亚马逊AWS官方博客
使用Graviton机型推理LLM模型实践指南
1. 背景介绍
在企业 AI 应用实践中,并非所有任务都需要部署参数量数百亿的大型模型。大量业务场景如工单分类与路由、客服评论情感分析、关键信息提取、实时文本翻译等,属于高频但相对简单的任务,这些场景对响应速度和成本更为敏感。AWS Graviton 处理器与 Qwen3 0.6B 轻量级模型的结合,为这类场景提供了一个极具性价比的推理解决方案。
通过在多种实例类型上的全面测试,我们发现 Graviton实例相比同配置的 Intel c7i.xlarge 实例,推理速度提升 42%,单次请求成本降低 31%,端到端延迟减少 23%。对于不需要复杂多轮推理的应用场景,基于 CPU 的 Graviton 实例提供了除 GPU 之外的另一种高性价比推理方案选择,为企业构建成本可控、性能优异的智能化服务提供了理想的技术基础。
1.1 AWS Graviton 处理器:为云端工作负载优化的 ARM 架构
AWS Graviton 是亚马逊云科技自研的基于 ARM 架构的处理器系列,专为云端工作负载优化设计。在机器学习推理任务中,Graviton 处理器展现出色的性能表现。相比同等性能的 x86 实例,Graviton 实例可以节省高达 20% 的成本,这对于需要长期运行推理服务的企业而言具有显著的经济价值。ARM 架构天然的低功耗特性使得 Graviton 处理器在性能功耗比方面具有明显优势,在相同计算能力下消耗更少的能源。
针对 AI 推理工作负载,Graviton 处理器提供了优化的内存带宽设计,为模型推理过程中的大量数据读写操作提供充足的带宽支持。Graviton 实例与 AWS 服务深度集成,包括 Amazon SageMaker、Amazon Elastic Container Service(Amazon ECS)、Amazon Elastic Kubernetes Service(Amazon EKS)等核心服务,为用户提供 seamless 的部署体验。这种原生的云集成能力使得基于 Graviton 的推理服务可以充分利用 AWS 生态系统的各项能力。
1.2 Qwen3 0.6B:轻量高效的大语言模型
Qwen3 0.6B 是阿里巴巴通义千问系列的轻量级大语言模型,采用基于 Transformer 的 decoder-only 架构设计。该模型拥有 6 亿参数规模,经过完整的预训练和后训练阶段优化,支持 32K tokens 的上下文长度。尽管参数量相对较小,Qwen3 0.6B 仍然保持了良好的语言理解能力,在多个评测基准上展现出令人印象深刻的性能表现。
从性能特点来看,Qwen3 0.6B 具有多项显著优势。模型的轻量化设计使其推理速度快,能够满足实时应用场景的响应要求。内存占用低是该模型的另一大特点,即使在资源受限的环境下也能稳定运行,这为边缘计算和私有化部署提供了可能。模型对中英文都有良好的支持,特别是在中文语境下表现突出。
根据图1官方评估结果,Qwen3 0.6B 在多个评测基准上的表现甚至超过了参数量更大的模型。在 MMLU 任务中,Qwen3 0.6B 获得了 52.81 的分数,在 Math & STEM 类任务的 GPQA 测试中得分 26.77,在 Coding 类任务的 EvalPlus 中达到 36.23 分。这些数据充分体现了模型在通用语言理解、数学推理和代码生成等多个维度的综合能力。对比 Gemma-3-1B(1B 参数)和 Qwen2.5-1.5B(1.5B 参数)等更大规模的模型,Qwen3 0.6B 在某些特定任务上展现出相当甚至更优的性能,证明了其训练和优化策略的有效性。
从应用场景角度看,Qwen3 0.6B 特别适合部署在边缘计算设备上,为终端用户提供本地化的 AI 能力。在实时对话系统中,模型的快速响应特性能够提供流畅的交互体验。对于文本分类和情感分析等任务,模型的轻量化特性使得大规模部署成为可能。此外,模型还适用于构建知识问答系统,为用户提供基于企业知识库的智能问答服务。
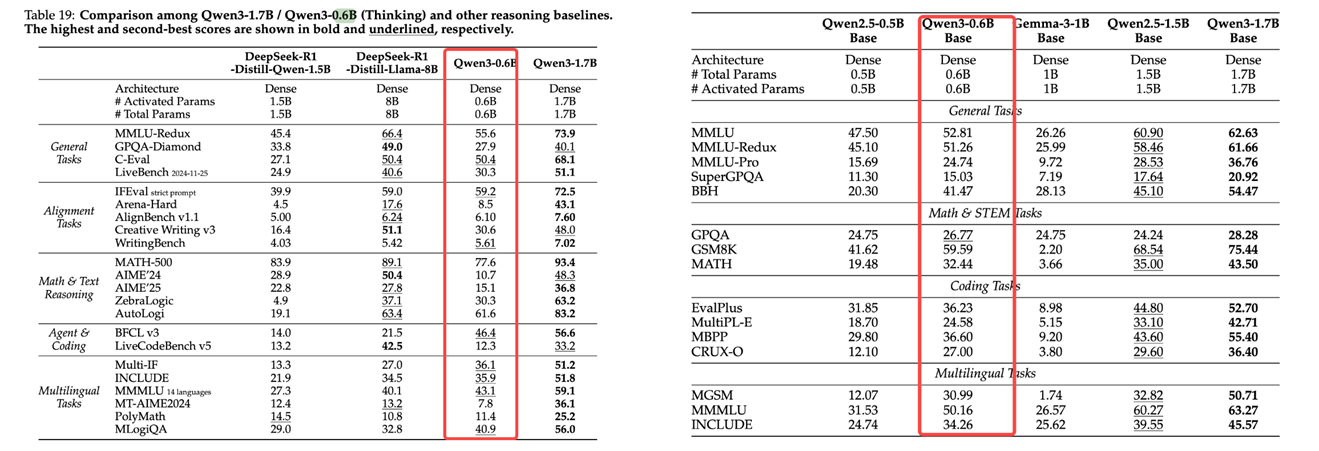 |
图1 Qwen3 系列模型评估结果
Qwen3 0.6B 与 Graviton 处理器的结合,为用户提供了一个成本效益极高的 LLM 推理解决方案。这一技术组合将 ARM 架构的能效优势与轻量级模型的资源友好特性相结合,在保持推理性能的同时显著降低了运营成本。在轻量级大语言模型推理场景中,AWS Graviton 处理器展现出显著的成本和性能优势。通过在多种实例类型上对 Qwen3 0.6B 模型进行全面测试,我们发现 Graviton 4 c8g.xlarge 实例相比同配置的 Intel c7i.xlarge 实例,推理速度提升 42%,单次请求成本降低 31%,端到端延迟减少 23%。对于文本分类、情感分析、工单路由、轻量级翻译等高频简单任务,基于 CPU 的 Graviton 实例提供了除 GPU 之外的另一种高性价比推理方案选择。
2. 部署方法
2.1方案架构
本方案提供了一个完整的部署流程,通过 Amazon SageMaker 和 Ollama 在 Graviton 实例上部署 Qwen3 0.6B 模型。这个方案的核心优势在于将 Ollama 的简便性与 Amazon SageMaker 的企业级能力相结合,既保留了 Ollama 在模型管理和推理方面的易用性,又获得了 SageMaker 在可扩展性、监控和运维方面的强大支持。
整体架构分为两个核心阶段。在镜像构建阶段(Image Build Phase),源代码首先存储在 Amazon Simple Storage Service(Amazon S3)中,AWS CodeBuild 项目从 S3 拉取源代码并执行容器镜像的构建过程。构建完成后,镜像被推送到 Amazon Elastic Container Registry(Amazon ECR)进行存储和版本管理。构建过程中的日志通过 Amazon CloudWatch 进行集中管理。使用 AWS CodeBuild 来构建 ARM 架构的容器镜像,避免了需要单独启动 Graviton 实例进行镜像打包的额外成本和复杂度。
在运行时阶段(Runtime Phase),客户端应用通过 Amazon SageMaker Endpoint 发起推理请求。SageMaker Endpoint 将请求路由到运行在 Graviton 实例上的容器。在 Graviton 实例内部,Ollama Runtime 负责模型的加载和推理执行,Qwen3 0.6B 模型以优化的方式运行在 ARM 架构上。这种架构使得推理服务可以充分利用 SageMaker 的自动扩缩容、流量分配和模型版本管理等能力。
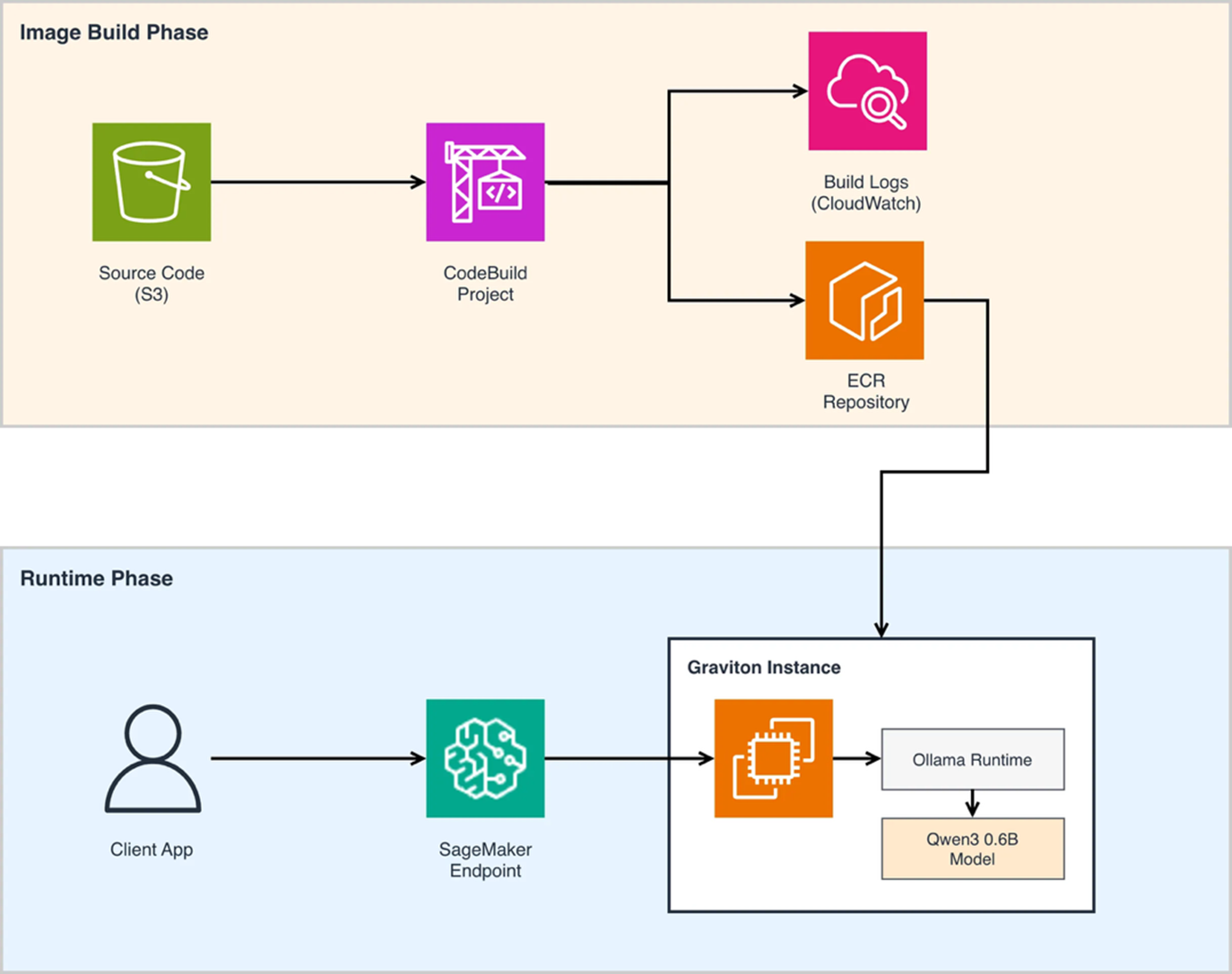 |
图2 在SageMaker上部署Ollama模型推理
2.2部署步骤
完整的部署代码已开源在 GitHub 仓库 ,用户可以通过 Jupyter Notebook 脚本一步步完成整个部署流程。以下章节将详细介绍部署过程中的关键步骤,涵盖从代码准备到推理调用的完整生命周期。
2.2.1. 克隆部署代码
首先从 GitHub 仓库获取部署所需的全部代码和配置文件:
2.2.2. 镜像打包
容器镜像封装了 Ollama 运行环境、模型推理代码以及与 SageMaker 集成所需的接口层。Dockerfile 基于 Ollama 官方镜像构建,并添加了 FastAPI 框架来实现与 Amazon SageMaker Endpoint 的协议适配。
镜像中的 FastAPI 应用实现了对高并发场景的支持,能够同时处理多个推理请求。端口 8080 是 SageMaker 推理容器的标准端口。方案使用 AWS CodeBuild 执行镜像构建,CodeBuild 支持原生的 ARM64 构建环境,可以直接构建适配 Graviton 处理器的容器镜像。
2.2.3. 创建和部署 SageMaker Endpoint
接下来需要创建 SageMaker 模型、Endpoint 配置,并部署 Endpoint。在模型配置中,需要指定容器镜像位置和环境变量,其中 OLLAMA_MODEL_ID 指定加载的模型,OLLAMA_NUM_PARALLEL 控制并行请求数量。在 Endpoint 配置中,明确指定使用 Graviton 实例类型(如 ml.c7g.xlarge),并将 ContainerStartupHealthCheckTimeoutInSeconds 设置为 1200 秒,因为首次启动时 Ollama 需要下载模型文件。
部署过程是异步的,可以通过轮询 API 监控部署状态。当状态从 “Creating” 变为 “InService” 时,Endpoint 即可开始处理推理请求。完整的代码实现请参考 GitHub 仓库中的 Notebook 。
2.2.4. 调用推理接口
部署完成后,客户端可以通过 SageMaker Runtime API 调用推理服务。方案支持流式响应(streaming response),这对于大语言模型的实时交互体验至关重要。
调用代码使用 invoke_endpoint_with_response_stream 方法实现流式调用,响应数据以 Server-Sent Events(SSE)格式返回。代码中的缓冲和解析逻辑处理了流式传输中可能出现的部分数据和分包问题,确保每个完整的 JSON 对象都能被正确解析。
这个部署方案将开源的 Ollama 生态与 AWS 托管服务有机结合。通过 AWS CodeBuild 实现了 ARM 架构镜像的自动化构建,通过 Amazon SageMaker 获得了企业级的模型托管能力,通过 Graviton 实例实现了成本优化。
2.3亚马逊云科技中国区(北京/宁夏区域)部署选择
在亚马逊云科技中国区新上线了 Graviton4 机型,与Amazon Graviton3处理器相比,Amazon Graviton4性能提升30%,独立核心数增加50%,内存带宽提升75%。可以在EC2 上选择 Graviton 3 和 Graviton 4 实例部署上述容器进行模型推理。对于API 接入端,同样可以采用亚马逊云科技推出的Static BGP(S-BGP)服务,是专为中国区域(北京和宁夏)设计的一种成本优化型数据传输服务。通过这项服务,我们致力于帮助客户在保证网络性能的同时显著降低数据传输成本。 S-BGP 可为符合条件的客户提供高达20%~70%的数据传输费用节省。
3. 应用分析
3.1适用场景:用轻量模型解决高频简单任务
在实际业务中,并非所有任务都需要部署参数量数百亿的大型模型。很多企业面临的问题是:70%-80% 的 AI 应用场景其实是相对简单和标准化的任务,但如果使用大型模型来处理这些场景,成本会显著增加。Qwen3 0.6B 正是为这类高频但相对简单的任务而设计的理想选择,它能够在保证任务完成质量的前提下,将推理成本降低到大型模型的几分之一甚至十分之一。
典型的适用场景包括:工单的自动分类与路由、实时文本翻译、关键信息提取、电商评论的情感分析等。这些任务的共同特点是问题域相对明确,不需要复杂的推理链,但对响应速度和成本敏感度高。例如,企业可以使用该模型对每天数万条客服工单进行自动分类和优先级判定,将技术问题路由至技术团队、账务问题路由至财务团队;或是对跨境电商平台的多语言商品评论进行实时翻译和情感分析,帮助商家快速了解国际用户反馈;又或是从大量合同文档中自动提取关键条款、日期、金额等结构化信息。
3.2性能与成本对比
我们在多个 Amazon EC2 实例类型上对 Qwen3 0.6B 模型进行了全面的性能测试。测试条件为 input tokens 和 output tokens 均为 200 时的性能表现:
| 实例类型 | 架构 | CPU | 内存 |
按需价格 (美元/小时) |
输出速度(tokens/秒) | 端到端延迟(秒) |
单次请求成本 (美元) |
| c7i.xlarge | Intel | 4 | 8 GiB | $0.1785 | 25.52 | 9.70 | $0.000481 |
| c7g.xlarge | Graviton 3 | 4 | 8 GiB | $0.145 | 32.65 | 8.39 | $0.000338 |
| c8g.xlarge | Graviton 4 | 4 | 8 GiB | $0.15952 | 36.22 | 7.47 | $0.000333 |
从测试数据可以清楚看到 Graviton 架构的成本优势。在相同配置(4 vCPU,8 GiB 内存)下,Graviton 3 c7g.xlarge 相比 Intel c7i.xlarge 的输出速度提升约 28%(32.65 vs 25.53 tokens/秒),端到端延迟降低约 14%,而单次请求成本下降约 30%。最新的 Graviton 4 c8g.xlarge 实例性能更加出色,输出速度达到 36.22 tokens/秒,比 Intel 实例快约 42%,端到端延迟仅 7.47 秒,单次请求成本进一步降至 $0.000333。
4. 总结
AWS Graviton 处理器与 Qwen3 0.6B 模型的结合为企业提供了一个极具性价比的 LLM 推理解决方案。通过SageMaker和Ollama可实现一键部署,支持多种应用场景。这一技术组合不仅满足当前轻量级AI应用需求,还为企业构建成本可控、性能优异的智能化服务提供了理想的技术基础,特别适合对成本敏感且需要快速响应的生产环境部署。基于实际测试验证,Graviton 4 实例相比同配置 Intel 实例在推理吞吐量上提升 42%,单次请求成本降低 31%。在工单分类、情感分析、关键信息提取、轻量级翻译等不需要复杂多轮推理的场景下,Graviton CPU 实例提供了除 GPU 之外的另一种推理方案选择,为企业的技术选型提供了更多灵活性。
参考文档
https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html
https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints-graviton.html
https://huggingface.co/Qwen/Qwen3-0.6B#best-practices
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
