背景
通常来说,云平台的网络运维人员在工作中常需要对网络流量进行精确监控和分析,例如精确到源/目的IP地址,端口号,传输层协议的流量。NAT Gateway是亚马逊云科技在VPC环境中提供的一种网络地址转换 (NAT) 服务,用户使用NAT Gateway以便私有子网中的实例可以连接到 VPC 外部的服务,例如更新软件、安装补丁或者调用其他公有服务接口等。NAT Gateway的网络流量是整体流量中很重要的一部分,本文主要介绍对NAT Gateway网络流量的数据分析与可视化方案。
亚马逊云科技提供的VPC Flow Logs对经过VPC中的弹性网络接口(Elastic Network Interfaces,即ENI)的网络流量的详细五元组信息进行监控和记录,可有效用于观测网络流量变化趋势,辅助调查诊断网络问题。本文将采用VPC Flow Logs的方式来对VPC中通过NAT Gateway的网络流量进行详细的分析和查看。
本文介绍的解决方案将会使用Amazon S3、Amazon Lambda、Amazon EventBridge、Amazon Athena、Amazon Glue和Amazon QuickSight等云服务,提供了一种基于VPC Flow Logs对NAT Gateway的流量进行分析与可视化的方案,并将每日流量排名历史数据以CSV形式归档至S3存储桶。解决方案方案使用Parquet压缩格式和按小时对数据作分区,使用Amazon EventBridge定期执行Lambda函数执行预加载当前时间点未来1天的数据分区和删除7天前的旧分区的操作,以提高查询效率并降低查询成本。
方案概览
本方案实现所涉及的 Amazon 服务以及整体架构如下所示,整个方案完全采用Serverless架构,用户无需创建任何的服务器或者基础设施资源,就可以将网络流量分析和展示快速地构建起来。

解决方案整个架构主要分为三个部分:
- 首先是中间核心的VPC Flow Logs数据流。
开启日志后会存储到S3存储桶中,然后通过Athena服务进行查询,再通过Quicksight BI工具进行可视化展现,供网络运维人员使用。
- 上面的部分通过EventBridge来操作Glue中的数据分区。
PartitionHandler实际包含了两个Lambda函数:add_partition和delete_partition。add_partition函数在每天23:00提前创建第二天的分区,以使Athena能够在第二天查询当天的Flow Logs。因Flow Logs设置了7天从S3中删除,delete_partition在每天凌晨1:00删除7天前的分区,以避免Athena加载不存在数据的空分区时,影响查询性能;
- 下面的部分是对网络流量数据的归档。
由于网络监控过程中主要关注当前或近期的数据,所以Flow Logs存储的S3存储桶设置过期策略为7天后过期,删除,而每天凌晨2:00执行的Lambda函数 ArchiveFileHandler 对昨天的数据进行存档至S3,供历史查询需要,如上图中 ArchiveFileHandler所示,该Lambda 执行用户自定义的Athena查询语句(本文示例中,记录流经NAT Gateway的流量排名前100的源/目的IP地址)。
环境搭建
创建Nat Gateway的VPC Flow Logs
- 建立一个S3 Bucket用于存储NAT Gateway flow log,例如 nat-flowlog-bucket;
- 为需要监测的NAT Gateway创建VPC flow log:
- Filter: All
- Maximum aggregation interval: 10 minutes
- Destination: Send to an Amazon S3 bucket
- Log record format: select custom format,本例中勾选所有fields,实际根据需要设定
- Log file format: Parquet
- Hive-compatible S3 prefix Enable
- Partition logs by time: Every 1 hour (60 minutes) ,本例中选择按小时分区,实际根据需要设定
设置S3 lifecycle为7天后删除。
在Athena中创建查询VPC Flow Logs的表
Athena中运行如下建表语句,创建用于分析VPC Flow Logs的外表 nat_flowlog_table。
CREATE EXTERNAL TABLE `nat_flowlog_table`(
`version` int,
`account_id` string,
`interface_id` string,
`srcaddr` string,
`dstaddr` string,
`srcport` int,
`dstport` int,
`protocol` int,
`packets` bigint,
`bytes` bigint,
`start` bigint,
`end` bigint,
`action` string,
`log_status` string,
`vpc_id` string,
`subnet_id` string,
`instance_id` string,
`tcp_flags` int,
`type` string,
`pkt_srcaddr` string,
`pkt_dstaddr` string,
`az_id` string,
`region` string,
`sublocation_type` string,
`sublocation_id` string,
`pkt_src_aws_service` string,
`pkt_dst_aws_service` string,
`traffic_path` int,
`flow_direction` string)
PARTITIONED BY (
`year` string,
`month` string,
`day` string,
`hour` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://nat-flowlog-bucket/AWSLogs/aws-account-id=111111111111/aws-service=vpcflowlogs/aws-region=us-east-1'
TBLPROPERTIES (
'skip.header.line.count'='1',
'transient_lastDdlTime'='1634953530')
创建每天自动加载第2天的分区,以及删除7天前的分区的Lambda函数
- 创建Lambda使用的IAM Role:PartitionHandlerRole,设置Trusted entity为Lambda,并添加如下Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:us-east-1:111111111111:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-east-1:111111111111:log-group:/aws/lambda/add_partition:*",
"arn:aws:logs:us-east-1:111111111111:log-group:/aws/lambda/delete_partition:*"
]
},
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetPartition",
"glue:GetTables",
"glue:GetPartitions",
"glue:BatchGetPartition",
"glue:GetDatabases",
"glue:GetTable",
"glue:BatchCreatePartition",
"glue:BatchDeletePartition"
],
"Resource": "*"
}
]
}
- 创建Lambda函数add_partition,Role使用步骤1中创建的PartitionHandlerRole。并设置Event Bridge触发条件为 cron(0 23 * * ? *),即每天23:00执行一次。
import json
import boto3
import logging
from datetime import datetime
from datetime import timedelta
ACCOUNT_ID = "111111111111"
DB_NAME = "default"
TABLE_NAME = "nat_flowlog_table"
log = logging.getLogger()
log.setLevel('INFO')
client = boto3.client('glue')
def lambda_handler(event, context):
event_time = event["time"]
event_datetime = datetime.strptime(event_time, "%Y-%m-%dT%H:%M:%SZ")
log.info(str(event_datetime))
event_datetime = event_datetime + timedelta(days=1)
log.info(str(event_datetime))
year = str(event_datetime.year)
month = f"{event_datetime.month:02}"
day = f"{event_datetime.day:02}"
try:
response2 = client.get_table(
CatalogId=ACCOUNT_ID,
DatabaseName=DB_NAME,
Name=TABLE_NAME
)
except Exception as error:
print("cannot fetch table as " + str(error))
exit(1)
# Parsing table info required to create partitions from table
input_format = response2['Table']['StorageDescriptor']['InputFormat']
output_format = response2['Table']['StorageDescriptor']['OutputFormat']
table_location = response2['Table']['StorageDescriptor']['Location']
serde_info = response2['Table']['StorageDescriptor']['SerdeInfo']
partition_keys = response2['Table']['PartitionKeys']
print(input_format)
print(output_format)
print(table_location)
print(serde_info)
print(partition_keys)
create_dict = []
for hour_index in range(24):
log.info(str(hour_index))
hour = f"{hour_index:02}"
log.info(str(hour))
part_location = "s3://nat-flowlog-bucket/AWSLogs/aws-account-id=111111111111/aws-service=vpcflowlogs/aws-region=us-east-1/year={}/month={}/day={}/hour={}/".format(year, month, day, hour)
input_json = {
'Values': [
year, month, day, hour
],
'StorageDescriptor': {
'Location': part_location,
'InputFormat': input_format,
'OutputFormat': output_format,
'SerdeInfo': serde_info
}
}
create_dict.append(input_json)
log.info(json.dumps(create_dict))
create_partition_response = client.batch_create_partition(
CatalogId=ACCOUNT_ID,
DatabaseName=DB_NAME,
TableName=TABLE_NAME,
PartitionInputList=create_dict
)
log.info(json.dumps(create_partition_response))
return {
'statusCode': 200,
'body': create_partition_response
}
- 创建Lambda函数delete_partition,Role使用步骤1中创建的PartitionHandlerRole。并设置Event Bridge触发条件为 cron(0 1 * * ? *),即每天凌晨1:00执行一次。
import json
import boto3
import logging
from datetime import datetime
from datetime import timedelta
log = logging.getLogger()
log.setLevel('INFO')
ACCOUNT_ID = "111111111111"
DB_NAME = "default"
TABLE_NAME = "nat_flowlog_table"
client = boto3.client('glue')
def lambda_handler(event, context):
event_time = event["time"]
event_datetime = datetime.strptime(event_time, "%Y-%m-%dT%H:%M:%SZ")
log.info(str(event_datetime))
event_datetime = event_datetime - timedelta(days=7)
log.info(str(event_datetime))
year = str(event_datetime.year)
month = f"{event_datetime.month:02}"
day = f"{event_datetime.day:02}"
delete_dict = []
for hour_index in range(24):
hour = f"{hour_index:02}"
delete_json = {
'Values': [
year, month, day, hour
]
}
delete_dict.append(delete_json)
log.info(json.dumps(delete_dict))
delete_partition_response = client.batch_delete_partition(
CatalogId=ACCOUNT_ID,
DatabaseName=DB_NAME,
TableName=TABLE_NAME,
PartitionsToDelete=delete_dict
)
log.info(json.dumps(delete_partition_response))
return {
'statusCode': 200,
'body': delete_partition_response
}
建立定时归档Flow Logs查询结果的Lambda函数
- 创建Lambda使用的IAM Role:ArchiveFlowLogsRole,添加Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"athena:GetWorkGroup",
"glue:GetPartition",
"athena:StartQueryExecution",
"glue:GetPartitions",
"athena:StopQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults",
"athena:ListQueryExecutions",
"glue:GetTable"
],
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"logs:CreateLogStream",
"s3:ListBucket",
"s3:GetBucketLocation",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:s3:::nat-log-output",
"arn:aws:s3:::nat-log-output/*",
"arn:aws:logs:us-east-1:111111111111:log-group:/aws/lambda/archive_flowlogs:*"
]
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket",
"logs:CreateLogGroup",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:logs:us-east-1:111111111111:*",
"arn:aws:s3:::nat-flowlog-bucket",
"arn:aws:s3:::nat-flowlog-bucket/*"
]
}
]
}
- 创建Lambda函数archive_flowlogs,代码如下。并设置EventBridge触发条件为 cron(0 2 * * ? *),即每天凌晨2:00执行一次该函数,去归档昨天的Flow logs查询结果到S3桶 nat-log-output (例如2月10号存档2月9号的Log到 s3://nat-log-output/2022-02-09/2022-02-09.csv)
import json
import logging
from datetime import datetime
from datetime import timedelta
import time
import boto3
log = logging.getLogger()
log.setLevel('INFO')
RETRY_COUNT = 10
DATABASE = 'default'
TABLE = 'nat_flowlog_table'
S3_BUCKET = 'nat-log-output'
def get_athena_query_result(client, query_execution_id, date_dir):
for i in range(1, 1 + RETRY_COUNT):
try:
query_status = client.get_query_execution(QueryExecutionId=query_execution_id)
except Exception as e:
log.error(str(e))
raise e
query_execution_status = query_status['QueryExecution']['Status']['State']
if query_execution_status == 'SUCCEEDED':
source_obj = '{}/{}.csv'.format(date_dir, query_execution_id)
#print(source_obj)
target_obj = '{}/{}.csv'.format(date_dir, date_dir)
# print(target_obj)
s3copy = copy_s3_obj(S3_BUCKET, source_obj, S3_BUCKET, target_obj)
# print(s3copy)
break
if query_execution_status == 'FAILED':
log.error("QUERY STATUS:" + query_execution_status + query_status['QueryExecution']['Status']['StateChangeReason'])
raise Exception("QUERY STATUS:" + query_execution_status + query_status['QueryExecution']['Status']['StateChangeReason'])
else:
#print("QUERY STATUS:" + query_execution_status)
time.sleep(i)
else:
client.stop_query_execution(QueryExecutionId=query_execution_id)
raise Exception('[get_athena_query_result] TIME OUT with retry ' + str(RETRY_COUNT))
def copy_s3_obj(source_bucket,source_object,target_bucket,target_object):
s3 = boto3.resource('s3')
copy_source = {
'Bucket': source_bucket,
'Key': source_object
}
target_bucket = s3.Bucket(target_bucket)
target_obj = target_bucket.Object(target_object)
target_obj.copy(copy_source)
def lambda_handler(event, context):
event_time = event["time"]
event_datetime = datetime.strptime(event_time, "%Y-%m-%dT%H:%M:%SZ")
log.info(str(event_datetime))
event_datetime = event_datetime - timedelta(days=1) # archive yesterday's data
log.info(str(event_datetime))
year = str(event_datetime.year)
month = f"{event_datetime.month:02}"
day = f"{event_datetime.day:02}"
date_dir = f"{year}-{month}-{day}"
# s3_output = 's3://bytedance-s3-base-de-vpc-flowlog-output/natgateway/'
s3_output = 's3://{}/{}/'.format(S3_BUCKET,date_dir)
client = boto3.client('athena')
sql = '''
select pkt_srcaddr, pkt_dstaddr, srcaddr, dstaddr, flow_direction, sum(bytes) as bytes
from {}.{}
where year = '{}' and month = '{}' and day = '{}'
group by 1,2,3,4,5
order by bytes desc
limit 100'''.format(DATABASE, TABLE, year, month, day)
# execution
try:
response = client.start_query_execution(
QueryString=sql,
QueryExecutionContext={
'Database': DATABASE
},
ResultConfiguration={
'OutputLocation': s3_output
}
)
except Exception as e:
log.error(str(e))
raise e
# get query execution id
query_execution_id = response['QueryExecutionId']
# get execution status
get_athena_query_result(client, query_execution_id, date_dir)
集成QuickSight
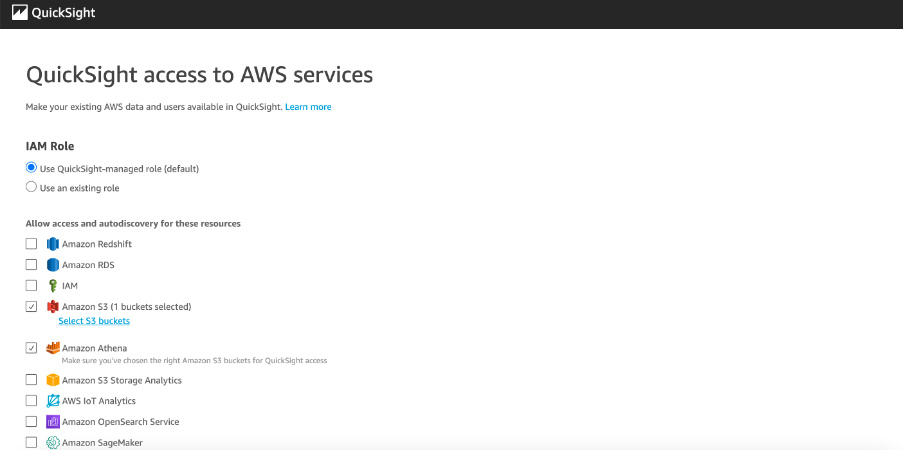
添加Quicksight对Athena和S3 (存放VPC Flow Logs的桶) 的权限
进入quicksight主界面,在右上角点击用户名,选择“Manage QuickSight” -> “Security & permissions”, 在 “QuickSight access to AWS services”处,点击Manage,勾选Athena与存放的VPC Flow Logs的S3桶。


- 创建DataSet和Analysis
在Athena中创建用于QuickSight展示的视图,其中对Flow Logs条目的start和end时间戳按5分钟 (300秒) 间隔做聚合:
create
or replace view de_nat_flowlog as
select
"interface_id",
"srcaddr",
"dstaddr",
"pkt_srcaddr",
"pkt_dstaddr",
from_unixtime(start-MOD("start",300)) AS starttime,
from_unixtime(end-MOD("end",300)) AS endtime,
flow_direction,
sum(bytes) as bytes
from "AwsDataCatalog"."default"."nat_flowlog_table"
group by 1,2,3,4,5,6,7,8
在QuickSight中新建DataSet, 选择Athena, 选择分析Flow Logs的DataBase和Table,点击Select,选择import to SPICE for quicker analysis。


选择右上角的Publish & visualize,由此DataSet 创建QuickSight Analysis和Visual。
下图为所有流向公网的流量的线图。

下图为源为NAT Gateway的IP,目的为公网IP的流量桑基图。

下图为通过filter实现的,主要关注的公网IP的流量日变化图。

下表为详细数据表格,可供排序分析,或下载CSV文件等。

- 设置Dataset SPICE的数据刷新时间:
为Dataset里”Schedule a refresh”,新建一个Hourly/ Daily 的刷新,例如每天13:59 刷新。当然也可以选择Direct Query Athena而不使用SPICE,使每次打开Analysis页面时都刷新并加载最新的源数据,这会增加Athena查询成本和每次刷新数据时的等待时间。可根据实际情况对该选项进行选择。

总结
本解决方案提供了一种对流经NAT Gateway的流量进行分析与可视化的方案。通过亚马逊云科技提供的网络流量分析工具VPC Flow Logs,以及Serverless的数据分析工具Amazon Athena、Amazon Glue与Amazon QuickSight,建立了一套方便网络运维人员日常观测网络流量,或查询与诊断经NAT的网络问题的解决方案。文中的查询使用了源/目的IP地址的流量作为查询目标,实际使用时可根据应用场景灵活地选择多种指标。
本篇作者