亚马逊AWS官方博客
给 Openclaw瘦身-利用Nova MME 和 S3 Vector实现Skill按需召回
摘要:本文介绍一种针对 OpenClaw 的智能Skills召回方案,基于 Amazon Bedrock Nova Multimodal Embeddings 和 Amazon S3 Vector,通过向量语义检索实现skill按需召回,将每次对话注入的技能描述 Token 降低约 90%,并提升响应速度。
一、背景概述
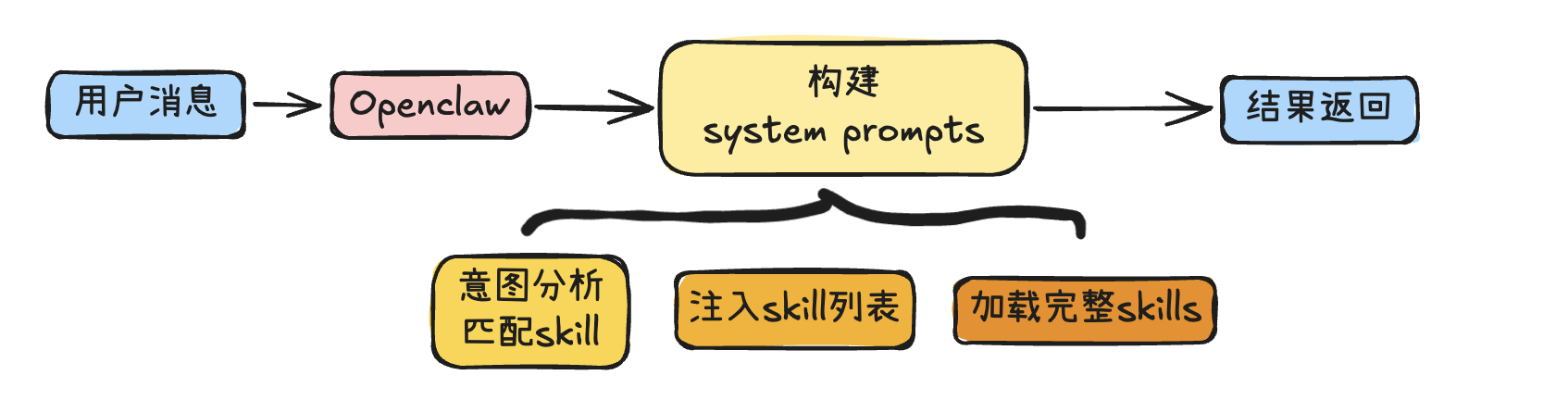
随着 OpenClaw 的生态日趋丰富,越来越多开发者为自己的 OpenClaw 实例配置了大量 Skills 来扩展能力边界。然而,一个容易被忽视的问题随之浮现:当skill数量从个位数增长到数十甚至上百个时,每次对话都将全部技能描述注入到 System Prompt 中,造成了显著的 Token 浪费和成本攀升。
1.1 OpenClaw 的 Skills 机制
OpenClaw 采用 AgentSkills 规范的技能目录结构。每个技能是一个包含 SKILL.md 文件的目录,通过 YAML frontmatter 定义名称、描述和元数据。OpenClaw 从三个位置加载技能,当同名技能存在时,按以下优先级覆盖(从高到低):
- Workspace Skills:位于工作空间目录下的 skills/ 目录,优先级最高
- Managed Skills:位于 ~/.openclaw/skills/,跨工作空间共享
- Bundled Skills:随 OpenClaw 安装包内置
当存在可用技能时,OpenClaw 会在 System Prompt 中注入一段紧凑的 XML 列表:
<available_skills>
<skill>
<name>feishu-doc</name>
<description>Feishu document read/write operations...</description>
<location>~/.openclaw/extensions/feishu/skills/feishu-doc/SKILL.md</location>
</skill>
<!-- 更多 skills... -->
</available_skills>根据 OpenClaw 官方文档,这段列表的 Token 开销是确定性的,其计算公式为:
总字符数 = 195(基础开销)+ 每个 Skill 的(97 + name 长度 + description 长度 + location 长度)
[图1] |
模型在识别到相关技能后,通过 read 工具按需加载对应 SKILL.md 的完整内容来获取详细指令,当技能数量增长到 30、50 甚至更多时,仅技能列表本身就会产生可观的 Token 消耗。一个直观的例子:当用户说”帮我查飞书文档”时,System Prompt 中注入了天气查询、音乐播放、邮件管理等 50 个技能的描述,其中只有 feishu-doc、feishu-wiki、feishu-drive 这 3 个与请求相关。这意味着绝大部分技能描述 Token 被浪费了。
二、解决方案
本文介绍一种针对 OpenClaw 的智能Skills召回方案ISS (Intelligent Skill Selection),基于 Amazon Bedrock Nova Multimodal Embeddings 和 Amazon S3 Vector,通过向量语义检索实现skill按需召回,将每次对话注入的技能描述 Token 降低约 90%,并提升响应速度。其中:
- Amazon Nova Multimodal Embeddings:提供高质量的文本向量化能力,将技能描述和用户查询映射到 1024 维向量空间,支持语义级别的相似度计算。单次嵌入生成延迟约 150ms,按调用计费,无需维护独立的嵌入服务。
- Amazon S3 Vector :作为向量数据的持久化存储层,无需管理向量数据库实例或索引,S3 作为全托管对象存储自动处理可用性和持久性。每个技能的向量以 JSON 文件形式存储,包含技能元数据和 1024 维嵌入向量。客户端在运行时加载向量并在本地执行余弦相似度计算。
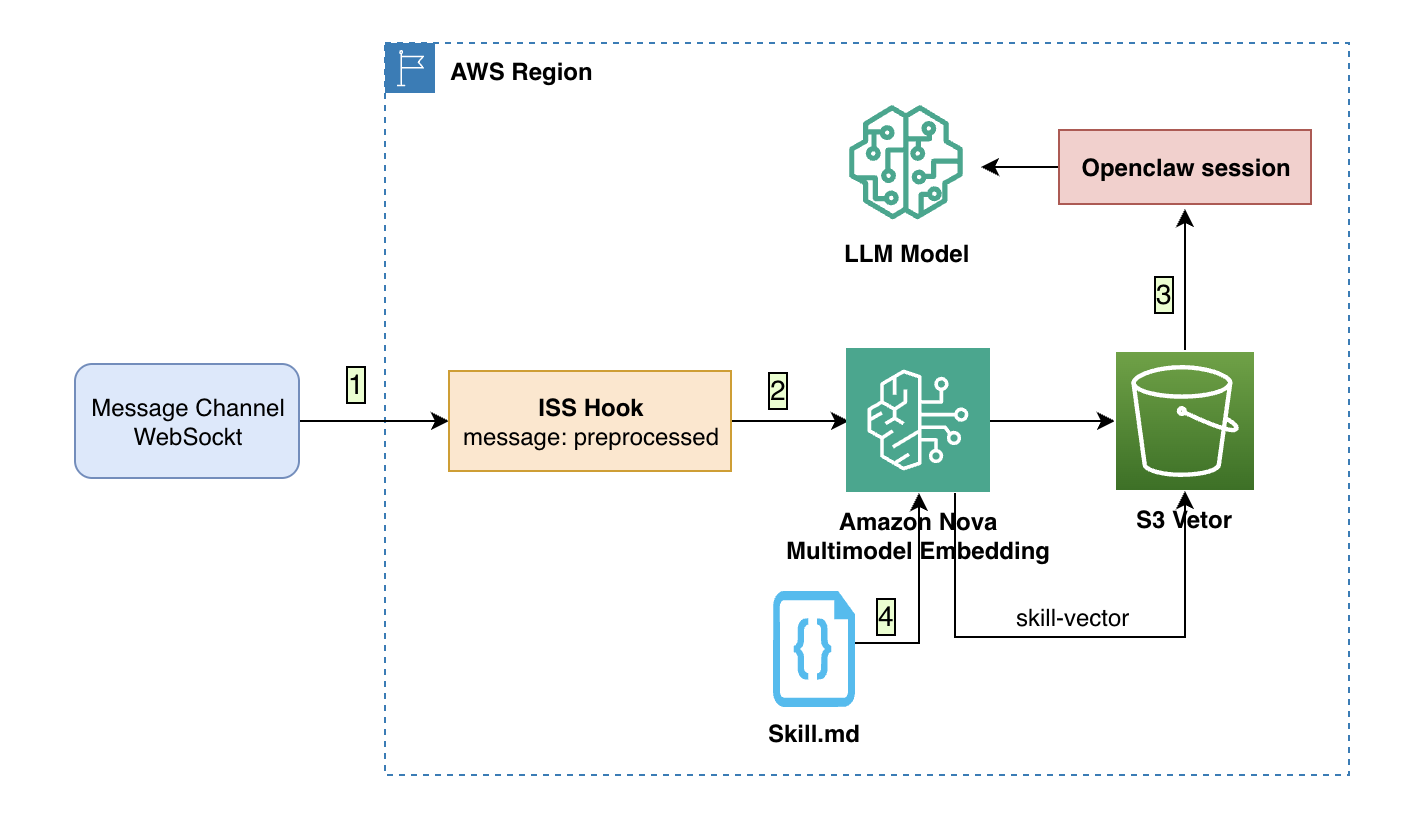
整体架构图如下:
[图2] |
- ISS Hook在 `message:preprocessed` 事件(消息预处理完成后、发给 Agent 前)拦截消息
- Nova MME 模型将用户消息转为向量
- 检索skills,在客户端计算余弦相似度取 Top-K skills,将K个完整skills注入session
- skill 向量库构建: 解析 SKILL.md 使用Nova MME进行skill向量化,并存入s3 Vector
三、模块设计详解
ISS 由三个完全解耦的模块组成
3.1 模块一 : vectorize-skills 离线向量化工具
这是一个独立的 Node.js 命令行工具,职责是扫描所有 OpenClaw 技能目录,提取每个 SKILL.md 的元数据(名称、描述、关键词),拼接为文本后调用 Amazon Bedrock Nova MME 生成 1024 维嵌入向量,最后以 JSON 格式上传到 S3。通过比较本地 SKILL.md 文件的修改时间(mtime)与 S3 中已有向量对象的上传时间,智能跳过未修改的技能,避免不必要的 API 调用。
async function isSkillModified(skillMdPath, existingVector) {
if (!existingVector.exists) {
return true; // 新 skill,需要向量化
}
const stats = await fs.stat(skillMdPath);
return stats.mtime > existingVector.lastModified;
}const text = `${metadata.name} ${metadata.description} ${metadata.keywords.join(' ')}`;
const vector = await getEmbedding(text);S3 中存储的每个技能 JSON 文件结构如下:
{
"skill_name": "feishu-doc",
"description": "Feishu document read/write operations...",
"trigger_keywords": ["feishu", "doc", "飞书", "文档"],
"location": "~/.openclaw/extensions/feishu/skills/feishu-doc/SKILL.md",
"vector": [0.123, -0.456, 0.789, ...],
"metadata": {
"version": "1.0.0",
"vectorized_at": "2026-03-15T10:30:00.000Z"
}
}3.2 模块二:ISS Hook 消息拦截器
OpenClaw 提供了基于事件的 Hook 系统,允许开发者在消息处理流水线的各个阶段注入自定义逻辑。ISS 利用 message:preprocessed 事件——该事件在媒体理解(音频转写、图片描述、链接摘要)完成之后、消息发送给 Agent 之前触发。
Hook 通过标准的 OpenClaw Hook 目录结构定义,包含 HOOK.md 元数据文件和 handler.ts 处理函数。HOOK.md 中的元数据声明了监听的事件和依赖:
---
name: iss
description: "Intelligent Skill Selection - 智能召回相关 skills 并动态注入"
metadata:
{"openclaw": {"emoji": "????", "events": ["message:preprocessed"], "requires": {"bins": ["node"], "env": ["OPENCLAW_SKILLS_VECTOR_BUCKET"]}}}
---handler.ts 在每条用户消息到达时执行以下流程:提取用户消息文本,调用 ISS Extension 进行向量检索,将召回的技能构建为 available_skills XML 块,注入到 event.context.bodyForAgent 中:
const handler = async (event) => {
if (event.type !== 'message' || event.action !== 'preprocessed') {
return;
}
await initializeISS();
let userQuery = event.context?.bodyForAgent || event.context?.body || '';
const relevantSkills = await retriever.retrieveRelevantSkills(userQuery);
if (relevantSkills.length > 0) {
const skillsBlock = buildSkillsBlock(relevantSkills);
event.context.bodyForAgent = skillsBlock + '\n\n' + event.context.bodyForAgent;
}
};3.3 模块三:ISS Extension 核心召回逻辑
这是共享的检索逻辑模块,被 ISS Hook 调用。核心类 SkillRetriever 封装了完整的召回流程。调用 Amazon Bedrock Nova MME 生成查询向量:
async getEmbedding(text) {
const command = new InvokeModelCommand({
modelId: 'amazon.nova-2-multimodal-embeddings-v1:0',
body: JSON.stringify({
schemaVersion: 'nova-multimodal-embed-v1',
taskType: 'SINGLE_EMBEDDING',
singleEmbeddingParams: {
embeddingPurpose: 'GENERIC_RETRIEVAL',
embeddingDimension: 1024,
text: { truncationMode: 'NONE', value: text }
}
})
});
const response = await this.bedrockClient.send(command);
const result = JSON.parse(new TextDecoder().decode(response.body));
return result.embeddings[0].embedding;
}从 S3 加载所有技能向量,进行余弦相似度计算。过滤、排序并返回 Top-K 个结果。
cosineSimilarity(vecA, vecB) {
let dotProduct = 0, normA = 0, normB = 0;
for (let i = 0; i < vecA.length; i++) {
dotProduct += vecA[i] * vecB[i];
normA += vecA[i] * vecA[i];
normB += vecB[i] * vecB[i];
}
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
}3.4 缓存策略
为降低延迟和成本,ISS 实现了两级缓存:
- 技能向量缓存:所有技能向量从 S3 加载后在内存中缓存 10 分钟(TTL),避免每条消息都请求 S3。
- 查询结果缓存:LRU 缓存(最大 100 条,TTL 1 小s时),相同查询直接返回缓存结果,完全跳过向量化和相似度计算。
3.5 运行时数据流
- 用户通过飞书/Telegram/Discord 等渠道发送消息(如”帮我查飞书文档”)
- OpenClaw Gateway 接收消息,完成媒体理解(音频转写、链接摘要等)
- 触发 message:preprocessed 事件,ISS Hook 拦截消息
- Hook 调用 ISS Extension 的 SkillRetriever
- SkillRetriever 调用 Nova MME 将用户查询向量化
- 从内存缓存(或 S3 Vector)加载所有技能向量
- 客户端计算余弦相似度,按分数降序排列
- 过滤低于阈值(0.2)的结果,取 Top-3
- 构建 available_skills XML 块,注入到消息体的 bodyForAgent 字段
- OpenClaw Agent 接收消息,只看到 3 个相关技能而非全部 50 个
- Agent 选择最匹配的技能(如 feishu-doc),用 read 工具加载其 SKILL.md 完整内容
- Agent 按照 SKILL.md 的指引完成任务并回复用户
四、效果对比
以 50 个技能、每个技能描述平均 120 tokens(含 name + description + location 的 XML 块)的典型场景为例,对比原生全量注入与 ISS 按需召回的 Token 消耗差异。
单轮对话对比:
- 原生方式(全量注入):50 skills × 120 tokens + 30 tokens 开销 = 6,030 tokens
- ISS 方式(Top-3 召回):3 skills × 120 tokens + 20 tokens 开销 = 380 tokens
- 单轮节省:5,650 tokens(93.7%)
多轮会话累积效果(10 轮对话,无 prompt cache):
Skills 描述注入在 System Prompt 中,每轮 API 调用都会重新发送完整的 system prompt。这意味着 skills 部分的 Token 消耗会随对话轮数线性增长,完整对话的token节约仍为93.7%
Prompt Cache 场景的影响:
如果使用 prompt caching(缓存命中时按约 1/10 价格计费),原生方式确实能降低后续轮次的开销。但 ISS 每轮的用户查询不同,召回结果可能变化,导致 system prompt 内容不完全一致,prompt cache 可能无法命中。这反而使原生方式在 cache 场景下有一定优势,但 ISS 的绝对节省量仍然显著。
ISS 自身开销几乎可以忽略:
ISS 每轮需调用一次 Nova MME Embedding API(约 $$0.00002/次)和偶尔的 S3 GetObject(缓存命中后不再请求),整个 10 轮会话的额外开销约$$0.0003,仅占节省金额的 0.2%。因此Skills 数量越多,节省比例越趋近于 1 – topK/N(此处为 1 – 3/50 = 94%)
五、总结
本文展示了一种针对 OpenClaw 的实用优化方案:利用向量语义检索将skill使用从”全量注入”转变为”按需召回”。通过 OpenClaw 的 Hook 机制在消息预处理阶段拦截并增强上下文,结合 Amazon Bedrock Nova MME 的向量化能力和 Amazon S3 Vector的持久化存储,实现了对 OpenClaw Agent 透明、对用户无感的智能技能选择。
该方案完全基于 AWS 托管服务构建,无需额外管理向量数据库等基础设施,部署简单,运维成本极低。三个模块完全解耦,可以独立开发、测试和部署。
➡️ 下一步行动:
相关产品:
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon Nova — 提供前沿智能和最高性价比的基础模型
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon S3 Vectors — 云原生向量存储
相关文章:
- 在Amazon EKS上部署OpenClaw AI Agent:基于Kata Containers的企业级沙箱实践
- OpenClaw 安全和功能增强实践
- 还在养龙虾(OpenClaw)吗?教你在 AWS 上让龙虾自己生龙虾
- OpenClaw 在电商平台的应用场景探索
- 构建专业化 AI 而不牺牲通用智能:Nova Forge 数据混合实战
六、相关资源
- ISS 项目 GitHub:https://github.com/CrazyCha/Intelligent-Skill-Selection
- Amazon Nova Embeddings:https://docs.aws.amazon.com/bedrock/latest/userguide/embeddings.html
- Amazon S3 Vectors:https://docs.aws.amazon.com/AmazonS3/latest/userguide/S3-Vectors.html
- OpenClaw 开源项目:https://github.com/openclaw/openclaw
- OpenClaw Skills 文档:https://docs.openclaw.ai/tools/skills
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
