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html
- https://aws.amazon.com/ec2/instance-types/g6e/
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |